
一种无位置偏见的广告协同推荐算法
2014-12-02 01:12霍晓骏
计算机工程 2014年12期
霍晓骏,贺 樑,杨 燕
(华东师范大学信息科学与技术学院,上海 200241)
1 概述
进入21 世纪,计算机的发展引发了电子商务的兴起。企业家通过展示在搜索引擎页面侧边栏的广告来为自己的商品做宣传,这种方式为广告发布者带来数以亿计的收益[1-2]。Google 和Yahoo 都凭借广告展示系统获得了巨大的利润,这样的利润仅来自于用户对广告的点击。一个好的广告推荐系统,能为商家带来意想不到的收获。
广告推荐系统会在网页的侧边栏展示多个广告,吸引用户点击。一个广告有时会多次展示在同个网页上,有时会展示在不同页面的不同位置,由此可以计算出一个广告在一个页面上的点击率(Clickthrough Rate,CTR)。如何预测CTR 以及利用CTR来正确推荐广告是目前研究的热点。文献[3]按照基于用户协同过滤的思想,根据CTR 的特点,通过找到与待推荐页面相似的页面,为页面进行来自邻居的推荐。这类方法存在的问题是,点击率的高低并不能完全等同于这个广告与展示它的网页的相关性,例如某些广告由于展示位置靠上,从而点击率较高,但是相关性不高。用户是否点击广告,则是由相关性决定的。因此将点击率“代替”相关性直接用于协同推荐系统是值得斟酌的。
文献[3]将点击率等同于相关性,从而使得广告排布不合理,导致用户对广告的点击量下降。为了解决这个问题,文献[4-5]提出位置模型和级联模型,衡量了点击率、位置影响、相关性三者之间的关系,但是却各有所短。比如在位置模型中,位置影响通过实验,如眼球追踪的实验和用户习惯问卷得到,需要耗费大量的人力物力,不适用于商业系统,因此难以推广。
为弥补这些方法的不足,本文将重点对文献[3]方法进行改进,考虑位置偏见带来的影响,提出NPBCF(No Position Bias Collaborative Filtering)方法,利用页面-广告相关性来代替点击率,通过构造贝叶斯公式,合理地解释点击率、相关性之间的关系。与传统方法相比,所有数据仅来自于对点击日志的分析,而无需另行收集。排除历史数据中位置的影响,提取不带位置偏见的页面-广告相关性,将这样的数据用于协同推荐,能够获得更准确的推荐效果。
2 相关工作
为了推荐广告,无论是预测点击率,或者是计算页面与广告的相关性,均有2 个研究方向:(1)基于模型的算法,建立特征模型预测点击率;(2)基于邻域的协同过滤算法,利用页面对广告的相关性,找到页面或者广告的相似邻居,根据相似邻居的广告点击率将合适的广告刊登在合适的页面上。对于这种算法,早期的学者并没有考虑位置可能带来的偏见,下文将介绍对位置偏见的相关研究。
2.1 基于模型的机器学习
机器学习可以预测点击率。通过建立特征模型,从数据中提取各种附加特征,如广告文字内容,甚至广告颜色、大小等[2],然后统计这些特征下广告的点击率,由此,当输入一些条件时,能够智能地推断出这些特征条件对广告点击的影响。KDD Cup 2012 中的任务2[6]是对广告点击次数的预测,该比赛提供了丰富的数据,不仅有最基本的页面id、广告id,同时还有广告的相关属性,如广告商、关键词、点击用户等。比赛的优胜者[6]将这些内容作为机器学习的特征,通过给定的训练数据,构建点击率预测模型。但是对于广告推荐而言,机器学习的可解释性差,很难向用户解释是出于什么原因为用户推荐这个广告,特别是很多用来训练的特征有时往往会被用户视为隐私,不愿意被广告推荐系统提取建模。
2.2 协同过滤广告推荐
传统的协同推荐系统[7]只使用了用户的购买记录,推荐流程尽量少地涉及用户隐私。文献[8]对比了协同过滤中的各种模型,浏览模型(UBM)、矩阵分解模型(MFCM)、个性化模型(PCM)并提出独创的混合个性化模型(HPCM),其创新点在于,将原有的用户-产品二维矩阵,扩展为用户、页面、文档三维空间,通过张量分解的方式,在这个立方数据上计算相似度,进行邻居推荐。
文献[3]将协同过滤应用到广告推荐系统中。一般的协同推荐系统是一个向用户推荐产品的系统,当协同过滤被应用到广告推荐系统中时,把页面看成“用户”,把广告看成“产品”,把某个页面中某个广告的点击率(CTR)看成是“用户对产品的评分”,为待推荐页面找到“行为上”与其相似的页面,将在这些相似页面上刊登过的并且CTR 较高的广告刊登在待推荐页面中。与基于用户的协同推荐相似,用户可能会接受来自于相似用户的推荐,那么在广告推荐场景下,在待推荐页面上刊登相似页面的广告也可能取得较高的点击率。
但是这种方法存在一个问题,在基于用户的协同过滤中,用户对产品的评分单纯地表示了用户对产品的喜好程度,不受其他因素的影响。相似的用户有着相似的喜好,来自相似用户的推荐确实是能够被待推荐用户接受。但在广告推荐中,CTR 不仅表示页面与广告的相关程度,同时也受到广告刊登位置的影响。某些广告CTR 高,并不说明这个广告和刊登它的页面很相关,可能仅仅是因为它的展示位置靠上才吸引了用户的点击。如果待推荐页面刊登了一个并不相关的广告,就无法吸引用户的注意,从而成为一次无用的展示。因此,需要从CTR 中分析出“页面-广告相关性”,正确地看待位置对CTR、相关性产生的影响,这样才能获得更准确的推荐结果。
2.3 广告推荐中位置的相关研究
2.3.1 位置模型
Hotchkiss 等人[9]发现了位置对文档的点击产生了重大影响。搜索引擎为用户提交的查询返回一个结果页面,其中包含许多查询结果链接以及广告链接,这些链接从上至下地排列。文献[9]将这些链接重新排序后展示,统计每个链接的点击率。最终发现,无论这些链接如何排序,位置越靠后的链接CTR越小。在广告推荐系统中,也有类似的现象。例如文献[4]中,作者统计了各位置的广告点击数量,发现最靠上位置的广告被点击的最多。于是,文献[4]通过贝叶斯公式,将位置看成是一种影响点击率的条件因素,将点击率描述为条件概率的形式:

将页面-广告点击率看成是页面-广告相关性p(click|ad,seen)和位置因素p(seen|pos)的共同影响,将广告位置作为一种单独作用的因素分离出来,强调“广告在某个位置被看见”这一事件发生的概率。
2.3.2 级联模型
另一种被称为级联模型的广告点击率预测方法受到文献[9]发现的另一个结果的启发。文献[9]跟踪用户在浏览网页时的用户眼球定位,发现用户普遍地浏览顺序是从上到下,于是Kempe 等人[5]将用户点击看成伯努利事件,认为只有当上一个位置的文档没有被点击时,下一个位置的文档才有可能被点击。
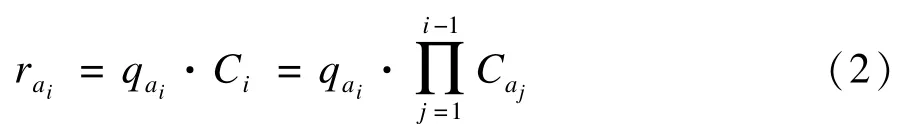
其中,rai表示广告ai在页面q的位置i下被点击的概率;qai代表广告ai被认为与页面q相关的概率;Ci代表拒绝概率;qai代表广告ai不被认为与页面q相关的概率;位置因素是通过拒绝概率Ci的连乘实现的。
位置模型和级联模型表示了位置因素、点击率、相关性三者之间的关系,它们都表现出了位置对点击率的影响。本文工作受到位置模型的启发,在此基础上,利用贝叶斯定理推导页面和广告的相关性,然后使用协同过滤的方法,估计页面和广告的相关性,形成推荐列表。
除了基于用户的协同过滤可以用于广告推荐,基于模型的协同过滤[10]也可以用于广告推荐[6]。另外,文献[11]也是利用位置模型预测点击率的一种变体,文献[12]详细解析了广告竞拍的原理,文献[13]则是针对广告拍卖设计的竞拍模型。
3 NPBCF 广告推荐算法
3.1 级联模型和位置模型的弊端
级联模型和位置模型作为广告位置研究的一项重大发现,具有重大影响。为了方便地构建问题模型,研究者们尽量地把问题简单化,但往往留下了一些弊端。例如在早期的级联模型中,只考虑了一次点击的情况,而用户先后点击多个广告的情况则不予考虑,这是不合逻辑的。后来学者也做了许多改进,使级联模型更加符合实际情况,但是却导致模型极度复杂化,使得实际应用难以实现。
关于位置模型的问题,同样在于实际应用难实现。按照模型的意义,对于p(seen|pos)这项,表示“某个位置的广告会被看见的概率”,这个概率一般是很难准确测量得到的。虽然文献[9]研究了人类的阅读习惯,可以统计各位置被用户查看的概率,但该文专门构造了一个实验环境,利用精细的摄像机来捕捉人类眼球运动,由此才能得到这些概率。在真实的应用场景下,一般民用摄像头难以胜任采集数据的要求,同时还将要面对侵犯隐私的问题。
3.2 排除位置偏见的页面-广告相关性计算方法
当需要计算某个广告ai在某个页面qj的相关性时,可以用这个广告ai和这个页面qj之间的点击率p(ai,qi)来衡量相关性,点击率越大,说明页面qj和广告ai越相关。此时:

其中,p(ai|qj)可以认为是广告ai和页面qj的相关性;p(qj)可以认为是页面的吸引作用。通过文献[4-5]可知,位置因素使得一些广告虽然和刊登它的页面有着很高的相关性,点击率却出奇的低。点击率是相关性和位置因素共同作用的产物。如果用p(ai|qj)表示页面qj和广告ai的相关性,那么点击率应该表示为p(ai|qj,pk),其中,pk表示位置。这时不能使用上式来计算相关性,因为p(ai,qj)是无法被统计的,它受到了位置的影响,只能统计例如p(ai,qj,pk)这样的概率,于是问题转化成如何用p(ai,qj,pk)来表示p(ai|qj)。
在考虑广告ai、页面qj、位置pk三者独立的情况下,有:
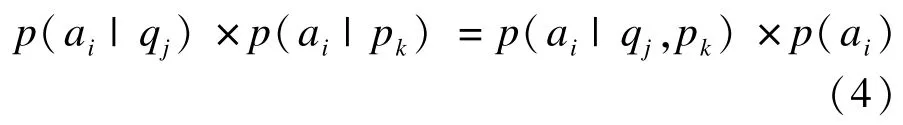
其中,p(ai|pk)和p(ai)并没有特别的意义,只是为了平衡等式而已。如果位置总共有N种,那么根据贝叶斯定理,有:

其中,p(ai,qj,pk)代表出现在页面qj的位置pk的广告ai的点击率;p(qj,pk)代表页面qj的位置pk的所有广告点击率;p(ai,pk)代表出现在位置pk的广告ai的点击率;p(pk)表示出现在位置pk的所有广告的点击率;p(ai)代表广告ai的点击率,这些点击率数据都可以通过统计日志信息得到。
为了更加突出位置对点击率造成的影响,本文人为地修改页面-广告相关性。当一个广告在一个页面的位置2 处被点击,令这个页面-广告相关性为上式计算结果的1.2 倍,当广告在页面的位置3 处被点击,令这个页面-广告相关性为上式计算结果的1.5 倍。一个广告如果能吸引用户在不起眼的地方去点击它,可想而知这个广告与刊登它的页面非常相似,以至于克服了不利位置带来的不利影响。
3.3 NPBCF 广告推荐流程
根据式(5)能够得到有点击记录的广告和页面之间的相关性,当需要对没有记录的页面-广告估计相关性时,可以将问题看作协同过滤。利用协同过滤中基于邻居的方法来预测相关性,同第2 节介绍的利用协同过滤预测点击率的方法一样,在本文方法中,将页面看成待推荐的用户,将广告看成用来推荐的产品,将页面-广告相关性看成是用户对产品的评分。
与传统的基于用户的协同过滤类似,NPBCF 算法的推荐结果来自于用户的邻居,即相似的页面。待推荐页面的某个邻居页面刊登了一些没有在待推荐页面上刊登过,并且在邻居页面上被点击过的广告,如果将这些广告刊登在待推荐页面上,很可能就会被点击。原因在于这个页面和它的邻居在点击行为上是存在相似性的,这种相似性使得它们对同个广告的相关性也是相近的,如果邻居页面与这个广告的相关程度足以导致被点击,那么相似页面与这个广告的相关程度也可能导致这个广告在待推荐页面上被点击。
首先需要衡量用户之间的关系,就是要度量不同页面之间的相似度。如果2 个页面具有相似的历史点击行为,可以认为这2 个页面是相似的邻居。相似的历史点击行为,不仅指在这2 个页面上有许多相同的广告被点击过,而且2 个页面对同个广告的相关性数值上也要接近。具体而言,根据相关性构建页面向量,使用调整余弦相似度相似计算每个页面之间的相似度[3]:

其中,px为p(ai|qx);py为p(ai|qy) -;s(qx,qy)表示刊登在页面qx和页面qy上的广告ai集合。
根据找到相似的页面进行邻居推荐,可以利用待推荐页面与其邻居的关系以及邻居对某个广告的相关性推导待推荐页面对这个广告的相关性。如果待推荐页面与某个邻居特别相似,那么这个邻居对某个广告的相关性将在很大程度上影响待推荐页面对这个广告的相关性,具体来说[3]:

其中,QK(qx)表示页面qx的K个邻居页面集合;qy是其中的元素,表示每个相似邻居页面,简单来说是一个加权求和的过程,待推荐页面综合考虑了它的邻居们对某个广告的看法后,根据自己与邻居的差距预估了自己对这个广告的看法。
根据式(7)能够预计出页面qx与广告ai的相关性,相关性越大,代表这个广告要是刊登在这个页面上,被点击的可能性就越大,可以选择最大的M个广告用于推荐。
NPBCF 算法流程如图1 所示。

图1 NPBCF 算法具体流程
4 实验结果与分析
本节将对比传统协同过滤(Collaborative Filtering,CF)[3]以及本文所提出的排除位置偏见的协同过滤NPBCF 的性能。
4.1 实验数据与结果分析
4.1.1 数据集
本文使用KDD CUP 2012 任务2 的训练数据集。在这个任务中,主办方收集了腾讯搜搜的广告点击数据。包含22 023 547 名用户的641 707 条广告的共计149 639 105 会话记录,每条会话记录包含的特征如表1 所示。

表1 KDD 数据集
每个页面上均展示3 个广告,从上至下分别表示为位置1、位置2、位置3。使用这个数据集完成对特定的10 000 个页面的广告推荐,由于采用最基本的协同过滤来处理推荐任务,有用的数据只有Click,Impression,AdID,Position 和QueryID,于是先将相同AdID,Position 和QueryID 的数据进行整合,得到3 142 966 条记录,由于数据量巨大,需要进一步处理。
4.1.2 数据预处理及划分
由于采用协同过滤的方式对页面进行推荐,而协同过滤对数据稀疏度有较高的要求。通过整理数据发现共有页面1 848 114 个,广告255 170 条,稀疏度为99.999 4% 。为了进一步减小稀疏度,需要减小数据集。于是选取了点击记录最多的10 000 个页面,只考虑这些页面的记录。此时数据量被压缩到2 766 393,包含广告255 170 条,稀疏度99.89%,勉强能够进行协同过滤推荐。在每个页面刊登的广告中,随机选择20% 的广告以及这些广告和页面的相关性作为测试集,其余数据作为训练集。
4.1.3 测评指标
本文采用TopN 的推荐方式,对推荐结果计算不同邻居数情况下的准确率(P)、召回率(R)、以及F 度量值(F)。TopN 推荐是给用户一个个性化的推荐列表,对应本文的应用场景,是给页面q一个性化推荐列表。TopN 推荐的预测准确率一般通过召回率/准确率度量,召回率又称查全率,是正确推荐的比率,准确率是正确推荐结果占全部推荐的比重,即推荐中存在正确推荐的比例,F 度量值是一种兼顾准确率和召回率的算法性能总体表现的一种指标。令R(q)是根据页面q在训练集上的行为给页面q做出的推荐列表,而T(q)是页面在测试集上的行为列表,那么推荐结果的准确率、召回率和F 度量值定义为:
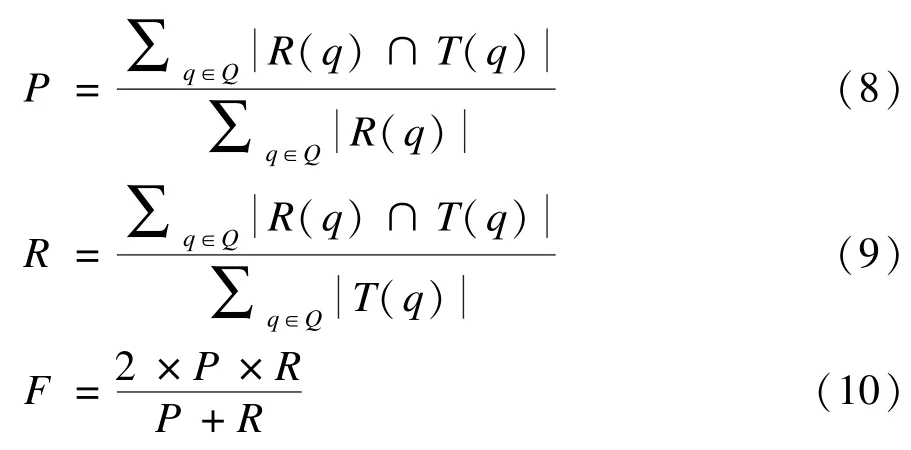
4.1.4 数据分析
统计每个位置的点击数量。有时同样的广告会展示在相同页面的不同位置,例如,广告“电脑维修”有时展示在页面“电脑”的位置1 处,有时在位置2 处。假设“电脑维修”在“电脑”的位置1 处展示了10 次,被点击3 次;位置2 处展示了20 次,未被点击,那么可以称“电脑维修-电脑”为一种配对,这种配对在位置1 处的点击率是30%,在位置2 处的点击率是0。
对于每一个配对,无论广告展示在何处,广告与页面的相关性是固定不变的,但发现有51 629 个广告在相同页面的位置1 处和位置2 处被点击过,其中,位置1 的点击率比位置2 的点击率更高的广告有30 143 个,有13 564 个广告在相同页面的位置1 处和位置3 处被点击过,其中,位置1 的点击率比位置3 的点击率更高的广告有8 433 个,这样的数据对比说明位置偏见确实存在。
4.2 结果分析
对比不同邻居数目(分别是5,10,15,20,25,30)情况下,采用传统协同过滤[3]和本文提出的NPBCF 算法,对10 000 个页面进行TOP10 推荐,即每个页面推荐10 个广告,观察2 种算法的准确率、召回率以及F 度量值,对比结果如图2~图4 所示。
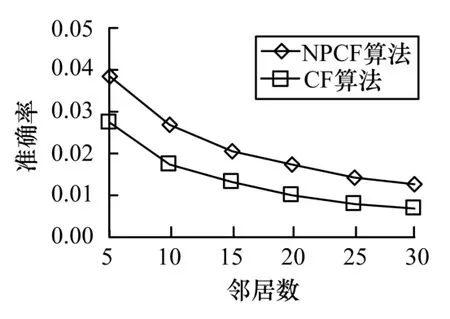
图2 准确率对比
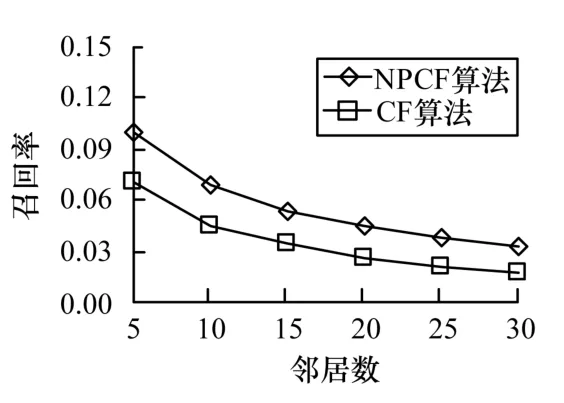
图3 召回率对比
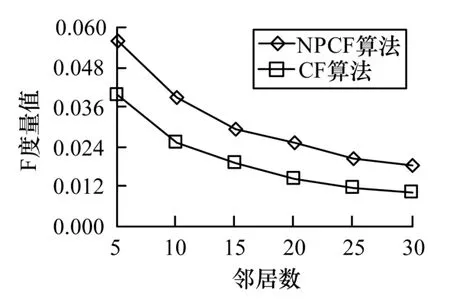
图4 F 度量值对比
通过对比发现,NPBCF 算法的效果比传统协同过滤算法至少提高了40%,而且随着邻居数目增多,虽然推荐质量下滑,但是NPBCF 算法对于参数选取错误有着更强的抵抗性。
对于一般的协同过滤系统,邻居数目越多,推荐结果越好,但是在本文实验中发现,当考虑更多的相似页面,反而使推荐质量严重下滑,为此,对比了邻居数为5 和邻居数为10 情况下NPBCF 算法的页面相似度和广告-页面相关性,如表2 所示。
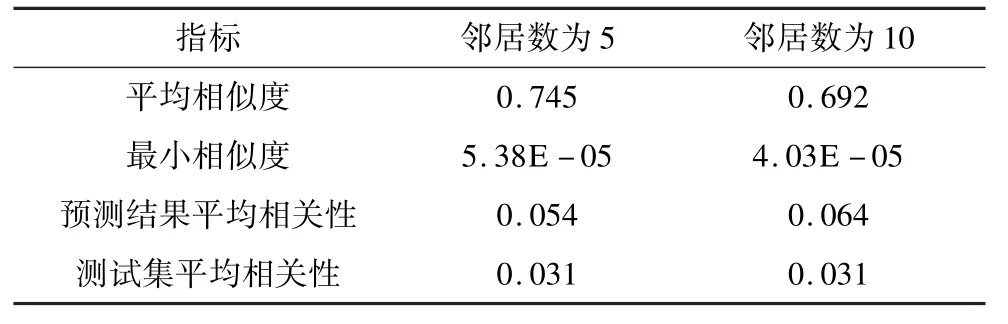
表2 相似度和相关性的对比
由此可以看出,在广告系统中,真正相似的页面数量十分有限。当系统考虑了更多不相似的邻居时,这些邻居页面刊登了点击率(相关性)十分高的广告,以至于这些广告能够无视页面不相似,成为协同推荐的结果,破坏推荐质量。当不考虑相似度过小的邻居时,即将10 个邻居中相似度低于平均相似度的页面剔除,发现NPBCF 的F 度量值上升了25% 。只有当系统将真正相似页面考虑为邻居,协同过滤才能发挥其原本的效果,不相似的页面对协同推荐效果有着严重的影响。
5 结束语
传统的观点误将页面-广告相关性看成页面-广告点击率。点击率不仅和页面-广告相关性有关,同时还受到广告刊登位置的影响。由于某些广告展示在靠上的位置,使得这些广告凭借位置上的优势获得了更高的点击率,如果笼统地将点击率看成相关性,将产生错误的推荐。本文提出一个相关性计算方法,能够排除点击数据中所带有的位置偏见,正确地计算页面-广告相关性,再通过协同过滤技术,为页面找到与其相似的其他邻居页面,利用邻居页面找到合适的广告。最终通过实验证明,本文提出的NPBCF 算法能够比传统协同过滤算法得到更准确的推荐结果。
[1]周傲英,周敏奇,宫学庆.计算广告:以数据为核心的Web 综合应用[J].计算机学报,2011,34 (10):1805-1819.
[2]Craswell N,Zoeter O,Taylor M,et al.An Experimental Comparison of Click Position-bias Models[C]//Proceedings of International Conference on Web Search and Web Data Mining.[S.l.]:ACM Press,2008:87-94.
[3]Anastasakos T,Hillard D,Kshetramade S,et al.A Collaborative Filtering Approach to Ad Recommendation Using the Query-ad Click Graph[C]//Proceedings of the 18th ACM Conference on Information and Knowledge Management.Hong Kong,China:ACM Press,2009:1927-1930.
[4]Richardson M,Dominowska E,Ragno R.Predicting Clicks:Estimating the Click-through Rate for New Ads[C]// Proceedings of the 16th International Conference on World Wide Web.Alberta,Canada:ACM Press,2007:521-530.
[5]Kempe D,Mahdian M.A Cascade Model for Externalities in Sponsored Search[C]//Proceedings of the 4th International Workshop on Internet and Network Economics.Berlin,Germany:Springer,2008:585-596.
[6]Wu Kuanwei,Ferng Chun-Sung,Ho Chia-Hua,et al.A Two-stage Ensemble of Diverse Models for Ranking Click-through Rates Slides[Z].2012.
[7]Sarwar B,Karypis G,Konstan J,et al.Item-based Collaborative Filtering Recommendation Algorithms[C]//Proceedings of the 10th International Conference on World Wide Web.Hong Kong,China:ACM Press,2001:285-295.
[8]Shen Si,Hu Botao,Chen Weizhu,et al.Personalized Click Model Through Collaborative Filtering [C]//Proceedings of the 5th ACM International Conference on Web Search and Data Mining.Seattle,USA:ACM Press,2012:323-332.
[9]Hotchkiss G,Alston S,Edwards G.Eye Tracking Study[EB/OL].(2005-08-11).http://www.enquiro.com/eye-tracking-pr.asp.
[10]Koren Y,Bell R,Volinsky C.Matrix Factorization Techniques for Recommender Systems[J].Computer,2009,42(8):30-37.
[11]Chen Ye,Yan T W.Position-normalized Click Prediction in Search Advertising[C]//Proceedings of the 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.New York,USA:ACM Press,2012:795-803.
[12]Edelman B,Ostrovsky M,Schwarz M.Internet Advertising and the Generalized Second Price Auction:Selling Billions of Dollars Worth of Keywords[J].American Economic Review,2007,97(1):242-259.
[13]Pin F,Key P.Stochastic Variability in Sponsored Search Auctions:Observations and Models[C]//Proceedings of the 12th ACM Conference on Electronic Commerce.[S.l.]:ACM Press,2011:61-70.
猜你喜欢
保健医苑(2022年1期)2022-08-30
科学大众(2020年23期)2021-01-18
汽车观察(2019年2期)2019-03-15
华东师范大学学报(自然科学版)(2018年3期)2018-05-14
中国卫生(2016年5期)2016-11-12
海峡姐妹(2015年8期)2015-02-27
生物进化(2014年2期)2014-04-16
海外英语(2013年3期)2013-08-27
网络安全技术与应用(2011年3期)2011-03-14
河北软件职业技术学院学报(2010年3期)2010-06-06
