
网络舆情监控系统中主题网络爬虫的研究与实现*
2014-12-02 06:07:04
舰船电子工程 2014年9期
(陆军军官学院计算中心 合肥 230031)
1 引言
网络舆情是是通过互联网传播的公众对现实生活中某些热点、焦点问题所持的有较强影响力、倾向性的言论和观点,是社会舆论的一种表现形式[1]。由于网络舆情传播速度快、影响大,因而有必要建立自动化的网络舆情监控系统以实现对网络舆情信息的及时采集、分析、监控与引导[2]。网络舆情监控系统主要包括信息采集模块、预处理模块、分析模块和预警模块四个部分[3]。采集模块是舆情分析处理工作的基础,其核心是通过一个或多个并行的采集器从互联网上不断收集各种网页数据,这些采集器通常称为网络爬虫或网络蜘蛛。本文首先对通用网络爬虫和主题网络爬虫的处理流程作了简单介绍,分析两者区别,提出了主题网络爬虫的设计模块结构,研究了系统所要实现的关键算法,用以指导一种简单、高效的面向主题的网络舆情信息采集系统的设计及实现,以提供对网络舆情采集和分析工作的支持。
2 网络爬虫的相关介绍
网络爬虫是网络舆情监控采集系统的核心和基础,它对网络舆情采集的覆盖率和查准率都有很大的影响。根据采集内容目标的不同,网络爬虫主要分为通用网络爬虫和主题网络爬虫两种。通用网络爬虫的目标就是尽可能多地采集信息页面,在采集时只关注网页采集的数量和质量,并不考虑网页采集的顺序和被采集页面的相关主题。随着网络信息的指数式增长,通用网络爬虫面临着网页规模、更新速度和个性化需求等多方面的挑战[4]。为改善网络爬虫的效率,使之能满足特定人群深层次的、面向特定领域的信息需求,必须要采用主题网络爬虫。其目标是尽可能多地采集与主题相关的网页,在采集的过程中时刻关注网页内容与主题的相关度。
2.1 通用网络爬虫简介
通用网络爬虫通过网页之间的超链接关系来不断采集网页,首先建立一个初始化的URL集合,它是一个有序的待抽取的URL 队列,接着从该队列的某一个URL 开始,提取对应页面的HTML内容,并分析提取在该网页上的其它所有超链接,将它们分别加入到URL队列中,更新之前的URL队列,再按照图遍历中广度或深度优先抓取策略来访问下一个URL 链接,依次循环,重复以上过程,直至所有的网页都被提取完毕或根据Web爬取策略停止采集为止,其爬取流程如图1所示。
2.2 主题网络爬虫介绍
主题网络爬虫是指选择性的抓取与目标主题相关的网页。首先对主题进行向量表示,根据内容相关度计算得出网页内容和主题的相关度,并对链接进行相关度评价,以决定是否采集某一网页[5]。在采集过程中并不需要采集所有网页,因而主题网络爬虫保存的页面较少,可以大大节省所需要的硬件和网络资源,能很好地满足特定人群对于查找特定主题的需求。主题爬虫是在通用爬虫的基础上做了一些功能上的扩充,增加了对URL 和网页的主题相关度评价,其完整的工作流程如图2所示。
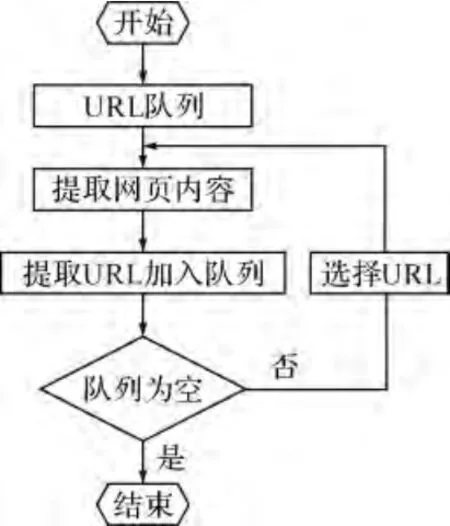
图1 通用网络爬虫工作流程
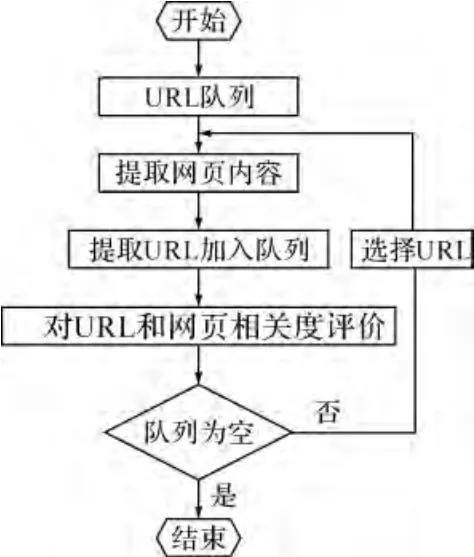
图2 主题网络爬虫工作流程
3 主题网络爬虫的模块设计
主题网络爬虫系统仅对和主题相关的网页进行采集,并不覆盖所有的网页。首先对主题进行向量表示,根据内容相关度计算出要访问的页面内容和主题的相关度,并对链接进行预测分析,识别出这些链接是否和主题相关,然后决定是否采集该链接指向的网页以及设置相关提取链接的顺序[6]。主题网络爬虫的完整的运行过程为
1)启动爬虫程序,输入主题及种子站点,对主题进行向量表示;
2)获取网页HTML正文内容,将网页送入页面相关度分析模块,计算该页面与主题的相关度,同时将提取到的页面链接及链接的锚文本等相关信息送入到链接评价模块,经测算相关度大于阈值的链接送入链接优先权队列;
3)根据链接选择策略选择将下一个要访问的链接送入到爬行模块;
4)返回到2),继续循环,直到满足结束条件为止。
主题网络爬虫更加注重于发现用户需要的信息资源,如何更多地获得与主题相关性比较高的网页及如何有效地提高采集效率是主题网络爬虫设计的关键。主题爬虫的设计是以普通爬虫为基础的,对普通爬虫做了一些功能上的扩充,根据主题网络爬虫的功能需求及其运行流程,其模块设计如图3所示。
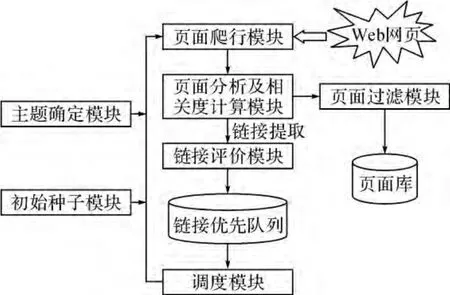
图3 主题网络爬虫模块结构
1)主题确定模块
主题确定模块是主题爬虫工作的基础,用于确定要爬行的主题,是对主题进行向量化表示。采用关键词集的方法来确立主题,把集合中关键词的个数n作为向量空间的维数,关键词的权值作为每一维分量的大小。权值通过特征提取来获得,首先给定一个与主题相关的网页集合,由程序自动提取网页里的共同特征,根据出现的频率计算权值。
2)优化初始种子模块
优化初始种子模块是选择与主题相关度高的URL作为页面爬行模块的入口地址,首先由搜索引擎搜索出网页,再由人工筛选获得。
3)页面分析以及相关度计算模块
相关度计算模块是主题爬虫区别于通用爬虫的最主要模块。该模块中首先需要设定一个阈值,再进行相关度计算,将计算结果与设定的阈值进行比较。若爬取的网页的主题相关度大于阈值,则表示与主题相关,需要进行后续处理。若网页的主题相关度小于阈值,则表示与主题无关,可以通过过滤模块丢弃。模块中的相似度计算和阈值设定尤为重要,关系到主题爬虫的整体性能。
4)页面过滤模块
页面过滤模块是对下载过的网页进行过滤。主题相关度大于阈值的网页就会被保存到数据库中,小于阈值的网页被丢弃,以节省存储空间更多地获得与主题相关度较高的网页。
5)相关度链接评价模块
该模块的主要功能是对已下载网页中的链接进行相关度评价,如果预测链接的价值较高,则爬取。该模块使得主题爬虫爬取到的尽量都是与主题相互关联的,而无关的网页或者相关度较低的网页尽量避免被访问,从而提高爬虫的效率和主题资源的覆盖程度。
6)调度模块
调度模块是按照某种策略选择下一步要处理的链接,送入到爬行模块。
4 主题爬虫关键技术研究
主题爬虫更加注重于网页的相关度,根据一定的网页分析算法过滤与主题无关的网页,保留与主题相关的网页及链接,以尽可能多地采集与主题相关的网页内容[7],就要依靠对爬虫算法的设计,以下是主题爬虫所要研究的关键问题:
1)选取何种方法对主题进行特征提取,把主题表示成n维的带权的向量,以便于后续的相关度计算,这是主题爬虫设计非常重要的前提;
2)采用何种方法选取较优秀的种子站点作为爬取的入口地址,种子站点选取的好坏关系到主题获得的质量;
3)选择何种方法计算一个网页与主题的相关度,以使采集到的网页更向主题靠拢;
4)选择什么样的算法来预测评价链接URL的主题相关度,以提高目标网页预测的准确性;
5)选择何种爬行策略指导爬取过程,使爬虫跨过不相关的网页进入与主题相关的区域,以提高主题网页的覆盖率。
4.1 主题向量表示及关键词权值计算方法
主题用一组关键词来表示,主题关键词一般是从种子文档提取。种子文档是由用户指定的样例文档、种子页面对应的文档和对种子页面进行相邻区域扩展后生成的文档等组成。种子文档生成过程:增加种子页面指向的页面以及指向种子页面的页面来扩展种子集页面,扩展到一定的条件后停止,再把用户输入的样例文档、种子页面文档和扩展的种子文档组成一个种子文档集,最后用基于统计的词频—逆文档频率(TF-IDF)[8]方法对种子文档集进行词频统计,并且进行权值计算,把权值最高的n个值组成主题关键词集,来表示给定任务的主题。
主题采用空间向量(VSM)[9]表示为
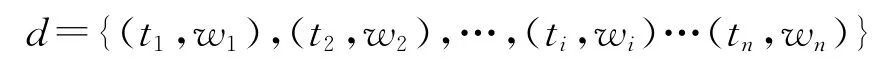
其中,n是文档特征关键词总个数,ti(1≤i≤n)为主题关键词集合,wi(1≤i≤n)为关键词ti对应的权值,用来表示它在文档中的重要程度,主题d也被简记为d={w1,w2,…,wn}。这样,主题通过向量空间模型表示成一个n维空间中的一个向量。
关键词ti的权值wi计算方法采用TF-IDF 方法,该方法体现了关键词在单个文档中的重要性及在整个文档集中的重要性,经典的TF-IDF公式如下:

其中tfi(d)为关键词ti在种子文档d中出现的频率,N为所有种子文档数目,ni为含有词项ti的文档数目。
4.2 相关度计算算法
向量距离法是计算相关度值最常用的方法。其步骤为:对采集的页面进行分析,统计出关键词出现频率,并求出频率之比,以出现频率最高的关键词为基准,其频率用ti=1表示,通过频率之间的比值,求出其它关键词的频率ti,则该页面向页面主题可用如下的向量表示为:d={(t1,w1),(t2,w2),…,(ti,wi)…(tn,wn)},(ti,wi)为每一维分量,该页面的主题相关度sim(di,dj)就可以用向量夹角的余弦公式来衡量,夹角θ越小,说明主题相关度越大,反之则越小。
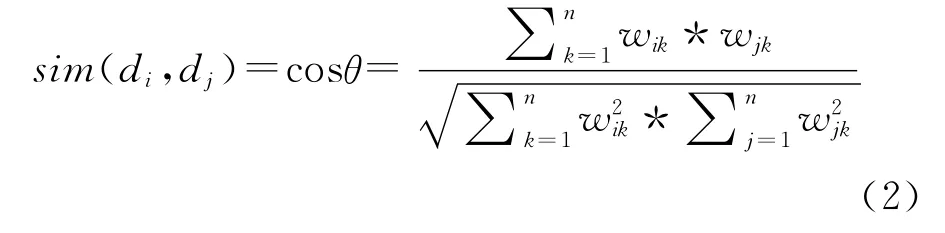
4.3 启发式搜索策略
启发式搜索就是根据已下载的页面、链接锚文本以及链接的结构关系来预测待抓取的目标网页的相关度,指导主题爬虫的爬取方向,以便于发现更多的与主题相关的网页,找到到达目标结点的最佳路径。
Fish-Seareh启发式搜索算法[10]是DeBar于1994年提出来的,它在深度优先搜索策略上的一种改进。其主要思想是:根据种子站点和查询的关键字,动态地维护一个待爬取URL优先队列,网页被抓取后,提取它所有的URL链接,这些链接所对应的网页统称为子网页。如果抓取的是与主题相关的网页,那么就把该网页所对应的子网页的深度设置成一个预先设定的值;如果抓取的是与主题无相关的网页,则把该网页中的子网页的深度设置成一个小于父网页深度的值。当深度减为零的时候,就停止这个方向的搜索。
4.4 基于分类器预测的算法
基于分类器预测实现的主题爬虫是一种比较有效的方法。Chakrabarti等于1999年提出的Focused crawling系统[11]是最早提出基于朴素贝叶斯分类的较为完善的主题爬虫。其主要思想是:首先选择开放URL目录体系中若干个子类节点作为主题信息,再把这些子类节点的所包含的页面作为训练样本集,来构造一个基于贝叶斯分类的分类器。对于一个新下载的页面,首先送入分类器进行预测,相关度大于阈值,就把页面中的链接送入链接优先权队列;小于阈值的页面,就连同它包含的链接一同丢弃。
5 结语
随着主题爬虫在信息采集和数据挖掘方面的重要性日益突出,主题爬虫的研究越来越受到人们的重视。本文首先概要介绍了通用网络爬虫和主题网络爬虫的特点和处理流程;接着在功能需求的基础上,分析了主题网络爬虫的模块设计及各个模块的功能;最后对主题网络爬虫要实现的目标,研究了主题向量表示、相关度计算、启发式搜索策略等系统涉及的关键算法。本文只是对主题爬虫的体系结构和关键算法进行了初步的研究和尝试,如何发现更多的网页、如何抓取相关度更高的页面及如何提高主题爬虫的效率都是下一步值得研究和改进的地方。
[1]叶昭晖,曾琼,李强.基于搜索引擎的网络舆情监控系统设计与实现[J].广西大学学报(自然科学版),2011,36(10):302-307.
[2]卓秀然,赵伯听,郭国洪,等.基于网络爬虫的舆情信息采集系统设计与实现[J].福建电脑,2012(4):134-135.
[3]何佳,周长胜,石显峰.网络舆情监控系统的实现方法[J].郑州大学学报(理学版),2010,42(3):82-85.
[4]S.Brin,L.Page.The anatomy of a large-scale hyPertextual search engine[R].Stanford University,1998:107-117.
[5]宋海洋,刘晓然,钱海俊,等.一种新的主题网络爬虫爬行策略[J].计算机应用与软件,2011,28(11):264-267.
[6]魏晶晶,杨定达,廖祥文.基于网页内容相似度改进算法的主题网络爬虫[J].计算机与现代化,2011(9):1-4.
[7]刘金红,陆余良.主题网络爬虫研究综述[J].计算机应用研究,2007,24(10):26-29.
[8]施聪莺,徐朝军,杨晓江.TFIDF 算法研究综述[J].计算机应用,2009(29):167-180.
[9]Qinglin Guo.The Similarity Computing of Documents Based on VSM[C]//Proceedings of Computer Software and Applications,2008.COMPSAC'08.32nd Annual IEEE International,2008:585-586.
[10]P.M.E.De Bra,R.D.J.Post.Searching for arbitrary information in the WWW:Thefish Search for Mosaic[C]//In 2nd World Wide Web Conference'94:Mosaic and the Web,Chieago,October,1994.
[11]Soumen Charkrabarti,Martin van den berg,Byron Dom,et al.A New Approach To Topic-specific web resource diseovery[J].Compute Networks,1999,31(11-16):1623-1640.
猜你喜欢
房地产导刊(2022年10期)2022-10-18 08:03:52
保健医苑(2022年1期)2022-08-30 08:39:14
现代信息科技(2021年21期)2021-05-07 02:54:12
电子制作(2018年10期)2018-08-04 03:24:38
电子测试(2018年1期)2018-04-18 11:53:04
电子制作(2017年2期)2017-05-17 03:54:56
电子制作(2017年9期)2017-04-17 03:00:46
电子测试(2015年18期)2016-01-14 01:22:58
计算机与网络(2014年7期)2014-03-25 10:57:07
电脑爱好者(2011年11期)2011-06-22 08:20:18
