
数据挖掘聚类算法在船岸一体化平台中的应用
2014-11-30 03:48:08汪益兵徐显文
中国航海 2014年2期
汪益兵, 王 捷, 徐显文
(浙江国际海运职业技术学院, 浙江 舟山 316021)
数据挖掘聚类算法在船岸一体化平台中的应用
汪益兵, 王 捷, 徐显文
(浙江国际海运职业技术学院, 浙江 舟山 316021)
船舶的远程动态跟踪及数据采集、处理与应用是船岸一体化平台的一项主要内容。船岸一体化平台收集的数据呈现复杂的关系,而利用数据挖掘技术能从中发现知识或规律,及时分析以提供决策支持。介绍船岸一体化平台的数据采集过程、对数据的要求以及数据挖掘方法的相关理论。以船舶节能为研究目标,举例说明k均值聚类算法的应用过程,为船岸一体化平台的数据处理与功能实现提供一个新的思路。
水路运输;数据挖掘;k-means聚类算法;船岸一体化平台;船舶节能
数据挖掘技术是随着数据库和人工智能发展起来的,现已成为信息决策领域研究的前沿,得到了学术界和工业界的广泛关注。[1]近年来,该技术在海上交通的交通流数据特征分析、交通事故分析与预防、船舶行为研究等领域得到了研究或应用。[2-6]日渐发展的船岸一体化平台在航运公司管理人员实时、高效管理船舶方面显示出广阔的应用前景。在船岸一体化平台中,运用数据挖掘聚类分析技术处理平台收集的船舶数据,获得相关知识、规律,为实现成本控制、节能减排、决策分析等功能提供技术支持。
1 船岸一体化平台及其对船舶数据的要求
船岸一体化平台是航运公司将利用现代通信、信息技术采集到的船舶各类运行数据进行集中管理与综合应用,然后将其作为船岸安全与技术管理决策依据的管理平台。该平台将公司(岸基)与所属船舶(船端)所有日常管理、技术管理、安全管理、航运管理、成本控制集于一体,实现船岸信息资源共享与管理一体化,其核心是实现对船舶航行安全、设备运行状态、在船人员、所载货物与突发事件等的控制与跟踪。该平台能够提高管理层的调度和经营、决策能力,实现快速、动态地指导一线船员生产实践以及船舶管理的现代化。[7-9]
船岸一体化平台由船基数据采集处理、船岸数据通信以及岸基数据挖掘与远程监控等几部分组成。船基数据(包括船舶航行数据、机舱工况数据、海上气象数据和船舶AIS(Automatic Identification System)数据等)经采集处理,在文本文件加密或压缩后,通过海事卫星和网络传输,以邮件方式发送到岸基。岸基将收到的邮件进行解压缩和解密后,分发到相应的应用系统或储存到指定的数据库中,实现船岸数据的同步与共享。[10-11]
通过数据交换平台,将不同的数据结构和数据格式转换成统一的、便于应用的形式,包括数据的解密或解压缩、数据类型的转换、数据长度的转换等。为满足不同业务对数据的要求,在对数据进行重组分类的基础上,再应用数据挖掘技术进行分析与处理。以船舶减少油耗实现节能目标为例,进行船舶数据挖掘与研究,研究对象除船舶航行数据外主要是机舱监测数据。此外,为简化船舶营运过程中的油耗分析和得到精确的决策规则,收集的是排除了特殊航行状态(如船舶抵离港、在港靠泊、锚地锚泊等)后两个连续挂靠港口间的船舶数据。
2 数据挖掘中的k均值聚类算法
数据挖掘是通过分析大量数据揭示新的关系、趋势和模式的过程,其主要任务是对数据库中的大量业务数据进行抽取、转换、分析和模型化处理,从中提取可辅助决策的关键性数据和隐藏的预测性信息。通过数据挖掘,能发掘数据间潜在的模式,找出可能忽略的信息,以可理解和观察的形式反映给用户,并给出基于知识的决策分析意见和结论。[12]
聚类算法是数据挖掘中的一个重要研究领域。聚类是一种常见的数据分析工具,其目的是把大量数据点的集合分成若干类,使得同类中的数据最大程度地相似,而不同类中的数据最大程度地不同。聚类的实质是将性质相似的点聚在一起,以发现其中的规律。基于划分的方法是最常用的聚类分析方法之一,k均值聚类算法是其代表算法。[13]
k均值聚类算法又称基于k-means聚类算法,在数据挖掘领域中得到了广泛应用。k均值聚类算法给定一个例子的集合X(其中包括n个数据对象),并将数据对象划分为k个聚类(k≤n),通常会采用一个划分准则(称为相似度函数),以使同一簇中的对象是相似的,而不同簇中的对象是相异的。k均值聚类算法的处理过程是:对于给定的一个包含n个d维数据点的数据集X={x1,x2,…,xi,…,xn}(其中xi∈Rd)以及要生成的数据子集的数目k,k-means聚类算法将数据对象组织为k个划分C={ck,i=1,2,…,k},每个划分代表一个类ck,每个类ck有一个类别中心μi。选取欧氏距离作为相似性和距离判断准则,计算该类内各点到聚类中心μi的距离平方和J(ck)为
(1)
(2)
式(2)中:若xi∈ci,则dki=1;若xi∉ci,则dki=0。
显然,根据最小二乘法和拉格朗日原理,聚类中心μk应该取为ck类各数据点的平均值。
k均值聚类算法从一个初始的k类别划分开始,将各数据点指派到各个类别中,以减小总的距离平方和。该算法是一个反复迭代过程,目的是使聚类域中所有的样品到聚类中心距离的平方和J(C)最小,算法具体流程见图1。
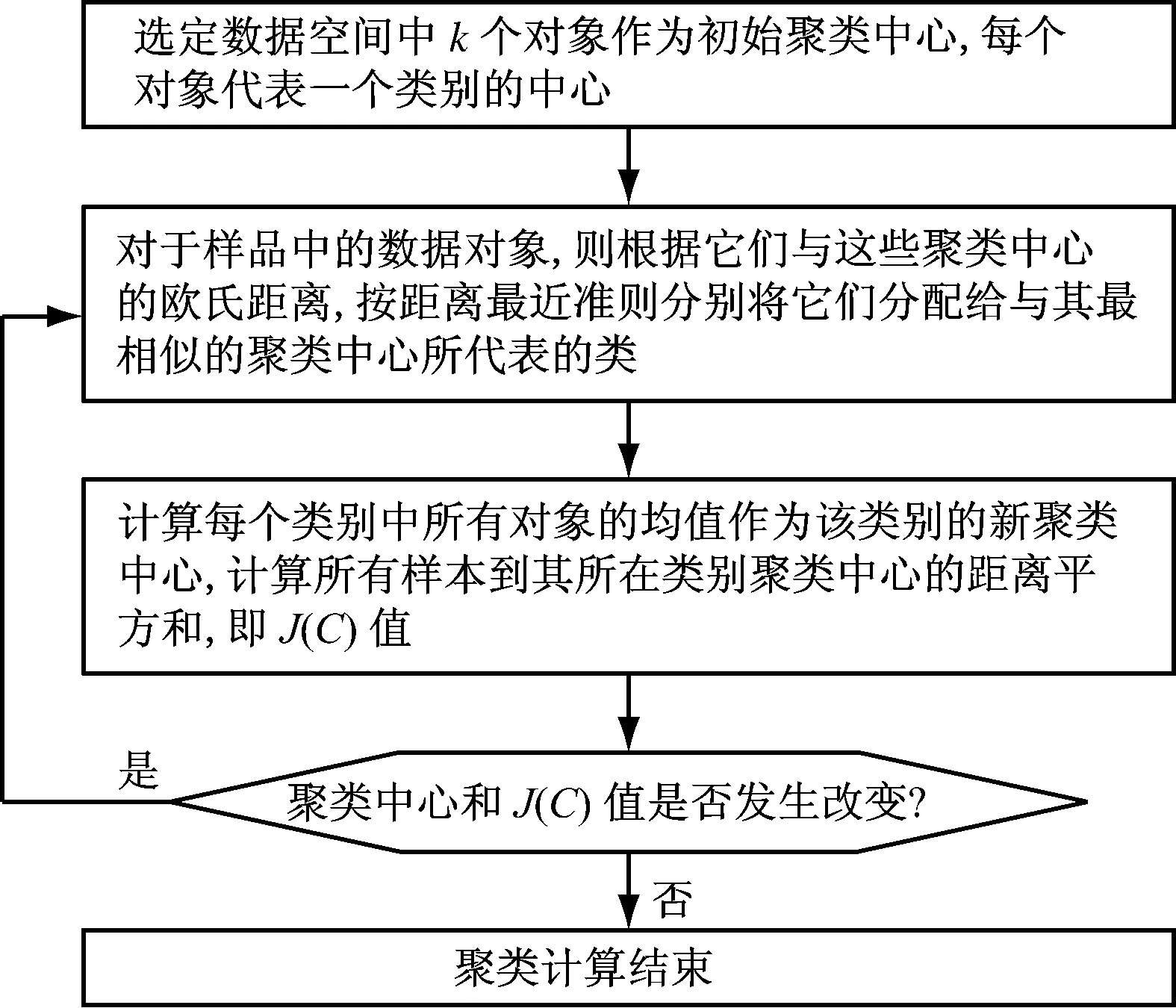
图1 k均值聚类算法流程图
实践中,着重发掘与主要因素相关的船舶运行特性与规律。k均值聚类算法需要用户提前输入聚类作业所要形成簇的数量,即k值。k值的选取对聚类的结果具有很大影响,通过调整k值评价不同的可能性。k均值聚类算法的优势在于能够挖掘出包含多个属性信息的潜在趋势,可用于识别特定情况与趋势,但结果分析需要基础资料的支撑。
3 数据挖掘聚类算法在船岸一体化平台实现船舶节能功能中的应用
3.1在船岸一体化平台中数据挖掘聚类算法的基本程序
1) 针对船岸一体化平台收集的船舶数据,把船舶节能作为研究目标,明确数据挖掘的要求与任务。
2) 对船舶数据采集与监控系统收集的数据进行清洗,即对原始数据进行加工(一般包含数据标准化、数据平整、丢失数据处理、时间相关数据处理以及异常数据的分析和处理等),以生成用于数据挖掘的数据库。
3) 采用k均值聚类算法实施数据挖掘任务,从船岸一体化平台的大量数据中寻找船舶主机高效(率)数据集(簇),在各聚类中心点(簇的中心点)与负荷的对应关系上建立基准值模型;针对所属类别,设计或选择有效的算法,实施数据挖掘。
4) 对挖掘结果进行解释、评估与优化。
5) 通过分析、整理,将结果输出到航运管理实际工作中,为决策提供依据。
3.2船舶油耗数据的预处理
为处理模糊和不确定知识,将粗糙集理论作为数据挖掘的数学工具,把研究对象的属性分为决策属性和条件属性。在对船舶营运油耗的研究中,决策属性采用的是船舶主机日耗油量与日累积航程的比值,称作单位航程油耗。而影响耗油的可能条件属性有:
1) 船舶因素:船舶种类与大小、装载状态、船舶吃水和吃水差、船舶稳性与摇摆性、船壳状况等。
2) 机器因素:主要指船舶主机、副机、锅炉等装备及其性能、技术状态等。
3) 燃油因素:主要指燃油品质与性能等。
4) 环境因素:风、流、浪和天气状况等。
5) 操纵因素:航向、航速和主机转速等运转工况。
在船岸一体化平台中,采集的数据来自于公司所属的各船舶。由于公司同系列船舶在船舶、机器等方面存在许多相似的属性,应用数据挖掘技术具有更丰富、科学的数据基础。这也是利用船岸一体化平台进行数据挖掘的有利条件。
在进行油耗分析前,需将油耗相关数据转换为船舶油耗信息系统的形式,以确定条件属性和决策属性。由于船岸不同的软硬件设备,数据结构各异,可能造成彼此不能识别对方的数据。因此,需对数据进行标准化。同时,设备故障或其他因素可能导致个别船舶数据不确定或缺失的现象,需对经典粗糙集理论进行扩充,以适应不完备的信息系统。
3.3建立基准值模型
对某一具体船舶节能而言,在一定负荷和环境参数下,单位航程油耗最小时对应的主机工况为最佳工况,在此工况下,主机效率及相关运行监控参数称为参数基准值。采用k均值聚类算法,在大量数据中寻找船舶机器高效数据集(簇),利用各聚类中心点(簇的重心点)与负荷的对应关系建立基准值模型。随后,对船舶主机运行数据进行分析,寻找各负荷工况下船舶主机的高效运行工况,将其对应的运行参数作为基准值建模的样本数据,并确定其基准值模型。[14]
选择船舶主机功率、单位航程油耗和主机转速3个属性进行分析。
1) 将主机功率分成N个区间,如果一个区间的点数太少,则与相邻的区间合并,这样就保证了每个主机功率区段有足够多的记录。
2) 对每个区段的点进行聚类,找到各簇数据对应的聚类中心中单位航程油耗最小的一簇数据,其聚类中心对应的主机功率和主机转速就是要找的一个基准值样本点。
3) 对每一个主机功率区间进行相同的操作,直到找到所有划分区间的样本点。
4) 将样本点进行正交曲线拟合,得到主机转速的基准值模型。
3.4实施数据挖掘
为方便说明,以某公司对3 590 TEU同系列全集装箱船采集的数据为例,对通过数据挖掘聚类算法实现船舶节能的目标作详细描述。
1) 采集船舶主机功率、单位航程油耗和主机转速3个属性参数的所有数据,在对数据预处理后,把该类船舶正常航行时主机功率在10 000~22 000 kW内的所有有效数据生成用于数据挖掘的数据库,并以每2 000 kW划分主机功率区间,共把数据分为6个区间。
2) 采用k均值聚类算法对主机功率在各个区间的单位航程油耗进行聚类分析,并列出聚类分析结果,其中主机功率在14 001~16 000 kW的聚类分析结果见表1。
在完成聚类分析后,从分析结果中找出单位航程油耗最小的一类,如果该类又包含足够多的数据记录,则可被认定为主机功率在该区间的一个样本点。例如在表1中,可认定Cluster-5为主机功率在14 001~16 000 kW的一个样本点。对其他功率区间依次类推,得到船舶主机功率在各区间对应单位航程油耗最小的样本点集合(见表2)。
根据表2,以主机功率、转速分别为横、纵坐标作样本点位置图(见图2),从图中可直观地发现船舶单位航程油耗最小时主机功率、转速的变化规律。公司根据船岸一体化平台的数据挖掘处理结果,获得同类型船舶在具体航次承受不同负荷下为实现船舶单位航程油耗最小可采用的主机转速,再把该运行工况应用于其他同类型船舶的航行实践中。
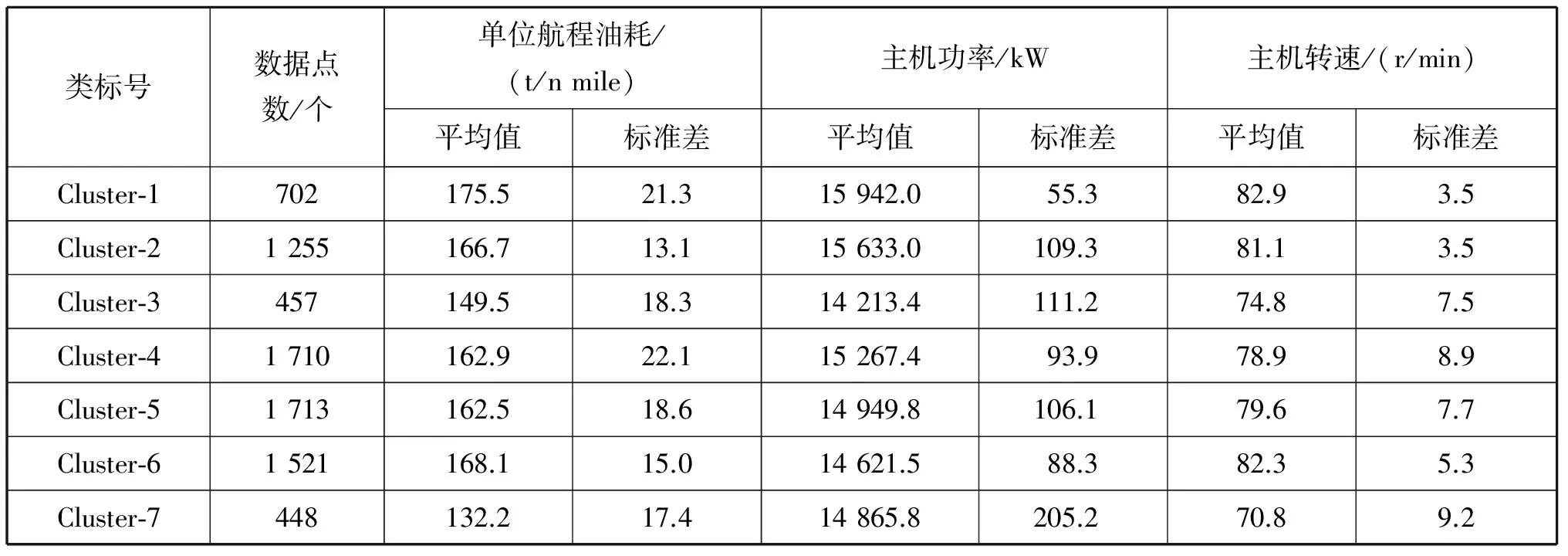
表1 主机功率在14 001~16 000 kW下的船舶主机转速聚类分析结果
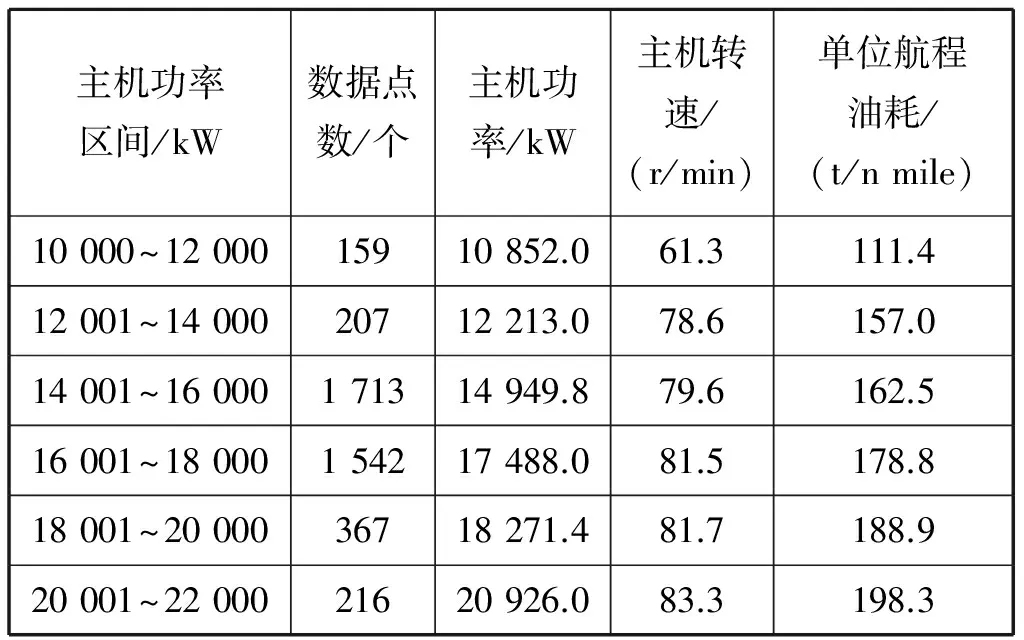
表2 主机功率各区间对应船舶单位航程油耗最小的样本点
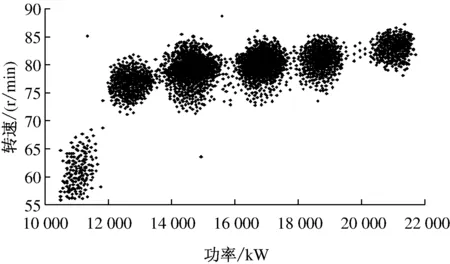
图2 样本点位置图
3.5评估优化与结果应用
从数据挖掘结果可以看出,船舶在每个主机功率区段采用对应主机转速的条件下,该样本点的单位航程油耗最小,与基准值定义的高效运行工况的定义是一致的。船舶在海上航行时,如果受风影响,单位航程油耗将会受到较大影响。海上天气对船舶单位航程燃油消耗的影响主要是通过影响船舶航程和航速产生的。增加主机转速和航速也会提高船舶单位航程的燃油消耗。为降低单位航程油耗,在实践中通常运用良好的船艺,通过调整、控制和稳定船舶航向,并采用数据挖掘处理得到一定主机功率下相对应的主机转速,实现船舶节能的目标。
4 结 语
鉴于数据挖掘技术的人工智能特征和针对复杂数据的处理能力及其已在多个行业的分析预测中取得的良好效果,提出在船岸一体化平台中利用数据挖掘技术对数据进行处理以辅助管理人员决策分析的思想。结合船舶节能实例,运用k均值聚类算法挖掘出影响船舶节能因素的潜在规律,给管理决策提供信息支撑,为航运公司提高船舶营运效率、降低营运成本提供科学依据。船舶营运油耗是一个受多因素影响的综合性过程,采用数据挖掘聚类算法研究分析船舶节能问题,为更好地发挥船岸一体化平台功能提供了一个新的思路。
[1] 殷瑞飞.数据挖掘中的聚类方法及其应用[D].厦门:厦门大学,2008.
[2] 郑滨,陈锦标,夏少生,等.基于数据挖掘的海上交通流数据特征分析[J].中国航海,2009,32(1):60-63.
[3] 牟军敏,邹早建,齐传新.数据挖掘技术在内河交通事故分析和预防中的应用[J].中国航海,2004,27(1):27-29.
[4] 朱飞祥,张英俊,高宗江.基于数据挖掘的船舶行为研究[J].中国航海,2012,35(2):50-54.
[5] 潘家财,邵哲平,姜青山.数据挖掘在海上交通特征分析中的应用研究[J].中国航海,2010,33(2):60-62.
[6] 朱飞祥.远洋船舶调度数据挖掘技术研究与应用[D].大连:大连海事大学,2008.
[7] 岳跃申,郑士君,黄爱平.新型船岸一体化管理平台的设计及其功能[J].航海技术,2009(9):70-72.
[8] 汪益兵,聂建涛.基于嵌入式技术的船岸一体化管理平台设计与开发[J].上海海事大学学报,2013,34(4):23-26.
[9] 蔡晔敏,周亚兰,朱蕊.船舶自动化系统网络的设计进展[J].上海工程技术大学学报,2010,24(2):142-144.
[10] 韩建锋,陈星.嵌入式船舶数据采集与监控系统[J].仪表技术与传感器,2008(8):61-62.
[11] 薛明刚,徐承飞,赵卫丽,等.船岸一体化数据同步的实现[J].中国修船,2011,24(1):21-24.
[12] 刘同明.数据挖掘技术及其应用[M].北京:国防工业出版社,2001.
[13] 行小帅,焦李成.数据挖掘的聚类方法[J].电路与系统学报,2003,8(1):59-67.
[14] 钱瑾,王培红,李琳.聚类算法在锅炉运行参数基准值分析中的应用[J].中国电机工程学报,2007,27(23):71-74.
ApplicationofClusteringAlgorithmforDataMininginShip-ShoreIntegrationPlatform
WANGYibing,WANGJie,XUXianwen
(Zhejiang International Maritime College, Zhoushan 316021, China)
Ship-shore integration platform performs ship tracking, data acquisition and processing, and management services. The large amount of data collected in ship-shore integration platform shows a complex relationship and the data mining technique is necessary for extracting knowledge and discovering laws from data and timely supporting decision making. The data acquisition process of the platforms and their requirements for the information as well as some concepts of data mining are introduced. The practical application ofk-means clustering algorithm aiming for energy saving is illustrated. This study demonstrates a new approach of developing a ship-shore integration platform.
waterway transportation; data mining;k-means clustering algorithm; ship-shore integration platform; ship energy saving
2013-12-22
浙江省公益性技术应用研究计划项目(2013C33084)
汪益兵(1970-),男,浙江兰溪人,副教授,船长,从事航海技术、交通运输管理研究。E-mail:zimcwyb@126.com.
1000-4653(2014)02-0122-05
TP311.13
A
猜你喜欢
价值工程(2023年33期)2023-12-13 01:24:56
车主之友(2022年5期)2022-11-23 07:22:20
小哥白尼(军事科学)(2022年7期)2022-09-20 03:51:34
数字技术与应用(2020年5期)2020-08-04 09:50:33
海峡姐妹(2019年5期)2019-06-18 10:40:34
电脑知识与技术(2018年11期)2018-07-28 07:19:12
百科探秘·航空航天(2017年12期)2018-01-31 02:31:24
上海铁道增刊(2017年3期)2018-01-22 03:01:18
车迷(2017年12期)2018-01-18 02:16:10
航海(2016年2期)2016-05-19 03:57:11
