
分布式大数据树形处理架构在犯罪预测方面的应用研究
2014-11-20 10:03:28万雪勇雷鹏程
江西警察学院学报 2014年5期
朱 峰,万雪勇,雷鹏程
(1.吉安市公安局网安支队,江西 吉安 343000;2.江西警察学院,江西 南昌 330103;3.江西省公安厅网络安全和技术侦察总队,江西 南昌 330006)
我们面对的大数据由大量的各种各样的数据库构成,数据库是由一张张数据表组成,大数据是由看则无限实则有界的数据表铺接成的数据地球。 站在数据地球之外来看, 我们需规划管理好各地的数据库,身在数据地球之中来讲,则需分布式交通和枢纽来遍及整个数据地球。 因此我们设计了以地域来划分,以服务接口为连接点的分布式大数据处理架构。
我们将分布各地的数据库称为离散数据库或数据库集群, 该架构物理上是一种以大数据处理中心为根、总线与接口为枝、各离散数据库和数据库集群为叶的树形结构。 基本原理是由大数据处理中心统一协调下发任务, 以各离散数据库预建的数据源产生地区索引为基础, 通过大数据处理的词义模型来挖掘大量数据中潜在的价值信息。 大数据时代很多情况下难以预先确定模式, 模式只有在数据出现之后才能确定, 且模式随着数据量的增长处于不断的演变之中,[1]大数据处理的词义模型跨越了大数据模式和数据的关系的障碍, 体现了该架构对不同数据库或者说数据模式的包容性, 而包容性是未来超大规模大数据处理的核心内容与研究方向。
本文将探讨基于面向服务可包容的分布式大数据树形处理架构在犯罪预测方面的应用。
一、 基于面向服务可包容的分布式大数据树形处理架构
研究大数据必须以理清数据源头为基础, 数据本身在一定程度上会受数据源头的特点所影响,数据模式又与不同数据库的结构相联系, 数据源是由产生的数据信息的设备来区分。 数据模式不能限制,然后以数据源来划分,即数据源产生地域来区别,可以将数据归类为相应有限的区块。 同一数据库有多地数据,将以数据的来源,如产生数据的IP 源归属或其他方法按省、市、县来建立数据区域索引。
这种分布式大数据树形处理架构主要包括以下几个模块:
(一)数据服务接口
1.XML 查询端。 XML 查询端,使用统一的XML语言编码,此端工作对象是各数据库或数据库集群,功能是访问查询指定数据库和在指定数据库中建立以IP 当前归属地为内容的索引(索引表通过IP 字段的自动检索建立, 也可手动根据具体情况数据源产生地来划分添加)。
2.XML 控制端。 接口统一标准以提供总线通过接口访问查询指定数据库, 以完成大数据处理中心下发的数据挖掘查询任务。
(二)数据的分布式并行处理
大数据处理中心通过总线和预先设置好的数据服务接口,按照指定命令分解任务,向有关联的各地数据库下发分任务, 各地数据库服务器可同时分别处理所接收的任务要求, 并将结果通过数据服务接口和总线反馈到大数据处理中心。
(三)大数据处理的词义模型
大数据处理的词义模型也是一种大数据需求型研究模型。 按区域划分以分类关键词为线索关联到离散数据库的表中记录的有关信息。 总的概要关系如图1 所示。
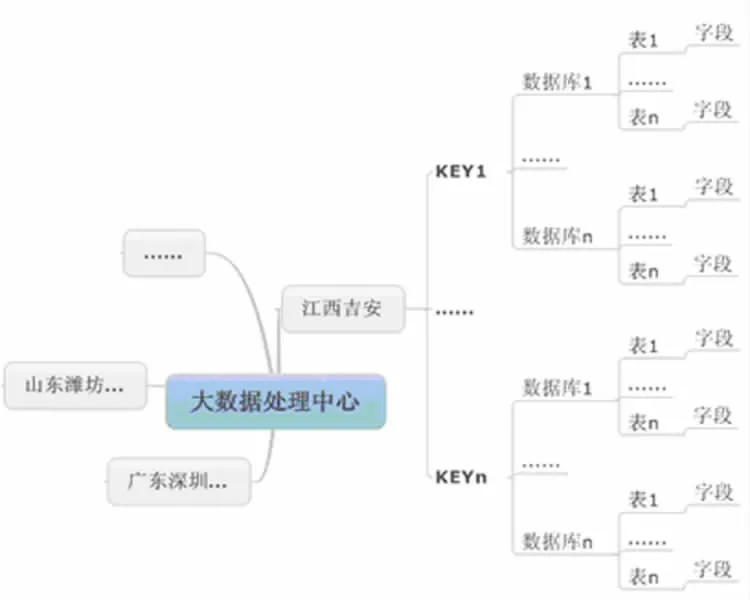
图1 大数据处理关系图
1.大数据需求研究模型
(1)大数据需求权重研究模型。 大数据需求研究模型必须考虑需求影响, 我们将某地区与需求内容(通常指某一需预测的已知事件) 关系度定义为S,S对大数据的研究模型的影响贯穿始末。 需求因子S映射出与S 密切影响的其他的关系因子量m1-…mn,Z(mi)为各因子量的出现概率,每个关系因子的影响度不一样,我们为之定义一个关系系数权重b1-…bn(注:bi = 1,1≤i≤n)。 这样我们就得出大数据需求研究模型权重计算公式:
S= Z(m1)b1+…+ Z(mn)bn 即S= bi* Z(mi)
通过这个公式可以计算出某地区与需求内容即某一事件的关系强度, 关系强度和评分一样可按百分比显示, 五级标注,80%-100%为一级,60%-80%为二级,40%-60%为三级,20%-40%为四级,20%以下为五级。[2]关系越强出现该需求内容的概率越大。
此权重计算公式针对一种相对的关系强度计算,在预测事件发生方面具有简便易操作的优点,但精确度不高,在粗略预测使用中较为合适。
(2)大数据需求全概率研究模型。 大数据需求全概率研究模型比权重研究模型具有较高的精确度和正确率,计算相对其也较复杂。 具体计算方式在下面大数据处理的词义模型中详细阐述。
2.大数据处理词义模型
(1)大数据处理词义模型的基本原理。 大数据处理的词义模型是建立在大数据需求研究模型之上通过词组分割、词义关联、逻辑转换获得多个关键词字段为各关系因子来进行大数据处理研究的模型。 该模型的方式是将大数据传统处理挖掘方法化归为处理大数据关键词信息的方法。
(2)关键词因子的筛选。 通过各种方法获得大量有关的关键词因子数据集合, 但其数量太多会增加研究的复杂性。 所以要筛选出尽可能少的关键词因子,且尽可能全地反映我们需求的结果状态。 关键词因子数据集合中的项集存在性往往存在着一定关系, 这些项与项之间的关系异于挖掘算法里的关联关系,它们的相关关系是基于概率模型下的相关。[3]我们可通过主成分分析法 (principal component analysis) 将关键词因子间有相关关系的进行初步筛选,令剩下的关键词因子在表面上两两不相关,达到数据降维效果以降低研究难度和成本。
(3)大数据处理词义模型的全概率计算方式。 把需求内容即某事件用S 来表示, 产生该事件的有关原因事件A1-…An ,原因事件发生的概率通过以往数据计算为P (An)(原因An 对S 事件发生的影响度为P(B/An)),通过一些事件的逆向历史统计调查,发现原因事件与相应的关键词的出现量成正比。 设An原因事件对应的关键词为Kn,设定某地区某时间段产生关键词Kn 有效次数量(排除重复量、错误量、干扰量) 与所有地区在该时间段产生该关键词有效次数量的比值为Z(Kn),通过大量历史数据计算出这个值和原因事件发生概率P(An)偏差系数为ξn。因此P(An)= Z(Kn)ξ,将此结果套入全概率公式可得公式:
事件S 发生的概率P(S)= P(S/Ai) Z(Ki)ξi
对各数据中反映关键词Kn 有效次数量的复杂重复量排除中, 我们可以参考2010 年PVLDB 全球数据库顶级会议上介绍的一种对多数据源同步复制、传递复制的检测算法,[4]结合利用隐马尔可夫模型来识别有关数据复制造成的重复量。
(四)大数据处理中心
大数据处理中心是由各种功能服务器组成的服务器集群,包括若干专项功能服务器,是进行任务下发、任务分析、任务收集、任务研判、错误纠正、实时监测的大数据处理架构中心。
1.离散数据库资料服务器。记录各地离散数据库的有关信息与分类备注, 并实时监测各数据库的有关状态,通过各地数据库与服务接口地址,定期检测数据库的运行状态,并记录反馈结果,实时更新数据库备案资料, 以及记录保存各离散数据库在完成大数据处理挖掘中的工作资料。
2.IP 实时分配信息服务器。 该服务器中,建立了IP 统一规划库,实时跟踪IP 的重新分配情况。 并记录IP 每次重新分配的时间段和归属地。 为区别离散数据库中的数据源产生地的归属提供可靠信息支撑。 各离散数据库在新建数据源归属索引时可以根据IP 和时间段,来划分归属。 为每个IP 在某时间段的使用地建立档案,并以不同序号识别,同一IP 因多次调整跨县市分配都有不同的序号标注记录,并且该IP 序号同时写入在离散数据库的数据源归属索引中。
3.任务分配研判服务器。其按照每次大数据挖掘处理任务的具体需求,进行任务划分,并下发到各地的离散数据库所在服务器和其他有关给任务提供支撑的服务器, 并对反馈的信息根据预设模型进行分析研判为各类决策活动提供有价值的信息。
4.异常识别纠错服务器。实时跟踪处理各地分任务的完成情况,统一汇集处理分析结果,并记录错误实时反馈修正。如当出现归属误差等错误时,通过IP分配序号可以及时找到需要修改的离散数据库中的索引信息,以及时修正错误。 根据离散数据库服务器中的有关数据库实时信息识别数据库异常状态,针对性连接访问有关异常数据库进行全面核对检查,并将结果反馈到离散数据库资料服务器。
二、在犯罪预测方面的应用研究
犯罪预测,就是运用科学的理论和方法,通过调查、统计、比较、处理有关犯罪的数字和资料,分析研究犯罪的规律,对未来犯罪现象的种类、数量、发展趋势等进行的推测和估计。[5]犯罪预测的方法非常多,如:专家预测法、相关因素分析法、统计学的方法、概率论的方法、模糊数学预测法等。 犯罪预测已被公认为犯罪学理论体系中重要的组成部分, 是犯罪预防必不可少的前提条件。
大数据处理词义模型特别适合区域型事件发生概率的预测工作, 在打击违法犯罪工作方面可以通过统计计算区域各类违法犯罪的扩散趋势与未来发案率, 为各类违法犯罪特别是信息安全方面犯罪的防范、控制、侦破提供有效的数据情报支撑。
微博犯罪预测就是大数据处理词义模型的应用。 带地理位置标签的微博预测犯罪,通过大量的历史犯罪记录和地理位置信息进行相关分析, 具体是通过微博博文当时谈论的热点, 或某一类群体某一时刻谈论某类热点关键词, 与这之后这一地区发生某类犯罪情况,得到他们之间的匹配度,利用前面所述关键词因子筛选方法和概率计算方式预测出该地区未来会发生犯罪或某类犯罪的几率。
另一类常见的是搜索引擎犯罪预测。 通过大量历史数据分析不同地区,在某一段时期,检索某类关键词的频率和之后这一地区发生某类犯罪匹配情况, 利用关键词因子筛选法选出一系列有效检索关键词, 并计算出这些关键词因子与某类犯罪事件发生的影响系数等相关参数。 我们可将当前这些检索关键词出现的频率和提交这些关键词区域进行概率分析,获知未来该区域发生某类犯罪的可能性大小。
大数据处理词义模型用于犯罪预测已越来越多的出现在国内外各警察机构。 美国已经有超过10 个城市的警察局引入了大数据处理算法,包括洛杉矶、波士顿和芝加哥等, 洛杉矶警察局利用大数据处理及分析软件成功地把辖区里的盗窃犯罪降低了33%, 暴力犯罪降低了21%, 财产类犯罪降低了12%。 北京怀柔公安局使用的“犯罪数据分析和趋势预测系统”,是典型的大数据处理模型在犯罪分析及预测方面的应用, 该系统的应用使怀柔公安局辖区内的龙山、泉河、怀柔镇派出所2013 年刑事案件发案率分别下降了10.7% 、9.3% 和8.8% 。
三、总结
大数据具有多源异构、分布广泛、动态增长、无固定模式等特点, 大数据时代的到来为我们的公安工作带来了深刻的影响, 犯罪预测作为预防犯罪的重要前提,在大数据时代将会有长足的发展。
我们研究了一种基于面向服务为功能基础的,按区域树形分布式并行处理大数据的体系架构,并将其词义处理模型用于犯罪预测, 在吉安市公安局网安支队做了有益的尝试,取得了一定的成果。
[1] 孟小峰,慈祥.大数据管理:概念、技术与挑战[J].计算机研究与发展,2013,(1):146-169.
[2] 朱峰,刘捷,李军.远程勘验取证分析软件开发与实现[J].信息网络安全,2011,(11):73-74.
[3] 李海峰,章宁,柴艳妹.不确定性数据上频繁项集挖掘的预处理方法[J].计算机科学,2012,(7):161-164.
[4] Xin Dong, Laure Berti-Equille,Yifan Hu, Divesh Srivastava. Global Detection of Complex Copying Relationships Between Sources[J]. Proceedings of the VLDB Endowment,2010,3(1-2):1358-1369.
[5] 康树华,张小虎.犯罪学[M].北京:北京大学出版社,2004:187.
猜你喜欢
心理学报(2022年4期)2022-04-12 07:38:02
水泵技术(2021年3期)2021-08-14 02:09:20
西夏研究(2020年1期)2020-04-01 11:54:26
新高考(英语进阶)(2018年3期)2018-05-14 07:38:00
计算机与生活(2018年3期)2018-03-12 08:38:11
中国科技期刊研究(2017年2期)2017-05-14 06:16:26
中国惯性技术学报(2015年1期)2015-12-19 13:12:17
浙江大学学报(工学版)(2015年2期)2015-05-30 07:05:04
语言与翻译(2014年3期)2014-07-12 10:31:59
土木建筑工程信息技术(2013年4期)2013-10-17 02:27:54
