
基于语义相似度计算的Deep Web数据库查询*
2014-11-10 07:10:04夏海峰陈军华
网络安全与数据管理 2014年8期
夏海峰,陈军华
(上海师范大学 计算机系,上海200234)
在当今信息时代,万维网成了主要的资源。随着万维网的飞速发展,使得其在全球网络中所占的比重越来越大,其内部涵盖的信息也越来越丰富。然而对于其内部所包含的Deep Web,却没有被很好地开发和利用。根据Bright Planet对 Deep Web统计而发布的白皮书[1],截止到2011年,共有600万个中文万维网数据库,并且每天都以指数级的速度增长。传统意义上的万维网数据搜索只能通过查询接口(即HTML表单)被用户访问,用户得到的反馈内容也仅仅局限于查询接口与后台数据库交互之后生成的查询页面内容。
基于当前中文Deep Web数据库的研究现状,本文提出了基于语义相似度计算的中文Deep Web数据查询方法。该方法旨在通过基于计算关键词和属性词典之间的语义相似度,将用户查询的关键词映射到具体的领域,最大程度地缩减数据库的查询范围,最终提高查询的效率。对于Deep Web数据库,本文采用数据集成技术[2],将同一领域的数据库表结构采用标签的形式,形成对应的属性词典,从而实现前后台的无缝连接。
1 理论基础
1.1 知网体系
知网(HowNet)是一个以汉语和英语的词语所代表的概念为描述对象,以揭示概念与概念之间以及概念所具有的属性之间的关系为基本内容的常识知识库。其体系架构如图1所示。知网体系包含丰富的语义知识和相关本体知识。在知网中,所有词汇的概念都是基于以下两个主要概念:
(1)概念。它是对词汇语义的一种描述,每一个词可以表达为几个义项。义项是用一种知识表示语言来描述的,这种知识表示语言所用的词汇叫做概念。
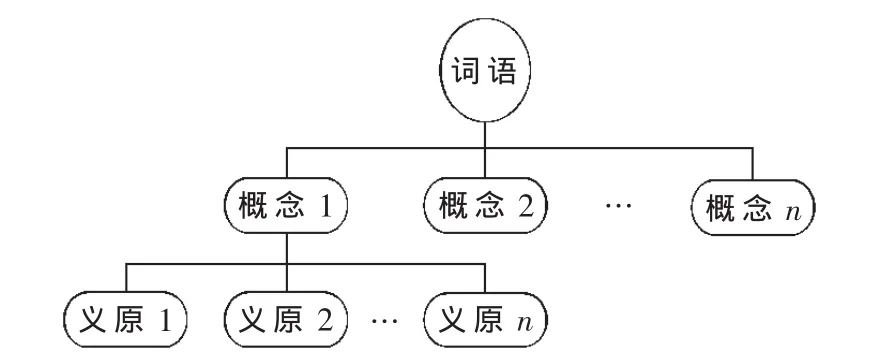
图1 知网体系架构
(2)义原。它是用于描述一个概念的最小意义单位,从所有词汇中提炼出的可以用来描述其他词汇的不可再分的基本元素。
在知网体系中,每个词汇都由一个四元组W_C=词语;E_C=词语例子;G_C=词语词性;DEF=概念定义)表示而成,并且在知网体系中,它并不像同义词词林那样将所有的概念归结到一个树状的概念层次体系中,而是每一个概念都是由义原采用四元组的形式加以表示。图2显示的是关键词“北京”基于知网的语义表示形式。
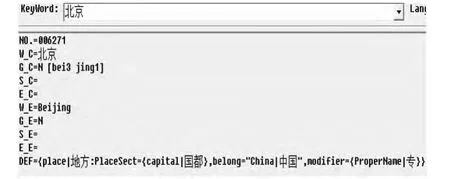
图2 关键词“北京”
1.2 属性词典
在Deep Web数据库中,本文引入了属性词典的概念[3]。事先在数据库中创建一个属性词典(称之为Attr-Dict表),该表的作用在于保存数据库中每一张表结构的字段和对于该字段的详细解释。该属性词典主要用于计算关键词和后台数据库属性列之间的语义相似度。
该AttrDict表的表结构如下:
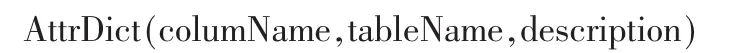
其中,字段columName为数据列名,字段tableName为对应的表名,字段description为属性对应的描述。
在本文的数据源中,假定其中的两张表如下:

则对应的AttrDict表对应的字段如表1所示。
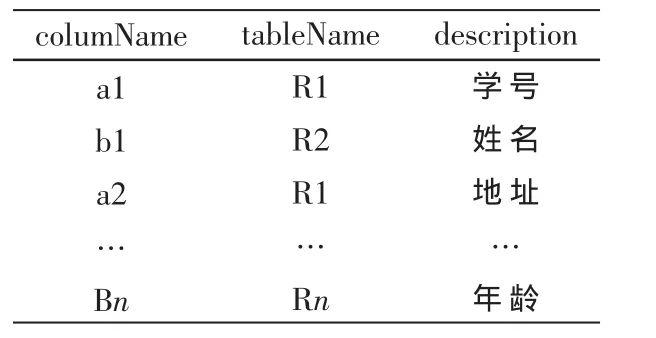
表1 属性词典表结构示例
2 语义相似度计算方法研究

图3 基于语义相似度计算Deep Web数据库查询
本文在计算关键词[4-5]的语义相似度时,采用基于词语相似度的计算方法,其流程如图3所示。计算出当前关键词和属性词典每个属性列的相关联程度,设定一个起初的阈值,当相似度计算所得结果大于该阈值时,认为当前属性列对应的领域即是当前关键词对应的领域R,这样也就确定了关键词K和属性列之间的对应关系,从而确定对应的表结构的字段集合C,最终根据生成的一个完成的SQL查询语句,将查询的结构反馈给用户。
基于HowNet的词语相似度[6]充分利用了 HowNet对每个概念描述时的语义信息,但没有考虑到在信息检索过程中关键词的相关词的语义相似度,这样可能减少实际上关键词的相关词的检索范围。基于以上观点,本文提出了一种改进的词语相似度计算方法[7],主要工作如下:
(1)首先利用词林(哈工大版)[8]获得当前关键词的相关词集合;
(2)基于HowNet获得相关词集合的每个相关词的概念定义(DEF);
(3)利用知网计算相关概念词集合词语和属性词典的概念相似度。
2.1 预处理关键词
定义1 利用词林(哈工大版)寻找相关词,形成相关词集合,用下面一个4元组构成:

定义2 关键词概念定义(DEF)用下面一个5元组构成:
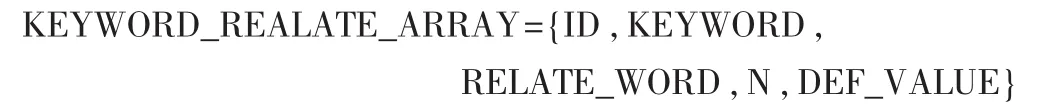
其中,ID表示单标识符,由系统自动赋予并唯一表示;KEYWORD表示当前检索系统提交的关键词;RELATE_WORD表示通过词林获得关键词的相关词;N为正整数,表示提交表单中概念定义属性的个数;DEF_VALUE为概念定义属性名/值对集合,用来表示当前关键词的概念定义的详细信息,其个数为N。
2.2 相似度计算方法
(1)词语相似度:
假设现有两个词语A1和A2,A1由m个概念组成,A2由n个概念组成,如下表示:

[6]认为两个词语的相似度,也就是两个词语的概念的任意组合的相似度的最大值。其计算采用的是最大值匹配法,公式如下:

(2)概念相似度
参考文献[6]把对义项的描述分为4类:第一基本义原描述、其他基本义原描述、关系义原描述和关系符号描述。假设义项C1有m个义原,C2有n个义原,如下式所示:

则对于义项C1、C2之间的相似度可以用义原的相似度加以描述:
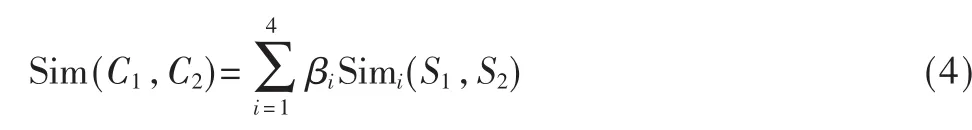
Sim1(S1,S2)表 示 第 一 义 原 的 相 似 度 ,Sim2(S1,S2)表 示其他基本义原的相似度,Sim3(S1,S2)表示关系义原描述的相似度,Sim4(S1,S2)表示符号义原的相似度,并且 β1+β2+β3+β4=1。
(3)义原相似度
HowNet是一个具有网状结构的世界知识库,义原相似度要利用义原间的上、下位关系来构造一种树状结构的义原层次体系,通过树中各个义原节点之间的相互关系来计算。许多学者在这方面进行了大量的研究,其中被广泛认可的是中科院刘群等人的公式:

2.3 基于相似度计算的匹配算法
定义 3 对于给定的阈值 E,如果 Sim(A,B)≥E(Sim为计算相似度的方法,详见2.2节),则认为关键词相关词A和数据库列属性概念描述B相匹配,Match(A,B)=1;否则 Math(A,B)=0,两者不匹配。
为了规则化处理,假设A和B都存放在单链表中,A的表头指针为 HeadA,B的表头指针为 HeadB,下面是关键词相关词A和数据库列属性概念描述B的匹配算法过程:
/*Threshold表示设定的阈值;r、s分别表示A、B两个单链表中要比较的节点;Delete(node)表示将当前节点从链表中删除*/

删除B中不满足条件的节点之后,剩下的都是和关键词满足一定相似度的列,基于此,下面给出了集成方法。

3 实验分析与说明
Deep Web蕴含了海量的数据,受客观条件限制不可能在整个深度万维网上进行实验,并且中文实验数据样本不多,为了简化起见,选择了上海师范大学某学院信息管理系统2012~2013年的数据进行测试,整个系统共包含20张表结构,数据量500 MB。实现的步骤主要分为以下3个部分:
(1)基于哈工大《同义词词林(扩展版)》计算关键词的相关词,获取过程如图4所示。
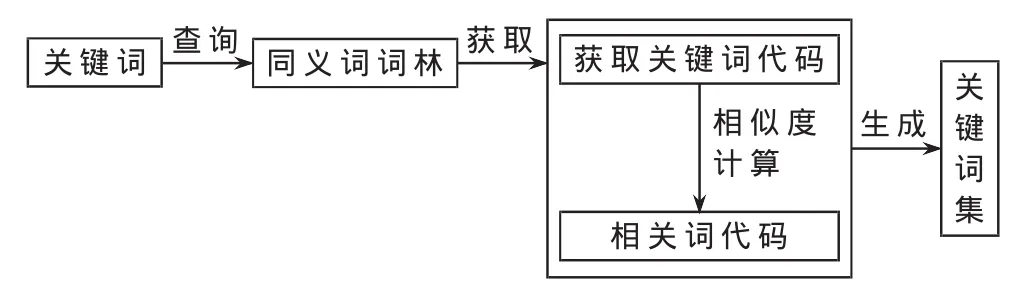
图4 基于同义词词林的相关词获取过程
输入关键词"北京"进行查询,获取"北京"的代码为"Di03A01=",根据参考文献[8]中相似度计算公式,得到与当前关键词处于同一层的关键词分别是:"Di03A01=:北 京","Di03A02=:都 城","Di03A03@:陪 都"。在同义词词林的定义中,“=”代表“相等”、“同义”,“@”代表当前该词语在同义词词典中既没有同义词也没有相关词,故本实验中,省去"Di03A03@:陪都"这一个基于同义词词林获得相邻的近义词。
(2)基于 HowNet获得关键词集合的概念定义(DEF)如表2所示,其中根据集合的原理,取其共同拥有的部分,则关键词集对应的DEF={地方,国都}。

表2 关键词集表
(3)基于本文提出的改进的相似度的计算方法,计算出关键词DEF集和属性词典对应属性列之间的语义相似度。
①创建后台数据库属性词典(AttrDict)
选取上海师范大学某学院信息管理系统后台表2个月的数据进行试验。根据要求,属性词典主要包含3个部分:表名、字段名和对应的描述文字,如表3所示。为了简便起见,选取其中的一张表member作为展示部分。
②相似度计算方法
由 DEF={地方,国都},根据HowNet逐个计算DEF值和当前AttrDict中每条记录的相似度,如图 5、图 6所示。
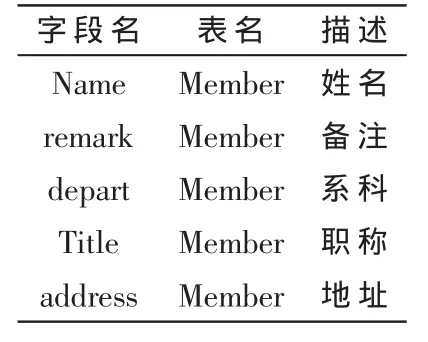
表3 属性词典表

图5 地方的相似度计算

图6 国都的相似度计算
根据事先设定的阈值E=0.5,当两个词语之间的相似度 表4 相似度计算结果表 ③限定对应的查询领域 由表4中相似度计算所得结果,证实“北京”这一词语可能与后台数据库对应的“备注”、“地址”的相关度很高,已无需查询所有的表结构了,只需要查询“备注”和“地址”列对应的数据,根据这一结果,动态生成相应的SQL查询语句,并将查询的结果返回给前台页面。 本文采用基于语义相似度的查询方法进行Deep Web数据库源的查询,较早地探讨了中文深网技术,宏观上提出了整体解决方案,并且通过实验过程验证了当前方法的可用性。本文是对Deep Web数据库相似度的一次初探,主要研究通过计算查询关键词和属性词典概念之间的相似度,从而降低全表扫描带来的系统资源的损耗,提高数据库整体查询效率。但是本文方法依然存在一些问题,下一步不仅应该深入研究相似度的改进算法,还要研究对于系统未登录词的处理,并将致力于做出全自动的属性匹配原型系统。另外,针对中文深网一整套解决方案实现原型系统也是未来工作的重点。 参考文献 [1]NOOR U,RASHID Z,RAUL A.A survey of automatic Deep Web classification techniques[J].International Journal of Computer Application,2011,19(6):43-50. [2]刘伟,孟小峰,孟卫一.Deep Web数据集成研究综述[J].计算机学报,2007,30(9):1475-1489. [3]冯磊,陈军华.数据库全文搜索方案的研究[J].上海师范大学学报(自然科学版),2010,39(2):153-155. [4]丁传羽,陈军华,夏海峰.基于关键词的深度万维网查询[J].计算机与数字工程,2013,41(4):616-618. [5]范举,周立柱.基于关键词的深度万维网数据库选择[J].计算机学报,2011,34(10):1797-1804. [6]刘群,李素建.基于知网的词汇语义相似度的计算[C].第三届汉语词汇语义学研讨会,台北,2002:59-76. [7]王小林,王义.改进的基于知网的词语相似度算法[J].吉林大学学报(信息科学版),2011,31(11):3076-3079. [8]田久乐,赵蔚.基于同义词词林的词语相似度计算方法[J].计算机应用,2010,28(6):602-605.
猜你喜欢
国际医药卫生导报(2022年18期)2022-09-29 01:29:00
小天使·一年级语数英综合(2020年4期)2020-12-16 02:56:32
开放教育研究(2020年2期)2020-03-31 01:54:14
文苑(2019年24期)2020-01-06 12:06:50
疯狂英语(双语世界)(2017年3期)2018-01-19 01:40:36
疯狂英语(双语世界)(2017年1期)2017-07-01 17:11:10
作文评点报·低幼版(2016年42期)2017-01-23 11:45:27
现代语文(2016年21期)2016-05-25 13:13:44
传奇故事(破茧成蝶)(2015年7期)2015-02-28 09:29:18
大连民族大学学报(2015年2期)2015-02-27 08:28:11
