
一种基于FP-growth的并行SON算法的实现
2014-11-10 07:10郭进伟皮建勇
网络安全与数据管理 2014年8期
郭进伟 ,皮建勇
(1.贵州大学 计算机科学与技术学院,贵州 贵阳550025;2.贵州大学 云计算与物联网研究中心,贵州 贵阳550025)
信息技术的高速发展使得各行各业累积了海量数据,如何从中提取有用的信息已经成为了数据挖掘所面临的巨大挑战。频繁项集是数据挖掘中一个非常重要的概念,Apriori算法[1]和 FP-growth算法[2]是挖掘频繁项集最为著名的算法,但其串行计算的复杂度较高。SON算法[3]为并行化发现频繁项集提供了解决思路。
谷歌于 2004年提出了 MapReduce编程模型[4],为并行处理和分析大规模的数据提供了重要的参考。根据MapReduce编程模型涌现出了众多的开源项目,其中A-pache基金会下的Hadoop[5]是其中比较有代表性的分布式并行编程框架。近几年随着大数据的兴起,MapReduce编程模型的研究[6]以及基于MapReduce的数据挖掘算法的实现[7]也愈加火热。
1 相关概念
1.1 FP-growth算法简介
FP-growth算法是Han Jiawei等人于2000年提出的发现频繁项集的算法,该算法采用分治策略将一个问题分解为较小的子问题,从而发现以某个特定后缀结尾的所有频繁项集。该算法使用了一种称之为频繁模式树FP-tree(Frequent Pattern Tree)的数据结构,FP-tree 是一种特殊的前缀树,由频繁项头表和项前缀树构成。
FP-growth算法发现频繁项集的基本思想是:根据FP-tree构造每个频繁项的条件FP-tree,每个频繁项都是一个前缀;每个前缀和其条件FP-tree的每一项合并生成一个新的前缀,根据此前缀继续生成条件FP-tree,直到生成的条件FP-tree为空;每一个前缀都是频繁的,即算法所得到的所有的前缀即为最终的频繁项集。
相比于Apriori算法,FP-growth算法有如下优点:(1)将较大的数据库压缩成了较小的数据结构保存在内存中,从而避免了反复扫描数据库,降低了扫描开销;(2)基于FP-tree的挖掘采用递归的方式搜索较短的模式并将其逐次连接起来,从而避免生成大量的候选项集;(3)将原本的挖掘任务划分成一组在有限的条件数据库中挖掘特定的频繁模式的任务,从而降低了搜索空间。
1.2 SON算法简介
Apriori算法通过迭代的方式来挖掘出所有的频繁项集,即候选(k+1)-项集的产生依赖于频繁k-项集,然后通过扫描事物数据集来计算出每一个候选(k+1)-项集支持度计数,进而判断得到频繁(k+1)-项集,因此该算法需要对事务数据集进行多次扫描。如果找到这样一种方法,通过该方法得到的候选项集包含了该事务数据集中所有的频繁项集,那么只需要对事物数据集扫描一遍即可找出所有的频繁项集。
以上为分区算法的核心思想。分区算法需要对事物数据集进行两遍扫描,第一遍扫描找出候选项集,此候选项集包含所有的频繁项集。第二遍扫描对所有的候选项集新型计数,其中大于最小支持度计数的候选项集即为频繁项集。
根据分区算法两遍扫描的思想,算法的执行分为两个阶段。在第一个阶段,算法把事物数据集划分为数个互不相交的分区,然后分别为每个分区计算出本分区的频繁项集(称之为局部频繁项集,此项集是潜在的整个事务数据集的频繁项集),最后把所有分区的频繁项集汇聚到一起就得到了整个事务数据集的候选项集(称之为全局候选项集)。在第二个阶段,为上一个阶段得到的全局候选项集进行计数,从而得到候选项集的支持度计数,其中大于最小支持度计数的候选项集即为全局频繁项集。以下为SON算法的伪代码,表1为伪代码中所用的符号定义说明。


表1 符号定义
伪代码中首先将事务数据集D划分为n个分区,阶段1分别对每一个分区pi通过gen_large_itemsets方法计算其局部频繁项集L′,该方法采用的是Apriori算法。在合并阶段,算法将每个分区局部频繁项集合并成一个全局候选项集CG。在阶段2中,算法计算每个全局候选项集的支持度计数,其中大于最小支持度计数minSup的为最终的频繁项集LG。
2 基于FP-growth的SON算法的并行化实现
从SON算法的描述中可以看出,在算法第一阶段中需要计算出局部频繁项集,原始的SON算法采用Apriori算法来计算每个分区的频繁项集,即同样需要对每个分区扫描多次才能得到局部频繁项集,所以SON算法是宏观上对整个事务数据集扫描两次,而从局部上来看仍然需要对每个分区分别扫描多次。本节提出的算法实现基于FP-growth,这将有效减少对分区的扫描次数。
SON算法非常适合于并行计算环境,SON算法中的每一个分区都可以并行地处理。用MapReduce编程模型对基于FP-growth的SON算法进行并行化实现。算法的实现需要两轮迭代,第一轮MapReduce迭代计算出每一个分区的局部频繁项集并由此生成全局候选项集。第二轮MapReduce迭代计算出每一个全局候选项集的支持度计数,并根据支持度计数来判断是否为频繁项集。
2.1 第一轮MapReduce迭代
在Map阶段,每个Map任务完成从事务数据集的某一个分区中读取到的事务,并将该分区中所有的事务存储在本地内存中,然后利用FP-growth算法算出本分区的局部频繁项集,最后输出的是一个键值对


在Reduce阶段,每个Reduce任务会处理一组局部频繁项集,上个阶段所有的Map任务输出的相同的局部频繁项集会集中到同一个Reduce任务上进行处理,Reduce的任务就是将相同的局部频繁项集输出一次即可,最后的输出结果即为全局的候选项集。

2.2 第二轮MapReduce迭代
在Map阶段,每个Map任务仍然处理事务数据集上的一个分区,在Map任务开始前,把上一个MapReduce迭代产生的全局候选项集放入本地内存中,Map任务开始后每读入一个事务,找寻全局候选项集中哪些候选项集为此事务的子集,如果某候选项集为此事务子集,即输出

在Reduce阶段,每个Reduce任务处理一组全局候选项集,上个阶段所有的Map任务输出的相同的候选项集会集中到同一个Reduce任务上进行处理,计算全局候选项集的支持度计数,根据其支持度计数即可判断该项集是否为频繁项集,Reduce任务会将得到的全局频繁项集进行输出。


3 实验结果与实验分析
3.1 实验环境
整个实验在Hadoop平台下完成,平台采用了Hadoop的1.0.4稳定版本。硬件设备为4台x86架构的PC,主设备节点采用 Intel志强四核处理器,内存为2 GB;从设备节点采用了AMD四核处理器,主频为 2.7 GHz,内存为2 GB。
3.2 实验数据集
实验采用accidents[8]作为实验事务数据集,该数据集包含1991年~2000年Flanders地区的交通事故记录。该数据集的大小为34 678 KB,共340 184条事务,有572个不同的项,平均每条事务包含45个项。
3.3 实验分析
为了对基于Apriori的并行SON算法和基于FP-growth的并行 SON算法进行比较,首先用MapReduce模型分别实现两个算法。发现两个算法仅在阶段1的局部频繁项集处有异,在阶段2没有任何差别,所以实验仅对两个算法的阶段1的运行进行比较。两个算法分别在同等的集群条件和同样的数据集下运行。由于分布式环境下的实验结果具有一定的颠簸性,所有实验的最终结果均为多次实验后取得的合理值。
图1为accidents数据集在保持不变和划分为2块、4块、8块的情况下,两种算法分别在第一轮迭代时消耗的总时间。从图1可以看出,在算法采用相同的分区数目时,基于FP-growth的并行SON算法比基于Apriori的并行SON算法运行时间明显减少。随着数据集划分的分区数目的增加,两种算法运行的总时间将明显减少。

图1 算法第一阶段运行时间
图2显示了随着accidents数据集划分块数的增加,基于FP-growth的并行SON算法的运行能够得到接近线性的加速比。
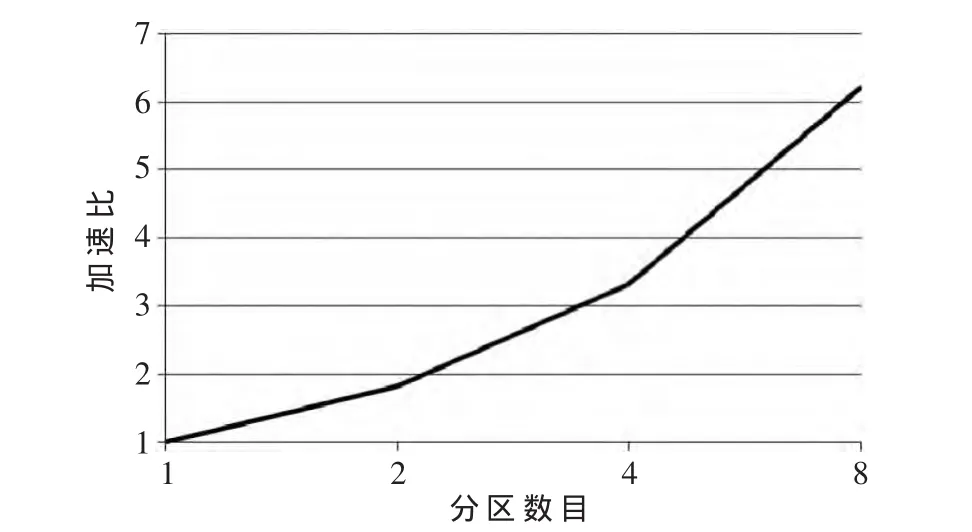
图2 基于FP-growth的并行SON算法的加速比
本文分析了传统的SON算法,指出了SON算法虽然从宏观上对事务数据集扫描了两次,但是发现在局部频繁项集时采用的Apriori算法仍然需要对每个分区扫描多次。根据MapReduce编程模型,本文提出的基于FP-growth的并行SON算法的实现,不仅减少了SON算法在阶段1中的运行时间,并且算法运行在Hadoop集群上,为处理海量数据提供了可能。虽然本文提出的算法的实现从某种程度上可以看作是FP-growth算法的并行化实现,但是每个分区生成的FP-tree都是独立的,互相之间没有联系,这导致了随着分区数目的增加使阶段1生成的全局频繁项集也会增加。因此,如何利用MapReduce实现FP-growth的完全并行化实现将在后续工作中进一步研究。
[1]AGRAWAL R,SRIKANT R.Fast algorithms for mining association rules[C].Proceedings of 20th Conference on Very Large Data Bases,1994:487-499.
[2]Han Jiawei,Pei Jian,Yin Yiwen.Mining frequent patterns without candidate generation[C].Proceedings of Conference on the Management of Data,2000:1-12.
[3]SAVASERE A,OMIECINSKI E,NAVATHE S.An efficient algorithm for mining association rules in large databases[C].Proceedings of the 21st Conference on Very Large Database,1995:432-444.
[4]DEAN J,GHEMAWAT S.MapReduce:simplified data processing on large clusters[J].Communications of the ACM,2008,51(1):107-113.
[5]Apache Hadoop[EB/OL].[2013-07-12].http://hadoop.apache.org.
[6]李建江,崔健,王聃,等.MapReduce并行编程模型研究综述[J].电子学报,2011,39(11):2635-2642.
[7]Apache Mahouts[EB/OL].[2013-08-12].http://mahout.apache.org/.
[8]Frequent Itemset Mining Dataset Repository[EB/OL].[2013-08-28].http://fimi.ua.ac.be/data.
猜你喜欢
中国交通信息化(2022年10期)2022-11-17
数学物理学报(2022年4期)2022-08-22
数学物理学报(2022年2期)2022-04-26
河南水利年鉴(2020年0期)2020-06-09
金桥(2018年4期)2018-09-26
天津科技大学学报(2018年4期)2018-08-22
华中师范大学学报(自然科学版)(2017年6期)2017-12-26
大连理工大学学报(2017年5期)2017-09-20
中国卫生(2014年5期)2014-11-10
中南民族大学学报(自然科学版)(2011年2期)2011-02-07
