
R.Hausser的左结合语法
2014-10-24 01:18:47冯志伟
外语学刊 2014年2期
冯志伟
(杭州师范大学,杭州 310036)
●语言学
〇引进与诠释
R.Hausser的左结合语法
冯志伟
(杭州师范大学,杭州 310036)
本文在“语表组合线性内部匹配”理论和“数据库语义学”基础上,介绍Roland Hausser的“左结合语法”。 这种独具特色的形式语法,对于自然语言的自动分析和自动生成具有重要的指导意义。
语表组合线性内部匹配;数据库语义学;左结合语法
采用计算机技术来研究和处理自然语言是20世纪 40 年代末期和50年代才开始的。50多年来,这项研究取得长足的进展,成为当代语言学中一个重要的新兴分支——自然语言处理(Natural Language Processing,简称NLP)。在信息网络时代,自然语言处理引起包括计算机专家和语言学家在内的越来越多的学者的重视,成为文科和理科紧密结合的一门典型交叉学科(Manaris 1999)。
由于现实的自然语言极为复杂,不可能直接作为计算机的处理对象,为了使现实的自然语言成为可以由计算机直接处理的对象,在众多的应用领域中,我们需要根据处理的要求,把自然语言抽象处理为一个“问题”(problem),再把这个问题在语言学上加以“形式化”(formalism),建立语言的“形式模型”(formal model),使之能以一定的数学形式,严密而规整地表示出来,并且把这种严密而规整的数学形式表示为“算法”(algorithm),建立自然语言处理的“计算模型”(computational model),使之能够在计算机上实现。在自然语言处理中,算法取决于形式模型,形式模型是自然语言计算机处理的本质,而算法只不过是实现形式模型的手段而已。这种建立语言形式模型的研究是非常重要的,它应当属于自然语言处理的基础理论研究。(冯志伟 2010)
由于自然语言处理的复杂性,这样的形式模型的研究往往是一个“强不适定问题”(strongly ill-posed problem),也就是说,在用形式模型建立算法来求解自然语言处理的问题时,往往难以满足问题解的“存在性”、“唯一性”和“稳定性”这3条最基本的要求,有时是不能满足其中的一条,有时甚至3条都不能满足。因此,对于这样的强不适定性问题求解,应当加入适当的“约束条件”(constraint conditions),使问题的一部分在一定的范围内变成“适定问题”(well-posed problem),从而顺利地求解这个问题,建立自然语言处理的形式模型,以达到自然语言处理的目标。(张钹 2007:3-7)
我们在本文中介绍的“左结合语法”(Left-Associative Grammar,简称LA)就是一种独具特色的自然语言处理的形式模型。
左结合语法的创始人Roland Hausser是德国爱尔兰根-纽伦堡大学计算语言学教授。他先后出版了《表面组成语法》、《自然人机交流》、《计算语言学基础-人机自然语言交流》和《自然语言交流的计算机模型》等多部专著,发表文章近百篇。近年来,Hausser进一步提出了“数据库语义学”(Database Semantics,简称DBS)和完整的“语表组合线性内部匹配”理论(Surface Compositional Li-near Internal Matching,简称SLIM),创立了左结合语法,在计算语言学界形成了他自己独特的风格。
我与Hausser曾有一面之交。2002年联合国教科文组织(UNESCO)韩国委员会在韩国首尔举行了一次关于“信息时代的语言问题”的学术研讨会,我和Hausser都被邀请参加了这次会议,在会议期间的交谈中,我对于Hausser独特的理论有了初步的了解,回国之后,我又细读了他的《计算语言学基础-人机自然语言交流》一书,对于他的理论又有了进一步的认识。我认为Hausser是一位具有独创精神的计算语言学家。
2006年,Hausser又出版了《自然语言交流的计算机模型-数据库语义学下的语言理解、推理和生成》一书(Hausse 2006)。在这本书中,他系统地分析了自然语言的主要结构,以英语为例,分析了听话人模式(hearer mode)和说话人模式(speaker mode)下的示意推导。听话人模式下的分析主要讨论了如何严格按照时间线性顺序将函词-论元结构(hypotaxis)和并列结构(parataxis)编码为命题因子,并把共指(coreference)作为推理基础上的二级关系来分析。说话者模式下的分析主要讨论如何在词库内进行以提取内容为基础的自动导航,如何按照相应语言的语法要求输出正确的词形和语序,如何析出适当的功能词,等等。在这本重要的著作中,Hausser构建了一个功能完整但覆盖面有限的英语交流体系,为我们提供了一个对自然语言交流进行理论分析的功能框架。
Hausser认为,面向未来的计算语言学的中心任务就是研究一种人类可以用自己的语言与计算机进行自由交流的认知机器。因此,自然语言的人机交流应当是计算语言学的中心任务。计算语言学研究应当通过对说话人的语言生成过程与听话人解释语言的过程进行建模,在适宜的计算机上复制信息的自然传递过程,从而构建一种可与人用自然语言自由交流的自治的认知机器,这样的认知机器也就是机器人(robot)。为了实现这一目标,我们必须对于自然语言交流机制的功能模型有深刻的理解。
Hausser提出的“语表组合线性内部匹配”理论以人作为人机交流的主体,而不是以语言符号为主体,突出了人在人机交流中的主导作用,SLIM理论要求通过完全显化的机械步骤,使用逻辑和电子的方式来解释自然语言理解和自然语言的生成过程。因此, SLIM理论与现代语言学中的结构主义、行为主义和言语行为等理论是不同的,具有明显的创新特色。
SLIM理论强调“表层成分”(Surface),以语表组合性作为它的方法论原则;SLIM理论强调“线性”(Linear),以时间线性作为它的实证原则;SLIM理论强调语言的“内部因素”(Internal),以语言的内部因素作为它的本体论原则;SLIM理论强调“匹配”(Matching),以语言和语境信息之间的匹配作为它的功能原则。事实上,SLIM这个名字本身就来自于“表层成分”、“线性”、“内部因素”和“匹配”这4项原则的英文名称的首字母缩写。
SLIM理论的技术实现手段叫做“数据库语义学”(DBS)。DBS是把自然语言理解和生成重新建构为“角色转换”(turn-taking)的规则体系。角色转换指的是从“说话人模式”向“听话人模式”的转换,或者从“听话人模式”向“说话人模式”的转换。
在自然语言的实际交流过程中,第1个过程是听话人模式中的自然主体从另一个主体或者语境获得信息,第2个过程是自然主体在自己的认知当中分析信息,第3个过程是自然主体思考如何作出反应,第4个过程是自然主体用语言或者行动做出反馈。
DBS的输入与第1个过程相似,要求计算机或者机器人具备外部界面。接下来匹配语境和认知的内容,采用左结合语法(LA)来模拟第2个过程,这个左结合语法是处于听话人模式中的,叫做LA-hear。左结合语法的第二个变体负责在内存词库中搜索合适的内容,叫做LA-think,这一部分操作对应于第3个过程。左结合语法的第三个变体的任务是语言生成,叫做LA-speak,模拟第4个过程。如图1所示:
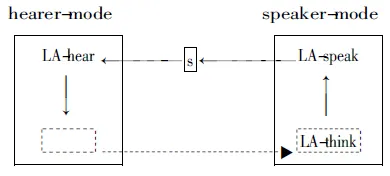
图1 角色转换体系
在图1中,听话人模式的LA-hear模拟第2个过程,说话人模式的LA-think模拟第3个过程,LA-speak模拟第4个过程。
DBS的分析结果用DBS图(DBS graph)来表示。DBS图是一种树结构,但是,DBS图的树结构与短语结构语法和依存语法的树结构有所不同。例如,英语的句子The little girl slept(那个小女孩睡着了) 用短语结构语法分析后的树结构如下:
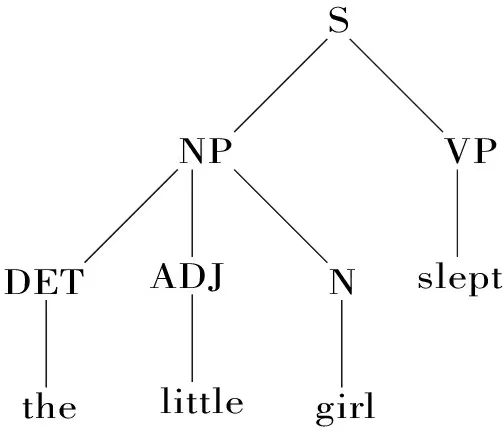
图2 短语结构树
在这个短语结构语法的树结构中,S(句子)由NP(名词短语)和VP(动词短语)组成,NP由DET(限定词),ADJ(形容词)和N(名词)组成,它们分别对应于单词the, little和girl,VP对应于单词slept. 句子的层次和单词之间的前后线性关系都是很清楚的,但是,在组成S的NP和VP之间,没有说明哪一个是中心词,在组成NP的DET, ADJ和N之间,也没有说明哪一个是中心词,句子中各个成分的中心不突出。
用依存语法分析后的树结构如下:
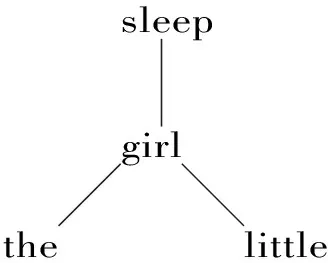
图3 依存结构树
在这个依存语法的树结构中,全部结点都是具体的单词,没有S, NP, VP, DET, ADJ和N等表示范畴的结点,各个单词之间的依存关系清楚,这种依存关系是二元关系,支配者是中心词,被支配者的从属词。但是,单词之间的前后线性顺序不如短语结构语法的树结构那样明确。
用DBS图分析后的树结构如图4所示:
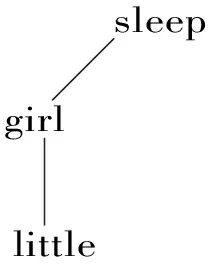
图4 DBS图的树结构
在DBS图的树结构中,着重对语言内容进行分析,因此,没有表示定冠词 the 的结点,结点上的单词都用原型词表示。DBS图最突出的特色在于,DBS图树结构的结点之间的连线各自有其明确的含义,连线不仅表示结点之间的依存关系,还可以根据连线走向的不同来表示不同的功能:垂直竖线“|” 表示修饰-被修饰关系,例如,图4中little与girl用垂直竖线相连,表示little修饰girl;左斜线 “/” 代表主语-动词关系,例如,图4中girl与sleep用左斜线相连,表示girl是sleep的主语。此外,DBS图树结构还使用右斜线 “” 表示宾语-动词关系,使用水平线 “-”表示并列关系。由于连线走向的不同可以表示不同的功能,这样的树结构表示的信息比短语结构语法的树结构和依存语法的树结构丰富多了。这是DBS图树结构最引人瞩目的特点。
上面的DBS图中表示了little做girl的修饰语,girl做sleep的主语,表达的是句子中单词之间的语义关系,所以,Hausser把这样的DBS图叫做“语义关系图”(the semantic relations graph,简称SRG)。
如果把DBS图中每个结点上的单词替换为代表其词性的字母,那么,语义关系图就变成了“词性关系图”(the part of speech signature,或者简写为signature)。上一例句的词性关系图如图5所示:
图5 词性关系图
语义关系图和词性关系图是同一句子内容的不同表示,它们表示的内容相同,表示的形式不同。
Hausser在2011年的新书中还提出了另外两个图:一个是“编号弧图”(the numbered arcs graph,简称NAG), 一个是“语表实现图”(the surface realization)。这两个图分别表现如何从内容生成语言的过程和结果。编号弧图表示激活语义关系图的时间线性顺序,也就是说,编号弧图在某种程度上可以说是添加了编号弧的语义关系图。语表实现图表示如何按照遍历顺序生成语言的表层形式。
例如,英语句子“The little girl ate an apple”(这个女孩吃了一个苹果)的语义关系图(SRG)如图6所示:

图6 语义关系图
由于语义关系图(SRG)只表示句子的内容,所以,在这个SRG中,没有表示定冠词the的结点,也没有表示不定冠词an的结点,过去时形式ate用不定式动词eat来表示。
这个句子的词性关系图(signature)如图7所示:

图7 词性关系图
在这个词性关系图中,结点上的单词都替换表示其词性的字母。
这个句子的编号弧图(NAG)如图8所示:

图8 编号弧图
由于编号弧图要表示激活语义关系图的时间线性顺序,这种时间顺序用编号弧表示,编号弧用虚线标出,并在虚线旁边用数字注上时间的线性顺序:结点eat首先激活的结点girl(编号弧1);接着,结点girl激活结点little(编号弧2),由于它们之间用垂直竖线“|”相连,因此,可推导出little修饰girl(编号弧3);由于结点girl与结点eat之间用左斜线 “/”相连,因此,可推导出girl是eat的主语(编号弧4);然后,结点eat激活结点apple(编号弧5),由于结点apple与结点eat之间用右斜线 “”相连,因此,可推导出apple是eat的宾语(编号弧6)。可以看出,所有表示推导的编号弧的方向都是自底向上的。
这个句子的语表实现图如图9所示:
图9 语表实现图
图9中的数字表示单词生成的顺序。
数据库语义学(DBS)有两个基础:一个是左结合语法(LA-grammar),一个是单词数据库(word bank)。左结合语法和单词数据库在DBS中紧密结合在一起。Hausser把左结合语法比作火车头,把单词数据库比作火车运行必需的铁路系统。
单词数据库存储单词的内容,其存储形式是一种非递归的特征结构,叫做“命题因子”(proplets)。英文 “proplet” 取自 “proposition droplet”,表示命题的构成部分。
一个命题因子是“属性-值偶对”的集合。每个单词或者句子元素的句法语义信息都体现为相应的属性-值矩阵。例如,汉语“学生”这个单词的属性-值矩阵如图10所示:

图10 属性-值矩阵
这样的属性-值矩阵就是单词数据库的“命题因子”。
左结合语法是按照自然语言的时间线性顺序自左向右结合进行分析与计算的方法。
具体来讲,每个句子的第一个词为整句分析过程中的第一个“句子起始部分”(sentence start),之后输入下“一个词”(next word),二者经过计算构成新的句子起始部分,再继续与下一个输入的单词进行组合计算。这样不断地进行分析,直到句子结束或者出现语法错误才终止。当出现句法歧义或者词汇歧义时,左结合语法允许按照不同的推导路径并行地继续运算。
Hausser将左结合语法与短语结构语法进行了对比分析。他指出,左结合语法与短语结构语法是同质的语言分析方法。它们之间的差异在于:短语结构语法依据的是“替换原则”(the principle of substitution),而左结合语法依据的则是“可接续性原则”(the principle of continuation)。如果以“a, b, c…” 来代表语言符号,以“+” 代表串连符,那么,左结合语法的计算过程可以表示如图11:
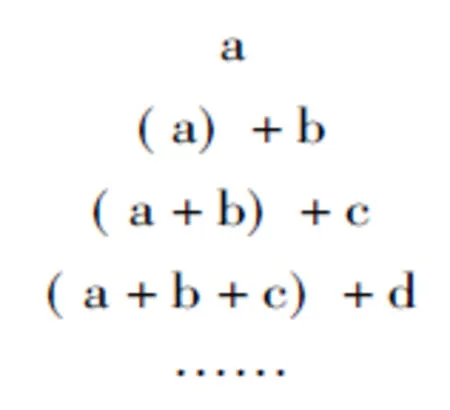
图11 左结合语法的计算过程
左结合语法在进行推导时,总是按照自左向右和自底向上的顺序,沿着树结构的左侧,一步一步地把单词逐一地结合起来的。树结构中的推导顺序如图12所示:
图12 树结构中的推导顺序
例如,英语句子“Every girl drunk water”(每一个女孩都喝了水)的推导顺序如图13所示:
图13 推导顺序示例
从这个树结构中可以看出,推导从左侧开始,首先把every与girl结合起来,形成(np),然后把(np)与drank结合起来,形成(np’v),最后把(np’v)与(sn)结合起来,形成(v)。
整个推导过程遵循时间线性(time linearity)的原则。所谓“时间线性”,就是“以时间为序,与时间同向”(linear like time and in the direction of time),也就是说,在推导时,要按照时间前后的顺序进行,要沿着时间的方向推进。
显而易见,左结合语法是一种基于短语结构语法的形式模型,同时又吸取了依存语法和数据库语义学的一些优点,具有明显的创新特色。这种独具特色的形式模型,对于自然语言的自动分析和自动生成具有重要的指导意义。
冯志伟. 自然语言处理的形式模型[M]. 北京:中国科学技术大学出版社, 2010.
张 钹. 自然语言处理的计算模型[J]. 中文信息学报, 2007(3).
Hausser, R.AComputationalModelofNaturalLanguageCommunication:Interpretation,InferenceandProductioninDatabaseSemantics[M]. Berlin:Springer-Verlag, 2006.
Manaris, B.NaturalLanguageProcessing:AHuman-computerInteractionPerspective[J].AdvancesinComputers, 1999(47).
【责任编辑谢 群】
Left-AssociativeGrammarofRolandHausser
Feng Zhi-wei
(Hangzhou Normal University, Hangzhou 310036, China )
Based upon Surface Compositional Linear Internal Matching (SCLIM) and Database Semantics (DBS), this paper introduces the Left-Associative Grammar (LA) of Roland Hausser. LA plays important role in automatic analysis and generation in natural language processing.
Surface Compositional Linear Internal Matching; Database Semantics; Left-Associative Grammar
H043
A
1000-0100(2014)02-0030-5
2012-03-27
猜你喜欢
数学物理学报(2018年1期)2018-03-26 08:16:42
浙江大学学报(理学版)(2017年1期)2017-02-07 09:53:45
电脑知识与技术(2015年14期)2015-07-24 11:30:20
浙江大学学报(工学版)(2015年6期)2015-03-01 01:18:24
河南科技(2014年11期)2014-02-27 14:17:57
电子设计工程(2014年12期)2014-02-27 11:58:23
苏州市职业大学学报(2010年1期)2010-01-29 02:26:40
科技经济市场(2006年6期)2003-03-17 01:51:26
