
基于批量提交数据的快速查询算法研究与设计
2014-10-23 12:38:12王防修石文文付威威
武汉轻工大学学报 2014年3期
谭 威,王防修,石文文,付威威
(武汉轻工大学数学与计算机学院,湖北武汉 430023)
二维数据主要来自于一类按照时间周期返回数据的传感器[1],这类传感器会被安装在需要实时监控的设备上,比如仪表盘、锅炉等,通过传感器适时传回监测设备提交的属性数据。又比如某一时刻的温度、锅炉的压力等,系统可以完整地记录下监测设备的整个运行状况,在监控现场出现异常状况时可以通过监测设备提交的历史记录进行故障定位和故障分析。当前的应用发展趋势表明,被监测个体的数目正在迅速增长,同时随着技术的进步以及应用的需求,数据回传的周期也越来越短,这就要求对众多监测设备提交的大量数据能够适时存储[2-5]和快速查询[6-10]。
所称批量提交数据,就是指应用环境中每个测点在一段时间内提交了大量数据。监测设备数量越多,则所有测点在一段时间内批量提交的数据量就越大。虽然每个设备采样周期固定,但不同设备的采样周期会有不同。因此,如何对监测设备提交的批量数据进行快速查询是监控系统适时处理问题的关键。
此外,所有的批量数据都必须保存在磁盘上,这就要求尽可能地节省磁盘空间。在实际的数据处理中,为了提高查询效率,必须使,内存和磁盘在容量上存在较大差距,要求降低索引之间的耦合度,内存索引和磁盘索引能够实现快速切换,在较小内存情况下也可以正常工作。降低数据和索引的耦合度,索引和数据分开存储[11]。为了节省存储空间,尽量使所提交的数据占尽可能少的外存空间。
总之,根据批量提交数据的结构特征,本文提出了一种基于批量提交数据的索引算法,通过该算法,实现了测点参数与属性数据的分离,其中测点参数作为索引文件的内容,而所有的属性数据存储在数据文件中,通过搜索索引文件可以很快地找到需要的属性数据。算法测试表明:通过索引文件查找属性数据文件,可以很好的解决下列问题:①实现批量提交数据在测点维度的快速查询;②实现批量提交数据在时间维度的快速查询;③实现单一测点在一段时间内的快速查询;④实现批量测点在某个时刻的快速查询。
1 批量数据存储与查询的数学模型
对于一个起始时刻为begin_time,采样周期为time_gap,编号为ID的测点而言,为方便查询,使该测点批量提交属性数据的起始地址为

其中M表示每个测点提交的数据量,而size表示一个属性数据的大小。
明确了属性数据的存储结构以后,则查询ID在时刻T提交的属性数据时,该属性数据在数据文件中的地址为
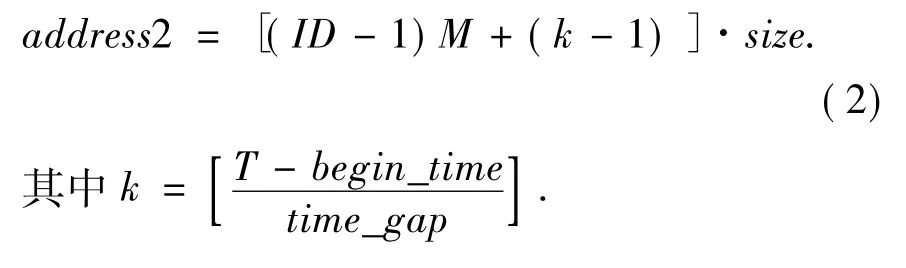
2 批量提交数据的快速查询
2.1 批量提交数据的分组存储策略
假设总共有N个测点,每个测点的采样周期不一定相同。如果每个测点批量提交的属性数据有M个,那么这些数据可以分组存储到不同的主表文件中,也可以存储在同一个主表文件中。此处采用分组存储的方式保存批量数据。具体过程如下:
步骤1 根据距离的远近,将相对比较集中的测点归为一组。假设N个测点被分为n组,且每组的测点个数为Ni,i=1,2,…,n,则满足下列关系:

步骤3 初始化主表文件计数器i=1。
步骤4 用分组主表文件fi保存第i组测点批量提交的属性数据,使得该文件的奇数行保存测点编号、数据提交的起始时刻、采样周期三个参数,而偶数行保存对应测点批量提交的M个属性数据,而数据之间用空格隔开,则文件fi的数据总量为:

步骤5 如果i<n,则使i=i+1,并重复步骤4。
最后,得到n个分组主表文件的数据量总和为:

2.2 快速查询算法
2.2.1 建立索引表文件
设l1表示分组主表文件中奇数行三个参数的累加长度,l2表示偶数行数据的长度。则为N个测点建立索引的过程如下:
步骤1 初始化分组主表文件指示器i=1。
步骤2 读分组主表文件fi的相关数据信息:
a)初始化测点计数器j=1和l1=0 l=1;
b)将fi的文件指针定位在l2(j-1)+l1;
c)读出文件fi当前位置的三个参数:测点编号ID,起始时刻begin_time,采样周期time_gap;
d)将begin_time,time_gap,l2(j-1)+l1保存在索引表文件Ind的第ID行;
e)如果j<M,则j=j+1,重复b)至d)。
步骤3 如果i<n,则i=i+1,且重复步骤2。
最后,得到索引表文件的数据量为i=3N。
2.2.2 批量数据在时间维度的快速查询
由于要查询N个测点在某个时刻T的属性数据,故n个分组主表文件都需要先后被读取,为了提高查询效率,必须通过索引表文件加快属性数据的准确定位。与测点维度查询不同,时间维度的查询需要查询所有测点 ,为提高查找索引表文件的效率,必须先将索引表文件导入内存建立索引,然后通过查询内存索引表来提高查询效率。如果要查询所有测点在时刻T的属性数据,则其查询过程如下。
步骤1 将索引表文件导入计算机内存,建立索引表 Indi,i=1,2,…,N 。
步骤2 初始化分组主表文件指示器i=1和测点计数器j=1。
步骤3 查询文件fi中所有测点在时刻T提交的属性数据:
a)计算测点Indj·ID在时刻T提交的数据位置
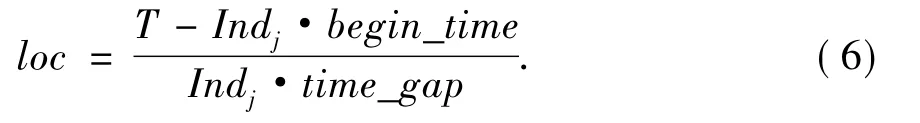
b)如果1≤loc≤M,则从文件fi读属性数据的物理地址为
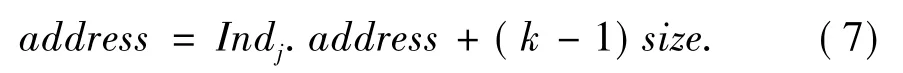
c)如果文件fi未被读完,则j=j+1,重复a)和b)。
步骤4 如果i<n,表示分组文件未处理完,则i=i+1,重复步骤3。
2.2.3 批量数据测点维度的查询
如果要查询测点ID批量提交的属性数据,则只需要使用索引表文件一次,故不需要将索引文件读入计算机内存。首先根据测点号ID所对应的主表文件在起始时刻提交的属性数据的地址,然后顺序读出该测点在不同时刻提交的属性数据。具体的求解过程如下。
步骤1 从索引表文件的第ID行立即找到该测点的begin_time,time_gap,以及在分组主表文件中的起始地址address。
步骤2 通过顺序查找或折半查找求出测点ID所在的分组主表文件fi。
步骤3 从文件fi的address开始依次读入M个属性数据。
3 算法改进
3.1 批量数据的归并存储和索引表的建立
由于分组主表文件都是文本文件,为方便查询,要求每个分组主表文件中的数据必须是等长的,这必然导致该算法的使用范围受到限制。同时,用文本表示数据需要花费更多的存储空间。如果用一个二进制主表文件保存全部属性数据,则既扩大了算法的使用范围,又可以节省存储空间。
对于n个测点而言,如果每个测点提交M个属性数据,则总共要提交Mn个属性数据。保存数据和建立索引表的过程如下。
1)对n个测点从1至n连续编号,然后在索引表文件中依次保存每个测点起始时间和采样周期。
2)依次保存每个测点批量提交的属性数据,则得到一个n×M的二维矩阵。因为每个属性数据占4个字节,故数据文件大小为4Mn。
3)对于一个测点ID而言,直接从索引表文件的位置8(ID-1)读取该测点的起始时间begin_time和采样周期time_gap。同理,直接从主表文件的位置4M(ID-1)开始读出该测点提交的所有属性数据。
3.2 批量数据在时间维度和测点维度的查询
在建立了索引表文件和主表文件后,接下来就是如何使用索引表文件快速地对主表文件进行时间维度和测点维度的数据查询问题。
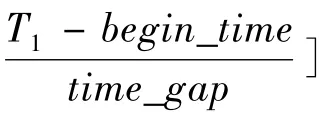

4 算法测试
假设存在10 000个监测设备,对每个设备使用随机数方式产生10 000个属性数据,每个设备采样周期固定,不同设备的采样周期在100至1 000之间随机选择,针对这些数据实现批量提交数据的快速查询。本算法的测试数据由2013第二届中国软件杯设计大赛的第二题提供,可以从中国软件杯的官网上直接下载得到。
针对现有的批量数据,进行如下的实验。
1)测试单个测点在不同时刻提交的属性数据,如表1所示。
2)测试所有测点在同一时刻提交的属性数据,如表2所示。
3)测试单个测点在一段时间内提交的属性数据,如表3所示。
4)测试不同测点在同一时刻提交的属性数据,如表4所示。

表1 测点维度查询的部分结果
表2 部分测点在某个时刻的属性数据

表3 单个测点在一段时间内的查询结果

表4 多个测点在某一个时刻的查询结果
表1与表3的区别在于:前者反映的是一个测点在所有时刻提交的属性数据,而后者是查询一个测点在一段时间内提交的属性数据。表2与表4的区别在于:前者反映的是所有测点在某一时刻提交的属性数据,而后者是查询几个不同测点在某一时刻提交的属性数据。其中,表1和表2只给出少量的部分结果,受篇幅所限无法将其结果全部列举。算法测试的主要目的是通过上述四个表反映出本算法的输入和输出。
5 算法分析
如果通过索引表文件查询分组主表文件,则要求每个分组主表文件必须具有一定的格式:①除参数外,每行属性数据的长度必须相同;②属性数据之间的空格、必须相同;③属性数据等长。如果分组主表文件不满足这些格式要求,则无法通过直接查询分组主表文件得到需要的属性数据;反之,即使能查询到所需要的数据,但其查询效率与存储效率较低,如果采用改进算法,则对二进制主表文件的格式就没有上述要求。将分组主表文件合并成一个二进制主表文件,可以提高算法的查询效率和存储效率,具体的查询效率如表5所示,存储效率见表6。此外,与分组主表文件相比,属性数据在二进制主表文件中占用较小的内存空间。

表5 算法查询效率的比较

表6 算法存储效率的比较
从表5可以看出,测点维度的查询效率明显高于时间维度的查询。之所以会出现这种情况,完全是由主表文件的存储结构决定的。
表6中体现改进后的算法所占磁盘空间是改进前的一半,其中磁盘空间=主表+索引表。
6 结束语
鉴于批量提交数据在适时监控系统中的存储特性,本文研究了大批量数据存储与查询领域中一个较少关注的重要问题,即在众多测点同一时刻提交大量数据的背景下,如何实现批量提交数据的快速查询。在每个测点采样周期固定的基础上,采用数据位置索引的方式详细描述了测点分类、数据存储、索引建立等过程,设计了索引表与主表分开存储的改进算法。算例测试表明,使用改进后的算法,可以使批量提交数据的查询效率和存储效率得到明显提高。本文研究是在批量提交数据的条件下进行的,需要考虑各测点在提交数据时的不同步性。然而,批量提交数据的存储方式使得测点维度的查询效率明显高于时间维度的查询。基于此,如何提高时间维度的查询效率,是笔者下一步研究的重点。此外,本文未来还将考虑重启后批量提交数据的快速查询问题。
[1]郝晋峰,康建设.改进的二进制粒子群算法的传感器优化配置[J].火力与指挥控制,2013,38(8):65-68.
[2]沃焱,韩国强.一种海量传感器数据存储与查询方法[J].计算机学报,2012,28(1).:89-93.
[3]苗雯娟,张晓利.基于SQLServer二进制文件存储技术的研究[J].高等教育,2011,109(11):111-113.
[4]蒋涛,高云君 ,张彬.一种基于Hadoop的纺织海量生产数据存储设计[J].微型电脑应用,2013,30(6):53-57.
[5]张洁.云计算环境下的数据存储保护机制研究与仿真[J].计算机仿真,2013,30(8):254-257.
[6]杜方,陈跃国,杜小勇.RDF数据查询处理技术综述[J].软件学报,2013,24(6):1222-1242.
[7]蒋涛,高云君,张彬.不确定数据查询处理[J].电子学报,2013,5(5):966-975.
[8]高志君,郑纯军.基于空间索引的WSN数据查询机制[J].计算机工程与设计,2013,34(3).
[9]倪睿熙.一种基于JSON的异构数据查询方法[J].无线电通信技术,2013,39(1):73-76.
[10]孙莉,李静,刘国华.列存储数据查询中的连接策略优化方法[J].计算机研究与发展,2013,50(8):1647-1656.
[11]孙莉,李静,刘国华.信息检索中快速索引文件的设计研究[J].计算机工程与科学,2011,104(2):427-429.
猜你喜欢
科学家(2021年24期)2021-04-25 12:55:27
科技资讯(2019年18期)2019-09-17 11:03:28
中国科技纵横(2019年15期)2019-08-27 03:34:44
教育界·下旬(2019年1期)2019-04-26 10:06:40
小学生学习指导(低年级)(2019年3期)2019-04-22 03:34:48
小学生学习指导(低年级)(2018年9期)2018-09-26 05:59:42
小学生导刊(低年级)(2017年1期)2017-06-12 12:07:42
阜阳职业技术学院学报(2015年4期)2015-05-17 03:58:58
温州职业技术学院学报(2014年3期)2014-03-11 19:03:39
组合机床与自动化加工技术(2014年12期)2014-03-01 02:23:02
