
基于背景属性的目标识别
2014-10-19 01:19:42雒建卫姜志国
北京航空航天大学学报 2014年12期
雒建卫 姜志国
(北京航空航天大学 宇航学院,北京100191)
1 基于属性的目标识别
目标识别一直是计算机视觉研究的热门领域.给定一幅图像,目标识别的任务是要给出这幅图像中目标所属的类别.它的研究方向主要包括特征提取、目标建模以及分类器设计.传统的目标识别流程是给定输入图像,提取特征构建图像表示,代入分类器得到类别标签,如图1所示.这里的图像特征一般指的是低级特征,不具有语义信息,这导致传统目标识别方法仅可以用来判断图像中目标的类别,但不能实现根据图像产生文本描述[1]等高级视觉任务.

图1 传统目标识别流程图Fig.1 Pipeline of traditional object recognition
属性是图像的语义描述,可以表示图像中某些内容的存在与否,它可以是物体的形状、材质、部件、类别及功能,也可以是场景的类别以及上下文信息等.比如,飞机的属性既有机翼、轮子、发动机等部件,也有金属等材质属性以及可以飞行等功能属性.同时飞机标签也可以作为一种类别属性.又如,马场的属性有天空、草地等类别属性以及人在骑马等语义属性.
近年来,属性被广泛应用于计算机视觉问题研究,如目标识别[2-4]、零样本学习[5-6]、多关键字图像检索[7]、人脸检索[8]、视频中的行为识别[9]及细粒图像识别[10]等.以属性用于目标识别为例,针对人和猫两类图像,毛皮以及皮肤属性可以有效地将它们区分.而针对猫和狗等拥有相同属性的类别,可以使用类别属性来区分它们.在零样本学习中,由于不同类别可能共享相同的属性,比如猫和狗都存在毛皮属性,因此当狗这个类别的训练样本缺失时,可以通过对猫这个样本进行训练得到某些属性训练器,并用这些训练器来推断一个未曾见过类别(狗)的样本的类别.这里用到的先验是未曾见过的类别(狗)的属性描述是已知的.
属性作为中层特征用于目标识别的基本流程如图2所示.其中属性分类器的训练是通过将具有某种共同属性的目标(跨类别)作为正样本,其他目标作为负样本,通过训练器如支持向量机(SVM)训练得到该属性的分类器.属性特征就是图像在一系列属性分类器上得分的向量表示.传统的基于属性的分类器并没有考虑到目标所在背景,也就是上下文信息,而文献[10-11]证明目标通常与背景是相关联的,利用上下文信息有助于剔除错误分类目标,提高识别精度.
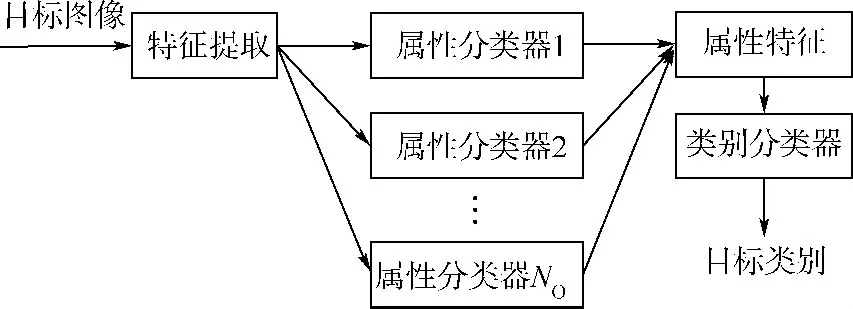
图2 基于目标属性的目标识别流程图Fig.2 Pipeline of object recognition based on object attribute
鉴于目标与背景在语义上存在相关性,本文提出基于背景属性的目标识别方法,并与传统方法、基于目标属性的方法[2]以及其他背景特征与目标特征相融合的方法进行了对比.实验表明,背景属性有助于提高目标识别精度.要强调的是,本文的主要目的是检验背景属性对于目标识别的作用,并没有考虑背景属性内部和目标自身属性内部的相关性.同时,由于所用到的数据库中,目标所在的区域是已标记的,也就是本文不考虑检测步骤,但所提出的利用背景语义对目标进行识别方法可以移植到目标检测中去.
2 数据库及属性标定
2.1 数据库及目标属性
本文采用的数据库是a-Pascal[2],它是从Pascal VOC2008数据库整理得到的.该数据库共有20种类的目标,包括:人、鸟、猫、奶牛、狗、马、羊、飞机、自行车、船、公交车、汽车、摩托、火车、瓶子、椅子、餐桌、盆栽、沙发以及电视.除了人这个类别包含5 000个实例外,其他每类约有 150~1000个实例.Farhadi等[2]也为该数据库标注了64种属性标记,有的为形状属性,如二维盒子、三维盒子以及竖型圆柱等;有的为材质属性,如木质的、金属的、毛皮的、皮革的、羽毛的、透明的以及有光泽的等;大部分为部件属性,如头、耳朵、嘴、头发、躯干、脸以及手等人所有的属性,还有侧视镜、发动机以及轮子等汽车所有属性.虽然同属于一个类别的目标应该具有相同的属性,但由于图像中存在遮挡、光照以及视点变化,不同实例的属性标记通常存在差异,a-Pascal就是考虑到这些差异,对每幅图分别进行属性标记的.在实验中,将类别标签作为扩展属性,因此最后目标属性个数为84(以下若无特别声明,属性均包含类别标签).
2.2 背景属性标记
为了利用背景信息辅助目标识别,本文对a-Pascal数据集中图像的背景属性分10类进行了标注,分别为:室内、墙壁、道路、室外、天空、沙土、草地、树木、水以及沙滩.这10类背景属性描述了目标所在场景的信息,有助于对前景目标的识别,比如当背景有水时,前景更有可能是船,沙发出现在室内场景的概率要明显高于室外.
3 特征表示
3.1 目标特征
针对前景目标图像,特征选取采用基于词袋模型(BoW)[12]的特征.词袋模型的基本思想是,将图像中的每个局部特征量化到固定的聚类中心,最后将这些聚类中心的直方图向量作为图像的特征表示.本文采用的局部特征有颜色特征、梯度方向直方图特征(HOG)[13]、边缘特征以及纹理特征[14],其中颜色和纹理特征有助于判别纹理属性,HOG特征有助于判别部件属性,而边缘特征则有助于判别形状.它们分别被量化为128,1000,8以及256个聚类中心.
由于所标记的目标属性中,大部分属性都是局部语义特征,为了更好地描述这些局部属性,目标所在区域被划分为3×2网格(如图3所示),在每个格子里分别计算颜色特征、HOG、边缘特征以及纹理特征的直方图表示,最后将每个格子的特征直方图和目标整个区域的特征直方图进行串联,得到9751维的特征向量.以上所使用特征与文献[2]相同.

图3 目标特征提取示意图Fig.3 Schematic diagram of object feature extraction
3.2 背景特征
本文采用Gist[15]特征表示背景图像.Gist是一种全局特征描述子,它描述自然场景的5个方向特性:自然度、开放度、粗糙度、扩展度以及崎岖度.它通过Gabor滤波器提取图像不同尺度上的不同频率和不同方向的特征.通常进行Gist特征提取时,对图像进行分块处理,并将每块中提取的特征进行串联作为最后的特征表示.本文采用4个尺度,每个尺度8个方向的Gabor滤波器,同时图像被归一化为256×256大小,且被分为8×8的方格,在每个方格上提取特征,最后将64个方格的特征串联作为最后的特征,总的特征维数是2048.
4 方法
4.1 数学描述
假设给定N幅图像{I1,I2,…,IN}和N个目标{O1,O2,…,ON},且 Oi∈Ii表示目标 Oi在图像Ii中.每个目标 Oi对应一个类别标签 ci∈{1,2,…,C},C为类别个数.与目标和图像相对应的特征表示分别为 X={x1,x2,…,xN}和 Y={y1,y2,…,yN}.假设目标共有m个属性Ao={Ao1,Ao2,…,Aom},背景共有 p 个属性为 Ab={Ab1,Ab2,…,Abp}.
4.2 基于背景属性的目标分类方法
为了验证背景属性对于目标识别的作用,提出基于背景属性的目标分类方法(以下简称属性串联分类法),如图4所示.该方法分别对目标图像和背景图像进行训练,得到目标属性和背景属性分类器,然后将目标和背景在各自属性分类器的得分进行串联组成属性特征,最后代入基于属性特征的类别分类器,输出目标类别.这种方法稍微复杂,需要对背景和目标分别训练各自的属性分类器,并将背景属性特征看作目标特征的一部分,与目标的属性特征串联看作目标最后的语义特征.
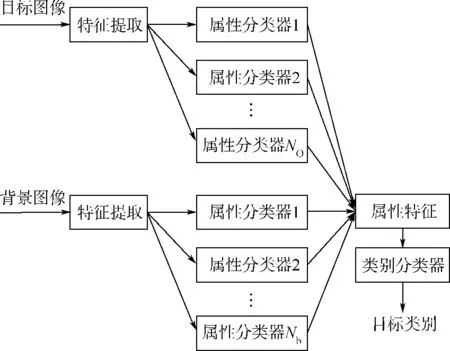
图4 属性串联分类方法Fig.4 Object recognition based on concatenated attributes
为了验证算法有效性,将提出的属性串联分类法方法与以下5种方法进行对比:
1)传统方法,如图1所示.该方法直接对图像底层特征进行分类.
2)基于目标属性的分类法(不包含类别标签),如图2所示.该方法以目标属性作为中层特征,对该特征进行分类.
3)基于目标属性的分类法(含类别标签).该方法将方法2进行扩展,将目标的类别标签当作扩展属性,用来增加属性的判别性.
4)特征串联直接分类法.如图5所示,该方法直接将背景特征和目标特征串联,并代入已训练目标类别分类器,给出目标的类别.这种方法比较简单,将背景特征看作目标特征的一部分,并直接在串联特征基础上训练目标类别,因此并没有考虑到背景的语义信息.
5)特征串联属性分类法.如图6所示,该方法将背景特征和目标特征进行串联作为新的目标特征,并训练目标属性分类器,然后基于目标属性特征构建最终目标分类器.4.3 分类器

图5 特征串联直接分类方法Fig.5 Object recognition based on concatenated features
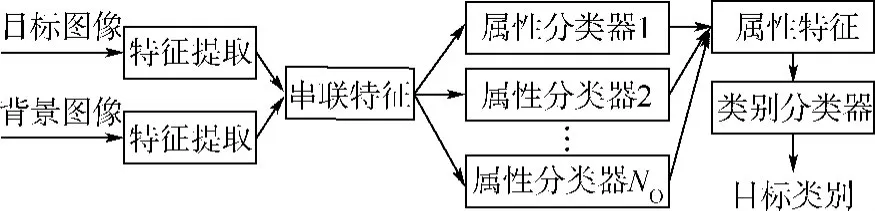
图6 特征串联属性分类方法Fig.6 Object recognition based on attributes built on concatenated features
本文采用线性支持向量机(SVM)作为属性分类器以及目标分类器,采用liblinear[16]程序软件包实现.该包在大型数据库以及高维特征上表现较好,且速度很快.优化目标函数为
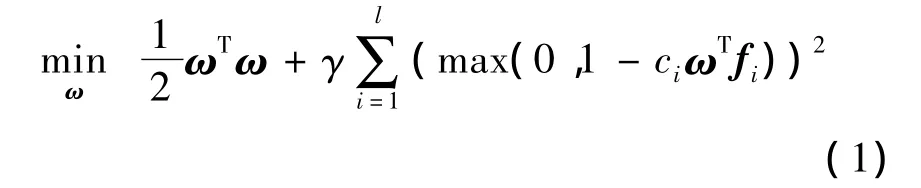
其中,ci和fi分别为标签和特征;参数γ是平衡项,通过实验选取最优.在训练属性Aoj分类器时,如果目标Oi的属性Aoji=1,则 ci=1,fi=xi,这是一个二分问题.背景属性分类器训练方法与目标属性相同.在基于目标属性的识别方法中,训练目标分类器时的输入是目标特征在所有属性分类器上的得分向量.目标Oi在属性分类器Aoj上的得分为,其中为属性分类器的分类面向量.
5 实验结果与分析
5.1 实验方法
实验时,样本被均分为训练集(a-Pascal train)和测试集(a-Pascal test)[2],其中训练集包含有6340个目标,测试集包含6 355个目标.训练时,针对每种属性(目标)分类器,样本按照属性(类别)又随机被均分为训练样本和验证样本.训练样本用来训练模型,验证样本用来验证模型参数,取在验证样本上识别率最高的参数.测试集用来统计最后模型的目标识别率.每种方法实验5次.
5.2 实验结果
表1为所有算法的实验结果比较,可以看出基于背景属性和目标属性串联的目标识别结果最好,特征串联直接分类与它相当,特征串联属性分类法次之,这说明背景特征(属性)有助于提高目标识别的精度.
基于目标属性的识别方法中,包含类别属性的方法要优于不包含类别属性的方法,这说明将类别标签引入属性集,有助于提高目标识别的精度.而不包含类别标签的基于属性的识别方法与传统方法相当,这说明基于属性的方法的有效性.不仅如此,基于属性的方法还可以用于计算机视觉的其他任务,如目标描述、异常属性检测以及缺失属性检测等[2].

表1 算法结果比较Table 1 Comparison of different algorithms
5.3 结果分析
图7为基于属性串联方法的目标分类混淆矩阵.可见类别人的识别率可以达到90%,说明基于属性的分类器的有效性,但其他类别大多数与人混淆,这是由于数据库比较复杂,目标类内变化比较大,而且人这个类别的实例非常多,导致结果偏向于这一类.分类结果仅次于类别人的是类别汽车,识别率达到75%,其中有13%错分为类别人.与汽车混淆最多的是公交车和火车,这可能是因为这些交通工具的属性非常相似,单纯依靠属性进行分类的判别性比较差,但从另一个方面看,说明属性分类器可以很好地描述目标的特性,并可以用于转移学习[3]等问题.值得注意的是自行车的分类效果比较差,并且与人混淆的最厉害,这可能是因为数据库中自行车经常与人同时出现,相互遮挡,导致自行车目标中检测出了人的属性,不过这也说明了属性对于描述目标的能力.另外一些分类效果非常差的类别,比如沙发、餐桌等,则可能是因为这些目标的类内变化非常大,导致分类器性能下降,这也间接说明a-Pascal是非常具有挑战性的数据库,目标的尺度、视点、光照、遮挡及类内变化都非常大,对分类器的泛化能力要求高.

图7 基于属性串联方法的分类混淆矩阵Fig.7 Confusion matrix of method based on concatenated attributes
6 结论
传统的目标识别算法仅仅考虑图像底层特征和目标类别的关系,而缺少语义描述.基于属性的目标识别算法以目标属性作为图像的中层特征,并构建目标类别与属性特征的关系.
本文提出基于图像上下文信息,即背景属性的目标识别方法,验证背景属性对于前景目标识别的作用.分别实现了6种方法:即属性串联分类方法、传统SVM方法、基于目标属性的识别方法(不含类别标签)、基于目标属性的识别方法(含类别标签)、特征串联直接分类方法以及特征串联属性分类法,并在a-Pascal数据集上进行了实验.结果证明,假设属性独立的条件下,利用背景特征有助于提高前景目标的识别率,属性串联分类法比传统SVM方法提升了1.33%.
References)
[1] Farhadi A,Hejrati M,Sadeghi M,et al.Every picture tells a story:generating sentences from images[C]//Computer Vision-ECCV 2010.Heidelberg:Springer Verlag,2010,6314(4):15-29
[2] Farhadi A,Endres I,Hoiem D,et al.Describing objects by their attributes[C]//2009 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops.Piscataway,NJ:IEEE Computer Society,2009:1778-1785
[3] Yu F X,Cao L L,Feris R S,et al.Designing category-level attributes for discriminative visual recognition[C]//Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition.Washington D C:IEEE Computer Society,2013:771-778
[4] Wang Y,Mori G.A discriminative latent model of object classes and attributes[C]//Lecture Notes in Computer Science.Heidelberg:Springer Verlag,2010(PART5):155-168
[5] Parikh D,Grauman K.Relative attributes[C]//Proceedings of the IEEE International Conference on Computer Vision.Piscataway,NJ:IEEE,2011:503-510
[6] Lampert C H,Nickisch H,Harmeling S.Learning to detect unseen object classes by between-class attribute transfer[C]//2009 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops.Piscataway,NJ:IEEE Computer Society,2009:951-958
[7] Siddiquie B,Feris R S,Davis L S.Image ranking and retrieval based on multi-attribute queries[C]//Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition.Piscataway,NJ:IEEE Computer Society,2011:801-808
[8] Kumar N,Berg A C,Belhumeur P N,et al.Attribute and simile classifiers for face verification[C]//Proceedings of the IEEE International Conference on Computer Vision.Piscataway,NJ:IEEE,2009:365-372
[9] Liu J G,Kuipers B,Savarese S.Recognizing human actions by attributes[C]//Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition.Piscataway,NJ:IEEE Computer Society,2011:3337-3344
[10] Duan K,Parikh D,Crandall D,et al.Discovering localized attributes for fine-grained recognition[C]//Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition.Washington D C:IEEE Computer Society,2012:3474-3481
[11] Torralba A,Murphy K P,Freeman W T,et al.Context-based vision system for place and object recognition[C]//Proceedings of the IEEE International Conference on Computer Vision.Piscataway,NJ:IEEE,2003,1:273-280
[12] Li F F,Perona P.A Bayesian hierarchical model for learning natural scene categories[C]//Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition.Piscataway,NJ:IEEE Computer Society,2005,2:524-531
[13] Dalal N,Triggs B.Histograms of oriented gradients for human detection[C]//Proceedings of 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition.Piscataway,NJ:IEEE Computer Society,2005,1:886-893
[14] Varma M,Zisserman A.A statistical approach to texture classification from single images[J].International Journal of Computer Vision,2005,62(1/2):61-81
[15] Oliva A,Torralba A.Modeling the shape of the scene:a holistic representation of the spatial envelope[J].International Journal of Computer Vision,2001,42(3):145-175
[16] Fan R E,Chang K W,Hsieh C J,et al.LIBLINEAR:a library for large linear classification[J].The Journal of Machine Learning Research,2008,9:1871-1874
猜你喜欢
故事作文·低年级(2023年11期)2023-12-05 06:39:56
故事作文·低年级(2023年12期)2023-03-24 14:16:52
电子测试(2018年1期)2018-04-18 11:52:35
光学精密工程(2016年4期)2016-11-07 09:05:00
光学精密工程(2016年3期)2016-11-07 09:03:33
中国环境监察(2016年7期)2016-10-23 05:36:30
中国现当代社会文化访谈录(2016年0期)2016-09-26 08:46:23
新校长(2016年8期)2016-01-10 06:43:59
商事法论集(2014年1期)2014-06-27 01:20:42
电测与仪表(2014年15期)2014-04-04 12:05:20
