
中文微博客的垃圾用户检测
2014-10-15 01:52李赫元俞晓明程学旗
中文信息学报 2014年3期
李赫元,俞晓明,刘 悦,程学旗,程 工
(1.中国科学院 计算技术研究所,北京100190;2.中国科学院大学,北京100190;3.国家计算机网络应急技术处理协调中心,北京100029)
1 引言
微博客(简称微博)是一种基于用户关系的信息分享、传播与获取平台。近几年,中文微博服务发展迅猛,截止2012年5月,新浪微博的注册用户已达3亿、每日发布的消息量超过1亿条[1];腾讯微博的注册用户数也已超过4亿。微博的出现不仅改变了信息的传播方式,也改善了我们的生活质量。然而,微博上却充斥着炒作、营销、谣言等不良信息,困扰着微博的健康发展。如何对垃圾用户及其发布的垃圾消息进行识别,已经成为了亟待解决的问题。目前,相关研究工作主要集中在Twitter等英文微博中,中文微博与英文微博之间存在着一些较为显著的差异。
(1)评论模式与提及
在Twitter中,转发只显示原作者。Twitter中的提及是用户之间的直接交互。针对这一点,国外学者提出了基于提及关系的检测方法。然而在中文微博中,转发的同时可以提及(@)原作者,使得两者难以区分。因此,利用提及关系的检测方法并不适用于中文微博。
(2)互粉行为
中文微博引入了“加V”“人气用户”等概念。为了提升自己的粉丝数量,新浪等微博中出现了大量的“互粉行为”,即主动关注别人并要求对方也关注自己。这一具有中文微博特色的现象,将影响“用户权威度”等在Twitter中有效的垃圾用户检测特征。
(3)对待垃圾用户的态度
Twitter中,官方开设了“spam账号”接受举报。举报信息公开、透明、便于采集,许多学者都选用举报信息作为垃圾用户的范本。中文微博客虽然提供了举报功能,但信息是不公开的。因此,在中文微博客中我们无法自动取得垃圾用户的标注信息。
本文以中文微博客为重点,探索垃圾用户检测方法。本文的创新之处在于:(1)关注中文微博中的“互粉”行为,并据此提出了新的用户图特征;(2)研究了注册时间与垃圾用户行为的关系,并据此提出了近期活跃度特征;(3)讨论中文微博开放平台中的应用,提出了应用来源黑、白名单特征。
本文余下的部分将如下安排:第2节讨论国内外的相关工作。第3节从用户图、用户资料、微博内容3个方面提出了7种新的检测特征。第4节首先介绍了数据的采集、标注,接着进行了分类器的训练、实验。通过对实验结果的分析,验证了特征的有效性。第5节对本文工作进行总结与展望。
2 相关工作
Grier[2]等研究了Twitter中包含URL的微博消息。统计表明,约8%的URL指向垃圾网页。研究还对垃圾账号进行了研究。只有16%的垃圾账号从注册之初就在发布垃圾Tweet;余下84%的账号均是被盗用的,其行为特征是,账号注册于很久之前并已经被弃用,直到近期突然开始散布垃圾消息。
Wang[3]等将垃圾用户的检测转化为机器学习的分类问题。该研究提出了5种检测特征,“用户权威度”、“重复Tweet率”、“含URL的Tweet比率”、“含提及(@)的 Tweet比率”、“含话题(#)的Tweet比率”。统计结果表明,垃圾用户在上述各项指标中都略区别于普通用户,但多数特征不具有鲁棒性。应用上述特征构造的朴素贝叶斯分类器可以达到91.7%的准确率。
Song[4]等从社交关系网的角度研究了Twitter中的垃圾用户。该研究提出了“用户距离”和“用户连通度”两个特征:若两个距离大于4的用户之间相互“提及”,则可认为是在传播垃圾信息;在用户距离相同的情况下,正常用户之间的连通度要强于垃圾账户之间的连通度。利用上述两个特征进行检测,可以达到94.6%的准确率。如第1节所述,在中文微博中,提及和评论混在了一起,因此该检测方法难以应用于中文微博中。
在国内的研究中,王宇[5]等人对新浪微博中的“僵尸粉”进行了研究,总结出了“用户微博数”“用户是否包含简介”等6种具有区分度的特征。其中“用户昵称可疑度”等特征需要借助人工识别。该研究同样使用朴素贝叶斯算法训练分类器,准确率达到了88%。
3 垃圾用户检测
3.1 检测特征
本节将从用户图、用户资料、微博内容三个方面,提出垃圾用户检测特征。在讨论相关研究中提出的5种检测特征的基础上,我们新提出了“纯粉丝度”“黑名单应用”“用户用字多样性”等7种新的检测特征。
3.1.1 用户图特征
微博中,用户的关系可以用有向图表示:出度表示“关注”,入度表示“粉丝”(被关注);若用户彼此关注了对方,则称为“互粉”(互为粉丝的简称)。以图1为例,C关注了A,A关注了B;B和C互粉。A的粉丝是C;B的粉丝是A和C;C的粉丝是B。
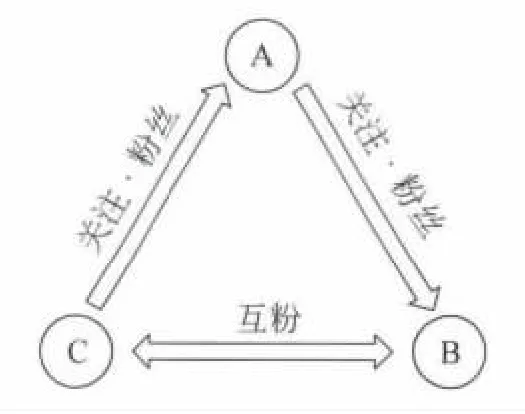
图1 “关注”“粉丝”和“互粉”
用户权威度
在Wang等人的研究中[3],定义了特征“用户权威度”,见式(1)。Nfollow表示用户u的粉丝数,Nfriend表示该用户的关注数。若用户既没有粉丝也没有关注,规定该用户的权威度为0。
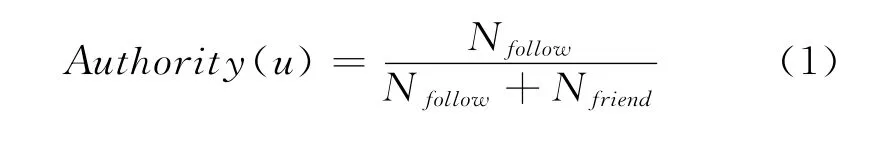
用户关注度
为了探讨垃圾用户、普通用户在主动关注方面有无差异,我们提出了“用户关注度”特征,如式(2)所示。Nfollow是用户的粉丝数,Nfriend是用户的关注数。直观地分析:垃圾用户会大量的关注别人,却很少得到别人的关注,因而该特征偏高。

纯粉丝度
在中文微博中,用户之间的“互粉”可以提高双方的粉丝数,也会干扰“用户权威度”特征的区分度。为了避免这种情况,我们定义了纯粉丝度,见式(3)。Nfollow依然表示用户u的粉丝数;分子部分为去除了互粉用户之后的“纯粉丝数”。该特征描述了粉丝质量。

3.1.2 用户资料特征
在王宇等人的研究中[5],提出了“用户简介”“微博域名”特征。本节将提出“用户头像特征”“近期活跃度”两个新的特征。
用户头像特征
在本研究中,我们对用户头像的图片进行了采集,并提出了“用户头像”特征,它识别用户是否使用了默认头像。若为默认头像,g(u)=0;若上传了头像,g(u)=1。
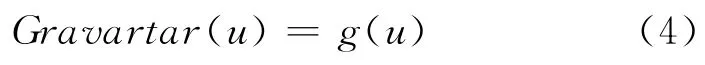
近期活跃度
用新账号发布垃圾信息很容易被识破。因此,垃圾用户更倾向于使用注册时间较长的“沉睡账号”散播垃圾信息。我们定义了“近期活跃度”指标,见式(5)。NDuringDays是用户最近100条消息跨越的天数。NCreateDays是截止采集当天,用户账号已存活的天数(注册天数)。对于突然活跃的沉睡账号,上述特征值会偏高;而对于一直活跃或已经很久不活跃的正常用户而言,这一特征值较低。

3.1.3 微博内容特征
基于内容过滤的技术在反垃圾邮件等领域取得了很好的效果。然而,这类方法需要大量的训练数据和标注样本。在国外的研究中,主要从“微博中是否含URL”“微博是否大量重复”两个方面考虑内容特征。本节结合了中文微博客的特点,提出了“用字多样性”、“白名单应用率”、“黑名单应用率”三个新的检测特征。
不含URL微博比例
由于微博消息的长度限定在140字以内,垃圾用户通常会选用“在微博中附加链接”的方式推广垃圾信息。基于此,Benevenuto[6]等提出了“不含URL微博比”这一特征,如式(6)所示。NAll是用户发布的微博数量,NNoURL是在所发微博中不含有URL的数量。

应用来源的白名单率和黑名单率
中文微博客推出了开放平台,提供了丰富多彩的应用,它们具有获取微博、发送微博、关注等操作权限。通过开放应用发布微博时,应用名称会显示在“消息来源”字段中。借助这一字段,我们对开放应用进行了研究,分为如下三类。
(1)黑名单应用
为了降低维护成本、垃圾制造者会使用“皮皮时光机”等开放应用管理微博。在采集数据中,我们选取垃圾用户使用最多的30个应用作为黑名单。当然,使用黑名单发送的微博不一定都是垃圾信息,例如,很多用户会选用“皮皮时光机”定期地转发热门微博。
随着移动互联网的发展,越来越多的用户使用手机客户端发微博。但对垃圾用户而言,用手机客户端管理数百个账号的成本过大。因此,我们将手机客户端定义为白名单应用。
(3)其他应用
并非全部的开放应用都符合上述两种分类。如“微博桌面”等应用,正常用户使用它们来发微博,垃圾用户通过“模拟点击”的方式操控账号。由于其不具有明显区分度,我们在特征研究中不使用这类应用。
在如上所述的分类基础上,我们定义了“白名单率”“黑名单率”两个特征:
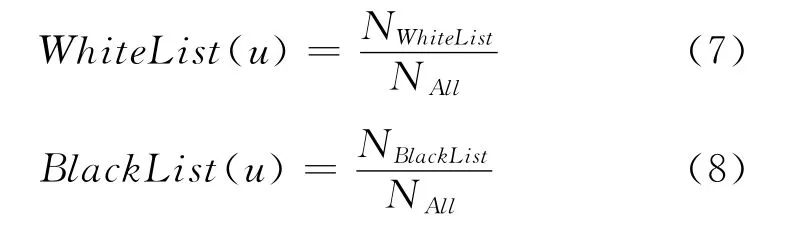
NAll是用户u发布的微博总数。NWhiteList是通过白名单发送的微博总数,NBlackList是通过黑名单发送的微博总数。根据预期,垃圾用户具有较高的黑名单率和较低的白名单率。
微博相似度
在Wang的研究中[3],使用了编辑距离计算微博的重复度,并以此作为检测特征。但在中文微博中,用户很少发布重复消息。我们应用余弦距离计算用户微博相似度,如式(9)所示。该特征计算了用户u所发布的n条微博之间的余弦相似度均值。

微博用字多样性
老佛爷何等人物,一听就火大了,一个江湖人物还敢如此摆架子?幸亏太监建议,说程廷华是孝子,他母亲马上七十大寿了,不如在他母亲身上做点文章。于是慈禧就派人做了一块大匾,书“节孝可风”四个字,刻太后金印,由宫里派人,宫宝田带队,吹吹打打给程廷华的母亲送了过去,声势把半个北京城都轰动了。
为了研究正常用户与垃圾用户在微博消息的用词(字)上有无差异,我们定义了用字多样性这个特征,见式(10)。由于微博消息具有长度短、用词不规范等特点,我们以字为最小分割单位,并在处理前删除消息中的URL链接。

假设用户u一共发了n条微博,每条消息的长度记为leni,则全部消息的总长度为同时,统计这些消息中非重复的单字数,记为cntd。
分类器与检测
垃圾用户的检测问题,可以视为一个分类(Classification)问题。假设微博用户的全集为U,类别集合C={Cspam,Cnormal},Cspam表示垃圾用户、Cnormal表示正常用户。垃圾用户的检测问题,即为求一个分类函数F,将U中的微博用户影射到类别C上。

上述影射函数F即代表了一个分类器,它可由机器学习算法习得。在本研究中,选用支持向量机(SVM)算法,它是一种有监督的机器学习算法,可以解决分类、回归等问题。对于分类问题,SVM通过预定义核函数的非线性变换,将输入空间变换到一个高维空间,在后者中求广义的最优分类面[7]。常用的核函数主要有三种:多项式函数(Polynomial)、径向基函数(Radial Basis Function)和Sigmoid函数。
基于SVM分类器的垃圾用户检测流程如图2所示。

图2 垃圾用户检测流程
检测可分为“训练”“分类”两个阶段。在训练阶段,我们对采集的微博用户数据进行标注,提取3.1节所述的检测特征。接着,用SVM训练分类器并对其效果进行评价,如有必要,将选择新的特征(集)并重新训练分类器。在检测阶段,提取待检测用户的特征,并使用训练阶段得到的SVM分类器进行分类,分类结果(Cspam或Cnormal)即为检测结果。
4 实验与分析
4.1 数据的采集与标注
我们使用OAuth2和API开发了新浪微博采集器,它的首要任务是搜集一些用户样本。微博的API提供了“public_timeline”接口,它会随机返回最新发言的20个用户及其微博信息。我们使用该接口,于2011年12月20日进行了用户数据的采集。经过去重处理后,共包含145 317个微博用户、1 522 092条微博。
上述采集只能获取部分活跃用户的最新微博信息,却并不包含用户的全部消息。此外,如3.1节所述,用户的表现行为与其注册时间有一定关联。为此,我们在2012年6月23日进行了二次采集。本次我们使用“user_timeline”接口,它根据第一次采集的用户ID,获取用户头像等资料、粉丝数等信息,并抓取用户最新发布的100条微博。本轮采集后,共包含125 683个有效用户、4 657 811条微博(新浪会定期清理垃圾账号,导致用户数减少)。
为了将二次采集的数据用于分类器,随机抽取了3 000个用户作为实验的数据集。为了获取客观、准确的标注结果,开发了标注平台,并邀请3位评价者对实验进行随机、交叉标注。标注遵循如下标准。
1)垃圾用户
标注值为-1,其行为特征为:转发大量广告、炒作消息;发布的微博具有明显的商业意图(如商品推介);发送或转发大量低质微博(如心灵鸡汤)。
2)正常用户
标注值为1,其行为特征为:发布较为贴近生活的微博(如聚会、心情等);在转发微博时,包含了个人的见解、评价(转发加评论);与他人存在较为真实的互动(如相互@、评论)。
3)不确定用户
标注值为0,若评价者认为账号难以区分,可将其标注为“不确定用户”。该类用户可能同时具有垃圾用户、正常用户的部分行为。
在标注者完成标注后,我们对数据进行了筛选与清理:首先,选择出至少2位评价者给出一致标注值的用户账号;其次,去除标注结果为“不确定”的账号。经过上述处理后,共剩余2 471个用户,本研究使用它们作为训练、测试数据。
4.2 实验结果
本研究使用LIBSVM[8]软件训练分类器。在效果的评价方面,选用准确率(Accuracy)、召回率(Recall)和F值。为了说明指标在本研究中的意义,考虑如表1所示的混淆矩阵。

表1 混淆矩阵
其中,准确率(Accuracy)描述了分类器将垃圾用户、正常用户正常分类的百分比。

召回率(Recall)表明了检测出的垃圾用户中,真实垃圾用户的百分比。

F值则综合考虑了准确率和召回率。

在明确了指标之后,我们从标注数据集上提取出第3节提出的各种特征,并采用10折交叉验证的策略,对分类器进行训练、验证。表2记录了两组实验结果:F_ALL和F_OPTIMAL。

表2 分类器实验结果
在第一组实验,F_ALL中,我们选择了第3节提出的全部12个特征训练分类器。实验结果如表2第1行所示:分类器的准确率达到93.46%,召回率为97.64%。
在进行该实验的过程中,我们发现部分特征具有“负效果”,会降低分类器的准确率。为了找出最优的特征组合,我们使用Wrapper[9]策略对12种特征进行选择:首先,求出特征组合的幂集,它共包含212+1=8 192个特征组合;其次,使用上述每一种特征组合训练分类器,对用户进行检测,计算分类结果的F值;最后,选出F值最高的特征组合,作为最优特征组合。最优组合共包含7个特征,如表3第1列所示。
为了验证最优组合中不同特征的贡献,我们单独使用每一特征训练分类器,并计算其F值,如表3第2列所示。从表中不难发现:应用黑名单率、纯粉丝度等本文提出的特征排名较为靠前,说明其具有较好的区分度。
在上述研究的基础上,我们进行了第二组实验。使用如表3所述的最优特征组合作为特征集合,训练、测试分类器。实验结果见表2的第2行,F_OPTIMAL。与第一组实验对比,准确率提升到了94.4%,召回率为97.71%。

表3 最优特征组合
在3.1.2节,我们提出了“用户头像特征”,但在最特征优组合中却不包含该特征。相反,前人提出的“简介”“微博域名”等特征却具有较好的效果。为此,我们对这三种特征进行了统计研究,结果如图3所示。在全部测试数据中,只有约3%的用户使用了默认头像,特征数据的不均衡导致它失去了应有的区分度。相反地,“简介”“微博域名”等特征的分布相对均衡,具有一定的区分度。
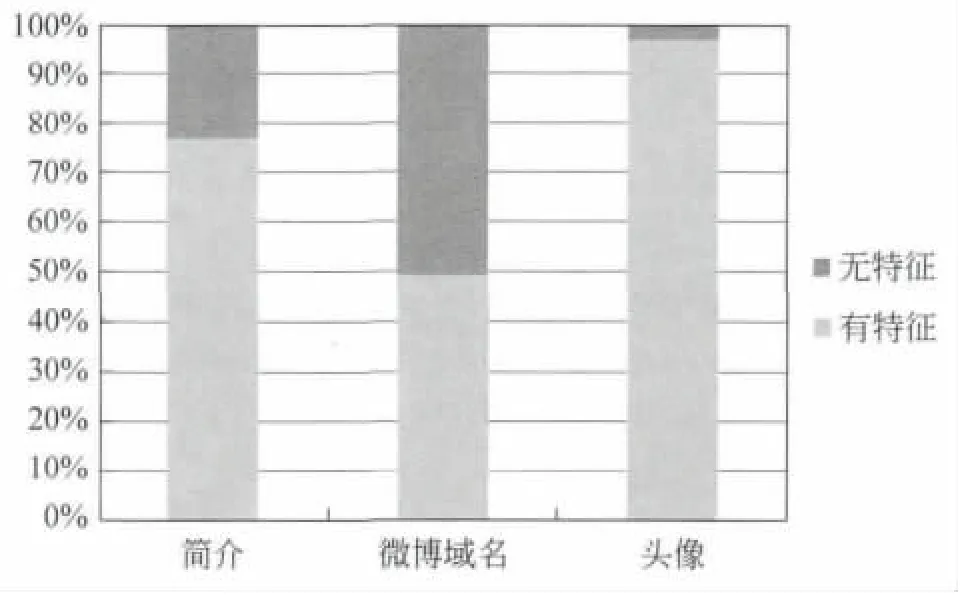
图3 用户资料特征的统计特征
4.3 特征分析
用户图特征
由4.2节实验可知,本文提出的“纯粉丝度”比前人提出的“用户权威度”更能显著区分垃圾用户。在中文微博中,许多用户选择了“互粉”“刷粉”等不正当手段来提高自身人气。纯粉丝度能很好地过滤掉“互粉”导致的“假人气”,因而具有更好的区分度。另一方面,为了更好地伪装自己,垃圾账号之间往往会互粉,形成错综复杂的关系网,造成受到高度关注的假象。因此,本文提出的“用户关注度”特征并没有取得预期的效果。
用户资料特征
本文提出的“近期活跃度”特征效果良好。垃圾用户的确会使用早期注册的“沉睡账号”发布垃圾消息。而本文提出的“用户头像”特征效果不佳。如4.2节所述,用户头像的分布极不均匀,致使该特征很难表现出应有的区分度。
微博内容特征
本文提出的“应用白名单率”“应用黑名单率”均具有很好的区分度。首先,手机客户端的应用门槛和管理成本阻碍了垃圾用户。其次,确实有大量的垃圾微博是通过黑名单中的应用传播的。此外,传统的“微博相似度”效果不佳。本文提出的“微博用字多样性”考虑了用户的微博用词习惯,取得了较好的效果:正常用户的微博话题广泛、用词随意,多样性较高;垃圾用户传播的信息较为单一,用词单调。
5 总结和展望
本文研究了中文微博客中垃圾用户的检测问题。研究从用户图、用户资料、微博内容三个方面提出了7种新的垃圾用户检测特征。利用上述特征训练的SVM分类器,取得了较好的准确率和召回率。实验表明,本文提出的“纯粉丝度”“用户近期活跃度”等5个特征具有良好的区分效果。
在实验与研究中,我们也遇到了一些问题:(1)对采集数据的标注依靠人工判别,工作量巨大。有必要寻找一种更好的实验数据标注方法。(2)在本文中,垃圾用户分类器的召回率较为理想,但分类器的准确率只有94%,仍有一定上升空间。我们将在未来的工作中对上述问题进行更为深入的探索与研究。
[1]新浪科技.新浪微博用户数超3亿 [EB/OL].2012-05-16.http://is.gd/Qfn4Z9.
[2]Grier C,Thomas K,Paxson V,et al.@spam:The Underground on 140Characters or Less [C]//Proceedings of the 17th ACM Conference on Computer and Communications Security (CCS 2010).New York,US,2010:27-37.
[3]Wang A.Don't follow me:Spam detection in Twitter[C]//Proceedings of the International Conference on Security and Cryptography.Athens,Greece,2011:142-151.
[4]Song J,Lee S,Kim J.Spam Filtering in Twitter Using Sender-ReceiverRelationship [M].Berlin,German:Springer,2006:301-317.
[5]王宇,陆余良,郭浩,等.中文微博僵尸粉检测技术研究[C]//中国自动化学会.第三届全国社会计算会议、平行控制会议、平行管理会议论文集.北京:中国自动化学会,2011.
[6]Benevenuto F,Magno G,Rodrigues T,et al.Detecting Spammers on Twitter[C]//Proceedings of Seventhannual Collaboration,Electronic Messaging,Anti-Abuseand Spam Conference(CEAS 2010).Redmond,US,2010.
[7]张学工.关于统计学习理论与支持向量[J].自动化学报,2001,26(1):32-41.
[8]Chang C.LIBSVM—A Library for Support Vector Machines [EB/OL].2006-2012.http://is.gd/rocwn9.
[9]Guyon I,Gunn S,Nikravesh M.Feature extraction,foundations and applications[M].Berlin,German:Springer,2006:188-191.
猜你喜欢
数学小灵通(1-2年级)(2021年11期)2021-12-02
科普童话·学霸日记(2021年2期)2021-09-05
派出所工作(2021年4期)2021-05-17
当代陕西(2019年24期)2020-01-18
电子技术与软件工程(2019年18期)2019-11-18
中国惯性技术学报(2018年4期)2018-11-08
小太阳画报(2018年10期)2018-05-14
电子技术与软件工程(2017年14期)2017-09-08
CHIP新电脑(2016年3期)2016-03-10
航天返回与遥感(2014年5期)2014-07-31
