
基于传播模拟的消息流行度预测
2014-10-15 01:52:30万圣贤郭嘉丰兰艳艳程学旗
中文信息学报 2014年3期
万圣贤,郭嘉丰,兰艳艳,程学旗
(1.中国科学院 计算技术研究所,北京100190;2.中国科学院大学,北京100190)
1 引言
近年来,在线社交网络快速发展,已经逐渐成为人们发布和获取信息的主要平台之一,这也为研究社会网络的人们提供了良好的实验平台。在较为流行的微博客网站(Twitter,新浪微博等)中,每个用户可以一次性发布不多于140字的消息,同时,用户可以使用follow的方式订阅其他用户发布或分享的消息并从其订阅的消息中选择一部分分享给其follower。正是由于这种递归的口口相传(word of mouth)的分享行为,一个用户发布的消息可能传播到整个网络,从而使得社交网络成为有效的消息传播途径。
社交网络上每天新产生数以亿计的消息,这些消息的流行度具有很大的差别[1]。如果能够准确预测一条消息的流行度,将对于信息推荐、病毒式营销以及网络舆情预警等应用有着重要的意义。一种常用的消息流行度的定义是消息的被转发(分享)次数,所以消息流行度可以认为是用户转发行为的累积效应。然而消息的传播是用户和用户,用户和消息之间相互作用的结果,影响用户转发行为的因素非常复杂,这使得消息流行度预测成为一个非常困难的问题[2]。本文中,我们尝试用一种新的思路来解决这个问题,我们使用机器学习的方法将可能影响用户转发行为的因素融合在一起,得到用户接收消息后的转发概率,并结合经典的传播模型在真实的社会网络中对消息的传播进行模拟,从而完成消息流行度的预测。我们在Twitter数据集上进行了实验,结果表明,相对于传统的分类方法(logistic regression),我们的方法取得了更高的准确度和稳定性。
本文的主要贡献是提出了一种通过学习用户转发行为并结合传播模型模拟消息传播过程从而进行消息流行度预测的方法。和之前方法的不同点在于,我们基于特定的传播模型使用机器学习的方法学习消息传播的微观性质,并将微观性质应用于模拟消息传播的宏观涌现,从而更充分的利用了社会网络的结构和用户特征信息并取得了更好的预测效果。
2 相关工作
关于社交网络上消息传播机制和消息流行度预测问题目前已经有很多研究工作,一部分工作侧重于分析消息传播的宏观性质,例如,消息转发数的增长模式、消息传播与网络结构的关系以及影响传播的用户和消息特征等,并建立模型来模拟和预测消息流行度的增长曲线[1-3]或直接使用机器学习的方法预测消息的最终流行度[4-5];另一部分工作侧重于分析影响消息传播的微观性质,主要集中于用户转发行为的分析和预测[6-7]。
Suh[8]等人对可能影响转发行为的特征做了大量的统计分析,发现消息内容、用户度分布等特征对转发行为有一定影响。Hong[5]等人将消息流行度预测问题形式化为分类问题,并使用logistic regression分别对消息是否被转发和消息转发次数两个目标进行了预测。Bakshy[4]等人使用URL的流行度度量用户的影响力,并使用回归树模型(regression tree model)对其进行预测,根据实验结果,Bakshy认为针对特定用户或URL的流行度预测是不可靠的。Lerman[2]等人对digg.com上的用户浏览行为进行建模,提出了一个模拟用户浏览行为的随机模型,并利用消息的初始传播信息来预测消息的最终流行度。然而,这些基于宏观角度的流行度预测方法没有能够充分考虑消息传播的微观过程。
作为微博上消息传播的主要方式,转发(retweet)行为的分析和预测是人们关注的热点之一。Yang[6]等人使用半监督学习的方式预测特定用户是否会转发一条消息。Galuba[7]等人同样对用户的转发行为建立概率模型并进行预测。然而,这些工作主要关注转发行为预测结果的准确率和召回率,并没有尝试预测消息的流行度,这些方法也不能直接应用于消息流行度预测。
3 传播模型
在许多在线社交网络尤其是微博客上,用户的转发行为是消息传播的主要途径。用户从其follow的用户(followee)那里接收消息,并从其接收到的消息中选择一部分转发给其所有的follower,从而形成传播级联(cascade)。
我们记社会网络为有向图G(V,E),其中V为节点集合,也就是所有用户集合,E为有向边集合,也就是用户关系集合。定义fd(u)为用户u的followee集合,fl(u)为用户u的follower集合。在常见的传播模型中,每个节点通常具有两种状态,激活和未激活状态,初始时V中大部分节点为未激活状态,消息从已经被激活的节点开始传播,根据不同的假设,主要包括以下两种传播模型[9]。
1.线性阈值模型(linear threshold model,LT模型)。LT模型假设用户u的每个followee v对该用户u有一定的影响力buv。每个用户u有随机的被激活阈值θu,传播的每一步中,假设fd(u)中当前被激活的所有用户为active_fd(u),那么如果则用户u被激活。激活了的用户u会在传播的下一步中对fl(u)中节点的状态产生影响,直到没有新的节点被激活为止。
2.独立级联模型(independent cascade model,IC模型)。IC模型假设每个节点u以概率puv独立的受到其followee节点v的影响。如果节点v在某一步t被激活,在t+1步中,v有一次以概率puv激活节点u的机会,直到没有新的节点被激活为止。
在微博客的消息传播场景中,由于“RT@”等标记的存在,我们明确的知道当前转发用户是受到哪个上层用户的影响而转发,可以较为直接的使用概率模型学习转发概率。另外,LT模型中用户被激活的概率随着其followee的激活线性增长,然而在微博客中,除了用户和用户之间的影响力,消息内容对转发行为有很大的影响,同一内容对同一用户的多次曝光起到的边际效用往往是衰减的,Ler-man[10]等人对Digg数据的分析也证明了这一点。所以,我们使用IC模型进行传播模拟。
此外,经典的IC模型中,用户只有一次被激活的机会,然而在消息的转发行为中,同一用户可能多次转发同一消息,用户的多次转发会增加其follower看到消息的概率从而增加其follower的转发概率,最终对后续的传播过程带来影响。所以,在我们的场景中我们使用经典IC模型的变体,允许用户被多次激活,并且用户的每次激活都会尝试激活其所有的follower。
在IC模型中,任意一条有向边(follow关系)(u→v)上都存在激活概率puv。IC模型本身并没有指定如何获取这些概率参数,不同的应用场景中存在不同的参数估计方法。在本文的消息传播场景中,对于同一条有向边(u→v),不同消息的转发概率存在较大差别,所以我们需要考虑消息本身的因素,也就是说我们需要获取的参数是puvm,其中,m表示一条特定消息。
4 转发概率学习
本节中我们具体讨论IC模型中转发概率的学习,包括正负例选取、概率模型以及特征选择。
4.1 正负例选取
为了学习转发概率,首先我们需要找出用于学习的正例和负例。我们结合具体的消息传播过程进行说明。图1是微博客中消息传播的示意图。图中的每一棵树表示一条消息的传播过程,树的根节点表示消息的发布者,树中的有向边表示消息的传播方向,也就是从消息的发布者或者转发者(传播者)指向其所有的follower。树中所有的节点都是该消息的接收者,其中黑色节点表示发布者或者转发者,用户的每一次转发都会引入新的接收者(除非该用户的follower数为0),所以,树中的所有叶子节点用户接收到消息但没有转发,所有内部节点用户接收到消息并进行转发。需要注意的是,因为存在同一用户多次接收或者多次转发同一条消息的情况,这里的传播树并不等同于消息在用户关系图上传播形成的子图,多次接收或多次转发同一条消息的用户在树中对应多个不同节点。
我们选择所有消息传播树中的非叶子节点(接收并且转发的用户)作为正例,所有叶子节点(接收但不转发的用户)作为负例。这种正负例的选择方式和修改后的IC模型吻合,否则,学习得到的概率会存在系统偏差。为了便于说明,我们还定义如下概念。

图1 消息传播示意图
原始用户:表示消息的原始作者,也就是树中根节点表示的用户,例如,na;
上层用户:表示一个消息接收者从谁那里接收该消息,也就是树中节点的父节点,例如,用户na是nb的上层用户,nc是nd的上层用户。类似的,还可以定义原始消息和上层消息。
4.2 模型与特征
我们使用最大熵模型[11]学习用户接收到消息后进行转发的概率。最大熵原理是概率模型学习的一个准则,就是在所有可能的模型中选择熵最大的模型。最大熵模型是对数线性模型(log linear model)的一种,可以用于学习不同特征下不同输出的概率。
我们认为Twitter上的转发行为主要是由当前用户对原始消息的信任度和兴趣度,上层用户对当前用户的影响力以及当前用户的活跃度三个因素决定。基于这一认识,我们在模型训练时使用了以下特征。
1.用户特征
用户特征包括用户的follower数,用户的followee数,用户历史发帖活跃度,用户历史转帖活跃度,用户历史被转发数,用户对用户历史转发数,当前用户和上层用户是否互相follow。在我们的传播过程中存在三种用户(当前用户,上层用户和原始用户),上述用户特征中,除后两个之外,都对这三种用户分别提取。后两个特征针对当前用户和上层用户提取。
2.消息内容特征
消息内容特征包括内容长度,内容是否包含hashtag,内容是否包含URL,消息的话题分布。
3.消息早期传播特征
消息早期传播特征包括消息从发布到被第5次转发经历的时间,消息发布后5分钟内的总转发数。
4.其他特征
其他特征包括原始消息的发布时间,上层消息的传播路径长度。
5 实验
5.1 数据预处理
我们使用Twitter API采集了Twitter上2011年12月16日到12月30日之间(两周)的部分数据,数据内容包括Twitter用户信息,Twitter用户构成的关系网络以及这些Twitter用户这两周内发布的所有消息。数据的总体情况见表1。

表1 Twitter数据信息
Twitter API返回的结果中包含每条消息是否为转发消息,如果是转发消息还返回其上层消息的ID,然而,Twitter用户也可以手动添加“RT@”等标记或者使用第三方应用进行消息转发,这些转发消息的上层消息ID是无法通过API直接获取的,我们解析转发消息内容中包含的“RT@”等标记,寻找上层用户并从上层用户的发布消息列表中找到该转发消息的上层消息。获取了每条转发消息的上层消息之后,我们沿着消息的传播路径回溯,得到每条转发消息的原始消息,如果转发路径中有间断,则找不到原始消息,我们根据是否包含“RT@”等标记判断一条消息是否为原始消息。这样,我们可以为每一条原始消息构建其传播树,我们去除掉转发次数小于5的原始消息,最终总共找到1 131条原始消息。图2是消息转发数的分布图,服从幂律分布。然而,我们采集到的Twitter用户并不是非常活跃,消息最多转发次数只有不到200次。我们取第一周的原始消息作为训练集,第二周的原始消息作为测试集。
5.2 Baseline
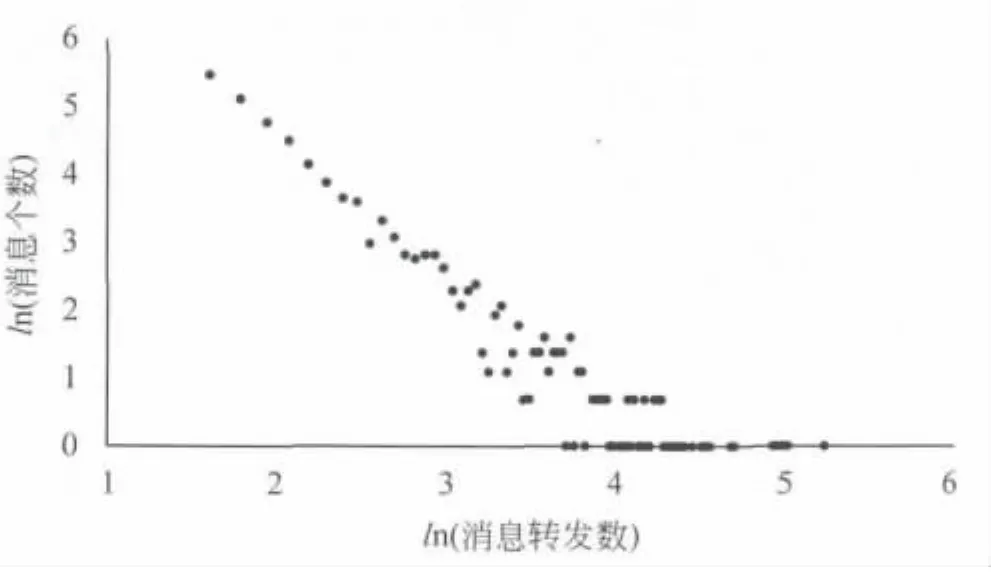
图2 消息转发次数分布图
我们选择 Hong[5]等人使用的logistic regression方法进行对比,这种分类方法直接根据原始消息的特征判断消息的流行度类别。由于这种方法不涉及到传播过程,所以我们提取特征的时候仅提取了跟原始消息相关的特征,包括原始用户特征、所有的消息内容特征、消息早期传播特征以及消息发布时间特征。
我们将原始消息根据最终转发数分为不同类别,由于转发数是服从幂律分布的,如图2所示,我们根据图2中横坐标刻度为2.5和3.5的地方将消息分为3个类别,用类别0,1,2表示。我们使用了多种评价指标对结果进行评价。
5.3 实验结果
为了测试特征的区分度,我们首先将最大熵模型用于二分类问题,判断给定用户接收到一条消息后是否会进行转发。由于正例的数量远远小于负例的数量,我们从负例集合中随机采样了和正例数量相等的负例用于训练和测试,在测试集上的分类精度为84.24%。可见,我们提取的特征具有较好的区分度,可以进一步应用于转发概率的学习。
在传播模拟过程中,我们并不是直接判断用户是否转发,而是学习用户转发的概率,然后使用IC模型基于真实的社会网络进行传播模拟。为了保证与真实概率的一致性,训练最大熵模型时,我们使用了训练集中所有的正例和负例。我们对每条消息模拟10次,并取10次模拟的平均结果作为最终的预测转发数。表2中列出了传播模拟和logistic regression(LR)两种方法预测结果的混淆矩阵,其中,每一行表示一个真实类别中的元素在两种分类方法下被分到各个预测类别的数目。
进一步地,我们使用准确率,召回率和F-measure对各个类别上的分类结果进行评价,评价结果见表3。
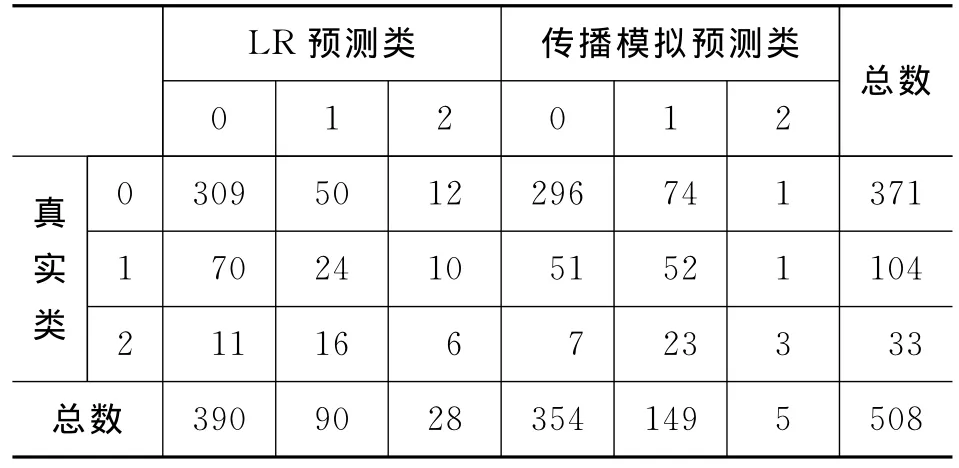
表2 分类结果的混淆矩阵
从实验结果中我们可以看出,我们的方法在准确率上一致地优于logistic regression方法,尤其是在第1,2类这些转发较多的消息类别上。在召回率上,我们的方法在第1类上取得了相对较好的效果,然而在第2类上效果欠佳。最后,我们分别使用微平均(micro-averaging)和宏平均(macro-averaging)方法计算F-measure。相对于微平均,宏平均能更好地处理类别间数据量不平衡带来的问题,所以更加适用于我们的场景。从结果中可以看出,不管是微平均还是宏平均,我们的方法总体上都优于logistic regression方法,尤其是宏平均,我们的方法显著优于logistic regression方法。
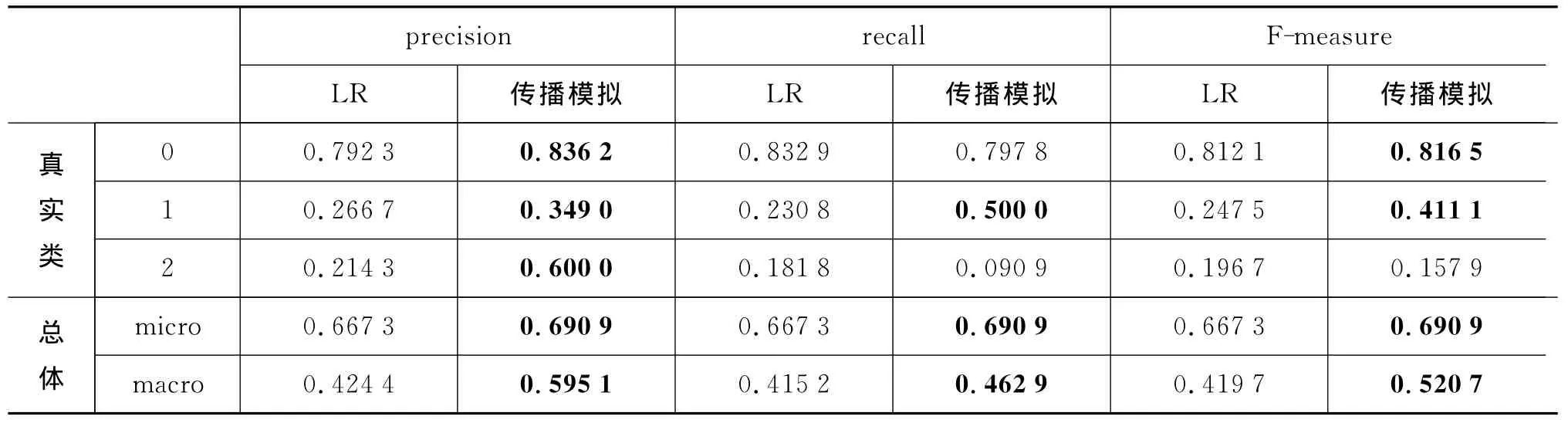
表3 分类评价指标结果
此外,由于这3种类别之间存在顺序关系(ordinal),第0类<第1类<第2类,简单的使用准确率和召回率并不合适,比如如果将真正属于第0类的消息误分到第2类应该比误分到第1类带来的损失更大。所以,我们再使用MSE(mean squared error)对结果进行评价,如表4所示。
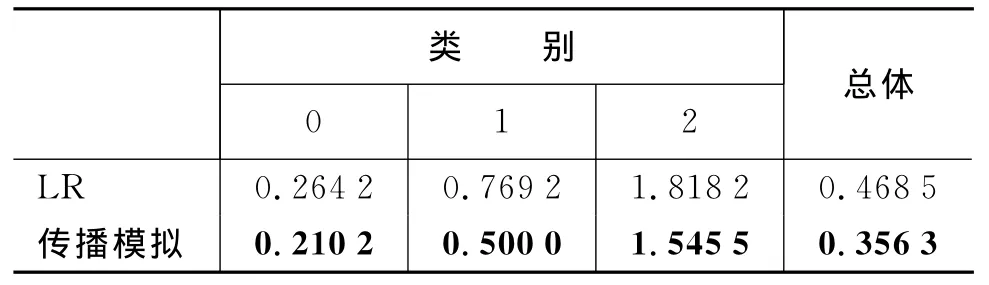
表4 评价指标MSE的结果
我们的结果在MSE指标下同样一致地优于logistic regression方法,值得注意的是,我们的方法虽然在第2类的召回率和F-measure上比logistic regression差一些,但是在MSE上表现更好,说明我们的方法更加稳定,也就是说分类错误的消息不会离真实类别偏差太远。
然而,不管是使用logistic regression的方法还是传播模拟的方法,都没能精确的预测出一条消息的流行度,尤其是流行度较高的消息,召回率都比较低。这也再次说明了,影响消息流行度的因素很多,对其进行精确预测是很困难的。
Salganik[12]等人的实验表明,流行度受到早期传播的偶然性因素影响很大,很多消息流行度预测方法利用消息流行度的前期趋势进行预测。所以,我们也统计了Twitter数据中早期流行度和最终流行度之间的关联关系。从图3中拟合的曲线可以看出,消息的早期流行度和最终流行度的确是存在正相关关系的,然而对于具体的消息,这种相关关系却差别很大,这也给预测增加了难度。
总的来说,由于我们的方法融合了大量的特征并且在真实的社会网络上进行传播模拟,所以更充分的利用了社会网络的结构和用户特征信息,从而能够更加准确稳定的进行消息流行度预测。
然而我们的方法也存在一些问题,多次传播模拟结果的平均使得预测结果的分布更加平滑,另外,学习微观转发概率时的目标和预测消息流行度的目标之间存在差别,这使得预测的结果和真实数据的分布之间存在差别,所以我们的结果中分到第2类的消息较少,而且这些消息虽然正确被分类,但是预测的流行度比真实流行度偏小。
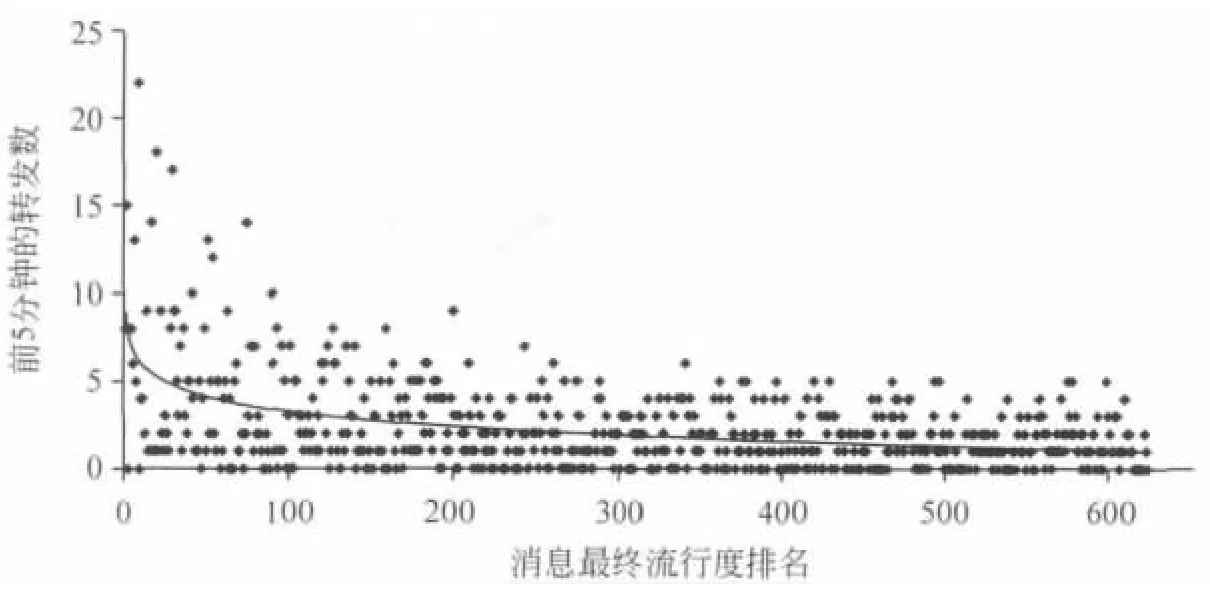
图3 消息最终流行度排名与前5分钟转发次数
6 总结和未来工作
本文提出了一种基于传播模拟的消息流行度预测方法,首先使用最大熵模型学习用户接收消息后进行转发的概率,然后使用IC模型对消息的传播进行模拟来预测消息的流行度。这种方法能够更充分的利用网络结构和用户特征信息,所以我们的方法取得了更好的结果,在准确率方面一致地优于logistic regression方法,并具有较高的稳定性。
然而,我们的工作中还存在一些问题,预测结果的分布和真实分布存在差别。另外,时间因素也是影响用户转发行为的重要因素,目前我们并没有对用户转发的时间进行建模,只是使用了传播层次来近似这一效果。在未来的工作中,我们会尝试解决这些问题。
[1]Wu F,Huberman B A.Novelty and collective attention[J].National Academy of Sciences,2007,104(45):17599.
[2]Lerman K,Hogg T.Using a model of social dynamics to predict popularity of news[C]//Proceedings of the ACM,USA,2010:621-630.
[3]Szabo G,Huberman B A.Predicting the popularity of online content [J].Communications of the ACM,2010,53(8):80-88.
[4]Bakshy E, Hofman J M, Mason W A,et al.Everyone's an influencer:quantifying influence on twitter[C]//Proceedings of the ACM,HK,2011:65-74.
[5]Hong L,Dan O,Davison B D.Predicting popular messages in twitter[C]//Proceedings of the ACM,2011:57-58.
[6]Yang Z,Guo J,Cai K,et al.Understanding retweeting behaviors in social networks[C]//Proceedings of the 19th ACM CIKM.Canada,2010:1633-1636.
[7]Galuba W,Aberer K,Chakraborty D,et al.Outtweeting the twitterers-predicting information cascades in microblogs[C]//Proceedings of the 3rd conference on Online social networks.USA:USENIX Association,2010:3-3.
[8]Suh B,Hong L,Pirolli P,et al.Want to be retweeted?Large scale analytics on factors impacting retweet in Twitter network[C]//Proceedings of the Social-Com.USA:IEEE,2010:177-184.
[9]Kempe D,Kleinberg J,Tardos Maximizing the spread of influence through a social network[C]//Proceedings of the ninth ACM SIGKDD.USA,2003:137-146.
[10]Ver S G,Ghosh R,Lerman K.What stops social epidemics[C]//Proceedings of the Fifth International AAAI Conference on Weblogs and Social Media.USA,2011:377-384.
[11]Berger A L,Pietra V J D,Pietra S A D.A maximum entropy approach to natural language processing[J].Computational linguistics,1996,22(1):39-71.
[12]Salganik M J,Dodds P S,Watts D J.Experimental study of inequality and unpredictability in an artificial cultural market[J].Science,2006,311(5762):854-856.
[13]Kwak H,Lee C,Park H,et al.What is Twitter,a social network or a news media?[C]//Proceedings of the 19th ACM,USA,2010:591-600.
[14]Wu S,Hofman J M,Mason W A,et al.Who says what to whom on twitter[C]//Proceedings of the 20th ACM,USA,2011:705-714.
猜你喜欢
机械工业标准化与质量(2022年6期)2022-08-12 02:07:42
中学生数理化·中考版(2022年6期)2022-06-05 06:49:10
中学生数理化·中考版(2021年6期)2021-11-22 07:52:30
国际眼科杂志(2021年9期)2021-09-15 03:24:42
新世纪智能(数学备考)(2021年4期)2021-08-06 09:04:50
新世纪智能(数学备考)(2021年4期)2021-08-06 09:04:50
装备制造技术(2020年2期)2020-12-14 03:09:16
通信产业报(2020年43期)2020-01-15 06:38:43
中国卫生(2015年12期)2015-11-10 05:13:34
中国卫生(2014年12期)2014-11-12 13:12:26
