
计算机程序抄袭检测系统的设计方案研究
2014-09-30 06:59:04张淑娟
吉林广播电视大学学报 2014年4期
张淑娟
(云南经济管理职业学院,云南 昆明 650106)
一、计算机程序抄袭检测系统相关技术理论概述
计算机程序抄袭检测系统的研发是为了进一步遏制越来越猖狂的抄袭现象,为良好的学术氛围构建一个检测平台。当前已经有诸多的计算机程序抄袭检测系统不断被研发出来,各种各样反抄袭手段也随之而出,因此在对计算机程序抄袭检测系统进一步研发的过程中,我们追求的不仅仅是能够检测相应的抄袭文档,还应该从性能、准确度以及检测效率等各个方面提升反抄袭检测系统的实用性。衡量一个反抄袭检测系统优劣的标准诸多,但是关键还在于程序的算法设计方面。我国现有的诸多计算机程序抄袭检测系统都是针对中文字符来设计相应算法的,而国外较为先进的计算机程序抄袭检测系统却是在英文环境之下进行开发的,难以为我国学术检测环境所应用。针对中英文在我国学术界的通用性,我国需要在此环境基础之上研发出相应的计算机程序抄袭检测系统。当前计算机程序抄袭检测系统相关核心技术主要有如下几种:
一是模拟匹配技术,模拟匹配技术在信息技术安全、信息检索以及数据挖掘等方面已经得到了广泛的运用,同时当前我国计算机程序抄袭检测系统也是在模拟匹配技术支持基础之上实现的,一个良好的计算机程序抄袭检测系统需要有一个精确的算法作为支撑,与此同时模拟匹配技术可以分为单模式和多模式匹配算法,其中单模式匹配算法指的是从在长度为N的字符串Y中找到与长度为M的字符串X有一定相似度的子串,如果有相符的字串就会相应的位置,如果没有找到相似的字串就会返回到零;其中多模式匹配算法指的是将字串集合P=(P1,P2,……P3),分别于字符串Z经过相匹配分析得到相似的字符串并回到相应的位置,如果没有找到相似的字串就会返回到零,多模式匹配算法与单模式匹配算法有所不同,多模式匹配算法可以同时计算多个字符串并进行匹配计算,可以大大提升计算机程序抄袭检测系统的检测效率和使用性能[1]。
二是相似度算法,随着当前我国计算机程序抄袭检测系统的日益完善,抄袭者开始不断变换抄袭手段,使用同义词替换、添加删除相应的字段、调换字符串之间的顺序等方式来逃避反抄袭检测系统,对此可以使用相似度算法原理来对计算机程序抄袭检测系统进行进一步的优化升级。相似度算法从一定程度上来说也是模式匹配算法中的一种算法模式,是对不同字符串中相似程度的计算方法,文本相似度计算方法主要有字符匹配相似度法、集合模型的相似度计算法、空间向量模型相似度计算方法等。
三是中文分词技术,在对文本抄袭进行反抄袭检测时,如果利用整句的方式对相关关键信息进行匹配相似度计算等,可能会使检测过程极为复杂且有检测信息片面等问题,从而大大降低了计算机程序抄袭检测系统的检测效率,对此,可以使用中文分词技术在对检测文本进行合理化分割的前提之下提升计算机程序抄袭检测系统的准确度和性能。中文分词技术主要包括了字符串匹配分词技术、统计方法的分词技术以及知识理解的分词技术等方法[2]。
二、计算机程序抄袭检测系统需求及功能分析
1.计算机程序抄袭检测系统中的核心技术
综合前人的研究以及本文对反抄袭程序的研究可以知道计算机程序抄袭检测系统设计的核心技术在于程序抄袭检测技术,从上述分析可以知道程序抄袭检测技术的重点在于相似度计算技术的选择与应用,相似度计算技术在计算机程序设计中的应用指的是运用计算机实现对不同两个程度文档、代码等各个方面的相似度匹配计算,这种方法已经被广泛地应用到数字技术、学术领域、软件工程代码管理以及知识产权保护等各个领域中,可见相似度计算技术在计算机程序抄袭检测系统的运用是至关重要的。但是在进行计算机程序抄袭检测系统设计开发时首先需要明确系统的需求分析和相应的功能分析[3]。
2.计算机程序抄袭检测系统需求及功能分析
(1)计算机程序抄袭检测系统使用需求分析
比如在学生提交所创作的电子文档类型的程序设计作业时,在没有对此实行反抄袭软件检测之前,教师难以从中了解到提交的这些电子文档类型程序设计作业哪些地方可能存在抄袭现象,因此在进行计算机程序抄袭检测系统设计开发之前需要将已有的所有文档进行相互对比匹配检测,最终可以给出不同程序文档之间的相似度匹配计算结果,一般都会以百分比的形式给出相应的似度匹配计算结果。与此同时需要考虑到计算机程序抄袭检测系统使用者的使用习惯和逻辑性思维,这就需要在完成不同程序文档之间的相似度匹配计算结果之后,对这些相似度计算结果进行一个方向性的排序,通过上述的计算分析处理就可以得到相似度最大的程度文档,以此可以综合性地高效、准确地确定存在抄袭现象的电子程序文档。
(2)计算机程序抄袭检测系统使用功能分析
从上述分析可以知道,在进行计算机程序抄袭检测系统开发设计时需要保障有如下几个方面的功能,以满足反抄袭检测系统的应用需求:
一是,选取并按照一定的顺序罗列出将要被计算机程序抄袭检测系统进行检测的程序文档文件名以及对应的文档路径等,对于这些罗列的程序文档可以进行后续的添加和删除,后续可以根据分析需求将指定的程序文档进行部分删除或者全部清空处理等[4]。
二是,开发设计具备对程序文档进行相似度计算的功能。首先需要对这些将要被计算机程序抄袭检测系统进行检测的程序文档进行相互匹配计算,即将所有文档进行相互的配对分析,然后在此基础之上对这些程序文档之间的相似度进行有效计算,最后将上述程序文档之间的相似度计算结果按照从高至低的顺序进行一一排列。在此将相似度匹配计算方法运用到计算机程序抄袭检测系统之中,可见这是该系统的核心功能所在。
三是,对上述程序文档相似度较高的对象进行进一步的细化对此处理分析。由于相似度较高的程序文档则说明这些程度文档具备较高抄袭度,因此在上述相似度匹配计算结果基础之上需要对其进行进一步的细化分析,从而准确地确认这些程序文档是否存在抄袭现象,可以将两个相似度最高的程序文档进行深入对比分析,并显示出相同部分来确定。对于相似度匹配计算结果较低的程序文档可以直接确定这些程序文档不存在相互抄袭的现象。
三、计算机程序抄袭检测系统设计方案
从上述分析可以知道我国计算机程序抄袭检测系统存在一定的可挖掘空间,面临中英文环境的冲击以及反抄袭检测系统的功能需求,本文将在此基础之上提出适用于中英文背景之下的计算机程序抄袭检测系统研发技术工具,该反抄袭检测系统设计的目的在于可以有效对程度文档中的中英文字符进行合理分割,进而实现相似度匹配的计算,最终设计出相似度匹配过程中的模糊匹配、分割匹配等计算模式,从而高效准确地对中英文字符文档进行检测,并进而根据所检测的各个层次的字符串按照规定的方式进行相似度计算,为抄袭现象的判断提供可靠依据。与此同时,计算机程序抄袭检测系统还需要为数据库提供中英文库存文档的存储、添加删除、信息资源库的文化更新以及用户信息资源的维护更新、文档筛选检测等方面的功能。据此可以对计算机程序抄袭检测系统的功能模块进行对应的开发设计[5]。
计算机程序抄袭检测系统的功能模块设计所需要服务的对象主要包括几个层面:
一是,计算机程序抄袭检测系统面向系统用户的功能设计,需要根据用户的需求提供用户注册功能、用户个人信息资源维护、信息更新以及修改完善、用户会员登录、信息资源程序文档的提交、检测结果的查询、操作处理等方面的功能。
二是,计算机程序抄袭检测系统面向系统管理员的功能设计,需要根据系统管理员的需求提供信息资源库中英文程序文档的添加删除、信息资源维护、信息资源信息表的及时更新等多个方面的操作处理功能,除此之外,还可以为系统管理员提供相关数据库的构建管理和系统用户操作处理等方面的服务功能。
三是,计算机程序抄袭检测系统检测运行实现的过程如下:首先系统管理员通过输入相应的口令登录到检测系统管理平台,然后将所要被检测的中英文文档添加进入相应的信息资源库,以此方便系统用户能够便捷地进行程序文档的检测。系统用户在完成系统平台注册登录之后便可以提供将要被检测的程序文档,计算机程序抄袭检测系统将用户的程序文档与信息资源库中的程序文档进行相似度匹配计算之后,可以得出相似度较高的程序文档。最后将这些相似度较高的程序文档进行进一步的两两对比深入分析,将最终结果通过计算机程序抄袭检测系统显示反馈给系统用户。
综上所述,可以将计算机程序抄袭检测系统开发设计为文档注册模块、筛选、抄袭检测以及后台信息资源维护模块等几个重要的模块,如图1所示,同时每一个模块相对独立地承担相应的功能,共同为反抄袭检测系统服务,从而为学术领域等提供最佳的反抄袭系统检测服务。
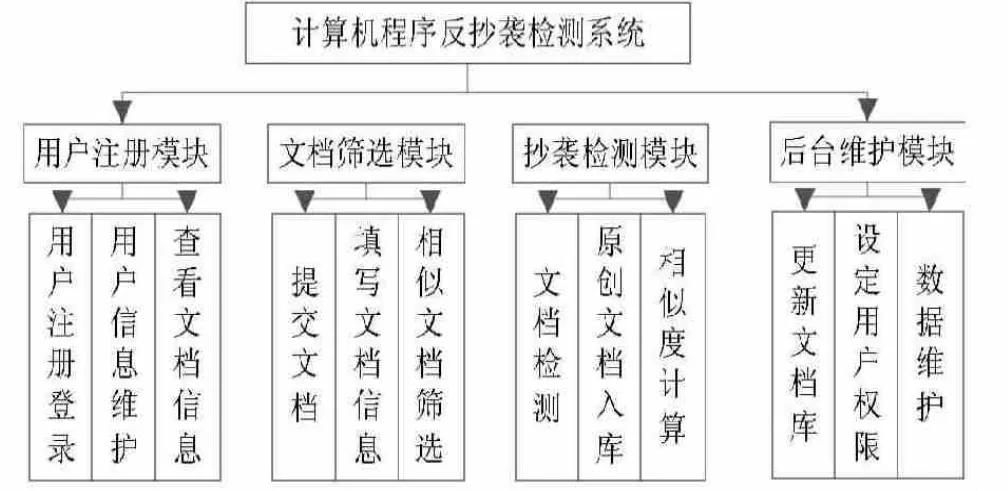
图1 :计算机程序抄袭检测系统模块方案
[1]房德安.计算机程序抄袭检测系统的设计方案分析[J].黑龙江科技信息,2013,(2):53-54.
[2]李雅慧,郭婷,孙丽颖.一种基于高频词和段落匹配的论文抄袭检测系统设计[J].现代经济信息,2009,(11):158-159.
[3]胡正军.程序代码相似度检测方法研究及应用[D].长沙:中南大学,2012.
[4]李旭东.程序相似度计算技术及其在教学中的应用[J].软件导刊(教育技术),2010,(4):111-113.
[5]祁俊,王晓英.抄袭检测系统对计算机类电子作业的影响分析[J].价值工程,2012,(8):76-79.
猜你喜欢
法制博览(2021年15期)2021-11-24 13:11:31
电子制作(2019年13期)2020-01-14 03:15:32
移动信息(2018年1期)2018-12-28 18:22:52
中央民族大学学报(自然科学版)(2018年3期)2018-11-09 01:16:38
知识产权(2016年6期)2016-12-01 06:59:49
专利代理(2016年1期)2016-05-17 06:14:09
专利代理(2016年1期)2016-05-17 06:13:57
山东工业技术(2015年21期)2015-07-27 08:18:10
燕山大学学报(2014年1期)2014-03-11 15:28:11
测绘科学与工程(2013年6期)2013-03-11 15:07:57
