
基于朴素贝叶斯分类器的纸病离线静态辨识方法研究
2014-08-15 06:48:14院金彪郑海英郭文强
中国造纸学报 2014年1期
院金彪 周 强 郑海英 郭文强 汤 伟
(1.陕西科技大学电气与信息工程学院,陕西西安,710021;2.察右中旗第一中学,内蒙古乌兰察布市,013550)
纸病检测主要是针对纸张外观缺陷,通过各种辨识方法,快速判断纸张的黑斑、孔洞、光斑、褶皱、边缘裂纹等纸病,对发现生产工艺中的故障、保证纸张质量以及纸病后期处理都有重要意义。
纸病辨识是纸病检测流程的关键环节,主要通过对纸病图像特征的提取、辨识,判断纸病类别。通常使用的纸病图像特征有灰度特征、几何特征、形状特征等,其中,灰度特征主要包括灰度均值、灰度方差等灰度统计量;几何特征主要包括图像位置、方向、周长、面积、长轴、短轴、距离等几何参数;形状特征主要有矩形度、圆形度、球状性、不变矩、偏心率等高阶统计量。传统方法的通用性差,对不同类型的纸病只能根据某一特定的特征量进行判断,如当使用背光源照射纸张时,黑斑与孔洞的灰度均值差距较大[1],因此,可用灰度均值区分这两种纸病,但是,相同条件下的孔洞与光斑纸病的灰度均值接近而不易区分,不过它们的灰度标准差的分布范围不同,可作为区分纸病的特征量。显然传统方法总是在寻找两两纸病间的特征分界点,不能用通用的标准去实现纸病辨识,而对于某些相似度高的纸病来说,更是难以寻找到某一合适的特征量来区分它们。同时,传统方法的鲁棒性通常较差,对周围的环境因素如光照强度变化适应性差。
本研究针对当前纸病辨识方法的通用性弱、鲁棒性差的问题,提出了基于朴素贝叶斯分类器的纸病离线静态辨识方法。该方法依据朴素贝叶斯分类器原理,首先通过对样本训练得到各种纸病特征量的条件概率分布,然后计算所检测到的纸病的特征向量属于各种纸病的后验概率,最后对各后验概率进行比较,实现各个特征量的信息融合,进而确定该特征向量所属的纸病类别。此外,在纸病辨识过程中,又增加了拒识域,将所求得的后验概率较为接近的纸病通过增加对其特征量的描述进行进一步判断,确保了纸病辨识精度。
1 朴素贝叶斯分类器原理和算法流程
1.1 朴素贝叶斯分类器原理
朴素贝叶斯分类器是一种简单且有效的分类方法,具有最小错误率的特点[2],可以预测一个给定样本属于某一类别的概率,其应用条件是假设所选的各特征量之间相互独立,主要是确定出给定的待分类项条件下各个类别出现的概率,概率最大值所对应的就是该特征所属的类别[3-5]。
设特征向量x={a1,a2,……,am},其中,每个a是x的一个属性,且a1,a2,……,am各自相互独立。有类别集合C={y1,y2,……,yn},P(y1|x),P(y2|x),……P(yn|x)即为所求概率,比较所得概率,取最大值所属的类即可。根据贝叶斯公式有:
(1)
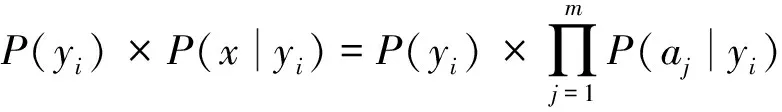
(2)
因为分母对于所有类别均为常数,因此,只要求分子最大值即可,所以有:
(3)
用常量M表示P(x)。由此可以看出,只要求得maxP(x|yi)×P(yi),即可确定其所属类别,实现信息融合。

图2 纸病辨识算法流程
1.2 朴素贝叶斯分类器的算法流程
朴素贝叶斯分类器算法流程如图1所示,整个过程分3个阶段:
(1)前期准备阶段,主要完成样本的确定和特征量的选取。分类器的质量很大程度上取决于特征量、训练样本质量及个数。
(2)分类器训练阶段,主要计算各特征量所属某一类别的条件概率。
(3)分类阶段,主要应用朴素贝叶斯分类器原理进行后验概率的计算并比较各后验概率大小,将最大值作为判断某特征向量属于哪种纸病类别的依据。
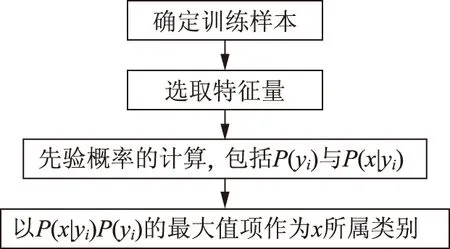
图1 朴素贝叶斯分类器算法流程
2 纸病辨识
2.1 纸病辨识算法流程
纸病辨识算法流程如图2所示。首先对纸病图像进行预处理,然后对预处理后的图像进行特征提取,纸病特征包括灰度均值、灰度标准差、不变矩、熵等,其次将得到的各个纸病的特征值融合成一个特征向量,最后根据朴素贝叶斯分类器原理对纸病进行分类。
2.2 主要纸病及预处理
摄像机所能检测到的纸病主要是处在纸张表面的外观纸病。外观纸病很多,本研究只针对常见的3种纸病即黑斑、光斑、边缘裂纹进行研究。
纸病的预处理过程主要是将采集到的灰度图像通过阈值分割后,利用均值滤波去除噪声,然后对图像进行边缘检测,进而确定纸病区域。阈值分割、均值滤波和边缘处理后的纸病图像分别如图3~图5所示。
2.3 纸病图像的特征提取及概率分布
2.3.1纸病特征量的提取
检测到纸病后,采用朴素贝叶斯分类器原理对纸病进行分类,主要根据纸病的特征向量来确定纸病类别。本研究涉及的纸病的特征向量由灰度均值、灰度标准差、不变矩、熵4个特征量组成。
(1)灰度均值
纸病图像预处理后,对纸病区域的各像素点灰度相加并取其平均值作为灰度均值(M),其计算公式如下[6]:
(4)
式中,S表示纸病区域;N表示纸病区域所有像素点个数;g(i,j)表示纸病区域内位置为(i,j)处的像素灰度,下同。
(2)灰度标准差
灰度标准差(E)是用来描述纸病区域内纸病灰度分布的离散集中程度,其计算公式如下:
(5)
(3)不变矩
图像区域的某些矩对平移、旋转、尺度等几何变换具有一些不变的特性[7],因此,矩的表示方法在物体分类与识别方面具有重要意义。在纸病识别中,不同纸病的不变矩差异很大,因此,把不变矩作为纸病特征描述的一个特征量。

图3 阈值分割后的纸病图像

图4 均值滤波后的纸病图像

图5 边缘检测后的纸病图像
对二维离散函数f(x,y),零阶矩可表示为:
(6)
中心矩的定义为:
(7)
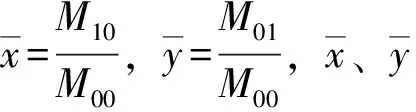
(8)
利用归一化的中心矩,可获得以下7个不变矩:
φ1=μ20+μ02
(9)
(10)
φ3=(μ30-3μ12)2+(μ03+3μ21)2
(11)
φ4=(μ30+μ12)2+(μ21+μ03)2
(12)
φ5=(μ30-3μ12)(μ30+μ12)[(μ30+μ12)2-3(μ21+μ03)2]+(3μ21-μ03)(μ21+μ03)[3(μ30+μ12)2-(μ21+μ03)2]
(13)
φ6=(μ20-μ02)[(μ30+μ12)2-(μ21+μ03)2]+4μ11(μ30+μ12)(μ21+μ03)
(14)
φ7=(3μ21-μ03)(μ30+μ12)[(μ30+μ12)2-3(μ21+μ03)2]+(3μ12-μ30)(μ21+μ30)[3(μ30+μ12)2-(μ21+μ03)2]
(15)
(4)熵
熵是用来表示任何一种能量在空间分布的均匀程度,能量分布得越均匀,熵越大。一个体系的能量完全均匀分布时,这个系统的熵就达到最大值。图像处理中采用信息熵的概念[9],表示图像灰度分布的均匀程度,且图像种类不同,其熵也不同,如某图像G的熵定义为:
(16)
式中,n取值为256,表示256种灰度级;pk表示灰度等于k的像素与图像总像素之比。信息熵表示图像所包含的平均信息量,表征图像信息的丰富程度。不同纸病之间的信息熵不同,而同种纸病之间的信息熵基本相同。
2.3.2概率分布的确定方法
不变矩本身有7个量,首先计算这7个量的条件概率分布,然后将这7个概率分布相乘就是不变矩这一特征量的条件概率分布,计算方法如下:
(17)
(18)
式中,i表示纸病类别;j表示不变矩7个量中的1个;Sij表示所取第i类纸病样本的第j个矩中与所检测到纸病的第j个矩相同的样本个数;S表示该类纸病的样本总数。
灰度均值、灰度标准差、熵这3个特征量的条件概率分布的确定方法相同,其计算方法如下:
(19)
式中,i表示纸病种类;k表示纸病特征量(灰度均值、灰度标准差、熵);Sik表示所选取的第i类纸病样本中的第k个特征量的数值与当前检测到纸病的相应的特征量数值相同的样本个数;S表示该类纸病样本总数。
2.4 纸病分类模型建立
本研究选取纸病的4种特征量即灰度均值(m1)、灰度标准差(m2)、不变矩(m3)、熵(m4),根据朴素贝叶斯分类器原理,可设纸病的特征向量为x={m1,m2,m3,m4}。要判断的纸病有3种,即黑斑(C1)、光斑(C2)、边缘裂纹(C3)。对于任何一类纸病Ci(i=1,2,3),都得通过样本将条件概率P(mj|Ci)以及各类纸病出现的先验概率P(Ci)计算出来,考虑到纸病出现的随机性,给每类纸病选择300个训练样本,因此,P(Ci)=1/3,取其中240个样本用来训练P(mj|Ci),剩下的60个样本用来检验系统识别精度。对于确定好的P(mj|Ci)与P(Ci),根据式(2)有:
(20)
根据式(3)可知:
(21)
因为各类纸病的先验概率P(Ci)均相同,所以只需求maxP(x|Ci)并比较,即可判断该纸病特征向量属于哪一类纸病。
此外,在纸病的辨识过程中,依靠经验设置了拒识域,即上述后验概率中某几个概率比较接近,其差值的绝对值在拒识域内,说明此时该纸病特征属于这几类的可能性或权重比较大,因此,系统采用增加特征量的方法来进一步判断,直到其差值脱离拒识域为止。其实现流程如图6所示。

图6 纸病辨识流程图
3 应用实例
每种纸病选取300个样本进行实验,实验结果如表1和表2所示,其中,分别用240个样本来训练得到3种纸病的条件概率分布;考虑到计算的复杂程度及快速性,对不变矩只求其φ1、φ2、φ3这3个矩。最后用各类样本集剩下的60个样本去检验朴素贝叶斯分类器对纸病种类辨识的准确度。

表1 纸病特征量的提取
由表1可以发现,不同纸病的特征量是不同的,从而求得的纸病特征向量也是不同的,能够保证纸病类别与纸病特征向量的一一对应关系,同时可以看出,选择较多的纸病特征量可以避免因某些特征相同而导致错误识别的风险。
由于贝叶斯容易得到拒识条件[10],为提高辨识精度,在纸病辨识过程中,又增加了拒识域(见表2),其中,Δu=P(x|Ci)-P(x|Cj),i,j=1,2,3,且i≠j。

表2 纸病的辨识率
由表2可知,当拒识域取值范围逐渐增大时,3种纸病辨识率都相应增大,提高了辨识精度。这说明在朴素贝叶斯分类器原理的基础上设置拒识域对于提高辨识精度起到了重要作用,使辨识系统精度可调,能够满足不同的辨识精度要求。
4 结 语
本研究提出了一种利用朴素贝叶斯分类器辨识造纸工业中常见纸病的方法。该方法综合了朴素贝叶斯分类器与整个检测流程最小错误率和通用性强的特点,在测试实验中,对经过训练的纸病类型具有较高的识别精度,并且快速性好;当拒识域为0.4时,3种纸病的辨识率均已达到96.7%。如果继续增大拒识域,可以将本研究提出的方法辨识精度进一步提高,但这可能会因增大计算机的成本而影响辨识的快速性。
参 考 文 献
[1] 张学兰, 李 军, 孟范孔. 一种基于机器视觉的纸病识别方法[J]. 中国造纸学报, 2013, 28(1): 48.
[2] 张春燕, 陈 笋, 张俊峰, 等. 基于最小风险贝叶斯分类器的茶叶茶梗分类[J]. 计算机工程与应用, 2012, 48(28): 187.
[3] 董立岩, 范森淼, 刘光远, 等. 基于贝叶斯分类器的图像分类[J]. 吉林大学学报, 2007, 45(2): 250.
[4] Muralidharan V, Sugumaran V. A comparative study of Naïve Bayes classifier and Bayes net classifier for fault diagnosis of monoblock centrifugal pump using wavelet analysis[J]. Applied Soft Computing, 2012, 12(8): 2023.
[5] Liu Sanyang, Zhu Mingmin, Yang Youlong, et al. A Bayesian Classifier Learning Algorithm Based on Optimization Model[J]. Mathematical Problems in Engineering, 2013, 2013: 1.
[6] 杨 波, 周 强, 张刚强. 基于几何及灰度特征的纸病检测算法研究[J]. 中国造纸, 2011, 30(9): 50.
[7] 魏伟波, 芮筱亭. 不变矩方法研究[J]. 火力与指挥控制, 2007, 32(11): 115.
[8] 王洪涛, 丁国清. 基于不变矩图像匹配的工件种类判别应用研究[J]. 制造业自动化, 2012, 34(1): 141.
[9] 王晓文, 赵宗贵 ,汤 磊. 一种新的红外与可见光图像融合评价方法[J]. 系统工程与电子技术, 2012, 34(5): 872.
[10] 蔺志青, 郭 军. 贝叶斯分类器在手写汉字识别中的应用[J]. 电子学报, 2002, 30(12): 1805.
猜你喜欢
九江职业技术学院学报(2022年1期)2022-12-02 09:46:54
保定学院学报(2022年2期)2022-04-07 02:26:50
小资CHIC!ELEGANCE(2021年36期)2021-10-15 02:25:24
四川文学(2020年11期)2020-02-06 01:54:30
当代陕西(2019年23期)2020-01-06 12:18:04
当代陕西(2019年9期)2019-05-20 09:47:38
许昌学院学报(2018年4期)2018-05-02 12:27:37
中华建设(2017年1期)2017-06-07 02:56:14
数理化解题研究(2017年4期)2017-05-04 04:07:54
铁道通信信号(2016年6期)2016-06-01 12:10:20
