
基于服务工作流的服务动态预取模型
2014-08-10 07:33:54李海波
计算机集成制造系统 2014年3期
李海波
(华侨大学 计算机科学与技术学院,福建 厦门 361021)
0 引言
为满足企业间的频繁交互以及业务环境和需求的动态变化,企业应用软件的构造和升级也逐步开始面向服务计算技术,并经常通过Web服务组合实现更为复杂的业务逻辑。服务组合方式有很多种,其中,依据服务间内在的逻辑关系,把一系列基本服务按照一定的时序组装在一起,实现复杂的交互,即为服务工作流[1]。服务的优劣通常采用服务质量(Quality of Service,QoS)衡量,为提高服务工作流环境中服务间的时序组合效率,服务工作流选取质量“最好”的服务来组合。但当前QoS的度量指标描述的基本都是软件技术特性,在候选服务少的情况下,基于QoS的方法基本无法起到改善系统效率的作用[2],必须寻找其他度量手段。
在服务工作流环境下,当服务节点业务量大时,大量的Web服务被不断地组合在一起,装入内存、执行、销毁、再装入内存。将Web服务装入内存通常称作Web服务的实例化。提高Web服务实例化的速度可以极大地缩短服务时序组合的响应时间。目前,缩短服务响应时间的方法包括基于体系结构的方法和预取方法两大类,前者通常采用专门的中间层缓冲一些常用服务[3-4],如 FastSOA[5],在服务再次收到同样的请求时重新使用缓冲的响应,以此减少对冗余请求响应造成的服务带宽,同时降低服务请求响应时间,但随着企业Web服务的激增,缓冲带来的性能改善不再显著[6];预取是根据访问历史预测用户的未来访问请求,并把预测对象预先存放在缓冲区中,当该对象被再次请求时,直接从缓存中提取该对象给用户,以此降低用户的访问延迟[7]。如果预测的足够准确,则采用预取技术实例化Web服务可明显提高服务工作流的整体效率。在服务工作流的动态环境下,服务的执行频率随业务的发展时刻变化,这是服务预取要考虑的主要因素。
为此,本文针对服务工作流环境,基于业务因素,提出一种Web服务的动态预取模型。首先分析业务频率对Web服务预取的影响,体现在服务调用的间隔以及被反复调用的程度上,通过服务间的相对依赖强度和绝对依赖强度两个计算模型得以体现,并最终获取服务预取集合,通过实验及对比分析验证方法的有效性。
1 相关工作
广义地讲,可预取的服务包括 Web页面、位置服务中的数据、流媒体、软构件等,服务的形态不同,预取方法也不同。基于路径预测的方法通过挖掘用户访问的路径获得预取集[7-8];文献[9]提出基于场景的数据预取方法,根据用户和终端上保存的访问历史记录的关系,当用户访问某场景时,客户端可以从服务器预取下一个可能的场景;基于位置的服务系统中,受带宽和数据量的影响,通常需要预取数据资源,包括基于图的增量预取策略[10]、基于语义的预取方法[11]、用于捕捉移动的物体的局部匹配方法[12]等;流媒体的预取则根据媒体服务的特征,多采取分段缓存的策略[13-14]。上述方法基本都是根据用户的访问历史数据,针对提供服务的不同对象的特点,给出相应的预取方法。由于事先无流程引导信息,这些方法预测的准确性取决于用户的访问偏好和操作的熟练程度。
软构件作为可执行单元,通过构件库为软件系统提供执行服务,可通过挖掘业务频率获得构件的预取集[15]。鉴于应用领域的特点,该方法可提供工作流模型作为预取的引导信息,预取结果较其他方法更准确。
2 服务预取因素分析
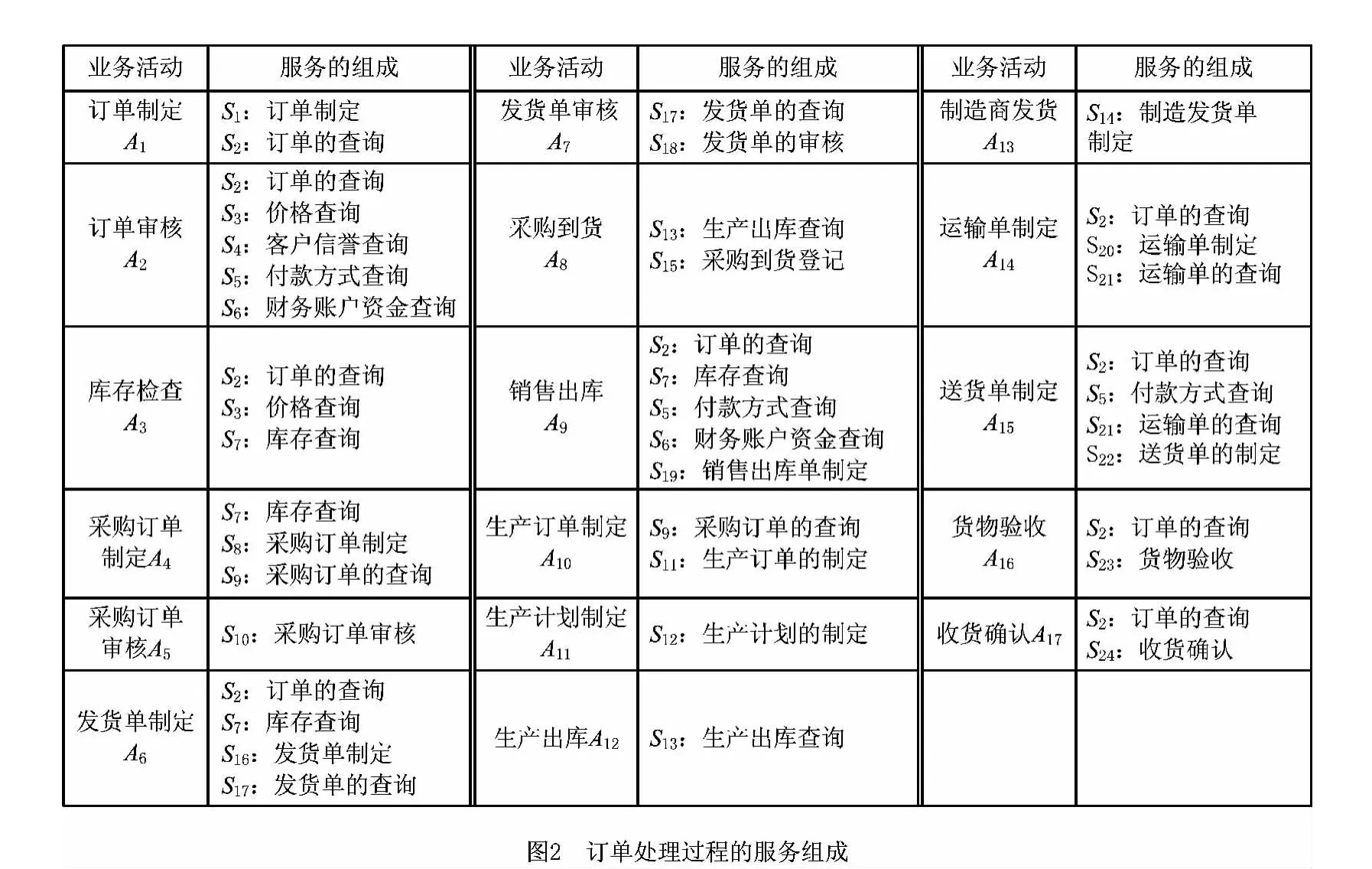
首先,从工作流模型的角度分析。服务工作流模型是对组织结构业务过程的抽象表示,是对一系列活动的逻辑顺序的规定,如图1所示为跨企业环境下的订单处理流程。由于服务工作流中的活动都是由Web服务组合而成的,活动间的时序关系也决定了所包含服务的时序关系。例如,根据图2所示的服务组合以及图3所示的一个工作流实例,A1包含组合服务{S1,S2},A2包含组合服务{S2,S3,S4,S5,S6},活动A1先于活动A2执行,则{S1,S2}就先于{S2,S3,S4,S5,S6}执行。如果两个服务直接相邻,则互为直接前驱和后继关系,如S1是S3的直接前驱,如果不直接相邻,则互为间接前驱和后继关系,如S1是活动A3中的S7的间接前驱。互为间接前驱和后继关系的服务之间的“距离”较远。此外,服务可以在不同活动中被反复调用,如S2;两个服务间的前驱和后继关系也是相对的,如S2和S7被反复执行的次数较多。
其次,从工作流运行阶段的角度,由于服务工作流模型描述的是业务发生的所有可能性,运行阶段会根据当前业务的发生情况选择执行路径,最终导致服务调用频率的不均衡,这也是由工作流模型中循环结构和选择结构的特点决定的[16]。在同一段时间内,不同活动执行的频率不同,且同一活动的执行频率在不同时期也不是固定的,业务频率的变化趋势可通过工作流日志得到如实反映。例如,当客户下订单后,若此类产品处于销售淡季,则服务工作流按图3执行,服务S11,S12,S13和S14的执行频率将会变低;若处于销售旺季,则销售商经常会库存不够,就会通过与制造商的协作采购产品,此时服务S11,S12,S13和S14的执行频率就会变高。因此,为了更准确地预取服务,服务预取模型中要体现业务频率的持续变化。
最后,虽然Web服务技术已经成熟,但其体系结构仍存在性能上的局限。作为一种分布式计算模式,基于可扩展标记语言(eXtensible Markup Language,XML)的标准协议,Web服务的调用涉及到简单对象访问协议(Simple Object Access Protocol,SOAP)报文的解析、验证、编码等步骤,再考虑服务传输,这些延迟对性能的影响也不容忽视。
综上分析,服务被反复执行的程度、服务间出现的间隔、整个业务的发生频率都是预取服务的决定因素,都可以通过挖掘工作流日志得到如实反映。

3 基于服务工作流日志的业务频率识别方法
业务频率是指一段时间内某项业务发生的频率。在服务工作流运行时,活动都是由服务组合而成,则每个活动的执行频率就是其组合服务的执行频率[16]。下面首先定义服务工作流日志。
定义1 服务工作流日志WL[16]。设A为所有工作流实例中出现的活动集合,A*是A范围内所有工作流实例的集合,则服务工作流日志WL⊆A*,是A上工作流实例的子集。
服务工作流日志的定义强调:①有效性,即使活动已定义在工作流模型中,但如果一直未执行,也不属于工作流日志的范围;②时效性,即只考虑某段时期内的工作流日志,一般根据最近的日志分析业务发展的最新情况。
工作流实例是活动的执行序列,包括工作流实例号(case_id)、活动开始时间(begin-time)和活动结束时间(end_time)等信息,如表1所示的服务工作流日志片段来自于图1所示的服务工作流。
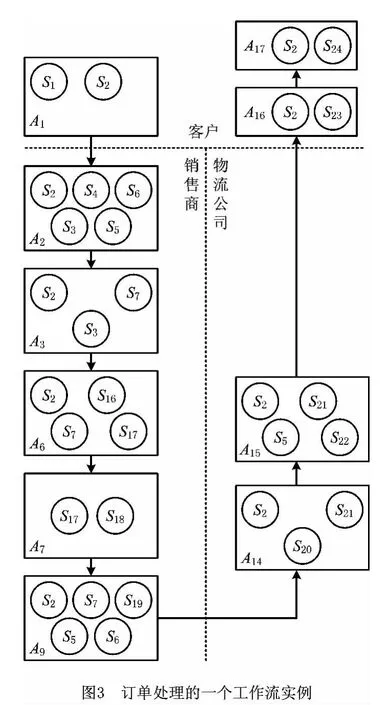
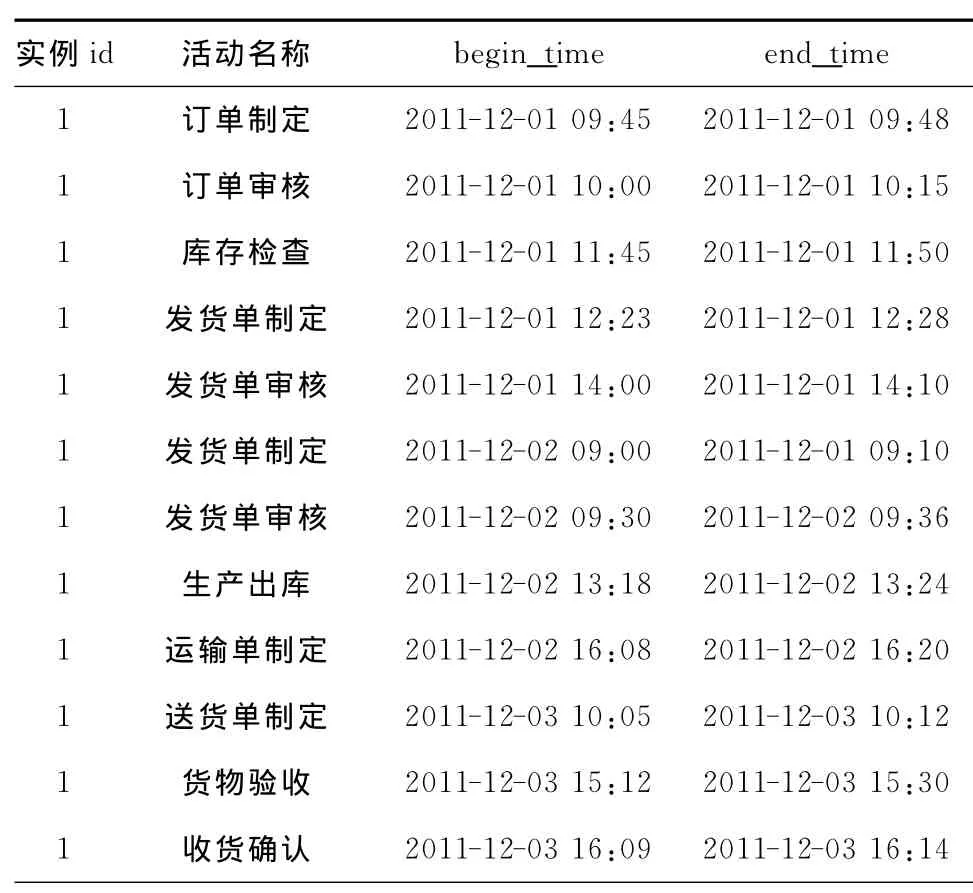
表1 服务工作流日志片段
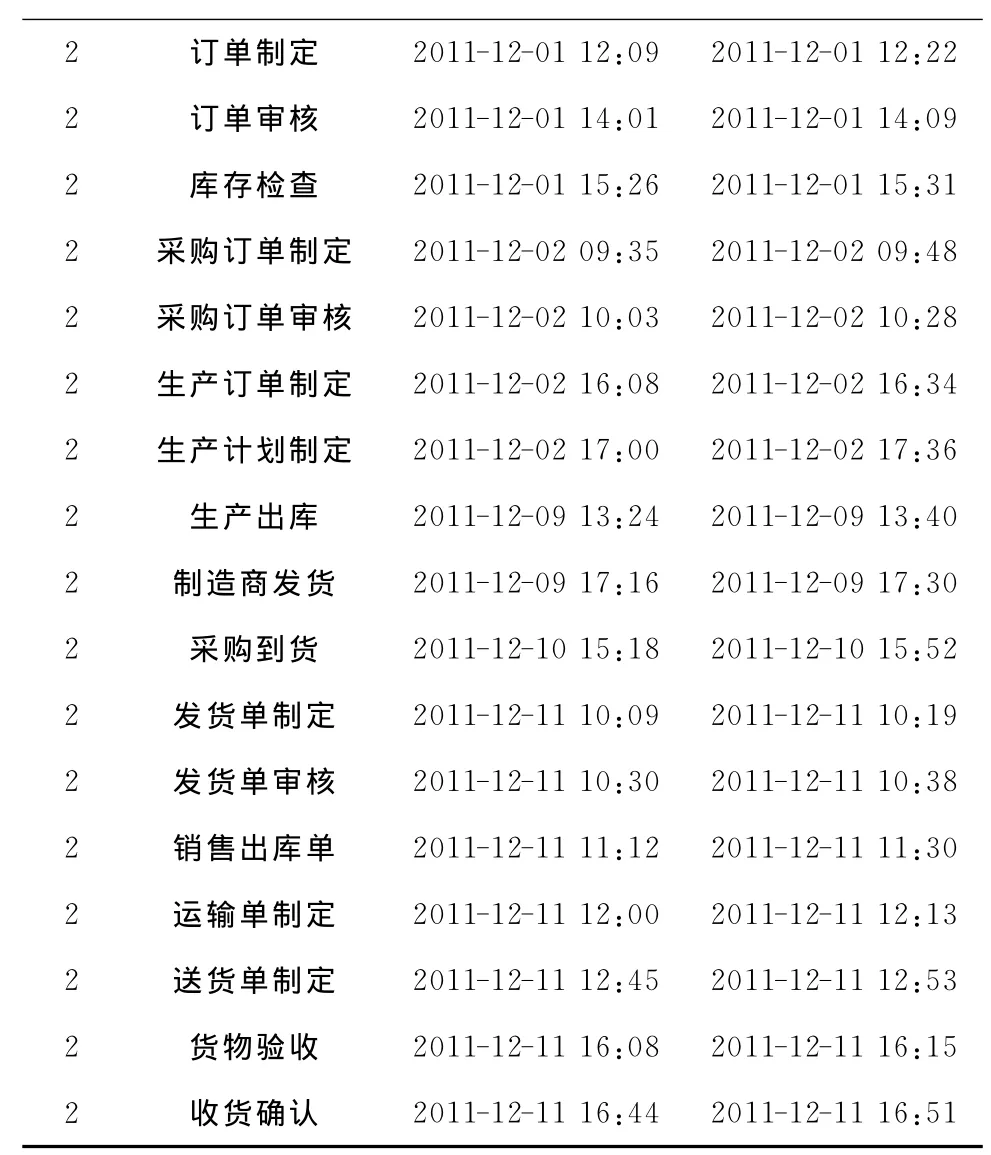
续表1
设WL 中工作流实例的集合I={I1,I2,I3,…,In},共包含m 种业务活动,表示成 A={a1,a2,a3,…,am},相应地,m 种活动的执行次数Freq={f1,f2,f3,…,fm}。设actj=Ins(ai)表示 WL 中的活动actj是工作流模型中活动ai的实例,在日志WL中共有M个活动实例。下面是Freq的求解算法。
算法1 WL_Freq——计算WL中每种业务活动被执行的次数。
输入:某段时间内工作流日志WL;
输出:每种业务活动执行次数Freq。
(1)令Freq的 m个分量均为0,即Freq=(0,0,…,0);j=0;
(2)如果A≠∅,则任取ai∈A,否则,结束算法;
(3)A=A-{ai};
(4)如果j=M,则令j=0,转步骤(2);
(5) =Ins(a), =f+1;如果actji则fii
(6)j=j+1,转步骤(4)。
以表1的工作流日志为例,应用上述算法,可以计算出发货单制定、发货单审核、采购订单制定三种业务活动出现的次数分别为3,3,1。设工作流模型中共定义了t种活动,若m<t,则说明不是所有活动都有机会执行,这是由模型中的选择控制结构决定的。因此,循环控制结构下的活动经常反复执行,执行次数多;而选择控制结构下的活动“有选择地”执行,执行次数少。
4 服务预取模型
为了使给出的服务预取模型能够反映上述几个影响因素,即服务工作流模型中定义的服务间隔、服务被执行频度、业务发生频率以及服务的执行延迟,首先量化这几个因素。
文献[15]提出过软构件的预取方法,与集中式运行环境相比,在分布环境下这些因素对服务预取的影响既相似又有差异。
若服务A是B的直接前驱或间接前驱(表示成A≺B),那么就形成了服务B对A时序上的依赖关系,表示成A→B,依赖关系的强弱需要反映出来。两个服务间的依赖关系越强,待预取的后继服务命中率越高,反之则越低。采用ADS(A→B)表示B对A的依赖程度,因为是单向的,所以称作绝对依赖强度。为反映服务A、B被反复调用的关系,需综合考虑A→B和B→A双向的依赖强度,用RDS(A→B)表示A→B的相对依赖强度,即“扣除”A对B的依赖程度后得到的B对A的依赖程度的“净值”。服务的绝对依赖强度模型和相对依赖强度模型是服务预取计算模型的关键。
根据第1章的分析,若服务A是B的前驱,则ADS(A→B)、RDS(A→B)的大小与服务A、B被调用的“间隔”和出现的次数有关,服务A、B被调用的间隔越小、次数越多,绝对依赖强度和相对依赖强度就越大。但对于RDS(A→B)来说,反方向依赖关系B→A的存在会使其强度减弱。在工作流日志中,对于任意一个工作流实例,用dis(A→B)表示A、B的间隔,即距离dis(A→B),若A是B的直接前驱,则dis(A→B)=1;若A、B被组装到同一个业务活动中,A和B之间不存在时序依赖关系,则dis(A→B)=0。
此外,Web服务调用过程包括服务传输、SOAP报文的解析、验证和编码等步骤所产生的延时,同时存在于客户端和服务端,如图4所示。本文考虑的是调用端的服务预取,对任意A≺B,要考虑以下几种情况的延迟:①调用端和服务A、B均在同一服务器上产生的延时忽略;②调用端和服务A、B不在同一服务器上产生的延时最大;③调用端和A或者B在同一服务器上,可以忽略一半的延时。
下面给出ADS(A→B)的计算模型:
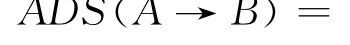
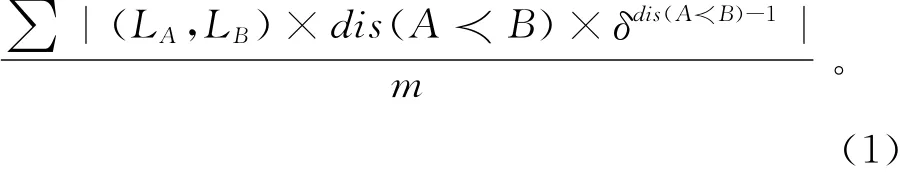
式中m为服务工作流实例的个数。服务之间时序依赖强度的总体趋势随着距离以指数关系减小[3-4],要求dis(A≺B)×δdis(A≺B)-1随dis(A≺B)的增加而减小,即单调递减,其中dis(A≺B)取自然数。通过对δ取值的测试,当0<δ<0.5时可使dis(A≺B)×δdis(A≺B)-1的结果随dis(A≺B)的增长表现出单调递减。因此,δ应该取小于0.5的最大数(δ越小,结果数据之间越难以区分),反复试验后,δ取0.4较为合适。当dis(A≺B)=1时,系数δdis(A≺B)-1=1,表示服务A 与B 直接相邻。对 m 个工作流实例取样,并依上述关系做累加体现业务频率。向量(LA,LB)表示服务调用延迟,0和1代表无延迟和有延迟,上述三种情况分别对应三种取值:(0,0),(1,1),(0,1)或(1,0),最后取向量的模,作为最终A→B的依赖强度。

相对依赖关系模型同时考虑了A→B和B→A的绝对依赖强度,对于A→B,如果m个工作流实例中不存在B→A,则ADS(B→A)=0,此时A→B的相对依赖强度等于其绝对依赖强度;如果m个工作流实例中A→B和B→A各自的绝对依赖强度相同,则RDS(A→B)=0,即服务A和B被反复调用的机会均等。
下面分析两种依赖关系模型的语义。以图4显示的1次工作流实例执行为例,假设服务S1,S2,S3,S4,S5和S6以及服务调用端均不在同一服务器上,计算绝对依赖强度和相对依赖强度。
计算结果分别如表2和表3所示。
表2 绝对依赖强度ADS(Si→Sj)计算示例

表3 相对依赖强度RDS(Si→Sj)计算示例
上述结果反映出两个服务之间绝对依赖关系和相对依赖关系的语义,如表4所示。

表4 绝对依赖强度与相对依赖强度的语义
如果考虑服务调用端以及所有被调服务所在服务器的位置,则使用向量(LA,LB)加以区分,符合向量取模的三角性质。绝对依赖强度虽能体现两个服务间的依赖程度,但还不足以体现反方向的依赖程度,要靠相对依赖强度补充。当样本数据较多时,就能充分反映某时期内业务发生情况对服务调用的影响趋势。
5 性能评价
5.1 实验验证
在制造全球化背景下,一个订单通常由多个企业协同完成,典型的制造环境包括销售商、制造商和物流公司等企业,以此为背景验证和分析服务预取模型的有效性,如图1所示的协同服务业务过程。工作流中的活动通常以服务组合的形式对外提供服务,有些服务提供给企业内部,有些服务提供给其他企业,实现互操作。提供服务的节点有销售商、制造商和物流公司3个。其中,销售商节点上运行的业务活动有A1,A2,A3,A4,A5,A6,A7,A8,A9,制造商节点上运行的业务活动有A10,A11,A12,A13,物流公司节点上运行的业务活动有A14,A15,A16,A17。由于业务活动是由服务组合而成的,有的业务活动也会调用其他服务节点的服务。考虑最一般的情形:服务工作流的调度和执行独立于这三个服务节点,以平台的方式对外提供集成服务。
实验包括两个步骤:①产生工作流日志;②计算服务工作流中服务的依赖强度。
(1)生成模拟服务工作流日志 按图1所示的服务工作流模型产生日志,每条工作流路径按相同次数出现,分别运行1 000次、2 000次和3 000次(和软件运行环境无关),活动A1,A2,…,A17执行的次数如图5所示。
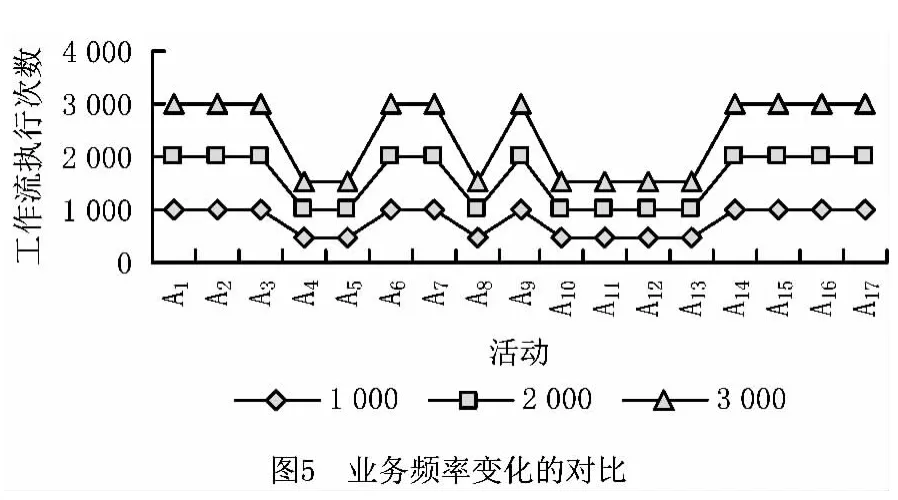
从运行结果看,不同运行次数下的总体趋势是相同的。
(2)计算服务工作流中服务间的依赖强度 选取运行1 000次的服务工作流日志,如图5所示,活动 A1,A2,A3,A6,A7,A9,A14,A15,A16,A17执 行1 000次,A4,A5,A8,A10,A11,A12,A13执行500次,以此执行频率计算服务依赖强度。
首先,依据式(1)计算24个服务间的绝对依赖强度,限于篇幅,只列出12个服务(S1~S12)之间的绝对依赖强度,如表5所示。
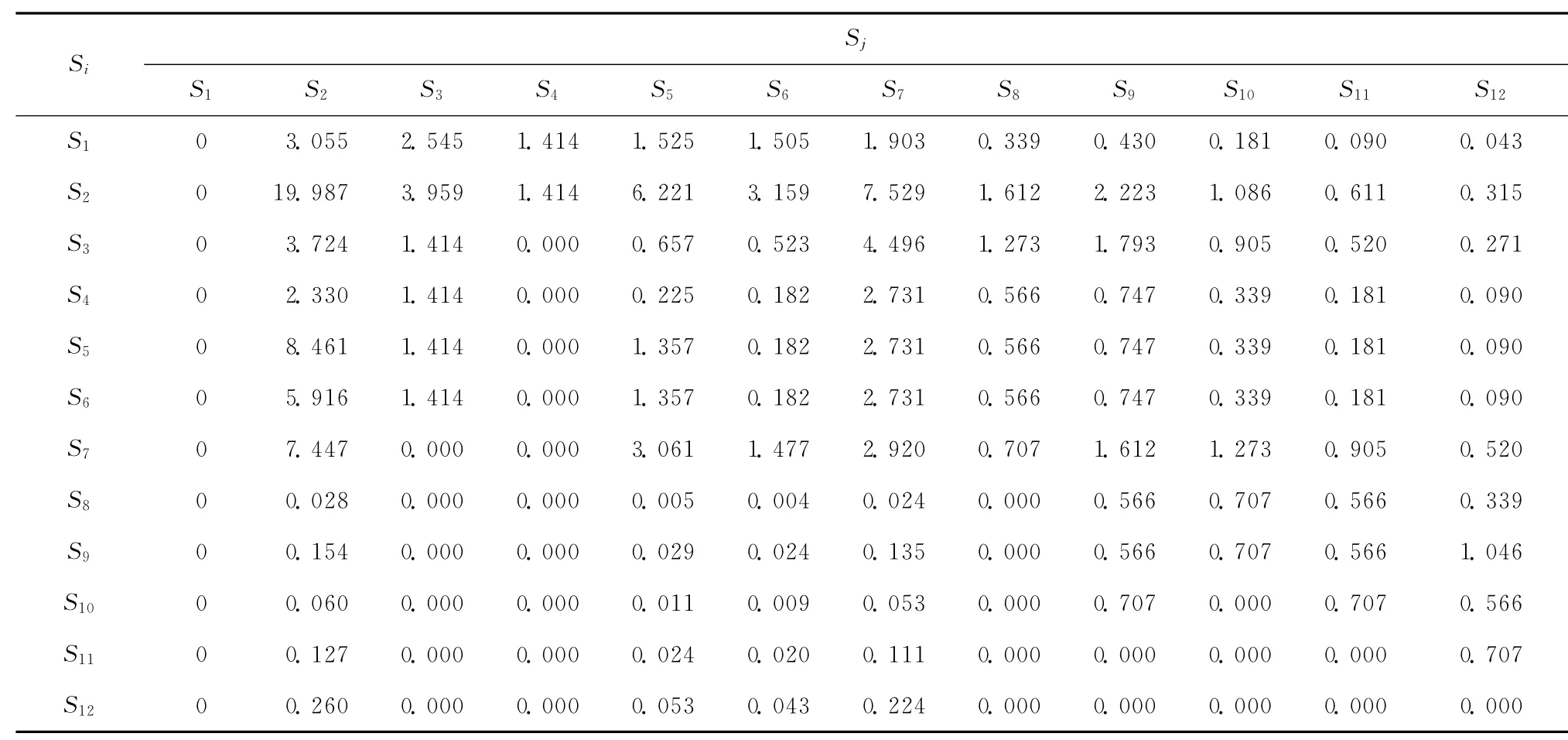
表5 部分服务间的绝对依赖强度ADS(Si→Sj_)
其次,依据式(2)计算24个服务之间的相对依赖强度,限于篇幅,只列出12个服务(S1~S12)之间的相对依赖强度,如表6所示。
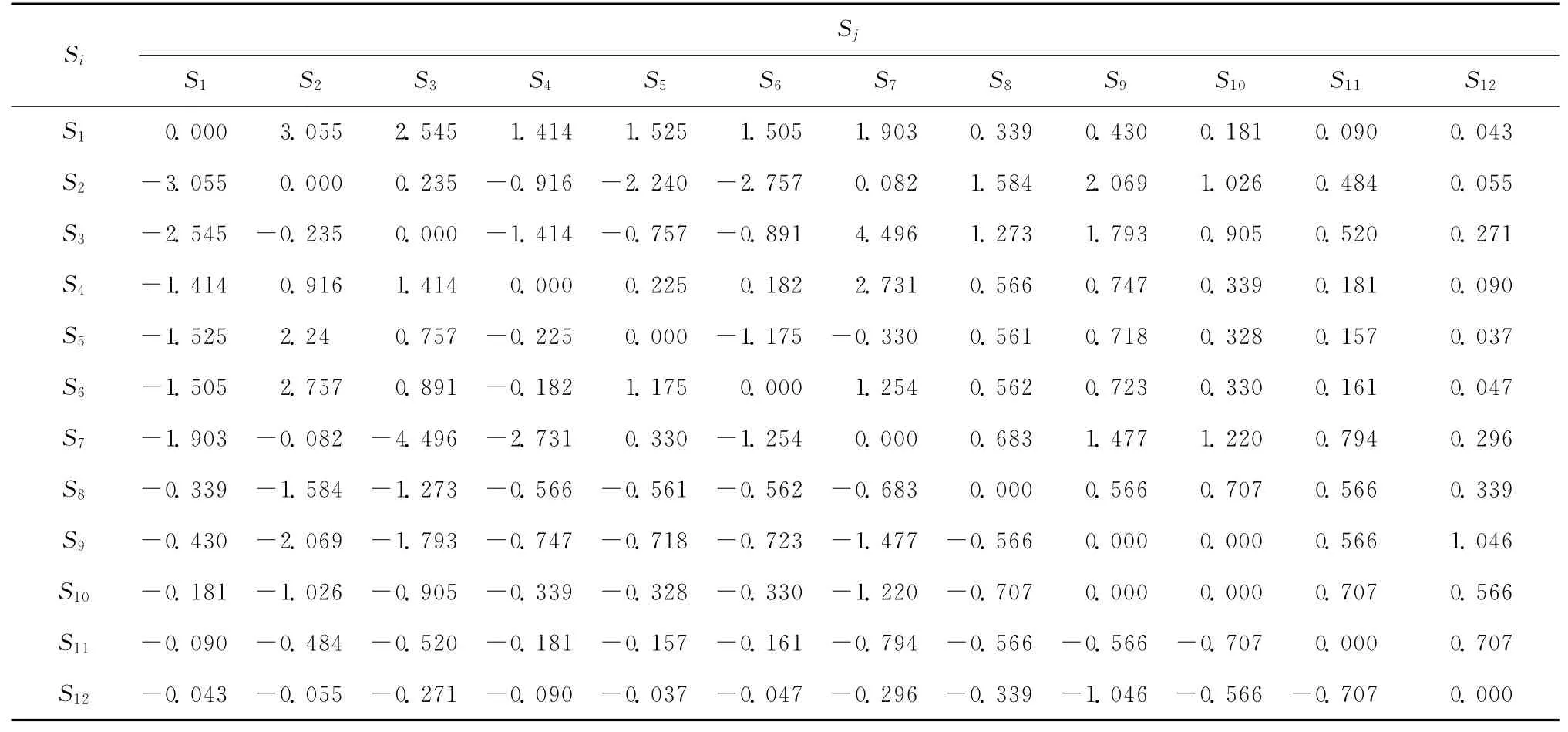
表6 部分服务之间的相对依赖强
从表4给出的定性分析结果来看,预取服务最好选取绝对依赖强度大、同时相对依赖强度小的服务,但这个阈值也可根据实际需要进行调整,如希望预取更多的服务。本例中,若选取绝对依赖强度(绝对值)最大值的1/3作为其阈值,选取相对依赖强度(绝对值)最大值的1/2作为其阈值,即需同时满足:①0≤相对依赖强度的绝对值≤1.931;②绝对依赖强度≥6.662,最终得到服务预取集合:{S2→S2,S2→S7,S7→S2}。若希望预取更多服务,则可降低绝对依赖强度阈值,不妨设为最大值的1/4,若相对依赖强度阈值不变,则最终得到服务预取集合为:{S2→S2,S2→S7,S2→S21,S7→S2,S21→S2}。
从表4给出的定性分析结果来看,预取服务最好选取绝对依赖强度大、同时相对依赖强度小的服务,但这个阈值也可根据实际需要进行调整,如希望预取更多的服务。本例中,若选取绝对依赖强度(绝对值)最大值的1/3作为其阈值,选取相对依赖强度(绝对值)最大值的1/2作为其阈值,即需同时满足:①0≤相对依赖强度的绝对值≤1.931;②绝对依赖强度≥6.662,最终得到服务预取集合:{S2→S2,S2→S7,S7→S2}。若希望预取更多服务,则可降低绝对依赖强度阈值,不妨设为最大值的1/4,若相对依赖强度阈值不变,则最终得到服务预取集合为:{S2→S2,S2→S7,S2→S21,S7→S2,S21→S2}。
从表4给出的定性分析结果来看,预取服务最好选取绝对依赖强度大、同时相对依赖强度小的服务,但这个阈值也可根据实际需要进行调整,如希望预取更多的服务。本例中,若选取绝对依赖强度(绝对值)最大值的1/3作为其阈值,选取相对依赖强度(绝对值)最大值的1/2作为其阈值,即需同时满足:①0≤相对依赖强度的绝对值≤1.931;②绝对依赖强度≥6.662,最终得到服务预取集合:{S2→S2,S2→S7,S7→S2}。若希望预取更多服务,则可降低绝对依赖强度阈值,不妨设为最大值的1/4,若相对依赖强度阈值不变,则最终得到服务预取集合为:{S2→S2,S2→S7,S2→S21,S7→S2,S21→S2}。
从表4给出的定性分析结果来看,预取服务最好选取绝对依赖强度大、同时相对依赖强度小的服务,但这个阈值也可根据实际需要进行调整,如希望预取更多的服务。本例中,若选取绝对依赖强度(绝对值)最大值的1/3作为其阈值,选取相对依赖强度(绝对值)最大值的1/2作为其阈值,即需同时满足:①0≤相对依赖强度的绝对值≤1.931;②绝对依赖强度≥6.662,最终得到服务预取集合:{S2→S2,S2→S7,S7→S2}。若希望预取更多服务,则可降低绝对依赖强度阈值,不妨设为最大值的1/4,若相对依赖强度阈值不变,则最终得到服务预取集合为:{S2→S2,S2→S7,S2→S21,S7→S2,S21→S2}。
从表4给出的定性分析结果来看,预取服务最好选取绝对依赖强度大、同时相对依赖强度小的服务,但这个阈值也可根据实际需要进行调整,如希望预取更多的服务。本例中,若选取绝对依赖强度(绝对值)最大值的1/3作为其阈值,选取相对依赖强度(绝对值)最大值的1/2作为其阈值,即需同时满足:①0≤相对依赖强度的绝对值≤1.931;②绝对依赖强度≥6.662,最终得到服务预取集合:{S2→S2,S2→S7,S7→S2}。若希望预取更多服务,则可降低绝对依赖强度阈值,不妨设为最大值的1/4,若相对依赖强度阈值不变,则最终得到服务预取集合为:{S2→S2,S2→S7,S2→S21,S7→S2,S21→S2}。
从表4给出的定性分析结果来看,预取服务最好选取绝对依赖强度大、同时相对依赖强度小的服务,但这个阈值也可根据实际需要进行调整,如希望预取更多的服务。本例中,若选取绝对依赖强度(绝对值)最大值的1/3作为其阈值,选取相对依赖强度(绝对值)最大值的1/2作为其阈值,即需同时满足:①0≤相对依赖强度的绝对值≤1.931;②绝对依赖强度≥6.662,最终得到服务预取集合:{S2→S2,S2→S7,S7→S2}。若希望预取更多服务,则可降低绝对依赖强度阈值,不妨设为最大值的1/4,若相对依赖强度阈值不变,则最终得到服务预取集合为:{S2→S2,S2→S7,S2→S21,S7→S2,S21→S2}。
从表4给出的定性分析结果来看,预取服务最好选取绝对依赖强度大、同时相对依赖强度小的服务,但这个阈值也可根据实际需要进行调整,如希望预取更多的服务。本例中,若选取绝对依赖强度(绝对值)最大值的1/3作为其阈值,选取相对依赖强度(绝对值)最大值的1/2作为其阈值,即需同时满足:①0≤相对依赖强度的绝对值≤1.931;②绝对依赖强度≥6.662,最终得到服务预取集合:{S2→S2,S2→S7,S7→S2}。若希望预取更多服务,则可降低绝对依赖强度阈值,不妨设为最大值的1/4,若相对依赖强度阈值不变,则最终得到服务预取集合为:{S2→S2,S2→S7,S2→S21,S7→S2,S21→S2}。
5.2 与相关方法比较
首先,与之前的研究成果[15]相比较。文献[15]考虑的是软构件的动态预取模型,在集中式的运行环境下,构件间调用的延迟可以忽略。而本文的预取对象是Web服务,其分布运行的特点决定了服务调用产生的延迟不能忽略,在本文的模型中采用向量(LA,LB)以及最后取模运算来体现更加准确。
其次,与较典型的预取方法比较。为了对比测试模型的预取性能,本文选用与文中方法相似的两个预取方法——基于条件概率的预测[8]和基于访问路径的预取方法[7]做比较,并采用预测精确度P和适用度T作为评价指标,具体定义如下:
定义2 预测精确度[17]。预测精确度P表示正确预测的Web服务对象数Np与预测总的Web服务对象数N的比率,即P=Np/N。
如果在接下来的一个预测窗口内用户对预测Web服务对象进行了请求,则称该预测是正确的,否则不正确。
定义3 适用度。适用度T表示模型预测的请求数Qp与总的请求数Q的比率,即T=Qp/Q。
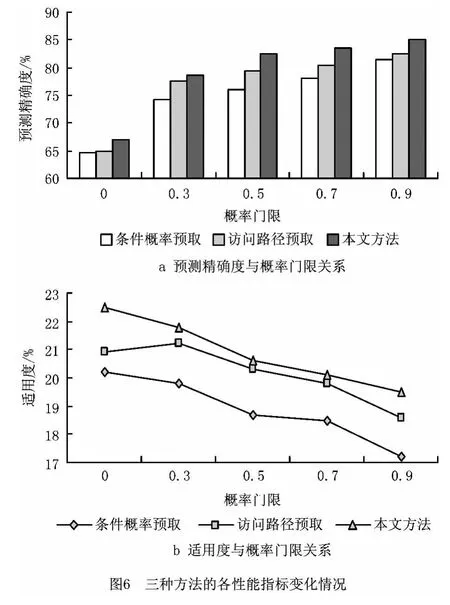
以图1所示的服务工作流模型为例,分别用不同的方法进行模拟实验,比较在相同的硬件条件下,选取不同的概率门限,按照三种不同方法计算出预取服务的精确度及适用度。实验结果表明,考虑了服务间的依赖强度与业务频率的影响,模型的预测精确度和适用度都有明显改善。图6a显示了三种模型的预测精确度随概率门限的增加而增加,本文所提方法优于其他两种方法。这是因为该方法充分考虑了业务频率,缩小了模型预测的 Web服务范围。图6b说明三种方法的适用度随概率门限的增加而减少,本方法所提模型保持了较高的适用度。
实验结果表明,本文提出的方法具有明显的优势。这是因为该方法建立在服务工作流模型之上,不但自身可确定被预取对象的顺序,而且能挖掘业务频率,从而缩小预测的范围。而基于访问路径的预取方法,需要大量的训练数据。基于条件概率的预取方法是根据用户访问记录中Web服务之间的转移概率P,再根据P的大小预测下一个Web服务。该方法取决于用户的访问偏好和操作的熟练程度。
5.3 性能讨论
由于Web服务技术采用了SOAP,服务调用时延迟较大。动态网页静态化是较典型的解决办法,对经常被调用的Web服务可做类似处理。具体地,以协同制造环境下的某企业服务器为例,采用本文所提的预取方法预测下一个可能被调用的服务,并使用出现频率高的参数对网页作静态化处理。这些服务可以属于该服务器,也可以是其他企业的,可有效提高企业间的互操作效率。
企业的业务数据时刻在变化,对预取的服务集可并行地做静态化处理,代价可忽略。动态网页静态化后的方法,但是静态化处理时存在参数命中率的问题,即用户调用服务时使用某些参数的可能性,因此预取的代价主要取决于参数的命中率,若静态化处理所采用的参数在执行时未被命中,则效率就没有改善。但如果参数的使用频率很高,则可大大提高预测的命中率,进而提高服务的响应速度,这也是所有预取、缓存技术应用的最佳环境。
6 结束语
本文方法建立在服务工作流之上,有工作流模型指导流程的推进,因此性能上占有绝对优势,提出的服务预取模型包括绝对依赖强度和相对依赖强度,全方位地体现出影响服务预取的业务因素,为服务缓冲提供了更加精确的预测,在多企业协同制造的环境下可提供更好的服务预取策略,以减轻应用服务器的运行负载,缩短用户访问的响应时间。近年来,云制造作为协同制造的一种新模式得到了广泛的关注和研究,其系统平台具有“集中资源分散服务”的特点,云制造环境下的服务预取更加重要,相应的预取模型是未来的研究方向。
[1] DENG Shuiguang,HUANG Longtao,YIN Jianwei,et al.Technical framework form Web service composition and its progress[J].Computer Integrated Manufacturing Systems,2011,17(2):404-412(in Chinese).[邓水光,黄龙涛,尹建伟,等.Web服务组合技术框架及其研究进展[J].计算机集成制造系统,2011,17(2):404-412.]
[2] GUO Chunli,LI Haibo.Controllability of quality of service in Web service workflow system based on variable granularity[J].China Mechanical Engineering,2011,22(21):2613-2618(in Chinese).[郭春丽,李海波.基于可变粒度的服务工作流系统服务质量可控性研究[J].中国机械工程,2011,22(21):2613-2618.]
[3] CHEN Weiling,YIN Shiqun,QIU Yuhui.Schema reasoning and semantic representation for citation semantic link network[C]//Proceedings of the 3rd International Conference on Intelligent Information Technology Application.Washington,D.C.,USA:IEEE,2009:366-369.
[4] DRAKATOSA S,PISSINOUA N,MAKKIA K et al.A context-aware cache structure for mobile computing environments[J].Journal of System and Software,2007,80(7):1102-1119.
[5] COHEN F.FastSOA:accelerate SOA using XML,XQuery and native XML database technology[EB/OL].(2006-03-06)[2012-05-06].http://www.ibm.com/developerworks/cn/xml/x-accsoa/index.html.
[6] BENEVENUTO F,DUARTE F,ALMEIDA V,et al.Web cache replacement policies:Properties,limitations and implications[C]//Proceedings of the 3rd Latin American Web Congress. Washington, D. C., USA:IEEE Computer Society,2005.
[7] XU Huanqing,WANG Yongcheng.A Web pre-fetching model based on analyzing user access pattern[J].Journal of Software,2003,14(6):1142-1147(in Chinese).[许欢庆,王永成.基于用户访问路径分析的网页预取模型[J].软件学报,2003,14(6):1142-1147.]
[8] ZHANG Boping,SHI Lei.Study on the Web pre-fetching based on the relationship of the Web structure[D].Zhengzhou:University of Zhengzhou,2006(in Chinese).[张泊平,石磊.基于网页结构相关性预取技术研究[D].郑州大学,2006.]
[9] LI Song,WANG Wendong,CUI Yidong,et al.A novel pre
fetching method for scene-based mobile social network service[C]//Proceedings of the 3rd IEEE International Conference on Broadband Network and Multimedia Technology.Washington,D.C.,USA:IEEE Computer Society,2010:144-148.
[10] YU Fang,JIANG Changjun,FU Ying.Incremental data prefetching for map service in mobile navigation application[C]//Proceedings of International Conference on Wireless Communications,Networking and Mobile Computing,Washington,D.C.,USA:IEEE Computer Society,2008.
[11] KANG Sang-Won,GIL Joon-Min,KIM Jongwan,et al.Description-based semantic prefetching scheme for data management in location-based services[J].Journal of Information Science and Engineering,2008,24(6):1788-1820.
[12] LIEN C C,WANG C C.An effective prefetching technique for location-based services with PPM [C]//Proceedings of the 9th Joint Conference on Information Sciences.DOI:10.2991/jcis.2006.221.
[13] XUE Jiansheng,CHENG Zi'ao,SUN Xin.A distribution technology based on segmentation prefetching and pipelining in classified streaming media service[C]//Proceedings of International Conference on Multimedia Technology.Washington,D.C.,USA:IEEE Computer Society,2010.
[14] KRISHNAPPA D K M,KHEMMARAT S,GAO Lixin,et al.On the feasibility of prefetching and caching for online TV services:a measurement study on hulu[C]//Proceedings of the 12th International Conference on Passive and Active Measurement. Berlin,Germany:Springer-Verlag,2011:72-80.
[15] LI Haibo,ZHAN Dechen,XU Xiaofei.Dynamic component prefetching method for workflow management system[J].Chinese Journal of Computers,2012,35(5):1038-1045(in Chinese).[李海波,战德臣,徐晓飞.面向工作流管理系统的动态构件预取方法[J].计算机学报,2012,35(5):1038-1045.]
[16] LI Haibo.Workflow management system oriented multigranularity component organization[J].China Mechanical Engineering,2011,22(16):1942-1948(in Chinese).[李海波.面向工作流管理系统的多粒度构件组织技术[J].中国机械工程,2011,22(16):1942-1948.]
[17] ZHANG Zhili,QI Deyu.Study on the key techinques of Web accelerating[D].Guangzhou:South China University of Technology,2006(in Chinese).[张志立,齐德显.Web加速关键技术研究[D].华南理工大学,2006.]
猜你喜欢
华人时刊(2021年13期)2021-11-27 09:19:02
心声歌刊(2020年4期)2020-09-07 06:37:14
商品与质量(2019年34期)2019-11-29 03:25:51
制造技术与机床(2019年9期)2019-09-10 07:36:54
西南交通大学学报(2018年6期)2018-12-18 02:22:28
测控技术(2018年5期)2018-12-09 09:04:46
小学生(看图说画)(2017年6期)2017-11-06 06:48:08
河北遥感(2017年2期)2017-08-07 14:49:00
信息安全研究(2016年4期)2016-12-01 06:07:05
衡阳师范学院学报(2016年3期)2016-07-10 07:16:27
