
基于字符笔画斜率特征的车牌识别算法研究*
2014-08-08 06:33方兴林
重庆工商大学学报(自然科学版) 2014年9期
方 兴 林
(黄山学院 经济管理学院,安徽 黄山 245041)
经济快速发展,家庭车辆拥有量日益增多,给人民带来极大方便的同时,也给交通管理部门带来巨大的管理压力,基于此,智能交通系统(Intelligent Transportation System,简称ITS)是未来社会发展过程中的必然选择.ITS是将先进的信息技术、通讯技术、传感技术、控制技术以及计算机技术等有效地集成运用于整个交通运输管理体系而建立起的一种在大范围内,全方位发挥作用的,实时、准确、高效的综合运输和管理系统,其中车牌自动识别技术是该系统的核心.一个完整的车牌识别流程包括4个步骤,即图像采集、车牌定位、字符分割、字符识别.字符识别是车牌自动识别技术的最后一步,也是关键一步,主要任务是对字符分割步骤的结果,即单个字符进行自动识别,以达到车辆智能管理的目的.
车牌字符识别属于模式识别的范畴,一般来说,模式识别方法主要包括统计方法和结构方法.依据车牌字符的结构和特点,对传统模式识别方法进行了适应性地改进,目前常见的车牌字符识别方法主要有模板匹配法[1,2]、神经网络法[3-5]和支持向量机法[6-8].模板匹配法是通过判定待识别字符与标准字符间的相似度达到识别目的,设置相似度阈值,当相似度超过阈值,则认为两字符为同一字符.模板匹配法原理简单,计算方便,且具有较高的识别率,因此得到了普遍的应用,但是其缺点也很明显,由于忽略了大量的字符细节信息,使得模板匹配法在识别相似字符时易出现误识别.神经网络法具有较强的容错能力,识别效率较高,然而其收敛速度较慢,难以保证全局最优,并且该方法需要大量的试验样本.支持向量机(Support Vector Machine)通过对大量识别样本集进行训练,进而得到一个最佳识别函数,从而实现识别的目的,具有较高的识别精度,但是训练样本运算复杂度高,耗时长,难以满足实时性要求.
特征匹配是一种特殊化的模板匹配,因为模板匹配是将字符本身作为一个整体特征进行匹配,而特征匹配是从字符中抽取少量的字符结构分类特征,以特征相似度匹配替代模板相似度匹配,可以很大程度降低算法复杂度,满足实时性的要求.基于此,特征匹配作为对传统模板匹配的一种改进,得到了广泛的应用.然而目前还没有提出一种普适性的特征提取算法,只是根据不同的应用领域,产生不同的特征提取方法,如正交投影法、基于小波变换的特征提取法[9,10]、网格像素统计法等[11].现有的算法均很难提高相似字符的识别能力,此外部分特征的提取方法如网格法所提取的特征维数过大,计算复杂度增加.针对现有算法的不足,此处试图提出一种新的字符特征提取方法,新的算法首先对成功分割后的单个车牌字符进行细化处理,在此基础上提取出字符像素的斜率特征信息,并将斜率值按特定算法构造成特征向量,通过对向量的数学运算来达到字符识别的目的.
1 字符特征提取
1.1 预处理
在经过车牌定位和字符分割步骤后,车牌图像已经变成了7个单个字符图像.由于车牌图像均是采集于自然环境中,车牌在不同品牌汽车的车身悬挂位置不尽相同,再加上拍摄角度等因素的影响,使得最终分割出的单个车牌字符大小尺寸不一样.为了方便后续处理,有必要对单个字符车牌进行归一化处理.在进行归一化处理后,单个车牌字符图像的尺寸均为16×32像素.
经过归一化处理后的单个车牌字符图像是彩色图像,虽然彩色图像包含了更多的字符信息,但是也提升了计算量和计算复杂度.其实经过车牌定位和字符分割后的图像,单个字符图像只包含字符和背景颜色信息,此时颜色信息已显得无关紧要.基于此,为了降低计算量,此处对单个车牌图像进行二值化处理.考虑车牌字符的特点,单一固定的阈值难以满足车牌字符普适性的需求,因此选择迭代法求取二值化的阈值,并对单个车牌图像进行二值化处理.
由于此处是将车牌字符的像素斜率信息作为识别特征,进行车牌字符识别,因此字符细化处理的效果直接决定着最终字符识别的效率.通过实验结果,对比了目前几种常见的成熟字符细化算法,最终选择基于数学形态学的方法来提取车牌字符图像的骨架,从而达到细化的效果.字符细化效果如图1所示.
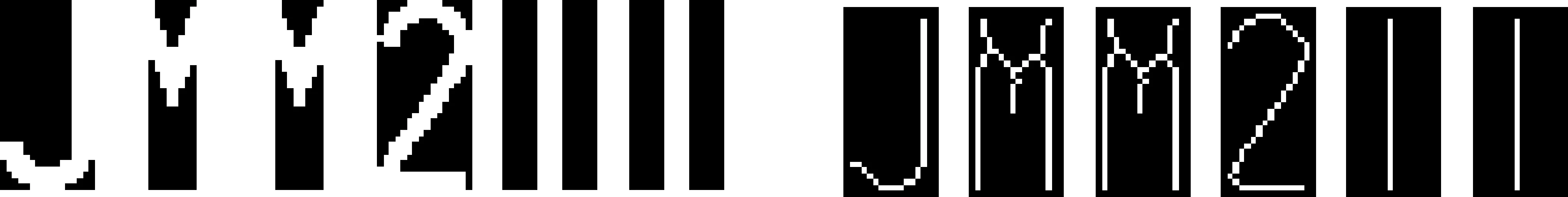
图1 字符细化效果图
1.2 斜率特征提取
字符结构特征是字符与生俱来的、特有的信息,因其所包含的信息量唯一,分类效果显著.此外,计算量小也是其优点之一.上述诸多特点使得基于字符结构特征的识别算法成为车牌字符识别研究领域中一类不可或缺的常用算法.字符结构特征包括字符笔画特征、字符轮廓特征、字符内部像素特征、点特征(拐点、角点等)、线特征(横线、竖线)等.其中笔画特征是字符最具代表性的特征之一,每一个字符均可拆解成若干个笔画,不同车牌字符的笔画在数量、长短以及形态等方面均是不同的,基于此,选择字符笔画特征作为字符识别特征.
如何表述字符不同的笔画特征,学者们开展了大量且富有成效的研究,常见的有笔画方向、笔画密度等[12].然而现有的基于笔画特征的字符识别大多适用于手写字符识别,手写字符与车牌字符之间最大的不同在于手写字符笔画不规则且随意性较强,而车牌字符的笔画非常工整,因此,现有的基于笔画特征的字符识别算法不适用于车牌字符识别.在现有的基于笔画特征的字符识别算法的基础上,尝试提取车牌字符笔画斜率信息作为识别特征.
如前文所述,经过分割后的车牌字符已经经过了归一化和细化处理,此时的车牌字符图像尺寸大小相等,且字符的笔画均是由一个像素构成,提取车牌字符笔画斜率特征的算法如下.
步骤1 在细化后的车牌图像上建立直角坐标系,坐标系的原点设在车牌图像的第1行、第1列,即车牌图像左上角点上,如图2所示.
步骤2 对车牌细化图像自上而下、自左而右逐行进行遍历,对遍历到的每一个白色像素点(车牌字符构成点)Pij(i为车牌细化图像的第i行,j为车牌细化图像的第j列),均计算该白色像素点的斜率Kij,Kij的计算由公式(1)得到.
(1)
步骤3 对车牌字符每个像素点的斜率值Kij(i=0,1,2,…,31,j=0,1,2,…,15),构造字符斜率识别特征向量V(Kij).
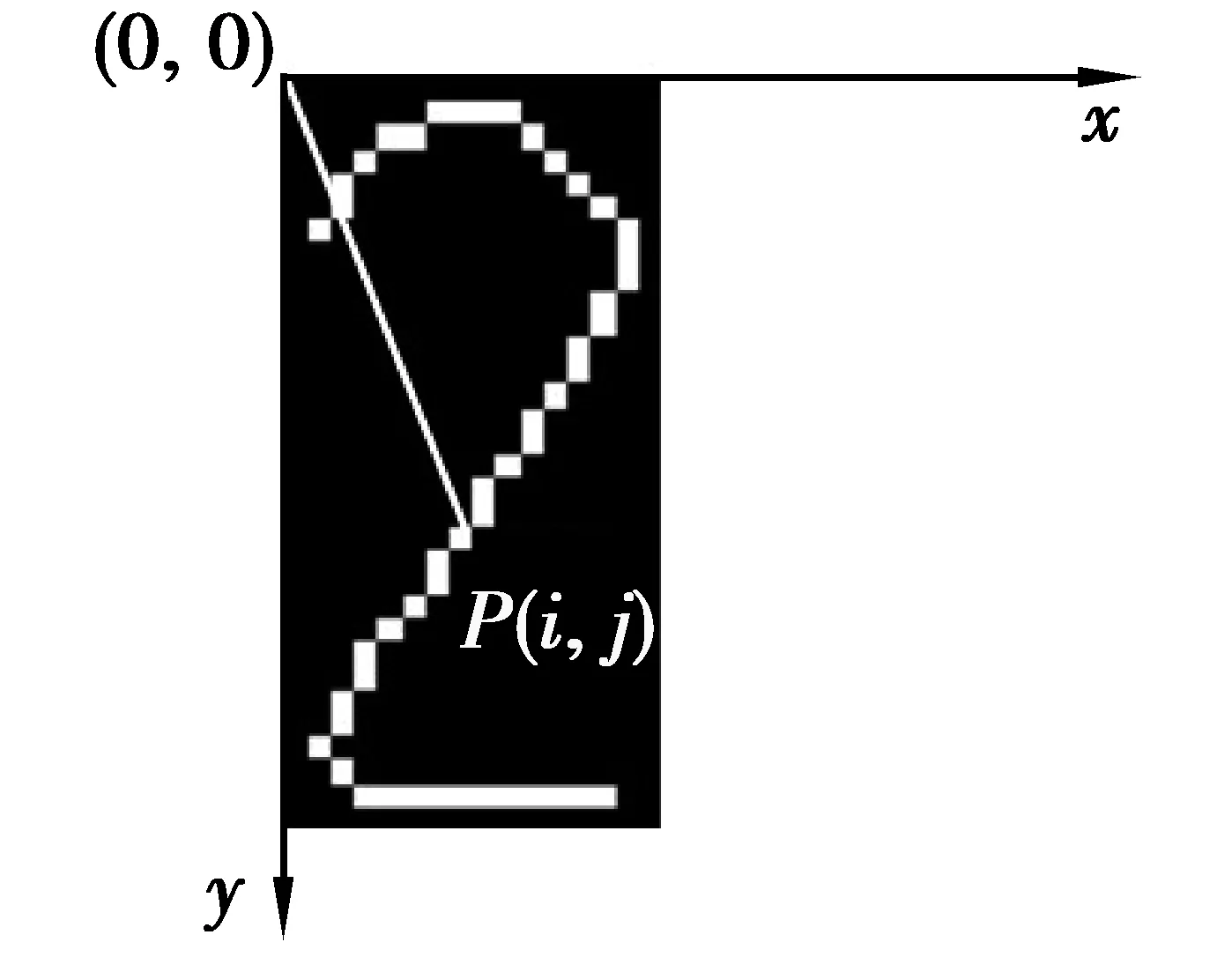
图2 字符笔画斜率示意图

图3 链码向量匹配
2 基于字符斜率向量的分类识别
在车牌字符细化和像素点斜率提取的基础上,依据几何向量的数学特性,新设计了一种基于车牌字符像素点斜率值特征向量的车牌字符分类器.新的分类器通过计算待识别车牌字符像素斜率值的向量与车牌标准模板字符像素点斜率值的向量之间的夹角,来确定这两个向量的匹配度[13].两向量之间的夹角可由公式(2)计算所得.
(2)
依据公式(2),当cosθ=1时,两向量完全匹配,即待识别车牌字符与模板字符完全一致;当cosθ=0时,两向量完全无关,即待识别车牌字符与模板字符完全不一致,如图3所示.
综上,新的分类器识别车牌字符步骤如下:
步骤1 提取车牌标准模板字符像素的斜率值,并构建特征向量V(Kij);
步骤2 提取待识别车牌字符像素的斜率值,并构造特征向量V′(Kij);
步骤3 计算向量V(Kij)与V′(Kij)的夹角,依据夹角值完成字符识别.由数学知识可知,两个向量须具有相同的维数,才可求得夹角,基于此,为了保证能够计算V(Kij)与V′(Kij)之间的夹角,实现字符匹配与识别,对V(Kij)与V′(Kij)进行离散化处理,即在图2的直角坐标系中,在270°~360°范围内,以原点为起始点,发出一条射线,该射线从270°开始向360°旋转移动,其移动的角度增幅依据实际需要而设置,此处选择0.5°.如果射线在移动的过程中遇到白色像素点,则计算该白色像素点的斜率值,如果射线移动到某一角度上遇到多个像素点,则选取横坐标最大的白色像素点作为计算点.经过离散化处理后,能保证V(Kij)与V′(Kij)两个向量的维数相同.
此外,在实际工程应用中,考虑到车牌图像捕获角度、摄像机成像畸变以及光照和灰尘污染、车牌破损等随机因素的影响,可能会导致相同字符在待识别状态与标准状态时的像素斜率值特征向量存在些许差异,这个差异如果不加以控制和解决,会导致新的分类器误识别率的增加,降低新分类器的鲁棒性.基于此,设定一个匹配相似度阈值δ(0<δ<1),规定如果两向量夹角的cosθ小于δ,则匹配不成功,即不是同一字符.δ的具体取值依识别环境的不同而设置.
3 仿真实验与分析
为了验证新提出的车牌字符识别算法的有效性,在安徽省黄山市高速公路2号口采集了1 000张小型车辆车牌图像进行了实验,车牌图像中涵盖了10个阿拉伯数字字符(0,1,2,…,9)和24个英文字符(除去O和I),样本集涵盖所有构成中国车牌的字符,因此符合测试需要.实验在Pentium(R)Dual-Core(2.30GHz),2G内存的计算机环境中,利用VC++ 6.0平台进行仿真实验,实验结果如表1所示.
同时为了对比所提出的算法与已有车牌识别算法的识别效果,选择了经典的模板匹配法和BP网络法作为参照.对比实验结果如表2所示.
表1中的测试数据显示,所提出的基于车牌字符像素斜率值的特征向量识别算法具有较高的识别率.但是,数据同时也显示,该方法对少数字符的识别率相对较低,如阿拉伯数字2,5,0和英文字符Q,S,Z等,这些字符的识别率只有95%左右.对识别率较低的字符笔画结构进一步细致分析,不难发现,这些字符的识别率低不是因为新算法拒绝识别,而是新算法对这些字符出现误识别,从而导致识别正确率较低.字符的笔画结构决定了英文字符Q,S,Z分别与阿拉比数字0,5,2在字符像素斜率值上有较高的重合度,因此导致识别率较低.
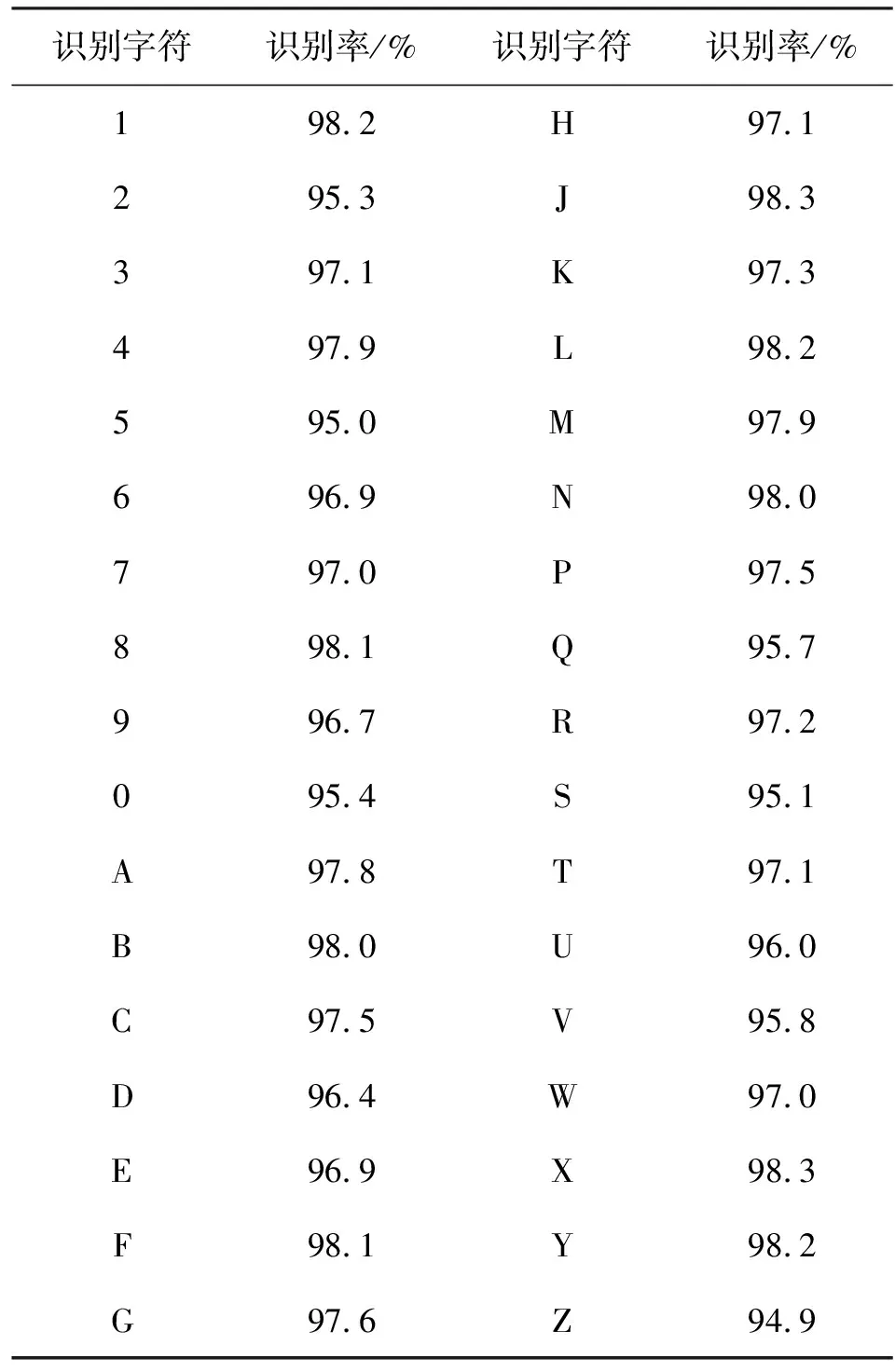
表1 字符识别结果
表2数据显示,所提出的新的车牌字符识别算法在整体识别准确率上明显优于传统的基于模板的车牌字符识别方法和基于BP网络的车牌字符识别方法,此外,单个字符的识别耗时也少于传统算法.综上,所提出的识别方法无论在识别正确率上,还是在实时性上,均优于传统识别方法,满足实际工程需要.
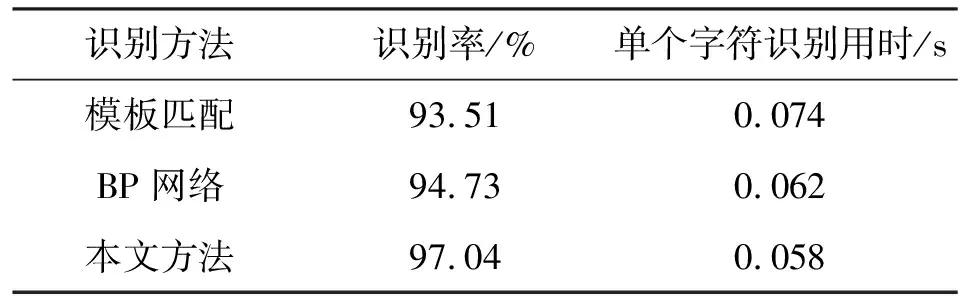
表2 不同识别方法识别率对比
4 结束语
字符识别是车牌智能识别系统中的最后一步,也是最关键的一步,它直接决定了车牌识别的成败.如何提高实际工程应用领域中车牌字符识别准确率和缩短识别耗时,依然值得学者不断深入研究.此处在现有的研究基础上,针对车牌字符结构特征的提取,另辟蹊径,提取经过细化处理后的车牌字符像素斜率值,并将斜率值构造成数学向量,通过计算待匹配字符像素斜率向量与标准模板字符像素斜率向量之间的夹角,完成字符的识别.新方法通过实验结果数据验证了其可行性和高效性.
不足之处在于没有对车牌字符串中唯一的一个中文汉字提出识别算法,其主要原因是目前针对中文汉字识别的研究已经相对成熟,已经存在大量实用性强的中文汉字识别算法[14,15],这些算法均可直接用于车牌中的汉字识别.关于车牌汉字识别算法的研究也是后续研究工作之一.此外,所提出的算法对个别字符存在识别率相对较低的情况,这也是后续研究工作的主要内容.
参考文献:
[1] 谷秋頔,白艳萍.基于模板匹配的车牌数字与字母识别[J].数学的实践与认识,2011,41(20):66-71
[2] 陈玮,曹志广,李剑平.改进的模板匹配方法在车牌识别中的应用[J].计算机工程与设计,2013,34(5):1808-1811
[3] 邓婷.基于特征统计的车牌非汉字字符识别方法[J].广西师范学院学报:自然科学版,2009,26(4):88-92
[4] 张凤清,段书凯,王丽丹.忆阻细胞神经网络在车牌定位中的应用[J].计算机科学,2013,40(06A):58-60
[5] 张燕,任安虎.多特征与BP神经网络车牌识别系统研究[J].科学技术与工程,2012,12(22):5645-5648
[6] 孙孟方,张立文,高火涛.基于支持向量机的字符编码识别系统[J].武汉大学学报:理学版,2013,59(3):245-248
[7] 王桂文,孙涵.基于正交盖氏矩和SVM的车牌字符识别[J].计算机工程,2012,38(13):192-195
[8] 薛丹,孙万蓉,李京京.一种基于SVW的改进车牌识别算法[J].电子科技,2013,26(11):22-25
[9] 朱广涛,李英.基于小波矩和主分量分析的车牌字符识别方法[J].计算机系统应用,2012,21(7):168-171
[10] 郭航宇,景晓军,尚勇.基于小波变换和数学形态学法的车牌定位方法研究[J].计算机技术与发展,2010,20(5):13-16
[11] 何兆成,佘锡伟,余文进.字符多特征提取方法及其在车牌识别中的应用[J].计算机工程与应用,2011,47(23):228-231
[12] 卢达,浦炜,陈琦玮.基于神经网络和模糊匹配算法的手写汉字预分类研究[J].计算机应用,2005,25(10):2418-2421
[13] 方兴林,余萍.一种基于链码向量的图像匹配算法[J].齐齐哈尔大学学报:自然科学版,2011,27(6):25-28
[14] 冯宇,李文举,孙娟红.基于小波变换和分形维数的车牌汉字识别[J].计算机工程,2011,37(22):137-138
[15] 王建平,陈正伟,栾庆磊.基于多群体遗传算法的汉字识别系统设计[J].合肥工业大学学报:自然科学版,2010,33(1):42-46
猜你喜欢
小学生学习指导(低年级)(2019年12期)2019-12-04
电子制作(2019年19期)2019-11-23
电脑爱好者(2019年8期)2019-10-30
电子制作(2019年12期)2019-07-16
数字通信世界(2019年3期)2019-04-19
成都信息工程大学学报(2017年3期)2017-11-09
小猕猴智力画刊(2017年5期)2017-05-25
电子制作(2017年22期)2017-02-02
湖南城市学院学报(自然科学版)(2016年2期)2016-12-01
华东理工大学学报(自然科学版)(2015年2期)2015-11-07
