
改进的支持向量机中文文本分类
2014-08-07 13:23顾伟傅德胜蔡玮
微型电脑应用 2014年10期
顾伟,傅德胜,蔡玮
改进的支持向量机中文文本分类
顾伟,傅德胜,蔡玮
支持向量机是数据挖掘的新方法,由于其优秀的学习能力而得到了广泛的应用,但是,传统的支持向量机算法在处理大规模问题时存在训练时间过长和内存空间需求过大的问题,而应用多个支持向量机构成多分类器系统进行并行学习,是目前解决文本分类中大规模数据处理问题的一种有效方法。在分析传统并行算法的基础上,提出了一种改进的基于多支持向量机的并行学习算法,实验结果表明,采用该算法可使得分类效率得到较大的程度的提高,虽然,分类精度相对传统的方法略差,但是,在可接受的范围之内。
多支持向量机;文本分类;并行算法
0 引言
文本分类又称文本自动分类,是指在给定的类别体系下,由计算机自动根据文本内容将其划归到某一个或者多个类别的过程,是搜索引擎、数字图书馆、信息检索和过滤、话题追踪与识别等领域的技术基础,有着广泛的应用前景,也是目前数据挖掘领域的一个研究热点与核心技术。目前常用的文本分类方法有最近邻(K-Nearest Neighbor,KNN)法、人工神经网络(Artificial Neural Networks,ANN)法、朴素贝叶斯分类法(Naive Bayesian classifier, NB)和支持向量机(Support Vector Machines, SVMs)法等等。其中支持向量机(SVMs)是由Vapnik等人基于统计学习理论和结构风险最小原理的提出的一种机器学习方法[1],由于该方法具有完备的理论基础、出色的学习性能和较强的泛化能力,并且在解决小样本、非线性和高维空间问题中的具有一定的优势,使得支持向量机得到了广泛的关注,并被成功地应用于文本分类、模式识别等领域。
1 相关研究进展
为了进一步提高支持向量机的分类性能,众多专家学者相继对支持向量机进行了大量的研究与应用,并提出了各种不同算法来改进其学习和训练过程以提高支持向量机的分类性能。根据前人的研究成果[2-4],目前支持向量机算法主要有以下几种:增量算法、分解算法、并行算法。
1.1 增量算法
增量算法的提出主要用来解决当样本随时间持续而逐渐增加的情况。此类算法在处理新增样本是,只对原学习结果中与新样本有关的部分进行增加、修改或删除操作,与之无关的部分则不被触及。Ralaivola[5]提出的种增量式学习方法思想是基于高斯核的局部特性,只更新对学习机器输出影响最大的Lag range 系数,以减少计算复杂度。BatchSVM 增量学习算法[6]将新增样本分成互不相交的多个子集,对新增样本分批训练,每次训练中把位于分类间隔以内的样本加入到历史样本中,重新训练, 直到所有新增样本都训练完,杨静等人则在此基础上提出了改进的BatchSVM学习算法[7]。
1.2 分解算法
SVM分解算法最早由Osuna 等人提出,主要思想是基于某种策略将训练集分解成若干子集,在每个子集上训练支持向量机,最后采用某种策略将各支持向量机组合起来[8]。比较典型的算法有SMO算法、chunking算法、SVMlight 算法、libSVM算法等。其中SMO算法是一种特殊的分解算法,该算法将工作集中仅划分为2个样本,由于每次迭代的时间非常短,因而大大缩短了训练时间。
1.3 并行算法
SVM 对于大规模数据集,训练速度异常缓慢,并且需要占用很多的内存,应用多个支持向量机分类器构成多分类器系统进行并行学习,是解决大规模数据处理问题的另一种有效方法。w-model 算法[9]和Cascade SVMs算法[10]是并行支持向量机两种典型的算法。
w-model 算法同时处理w规模最大为b的样本集,其设计思想类似于程序的并发执行,但不同之处在于在下一时刻进行训练时要将当前时刻最后一个并行处理节点抛弃,并将新的增量样本集单独进行训练,所得的结果替换掉当前第一个并行处理节点。由于w-model算法利用多个支持向量机分类器处理流数据,将流数据分布到各分类器上与历史数据进行重组和学习,因而可以避免数据流因随时间变化而可能产生的学习结果突变。但是算法的并行性并没有提高流数据处理所需要的时间,此外该算法需要每次都要在 t+1 时刻舍弃因而可能造成知识的丢失。
Cascade SVMs算法也采用了多个支持向量机分类器对大规模的数据进行并行处理的方法,Cascade SVMs算法保留了所有的分类器,而不舍弃其中的某一个,并且在对分类器进行更新时,将这多个分类器的训练结果结合,产生新的分类器,通过这样的方式来积累学习的结果,并将最后的结果作为反馈对初始的分类器进行调整和更新,以避免分布在多个分类器上的样本集中样本分布差异过大对分类器性能产生的潜在影响。Cascade SVMs 算法利用多个分类器对训练样本集并行处理,降低了整体学习过程需要的时间,同时利用反馈对初始的分类器进行调整和更新,避免了初始训练样本的分布差异过大而对分类器性能产生的潜在影响。但由于反馈是在各训练样本集的支持向量集逐层合并后才进行,在训练样本集个数较多的情况下,逐层训练分类器合并需要花费大量的时间。
尽管前人在SVM算法方面做了大量的工作,但是支持向量机同时还存在一些局限性依然没有克服,例如其求解时间和空间复杂度分别为O(n3)和O(n2),当训练集规模较大时,支持向量机的训练时间会太长并且容易导致内存空间不足。解决此类问题的方法主要是从如何处理样本集的训练问题、提高训练算法收敛速度等方面进行改进,例如工作集方法、并行化方法、避免求解二次规划问题方法和几何方法等等。本文在传统并行算法的基础上提出了一种改进的基于多支持向量机的并行学习算法,并在中文文本分类中取得了一定的效果。
2 SVM分类原理
SVM 方法是从线性可分情况下的最优分类面提出的[11,12],对于一个线性的两类分类问题,SVM的是找出一个合适的分类函数对未知样本进行预测,要求该分类函数不但能将两类正确地分开,并且可以使两类的分类间隔最大以保证最小的分类错误率,如图1所示:
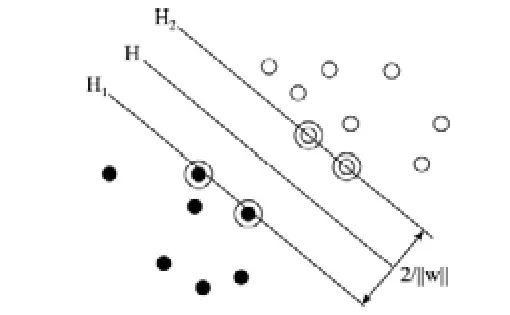
图1 最优分类超平面示意图
图1中实心点和空心点代表两类样本,H为分类超平面,H1和H2分别为过各类中离H最近的样本且平行于H的超平面,它们到H的距离相等,H1和H2之间的距离叫做分类间隔,所谓最优分类超平面就是以最大间隔将两类正确分开的超平面。

其中w表示垂直于超平面的向量,b表示偏移量。将判别函数归一化,使两类所有样本都满足公式(2):
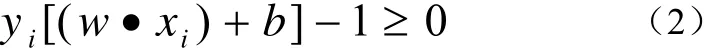
最终的分类判别函数可以表达为公式(3):
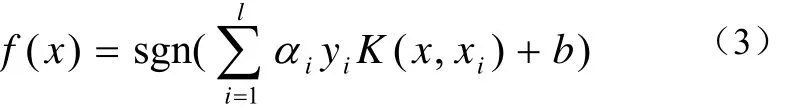
多项式核函数公式(4):
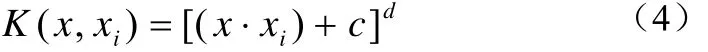
Gauss 径向基核函数公式(5):

Sigmoid核函数公式(6):
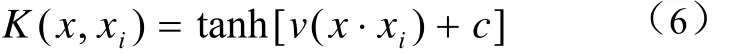
3 一种基于多支持向量机的并行学习算法
应用多个支持向量机分类器对大规模的训练样本集进行并行处理的最基本出发点是[13-17]:按照某种规则划分成多个容易处理的小规模训练样本子集,并将它们分布在多个支持向量机分类器上进行训练。本文在w-model 算法和Cascade SVMs算法的基础上,借鉴二者优点,提出了一种新的并行支持向量机方法。该算法在w-model算法的基础上,采用了多个支持向量机分类器对数据进行并行处理,并且在更新时保留了所有的分类器,但考虑到不同子样本集中样本的分布状态差异对分类器性能产生的潜在影响,因此在更新分类器的时候利用支持向量集的传递构成循环式的反馈,以调整分类器的分类性能,并通过调整Cascade SVMs算法中的反馈方式来节省训练分类器时间,该方法在保证分类器推广能力的同时减少了支持向量机的训练时间,并减少了支持向量的数目。具体算法描述如下:
以二值分类为例,假定己有样本集D和新增样本集M,并且D被划分为K个个不相交的子集,K为2的偶数倍,构造多层支持向量机模型,其算法可以描述为以下步骤:
Step1:分别训练这K个训练子集,得到K个SVM分类器以及对应的支持向量集SVi,i=1,2Kk。
Step2:分别SVi两两合并,进行训练后得到相应的支持向量集SVj,j=1,2,Kk/2
Step3:重复步骤2中的操作,直到得到最后需要合并的SVm和SVn。
Step4:分别将SVm和SVn 作为反馈向量加入到前k/2和后k/2个训练子集中,重新进行训练,重复步骤1至步骤3,得到新的SV’m和SV’n。
Step5:如果SVm-SV’m= Ø且SVn-SV’n=Ø,则将SV’m和SV’n合并,如果其差集为一固定的训练样本或者SVm-SV’m≤εand SVn-SV’n≤ε,则合并SV’m和SV’n,并加入(SVm-SV’m)和(SVn-SV’n)。
Step6:训练合并后的支持向量集,并得到最终的分类器SVMS。
Step7:将新增样本集M划分为若干个子集进行增量学习,在分类精度不满意的情况下将对应的子集加入到集合D中,并转至步骤1,重新训练。
Step8:End
4 算法实验与分析
4.1 实验描述
真实的数据来自复旦大学中文文本分类库,该文本库由复旦大学计算机信息与技术系国际数据库中心自然语言处理小组构建,该文本全部采自互联网,包含20个文本类别,该语料库分为训练集和验证集两部分,去除部分损坏文档后,得到完整文档18185篇。本文从该数据库中提取了经济、运动和环境3个方面的数据,任选其中的两类构成一个两类分类问题,于是就可以得到3个两类问题,如表1所示:

表1 实验数据分布
所有实验的硬件平台为:操作系统为Microsoft Windows XP Professiona ( SP3),CPU为P4 4. 0GH z, 内存4G MB,硬盘500 GB;软件平台为Matlab7.0。本文的实验系统是用C++语言编写而成,其中分词系统采用的是中科院研制的汉语词法分析系统 ICTCLAS(Institute of Computing Technology, Chinese Lexical Analysis System),经过特征提取后,特征空间的维数为4000;同时,为了便于和传统机器学习方法对比,标准的SVM分类方法使用的是台湾大学林智仁的开源工具包LIBSVM。
4.2 实验结果及分析
本文采用准确率(Precision)、召回率(Recall)、和训练时间来评价w-model 算法[9]、Cascade SVMs算法[10]以及标准SVM和改进后的并行SVM分类效果。准确率是判定属于某类的文本中,正确的判定所占的比例,召回率是对于某类文本,最终给出的判定结果中,正确的判定所占的比例,训练时间则是用来判定算法的工作效率,如表2~表4所示:
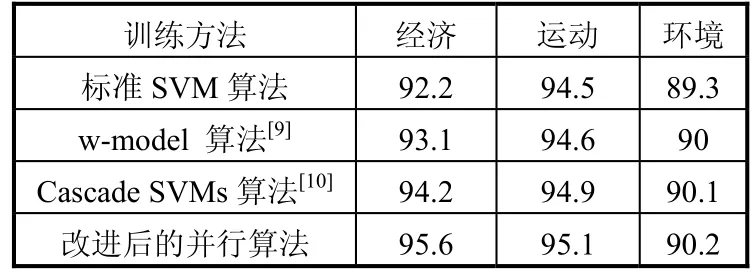
表2 不同算法的分类准确率对比(%)

表3 不同算法的分类召回率对比(%)
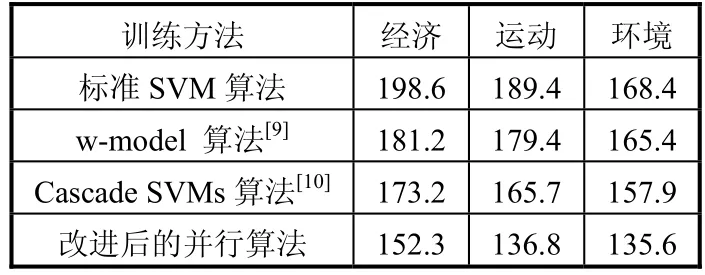
表4 不同算法的训练时间对比(s)
从表1和表2可以看出,在准确率(Precision) 和召回率(Recall)方面,改进的算法在经济、环境和运动类比w-model 算法[9]、Cascade SVMs算法[10]以及标准SVM都高。表3的结果表明,在训练耗时方面,改进后的SVM算法则比w-model 算法[9]、Cascade SVMs算法[10]以及标准SVM都低,提高了分类的效率。
通过以上分析可以看出,分类的效率的提高是本算法最主要的一个优点,具有较高的使用价值。不足的地方是改进后的方法分类效果相对传统的方法相对较差,但是均在可接受的范围之内。这是因为文本分类涉及文本表示、权重计算、特征提取、分类算法等多种复杂技术,每一个环节都会对最终的分类效果产生影响。因此需要对文本分类各个环节都做一定的研究与改进,这样文本系统的性能才会有明显的提高。
5 总结
本文在分析传统并行算法的基础上提出了一种改进的基于多支持向量机的并行学习算法,并对真实语料进行了实验测试,实验结果表明这种并行的多支持支持向量机是一种具有较好泛化能力、性能优越的技术,采用该算法可使得分类效率得到较大的程度的提高,虽然分类精度相对传统的方法略差,但是在可接受的范围之内。
[1] Vapnik V N. The Nature of Statistical Learning Theory [M].New York: Springer-Verlag,1995:205-208.
[2] 顾亚祥,丁世飞.支持向量机研究进展[J].计算机科学,2011,38(2):14-17.
[3] 祁亨年.支持向量机及其应用研究综述[J].计算机工程,2004,30(10):6-9.
[4] 王晓丹,王积勤.支持向量机训练和实现算法综述[J].计算机工程与应用,2004,13(10):75-78.
[5] Ralaivola L, Flovence d. Incremental Support vector machine Learning: a Local Approach[C] Proceedings of International Conference on Neural Network s. Vienna, Aus t ria,2001: 322-330.
[6] Domeniconi C, Gunop lo s D. Incremental support vector machine construction [A]. ICDM [C]. IEEE Trans, 2001: 589- 592.
[7] 杨静, 张健沛, 刘大听.基于多支持向量机分类器的增量学习算研究[J ]. 哈尔滨工程大学报, 2006, 26 (1) : 103- 106.
[8] Cristian, Shawe t. An introduction to support vector machine [M]. New York: Cambridge University Press, 2000.
[9] Lin K M, Lin C H. A Study of Reduced Support Vector Machines[C]. IEEE Transactions on Neural Network, 2003.
[10] Hans Peter Graf, Eric Cosatto, Leon Bottou, et al. Parallel Support Vector Machines:The Cascade SVM[C]. Proceedings of NIPS, 2004, 196-212.
[11] Cristianim N, Shawe-Taylor J.Introduction to Support Vector Machine[M].Cambridge University Press,2000.
[12] 李国正,王猛,曾华军译.支持向量机导论[M]. 北京:电子工业出版社,2004.
[13] Y.Yang, X.Liu.A Re-examination of Text Categorization Methods[C]. ACM (SIGIR'99).New York.ACM.Press. 1999:42-49.
[14] 马金娜; 田大钢.基于支持向量机的中文文本自动分类研究.系统工程与电子技术[J ].2007,03:254-258.
[15] 张苗,张德贤.多类支持向量机文本分类方法[J].计算机技术与发展, 2008,03:154-158.
[16] 张振宇.稳健的多支持向量机自适应提升算法.大连交通大学学报 2010,04:147-152.
[17] 付晓利,杨永田,张乃庆.一种基于多支持向量机的增量式并行训练算法[J ]. 航空电子技术,2007,06:214-217.
Improved SVM for Chinese Text Classification
Gu Wei1, Fu Desheng2, Cai Wei3
(1. Jiangsu Engineering Center of Network Monitoring, Nanjing University of Information Science & Technology, Nanjing210044, China; 2. School of Computer & Software, Nanjing University of Information Science & Technology, Nanjing210044, China; 3. School of Computer Engineering, Nanjing Institute of Technology, Nanjing 211167, China)
Support Vector Machines (SVMs) is a new technique for data mining. It has wide applications in various fields and is a research hot pot of the machine learning field. However, SVMs needs longer training time and larger memory when it is applied to handling large-scale problems. It’s an effective way to solve large scale data processing in text classification with multiple classifier systems composed by multiple support vector machine classifiers. Based on the analysis of traditional parallel algorithms, an improved algorithm based on multiple SVMs is proposed. The experimental results indicate that the new algorithm works well in precision and recall rate in the condition that the speeds of classification increases remarkably. Compared with traditional algorithms, the classified accuracy is lower but is within the range for acceptance.
Multiple SVMs; Text Classification; Parallel Algorithms
TP311
A
1007-757X(2014)10-0017-03
2014.06.27)
江苏高校优势学科建设工程项目(PAPD)
顾 伟(1983-),男,江苏南京,硕士,南京信息工程大学,江苏网络监控中心,实验师,研究方向:模式识别、人工智能、数据挖掘,南京,210044傅德胜(1950-),男,江苏南京,博士,南京信息工程大学,江苏网络监控中心,教授,研究方向:数据挖掘,信息安全,南京,210044蔡 玮(1981-),男,江苏南京,硕士,南京信息工程大学,讲师,研究方向:数据挖掘、软件工程,南京,211167
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
数学小灵通(1-2年级)(2021年4期)2021-06-09
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
中学生数理化·七年级数学人教版(2018年6期)2018-06-26
初中生世界·七年级(2017年9期)2017-10-13
计算机应用(2017年4期)2017-06-27
光学精密工程(2016年4期)2016-11-07
光学精密工程(2016年3期)2016-11-07
高中生学习·高三版(2016年9期)2016-05-14
