
基于粗糙集约简并加权的SVM分类算法
2014-07-25 09:00吴欣远林建辉
网络安全与数据管理 2014年20期
吴欣远,林建辉
(西南交通大学 牵引动力国家重点实验室,四川 成都 610031)
0 引言
支持向量机(Support Vector Machine,SVM)方法在模式分类中应用广泛[1-2]。它以VC维和结构风险最小化为基础,根据有限的信息在模型对特定样本的学习精度和学习能力之间得到问题的最优解。SVM使用内积函数将输入空间变换到一个高维空间,从中求广义最优分类面,较好地解决了过学习、高维数等实际问题,且具有较好的鲁棒性。但由于SVM最终将分类转换成二次规划问题,其计算量随着变量的增加而呈指数增长。在Web文本分类中,文本类别和数目多、噪音多,文本向量稀疏性大、维数高,中文文本的特征向量可能存在冗余且具有较大的相关性,这将导致SVM网络结构和核函数计算复杂[3]。如何减少SVM的分类训练时间,进一步提高分类精度,是当前需要解决的热点问题。由此,本文提出了基于粗糙集约简并加权的SVM分类算法。
1 粗糙集基本理论
1.1 知识表示系统和知识
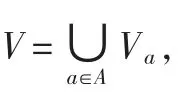
1.2 约简
设U为论域,R为U上的不可分辨关系。如果ind(R)=ind(R-{r}),r∈R,则称r在R之中是可省的,否则就是不可省的;若任一r∈R都是不可省的,则称R是独立的,否则R是相关的,即R中存在可约去的属性;若P⊆R是独立的,且ind(P)=ind(R),则称P是R的一个约简[4-5]。在R中所有不可省的关系的集合称为R的核,以core(R)来表示。
1.3 可变精度粗糙集模型
可变精度粗糙集模型是粗糙集模型的扩展,该模型可以通过设定近似包含阈值α,更精细地对边界上的样本进行划分,从而放松了经典粗糙集严格的边界定义,使其能够更好地处理不一致的信息,具有一定的抗噪声能力[6]。可变精度α-下、上近似集定义分别为:
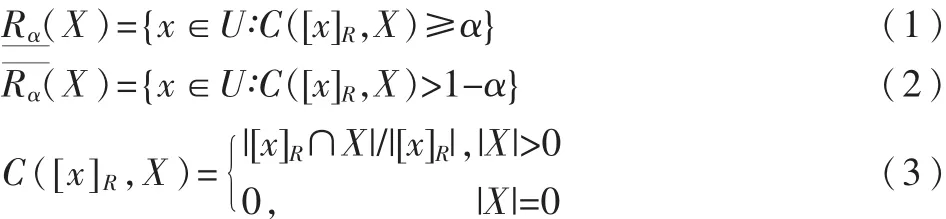
关系R形成的x的等价类被集合X包含的程度由C([x]R,X)描述;α-下近似和 α-上近似分别为关系R下的等价类以大于α包含度以及U中的等价类以大于1-α包含度包含在X中的元素集合;若α=1,VPRS模型退化为传统的粗糙集模型。
2 基于Web中文文本的可变精度粗糙集权重计算方法
基于可变精度粗糙集模型,将n类Web文本集按照文本所属类别划分为U={D1,D2,…,Dn}的等价类,不同的特征词形成的等价关系为R,可以定义 α-上、下近似集分别为:
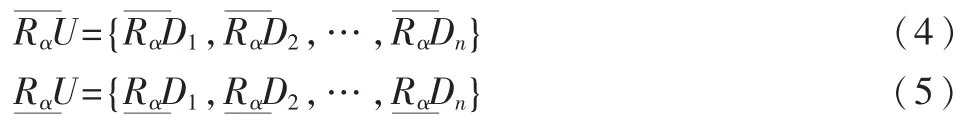
其中,集合Di在等价关系R下 α-上、下近似集分别由和表示;R对U划分的等价类可能或一定包含在决策属性划分的等价类的元素集合分别由和描述;由于Web文本分类中特征词分布具有随机性,因此可以引入式(6)中的分类近似质量 γR(U)来度量关系R对论域划分的等价类被确切分到决策属性划分的等价类的比率[8],近似质量越高,则特征词对分类的贡献就越大,并将其替代逆文本频率对特征词频率进行加权,以提高样本的可分性。

由此,本文提出了基于Web中文文本的可变精度粗糙集加权方法(WVPRS),如式(7)所示:

其中,Hwij为第j个特征词在第i篇Web文本中的权重;n为Web文本样本集的类别个数;tfij为第j个特征词在第i篇Web文本中出现的次数;max(λij)为特征词j所在网页标记 θ(Web文本i中)对应的最大加权系数(参照表1),其中 θ∈S,S={TITLE,H1,H2,H3,H4,H5,H6,B,U,I}。 例如,若特征词j在文本i<TITLE>和<U>中同时出现,则max(λij)=7;如果j只出现在Web文本i的正文中,则取max(λij)=1。
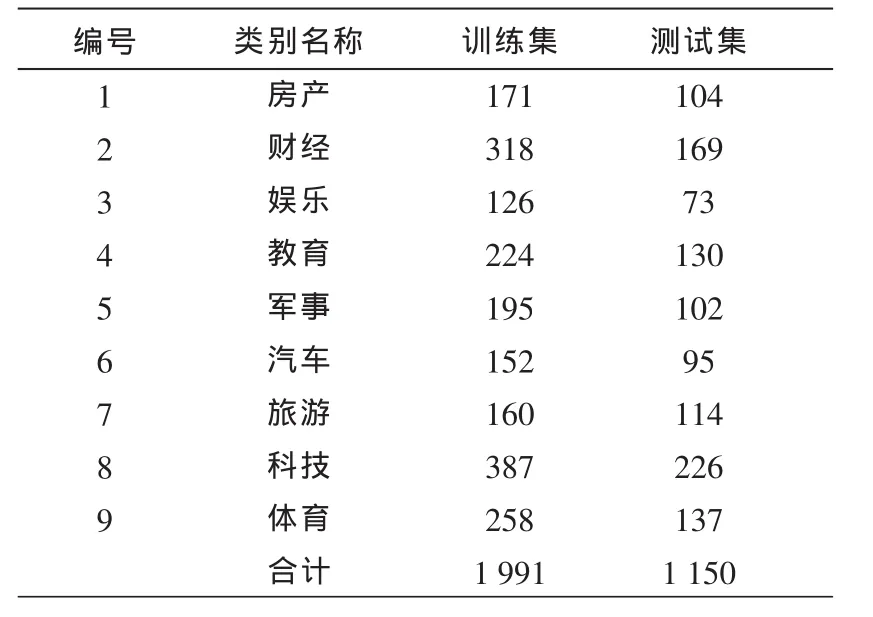
表1 实验用数据集分布
该权重计算方法既考虑到Web文本不同于纯文本的结构特点,应用特征词在Web文本中出现的位置信息对特征词频率进行加权,又考虑到已有的分类决策信息,分别计算特征词与各类决策以及整体决策划分的一致程度,由特征词对Web文本各类别的分类重要程度集中体现整体权重。基于Web文本的可变精度粗糙集加权方法对Web文本中特征词出现频率同时进行标记加权和近似质量加权,更充分地刻画了特征词对Web文本分类的重要程度。
3 基于粗糙集约简并加权的SVM分类算法
本文将粗糙集理论与SVM 相结合,提出了一种优势互补的混合分类模型。该模型由粗糙集的前期数据过滤、中期加权计算和SVM的后期分类三部分构成。
在模型的训练部分,首先对训练集进行分词等预处理和特征选择,并由得到的特征子集构造离散型的决策表。然后将粗糙集作为分类模型的前期数据过滤器,应用其约简理论,以不损失有效信息为前提,过滤掉决策表中的冗余特征,从而简化SVM的输入数据集,减小SVM算法训练复杂度,最终达到节省训练时间的目的。接着,训练模型转向中期权重计算阶段,将粗糙集作为加权计算器,应用式(7)的加权算法进行权重计算,得到Web文本中间表示形式。最后,训练模型转向后期分类阶段,利用SVM算法的优势对粗糙集约简并加权后的数据进行分类训练,最终得到分类性能较高的分类器。
模型的测试部分则应用训练部分得到的决策表约简结果对Web文本测试集直接进行特征提取,之后转向粗糙集的中期加权计算和SVM的后期分类阶段,得到分类结果。
4 实验验证
实验中Web文本训练集和测试集使用软件Webdup 0.93 Beta获取,将台湾大学林智仁开发的LIBSVM作为本实验中的SVM模型,ROSETTA用来做粗糙集的约简及加权等相关计算。
4.1 Web文本的获取以及预处理
用于Web中文文本分类的训练集和测试集包括房产、财经、娱乐、教育、军事、汽车、旅游、科技和体育9个类别,共3 141个文本。这9个类别在所抓取的各网站上都已经进行了很好的分类。数据集分布如表1所示。
扫描Web样本集中的HTML文档源代码,对表1中的标记所修饰内容进行识别并加权,只在正文中出现的内容则不需要加权,默认加权系数为1。本实验采用中科院软研所的ICTCLAS分词程序进行分词,并进行去停用词等预处理。
4.2 特征选择以及构造决策表
本实验中决策表的构造以采用信息增益方法的特征选择为基础。由信息增益的方法保留了对分类比较重要的1 000个特征项,然后构造决策表。决策表的论域为每类中所有Web文本的集合,论域中的对象则为每篇Web文本,Web文本的类别为决策属性,决策属性值即为某文本所属具体的类别,特征选择后保留的各特征词作为决策表的条件属性;接着通过测定特征词在某Web文本中出现的位置来确定其在该Web文本对象上所对应的条件属性值。
由此算法得到的条件属性值即为特征词所在Web文本标记对应权值系数的最大值(若特征词仅在正文中出现或者未在Web文本中的任何位置出现,那么该特征词的权值系数分别设为1和0)。例如,如果特征词在某Web文本的正文、<H3>标记中同时出现,则该特征词对应此Web文本对象上的属性值为4。综上所述,经过特征选择,重要的特征词被保留下来,这时再由Web文本的结构特征确定其所对应的属性值,得到了规模较小、离散型的决策表,同时不会影响分类的质量。
4.3 决策表的约简
常用的属性约简算法有属性逐步删除、属性逐步增加、基于可辨识矩阵和逻辑运算等方法。本实验中采用可辨识矩阵和逻辑运算进行决策表的约简,约简后保留了673个特征项,“属性蒸发”了32.7%。可见,粗糙集的约简算法有效地缩减了特征维数并对数据进行了 “浓缩”。
4.4 WVPRS权值计算和SVM分类
对上一步骤中经过粗糙集约简后保留的特征项应用前文提出的基于Web中文文本的可变精度粗糙集加权方法(取 α=0.8)进行权值计算,得到文本向量,然后转向SVM进行分类训练,并将训练得到的分类器分别与约简前、未考虑Web文本标记加权、采用逆文本频率加权的各SVM分类器性能进行比较。为了方便描述实验结果,特做如表2所示的标号。
实验过程中,SVM分类器采用线性核函数,选用查准率、查全率以及F1值来衡量分类效果,分别对表中不同方法的分类效果进行比较并分析,实验结果如表3~5所示。

表2 实验过程中采用的方法
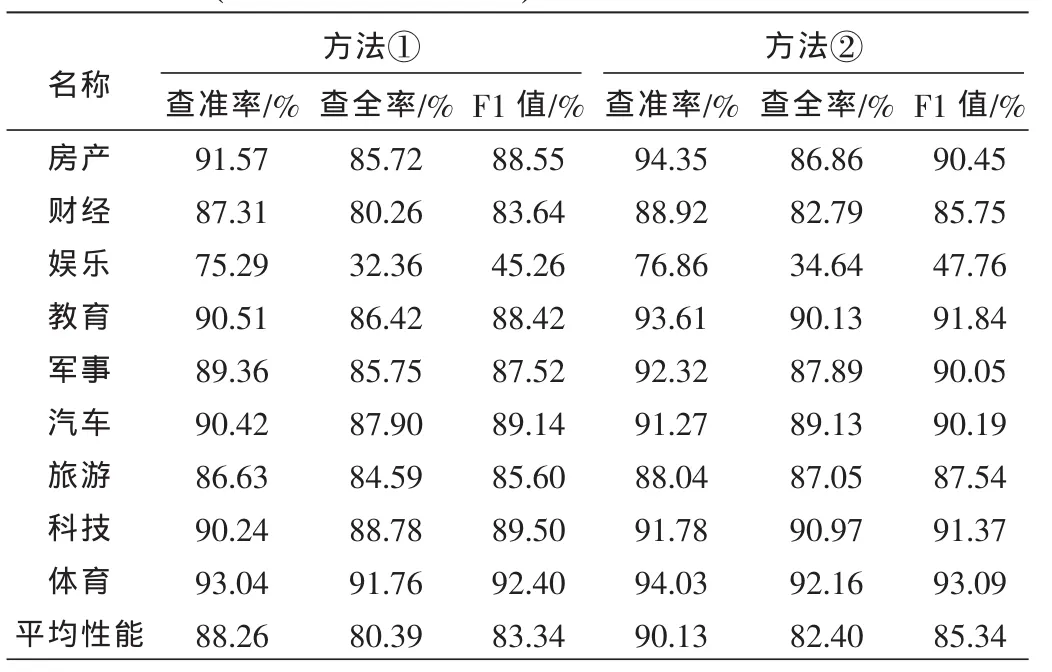
表3 采用方法①和方法②(标记加权前后)的分类器性能

表4 采用方法②和方法③(约简前后)的分类器训练时间

表5 采用方法③和方法④的分类器性能
通过表3可以看出:在相同的实验环境下,使用相同的数据集并采用未经过粗糙集前期数据约简和加权的SVM分类算法,方法②对Web文本中的特殊结构标记进行加权后,分类器的查准率、查全率、F1值较方法①分别提高了2.11%、2.50%、2.40%,方法②分类的平均性能比方法①要好。可见,对能够体现Web文本结构的特殊标记进行适当加权有利于改善分类器的性能。
表5中的方法③和方法④均考虑了Web文本中特殊标记和粗糙集约简对分类的作用,而方法④在特征词权重计算过程中引入了分类决策信息,将逆频率替代为近似质量对特征词在当前文本中出现的频率进行双重加权,进一步提高了SVM的分类精度,查准率、查全率和F1值分别提高了3.23%、2.67%和2.96%。结果表明,权重计算过程中考虑标记和已有分类决策信息的作用,能够有效地提高分类精度。
5 结论
SVM在分类问题中能够表现出非线性、高维输入空间等优势,而面对Web文本分类中噪音多、文本稀疏性大、特征词存在冗余等问题使SVM呈现出训练时间长、分类速度慢等不足。对此,本文阐述了粗糙集的约简理论和可变精度粗糙集模型,分析了HTML标记对网页内容的修饰作用并设计了特殊标记加权方案,提出了基于Web中文文本的可变精度粗糙集加权方法,最后设计了以粗糙集约简和权重计算作为前端预处理器,以SVM作为后端分类器的混合算法。实验证明,该算法从分类效率和分类精度两个方面对经典的SVM模型进行了优化,使其分类性能得到进一步保证。
[1]木林.基于SVM算法和其他算法在文本分类中的性能比较[J].内蒙古大学学报(自然科学版),2011,42(6):703-707.
[2]姜春茂,张国印,李志聪.基于遗传算法优化SVM的嵌入式网络系统异常入侵检测[J].计算机应用与软件,2011,28(2),287-289.
[3]胡志军,王鸿斌,张惠斌.基于距离排序的快速SVM分类算法[J].计算机应用与软件,2013,30(4),85-87.
[4]YeMingquan,WuXindong,HuXuegang,etal.Anonymizing classification data using rough set theory[J].Knowledge-Based Systems,2013,43(1):82-94.
[5]赵东红,王来生,张峰.遗传算法的粗糙集理论在文本降维上的应用[J].计算机工程与应用,2012,48(36),125-128.
[6]兰均,施化吉,李星毅,等.基于特征词复合权重的关联网页分类[J].计算机科学,2011,38(3):187-190.
[7]胡清华,谢宗霞,于达仁.基于粗糙集加权的文本分类方法研究[J],情报学报,2005,24(1):59-63.
[8]杨淑棉.粗糙集在文本分类系统中的应用研究[D].济南:山东师范大学,2007.
猜你喜欢
舰船电子工程(2022年4期)2022-05-11
四川师范大学学报(自然科学版)(2021年6期)2021-11-15
计算机系统应用(2021年9期)2021-10-11
计算机工程与应用(2020年12期)2020-06-18
成都信息工程大学学报(2019年2期)2019-08-28
计算机技术与发展(2018年8期)2018-08-21
自动化学报(2018年2期)2018-04-12
中国机械工程(2017年22期)2017-12-02
智能系统学报(2017年3期)2017-08-01
计算机与数字工程(2016年11期)2016-12-13
