
基于ZYNQ的稠密光流法软硬件协同处理
2014-07-19 15:10王芝斌阳文敏张圆蒲柴志雷
计算机工程与应用 2014年18期
王芝斌,阳文敏,张圆蒲,柴志雷
江南大学物联网工程学院,江苏无锡 214122
基于ZYNQ的稠密光流法软硬件协同处理
王芝斌,阳文敏,张圆蒲,柴志雷
江南大学物联网工程学院,江苏无锡 214122
1 引言
光流法在许多视频或图像应用中有广泛的应用前景,比如运动物体检测、运动物体估计、视频压缩等。光流法是由于场景中前景目标本身的移动、相机的运动,或者两者的共同运动所产生的。对光流算法的研究,真正提出有效光流计算方法还归功于Horn-Schunck[1]在1981年创造性地将二维速度场与灰度相联系,引入光流约束方程的算法,是光流算法发展的基石。通过光流法评估机制[2-3]的验证,基于Horn-Schunck[1]的稠密光流法模型,与经典的稀疏光流法Lucas-Kanada[4]相比,不但能够产生稠密光流法,而且能计算出很好的光流效果。
高质量的光流算法计算机非常复杂。对于分辨率为640×480的灰度图片,在Xilinx的FPGA+ARM异构芯片(即ZYNQ)上,单独利用ARM Cortex-A9的处理器上,计算基于HS(即Horn-Schunck)模型的稠密光流场需要24.40 s。低效的计算速度限制了光流法在现实世界的可应用性。目前有很多工作都关注于高效能的稠密光流计算。在通用处理器上研究降低光流计算的复杂度[5-6],更多的工作关注在专用硬件平台上加速光流的计算[7-8]。
Martin等人[9]在Altera APEX20XK的FPGA上也实现了基础的HS光流法,处理256×256的图片序列每秒能够达到60帧,但是影响HS光流法计算时间的一个关键参数(即迭代次数)没有清晰的说明。Rustam等人[10]提出使用了整数和组合整数、小数的基于HS光流法的硬件体系。同样地,光流法的迭代次数也没有详细给出。Gultekin等人[11]在Altera Cyclone-II的FPGA平台上,实现了基于HS的光流法,在工作频率为50 MHz的情况下,每秒可以处理257帧的256×256图片序列。但是,它并不是计算整张图片的稠密光流,而是计算图片内的一块小区域。然而,由于不易调试和底层的编程语言,即VHDL/Verilog,在单纯的FPGA上实现复杂图像算法非常耗时。所以,目前基于FPGA的光流法计算大部分停留在一些最基础的光流算法[9-11]。
随着异构芯片技术的不断发展,传统处理器和FPGA组成的异构系统芯片有潜力能够胜任高效能计算[12-13],如Xilinx公司的FPGA异构系统芯片(ZYNQ)。而且与传统的FPGA开发语言相比(即VHDL/Verilog)相比,随着高层综合语言的发展,集成了Xilinx开发环境的高层综合(HLS)技术,80%的高层综合语言(即C、C++、System C)与20%的底层综合语言(即VHDL、Verilog),能够大幅度提高FPGA的开发效率。
本文针对FPGA的异构系统平台(即ZYNQ),利用最新的高层综合(HLS)语言与传统的硬件描述语言相结合,通过算法的可并行性分析,重构与优化FPGA可运行的C代码,设计了基于HS稠密光流法的硬件加速器的IP核。针对ZYNQ平台的特点,调用已设计好的光流算法IP核,完成系统的硬件与软件设计。实验结果显示,对于640×480大小的图片,基于ZYNQ的软硬件协同的方式比纯软件方式的计算性能提高了34倍,执行时间从24.40 s降低到0.71 s。
2 稠密光流算法的工程流程介绍
图1所示是基于HS稠密光流法的基本工作流程,可以把光流法的计算划分为四个阶段:预处理(S1)、梯度计算(S2)、运动模型构造(S3)和迭代计算(S4)。
2.1 预处理(S1)
预处理(S1)阶段是平滑处理图像序列,它的作用即是用来减少图像噪音和外部的影响,一般用卷积来实现。这一阶段是一个通用的图像操作。
2.2 梯度计算(S2)
梯度计算(S2)阶段是在平滑后的图片的基础上计算图像的梯度,包括水平梯度(Ex)、垂直梯度(Ey)和时间梯度(Et)。基于HS的模型只需要一阶梯度的信息,通常梯度计算也是通过卷积来实现的。
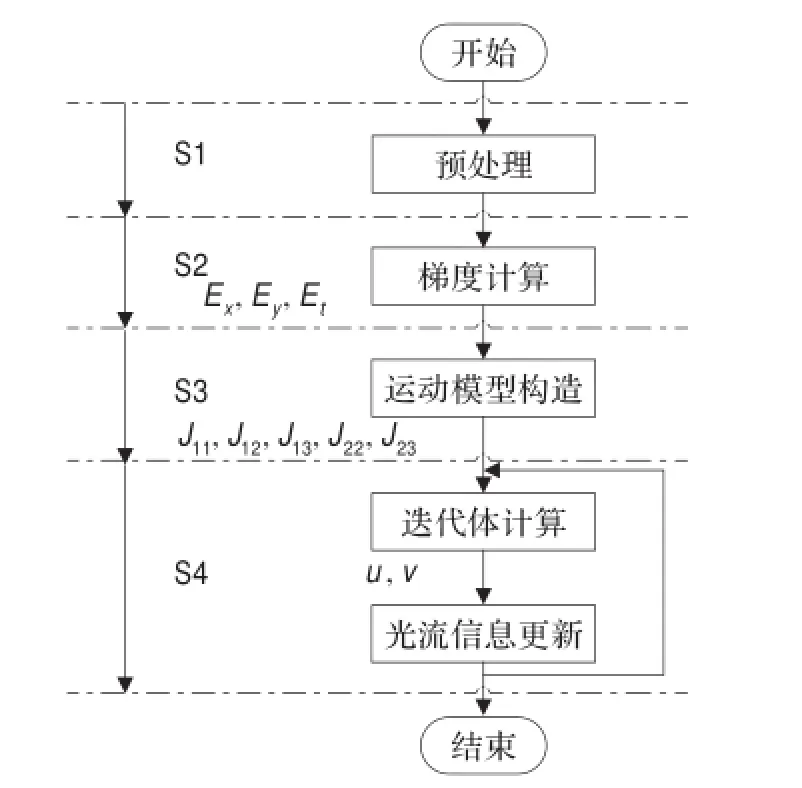
图1 基于HS的稠密光流法工作流程
2.3 运动模型构造(S3)
运动模型构造(S3)阶段是根据梯度信息来构造运动模型的信息。基于HS的稠密光流模型,需要构造5个运动模型信息(J11、J12、J13、J22和J23)。对于不同的运动模型由不同的梯度信息融合而构成。这一阶段的操作就是矩阵相乘,如公式(1)所示,J表示构造的运动模型,E表示梯度。
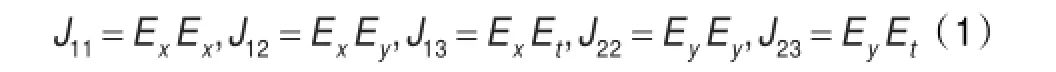
2.4 迭代阶段(S4)
迭代计算(S4)阶段是通过全局迭代计算光流,对于基于HS稠密光流法的模型,只需要更新光流模型(u,v)。如公式(2)所示,迭代体的计算是根据线性的超松弛算法(SOR),其中,i表示像素点的行坐标,j表示像素点的列坐标,J表示构造的运动模型,u和v分别表示水平和垂直的光流模型,N-(i)表示第i个像素点的上和左的相邻像素点,N+(i)表示第i个像素点的下和右的相邻像素点,w是超松弛迭代的权重因子,k是迭代的次数,ɑ是光流平滑的权值。
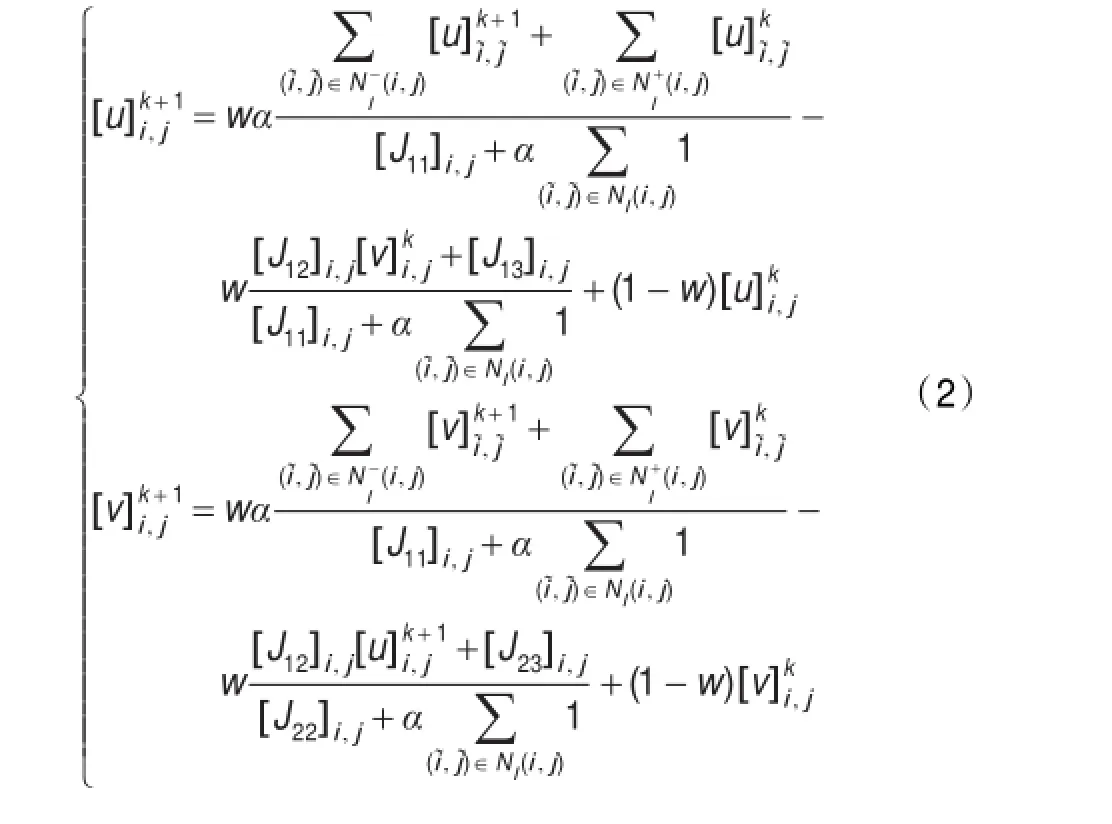
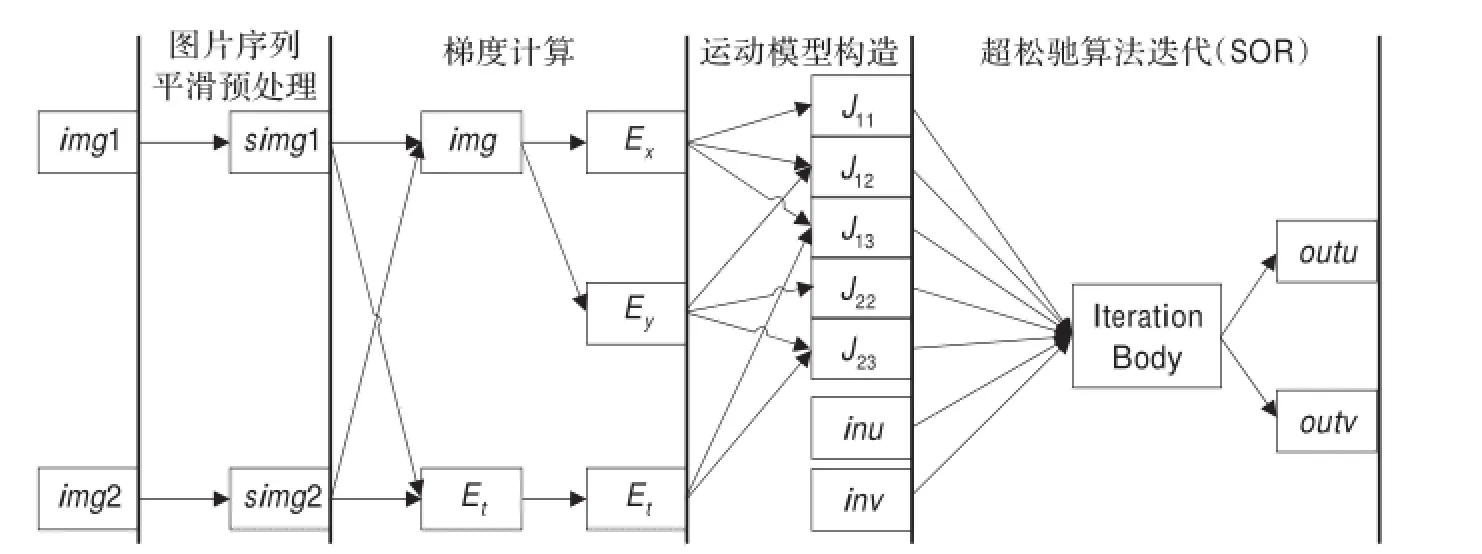
图2 光流计算的数据相关性
3 并行性分析
下面从任务并行、数据并行和流水线并行给出基于HS稠密光流法的并行性分析。
3.1 任务并行
如图2所示,每个阶段之间的操作都存在数据相关性,但是在同一个阶段内,多种操作可以自己独立计算。通过平滑处理图片序列(img1,img2),可以同时得到平滑后的图片(simg1,simg2);然后根据两张平滑后的图片的平均值((simg1+simg2)/2),可以计算水平梯度(Ex)和垂直梯度(Ey),同时时间梯度(Et)是两张图片相减所获得的;同样地由公式(1)可以同时得到5个运动模型的信息。这些操作都可以独立和同时计算,迭代计算部分的并行性会在下面分析。
3.2 数据并行
预处理和梯度计算的操作都可以通过卷积来实现,卷积操作是一个典型的数据并行。对于运动模型构造阶段,每一个运动模型的计算都可以通过相同的指令,这些操作都能够高效地实现并行计算。
3.3 流水并行
对于前三个阶段(S1,S2,S3),每一个阶段之间的数据交互,在合适的硬件上可以全流水线地工作。如图3所示,迭代计算需要迭代次数去获取结果,这就导致了整个系统的流水线性能的下降。因此,迭代计算部分应该首先被重构与优化。在实际优化中,展开迭代,需要展开以提高流水线的性能;在理想状态下,硬件资源足够的条件,整个系统几个周期全流水完成处理。

图3 SOR与Red-Black SOR的数据相关性
4 重构与优化FPGA运行的光流计算C代码
4.1 重构与优化FPGA可运行的迭代体
从并行性分析可知,迭代阶段(S4)首先重构与优化迭代体,由公式(2)可知,在计算光流(u或者v)的时候,它的每一个像素点的4个邻居都有数据相关性。如图3(a)所示,假设像素点7正在计算,像素点2,6,8,12都需要计算,特别是左上的像素点2,6已经更新了,而右下的像素点8,12没有更新。因为左上的两个像素点需要立即更新,这导致了原始的超松弛算法(SOR)不能并行处理。为了避免数据相关性,这里使用改进的红黑超松弛算法(Red-Black SOR)。如图3(b)所示,用红黑两次扫描来替代一次扫描,首先是红扫描处理的就是红色的像素点,此时它的4个邻居都是黑色没有更新的像素点;接着就是黑色像素点的处理,此时它的4个邻居都是已经更新的红色的像素点。不管哪一个颜色扫描,它周围的4个像素点都能够被同时处理,适合在FPGA上的并行计算。
图4所示的是用高层综合语言重构的C代码的红黑超松弛算法的硬件结构图。通过3×3的窗口的操作,在几个周期的延迟后,窗口内的9个像素点是能够满足同时访问光流的4个邻居像素点,这就是满足了并行计算的条件。在SOR初始化延迟后,每隔5个周期,每一组的数据流(inu、inv、J11、J12、J13、J22和J23)都会被立即处理,最后获得每一次迭代的光流值(outu、outv)。
4.2 优化迭代计算及其与外部存储器的带宽
如图4所示,迭代体的输入数据通道的接口由5个32位的运动模型和2个32位的光流模型构成,高带宽的输入数据通道(224位),易导致低效地访问外部存取器。为了高效地利用外部存取器,从两个方面来优化,一方面是减少访问外部存取器的次数,另一方面是降低通信的带宽。
为了减少访问外部存取器的次数,通过迭代展开可以有效地减少外部迭代的次数,使得多份迭代体能够流水地并行计算,增加了流水线指令的计算性能。为了降低通信的带宽,如图5所示,从预处理(S1)到运动模型构造(S3)也放在了迭代体的内部。对于每一次迭代,原始图片序列(img1,img2)与光流模型(u,v)构成了迭代体的输入数据端口,访问外部存取器的带宽降到了128位。前三阶段的计算时间要比访问高位宽外部存取器的时间短得多。
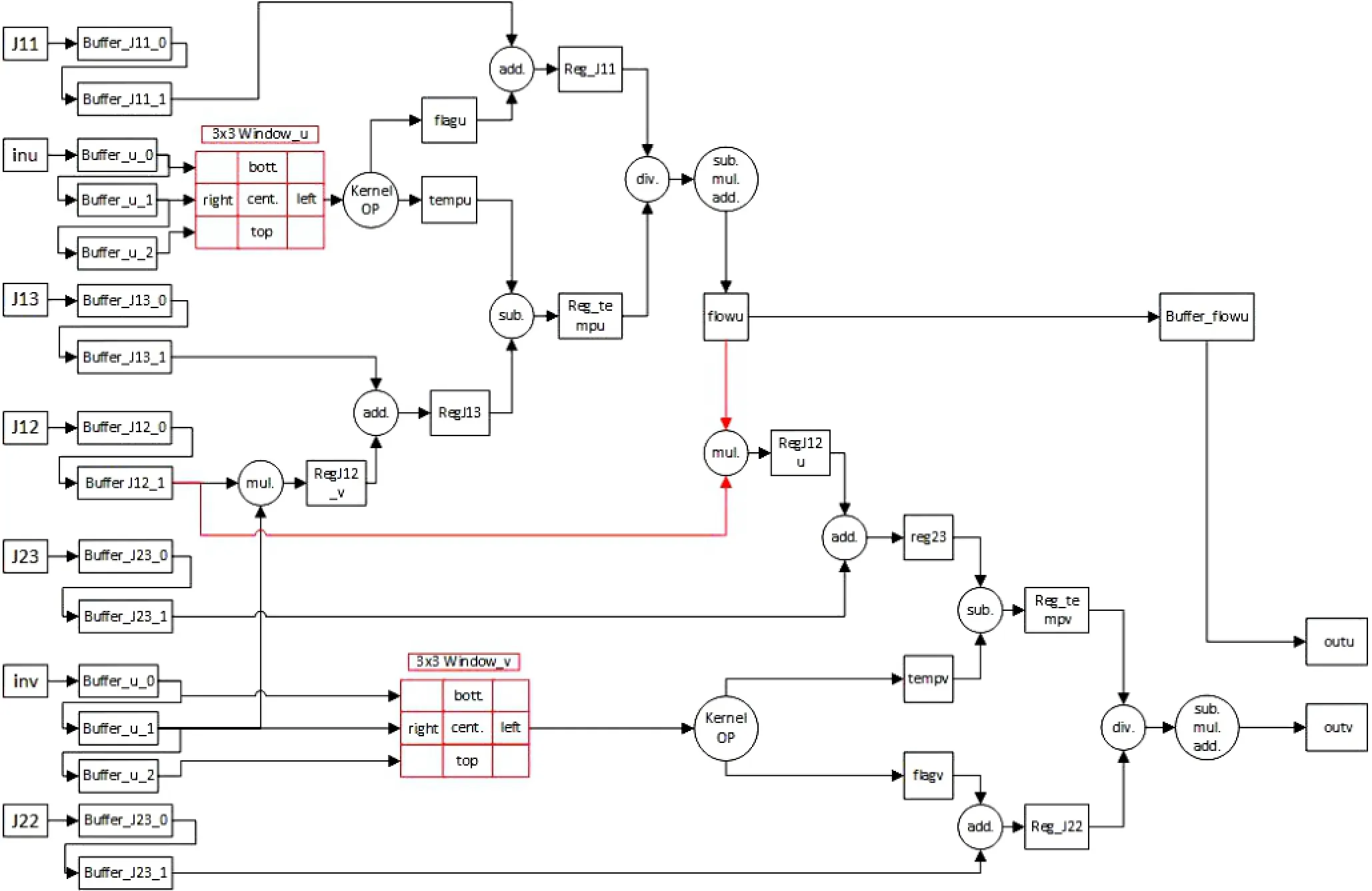
图4 用C描述的红黑迭代体的硬件结构图
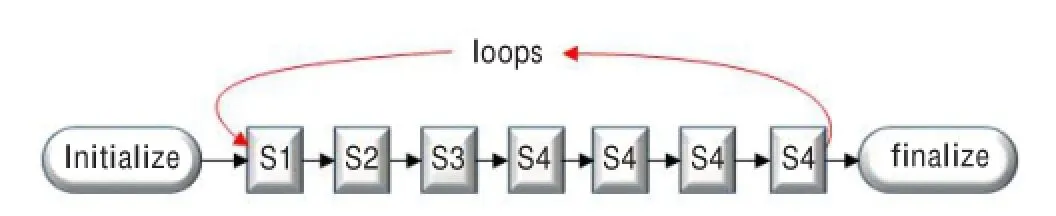
图5 改进的光流法的流水线
4.3 重构光流计算的其他阶段
在优化后的迭代体的内部,光流计算的前三个阶段(S1、S2、S3)也需要重构与优化FPGA可执行的C代码。预处理(S1)和梯度计算(S2)都是用卷积来实现的。卷积在FPGA上并行计算在前面的工作[14]已经详细讨论过了。运动模型构造(S3)是简单的乘法计算,可以直接在FPGA上实现。
5 稠密光流法在ZYNQ上的系统设计
使用Xilinx的高层综合(HLS)语言重构与优化了基于HS的稠密光流法计算,生成了基于ZYNQ的光流计算的IP核。下面针对ZYNQ的体系结构,结合HLS生成的光流算法的IP核,实现稠密光流法在ZYNQ上的软硬件协同。图6所示的是基于ZYNQ的稠密光流法的体系结构图,ZYNQ系统芯片集成了基于ARM的处理系统(PS)和可编程逻辑(PL)。
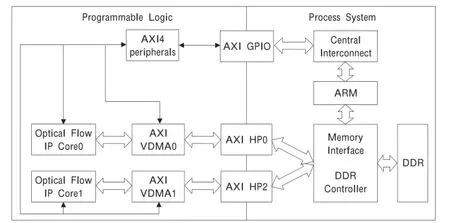
图6 基于ZYNQ光流法软硬件协同的结构图
PL端光流IP核与外部存取器(DDR)的通信方式是基于ARM的AXI4总线协议,其中PL端的数据通路是由视频直接存取访问(AXI VDMA,Video Direct Memory Access)来读写外部存取器的数据,PS端通过通用输入输出接口(GPIO)主动控制PL端的控制通路。为了完成外部迭代计算,使用两个光流的IP核流水地并行计算。光流的IP Core0通过AXI VDMA0读取数据区A,经过光流IP核的硬件延迟,处理完成的结果由AXI VDMA0写入数据区B;此时控制光流的IP Core1通过AXI VDMA1读取数据区B,经过PL端加速,处理完成的结果由AXI VDMA1写入数据区A;形成了一个高效的迭代计算环。
6 综合实验
综合实验采用平台是Digilent的Zedboard,其芯片是由FPGA与ARM组成的ZYNQ(ZYNQ7020CLG484)异构系统芯片。对于纯软件的处理方式,光流计算是在ZYNQ上的ARM Cortex-A9(即Processing System,PS)上处理的,其中PS端有两个32 KB的一级缓存、一个512 KB的共享二级缓冲和512 MB的外部存取器。对于软硬件协同的处理方式,ARM端和FPGA端协同工作。选用的图片序列是最新的Middlebury[2]光流测试集。
6.1 基于ZYNQ的光流法软硬件协同的资源利用率和功耗
表1是基于ZYNQ光流法软硬件协同在PL端的资源利用率,其中光流计算的IP核迭代计算(S4)流水的分数是2。从表中可以看出,FPGA的资源已经消耗了很多,如果在硬件资源足够的情况下,可以把P5做成更多的份数,这样可以减少外部迭代的次数,从而提高整个系统的吞吐率。数据通路的工作频率是100 MHz,控制通路的频率是50 MHz,而且整个系统的片上功耗只有1.911 W。
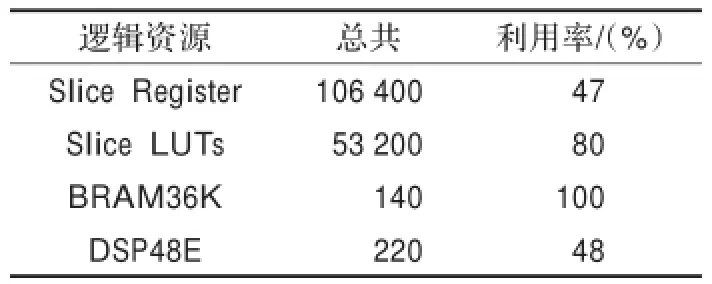
表1 PL端的资源利用率
6.2 软硬件协同与纯软件工作模式下的计算光流的时间比较与分析
在ZYNQ的ARM端软件单独计算稠密光流,随着图片的不断增大,算法的执行效率会直线下降;在软硬件协同的情况下,FPGA端对核心算法的进行加速运算,ARM端对FPGA端的IP核进行控制。如表2所示,软硬件协同执行的时间平均要比软件的执行时间快25倍左右,特别是对于大的图片,比如640×480的分辨率,软硬件协同的执行时间比纯软件执行要快34倍。对于光流算法,分辨率越大,计算出来的光流的细粒度也就越好,效果也就越准确。例外,纯软件工作下的迭代计算方法是原始的SOR迭代方法,迭代的次数为100;软硬件协同的采用改进的Red-Black SOR的迭代方法,迭代的次数同样也为100。
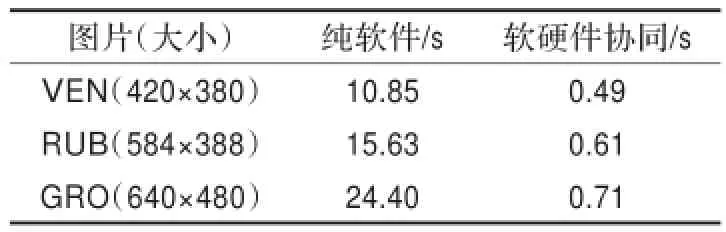
表2 基于ZYNQ的光流法软件与软硬件协同的执行时间比较
6.3 软硬件协同与纯软件工作模式下的计算光流的效果比较与分析
表3所示的是基于HS的光流法软件与软硬件协同工作模式下的光流效果的比较,采用的评价机制是平均角误差[2](Average Angular Error,AAE)。其中在纯软件工作模式下,给出了原始的SOR迭代方法与改进的SOR迭代方法的光流效果AAE误差。实验结果显示原始的SOR迭代方法计算的光流的结果更平滑,但是其细粒度的数据相关性不适合FPGA的并行计算,而Red-Black SOR在消除了其数据相关性的同时,也对其光流效果产生了影响。在软硬件协同的情况下,Red-Black SOR的迭代方法与纯软件下的Red-Black SOR的光流效果的误差主要在硬件模块内部处理使用的定点计算,而软件使用的是浮点计算,会使得结果更为平滑。表4所示的是软硬件协同与软件光流处理的光流效果对比,其中软件效果采用的原始的SOR迭代方法,软硬件协同效果是改进的Red-Black SOR迭代方法。
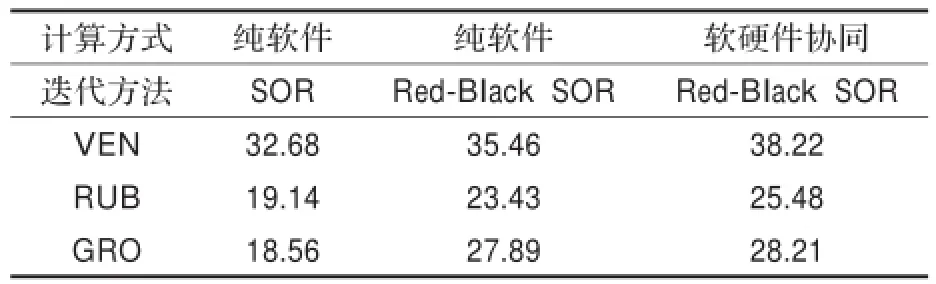
表3 软件与软硬件协同的光流效果AAE的评价

表4 软件与软硬件协同的光流效果的比较
7 结束语
在处理640×480大小的图片时,基于ZYNQ的软硬件协同方式比纯软件方式快34倍左右,执行时间从24.40 s降到了0.71 s,而ZYNQ芯片的片上功率为1.911 W。如果FPGA资源足够,通过迭代展开、减少FPGA与存取器的数据通信量等方式,还可以进一步提高整个系统的性能。
[1]Horn B K P,Schunck B G.Determining optical flow[J]. Artificial Intelligence,1981,17(1/3):185-203.
[2]Barron J L,Fleet D J,Beauchemin S S.Performance of optical flow techniques[J].International Journal of Computer Vision,1994,12(1):43-47.
[3]Baker S,Scharstein D,Lewis J P,et al.A database and evaluation methodology for optical flow[J].International Journal of Computer Vision,2011,92(1):1-31.
[4]Lucas B,Kanade T.An iterative image registration technique with an application in stereo vision[C]//7th International Joint Conference on Artificial Intelligence,Vancouver,Brithish Columbia,1981:674-679.
[5]Bruhn A,Weickert J.Towards ultimate motion estimation:combining highest accuracy with real-time performance[C]// 10th IEEE International Conference on Computer Vision,2005:749-755.
[6]BruhnA.Variationalopticalflowcomputation[D].Saarbrucken:Saarland University,2006.
[7]Mizukami Y,Tadamura K.Optical flow computation on compute unified device architecture[C]//14th International Conference on Image Analysis and Processing(IAIAP),Modena,Italy,2007.
[8]Diaz J,Ros E,Pelayo F,et al.FPGA-based real-time optical-flow system[J].IEEE Transactions on Circuits and Systems for Video Technology,2006,16(2):274-279.
[9]Martin J L,Zuloaga A,Cuadrado C,et al.Hardware implementation of optical flow constraint equation using FPGAs[J].ComputerVisionandImageUnderstanding,2005,98:462-490.
[10]Rustam A,Hamid N H,Hussin F A.FPGA-based hardware implementation of optical flow constraint equation of Horn and Schunck[C]//4th International Conference on Intelligent and Advanced Sytems(ICIAS),2012:790-794.
[11]Gultekin G,Saranli A.An FPGA based high performance optical flow hardware design for computer vision applications[J].MicroprocessorsandMicrosystems,2013,37:270-286.
[12]Chung E S,Milder P A,Hoe J C,et al.Single-chip heterogeneous computing:does the future include custom logic,FPGAs,and GPGPUs[C]//43rd Annual IEEE/ACM International Symposium on Microarchitecture,Atlanta,USA,2010.
[13]原魁,肖晗,何文浩.采用FPGA的机器视觉系统发展现状与趋势[J].计算机工程与应用,2010,46(36):1-6.
[14]Chai Zhilei,Shi Jianbo.Improving KLT in embedded systems by processing oversampling video sequence in realtime[C]//International Conference on Reconfigurable Computing and FPGAs,Cancun,Mexico,2011.
[15]朱学亮,柴志雷,梁久祯,等.KLT织物疵点检测算法研究及FPGA实现[J].计算机工程与应用,2012,48(24):144-148.
WANG Zhibin,YANG Wenmin,ZHANG Yuanpu,CHAI Zhilei
School of Internet of Things,Jiangnan University,Wuxi,Jiangsu 214122,China
Techniques of optical flow computation are widely used in many video/image based applications such as motion detection,motion estimation and video analysis etc.However,high-quality optical flow algorithms are computationally intensive.Slow computation limits the applicability of optical flow computation in real-world applications,especially in embedded systems.In this paper,an implementation of Horn-Schunck optical flow algorithm based on Xilinx ZYNQ is presented.The High-Level Synthesis(HLS)language together with traditional hardware description language is used to describe optical flow accelerator in the software-hardware co-processing mode.Taking resolution 640×480 as instance, the result shows that FPGA-accelerated HS outperforms 34x than the pure software vision on ZYNQ.The execution time is decreased from 24.40 s to 0.71 s.
optical flow accelerator;ZYNQ;high-level synthesis language;software-hardware co-processing;Field-Programmable Gate Array(FPGA)
光流法是计算机视觉中一个基础性的算法,可广泛应用于运动检测、运动估计、视频分析等领域。但光流法最大的问题是计算复杂、速度慢,限制了它在实际系统尤其是嵌入式系统中的应用。利用最新的高层综合(HLS)语言与传统的硬件描述语言相结合,在Xilinx的FPGA异构系统芯片(即ZYNQ)平台上,以软硬件协同的工作方式,设计了基于Horn-Schunck稠密光流法的硬件加速器。实验证明,对于640×480大小的图片,软硬件协同处理比纯软件处理的计算性能提高了34倍,执行时间从24.40 s降低到0.71 s。
光流加速器;ZYNQ;高层综合语言;软硬件协同处理;可编程器件
A
TP391
10.3778/j.issn.1002-8331.1311-0181
WANG Zhibin,YANG Wenmin,ZHANG Yuanpu,et al.Dense optical flow software-hardware co-processing based on ZYNQ.Computer Engineering and Applications,2014,50(18):44-49.
国家自然科学基金(No.60703106,No.61170121,No.61202312)。
王芝斌(1989—),男,硕士研究生,主要研究领域为光流场的实时计算、高层综合语言描述、基于FPGA的机器视觉设计;阳文敏,研究生;张圆蒲,研究生;柴志雷,副教授,硕士生导师。E-mail:zlchai@jiangnan.edu.cn
2013-11-13
2014-01-09
1002-8331(2014)18-0044-06
CNKI网络优先出版:2014-04-01,http://www.cnki.net/kcms/doi/10.3778/j.issn.1002-8331.1311-0181.html
猜你喜欢
导航定位学报(2022年5期)2022-10-13
现代电子技术(2021年1期)2021-01-17
上海大学学报(自然科学版)(2018年5期)2018-11-02
电脑知识与技术(2018年35期)2018-02-27
科技创新与应用(2017年8期)2017-04-26
自动化学报(2017年11期)2017-04-04
软件导刊(2016年12期)2017-01-21
光学精密工程(2016年2期)2016-11-07
中北大学学报(自然科学版)(2014年3期)2014-11-22
现代电子技术(2014年14期)2014-07-24
