
基于Hadoop的数字图书馆云检索系统的设计与实现
2014-07-05 06:43:26潘吴斌
图书馆理论与实践 2014年4期
●张 艳,潘吴斌
(南京信息工程大学 a.图书馆;b.计算机与软件学院,南京 210044)
数字图书馆在经历了互联网时代、Web时代、网格时代、Web2.O时代,己经开始进入云计算时代。云计算是提供海量数据存储和大规模数据处理的分布式并行技术,它作为一种适合图书馆应用的架构模式,可以将分散的数字信息资源整合在一起,实现数字图书馆的集约化,为数字资源的共建共享提供了新的解决办法。基于分布式计算的新型服务计算模式—云计算,完全可以满足数字图书馆建设的需要,将会成为未来数字图书馆发展的新趋势。
1 相关应用
Library TechnologyGuide1 月期中 MarshallBreeding[1]做了2012年图书馆自动化产业的预测,2012将是接下来十年新一轮自动化平台转换的开始。尤其对大学图书馆,将是新一代图书馆自动化平台的转折年。国际上,图书馆界纷纷采用云计算技术来减少成本和提高效率,比如,DuraSpace,Fedora Commons,LOCKSS,Library of Congress等机构都相继给出了数字图书馆的云存储方案,而针对数字图书馆的云检索系统是少之又少。
OCLC(联机计算机图书馆中心)创建的“Web级协作型图书馆管理服务”被公认为是图书馆领域第一个云服务,该服务的目的是降低图书馆费用,促进共同发展和提升用户体验。[2]其中被视作OCLC核心的是书目数据库WorldCat.org,汇集了全球多个国家各种类型文献的书目记录达240638724种,馆藏数量达1755480247条,[3]支持对图书资料、图书馆、列表和联络人等资源的检索,提供多字段检索,并可对年份、用户类型、文献格式等进行限定,提供多种检索结果处理和分析功能,从而实现全世界不同图书馆和机构资源的一站式检索,帮助用户找到最需要的资源。
2 云检索系统
云检索是从云计算延伸和发展起来的,以服务的形式向用户提供信息检索和访问。云计算包括了互联网上各种服务形式的应用以及数据中心提供这些服务的软硬件设施,互联网上的应用服务,即SaaS软件即服务,而数据中心的软硬件设施即所谓的云。从用户的角度来说,云检索就是利用云计算所提供的服务模式,设计一个基于云计算平台的检索系统,在丰富检索资源、优化检索模式和改善检索效果的基础上,获得更优的检索结果。从系统实现来看,云检索是一种服务的交付,它将检索对象分散在大量的对用户透明的节点上,利用海量的计算能力,隐藏具体的实现细节,把检索内容细化为一个个相互独立的云标签,并按相关度聚集在一起,将最终结果通过高速网络呈现给用户。一个典型的云检索系统架构包括一个处理节点和大量的元数据存储节点及文件系统的存储节点。
与传统的检索系统不同的是,云检索系统是经过云计算理念发展而来的,即实现每个细节的虚拟化和共享,把多个个体整合为一个具有强大检索能力的检索系统。比如,各个图书馆的检索系统可以整合成一个巨大的信息检索平台,实现区域或行业整合的图书馆信息检索平台,为用户提供全面、专业的检索服务。
3 图书馆检索平台的现状和需求
3.1 图书馆检索系统面临的问题
图书馆检索系统是图书馆信息化建设的重要部分。传统的图书馆检索系统可以支撑一定的系统应用,但随着图书馆书目总量的迅速增长和对检索系统服务要求的提升,传统的检索系统一般只提供基本的检索服务,用户更高的检索服务体验得不到满足,其中比较突出的问题有以下几方面。(1)数据库问题。图书馆书目信息的种类和数量繁多,由于不同数据库之间往往具有不同的检索系统和使用方式,用户需要应用不同的检索方式,使得图书馆检索系统的使用较为繁琐。(2)检索系统孤立。每个图书馆的检索系统相互独立,使得大部分检索系统中的图书信息冗余和不全面,应尽快开发图书馆统一检索系统。(3)缺乏智能型。用户查找时需要输入准确的检索词才能检索到,容易产生遗漏,多数的检索系统缺少必要的智能检索。(4)安全可靠性差、IT成本高。由于图书馆信息技术部门毕竟不是专业的IT部门,病毒和黑客防护能力一般,数据容易被窃取和毁坏;而且软硬件维护及维护人员的成本相对较高,对于一般图书馆也是一笔不小的开支。
3.2 云检索系统给图书馆带来的好处
图书馆的书目信息越来越大,导致检索系统响应越来越慢,而且由于检索系统缺乏智能型,检索结果不能令人满意。云检索系统提供海量的存储和计算能力,为巨大的书目信息存储和检索所需的计算提供了广阔的空间,为图书馆日趋严峻的信息检索问题找到了解决途径。图书馆应用云检索系统具有如下优势。(1)一站式检索。提供统一便捷的检索方式,进行快速的跨库和跨资源检索,以统一的形式呈现相关度排序的结果;还整合其他服务,包括馆际互借、文献传递等。(2)个性化服务。为读者建立个人账户,允许读者创建自定义的检索清单,为读者提供一定的空间,供其保存检索历史等其他标签信息。(3)网络数据库。引进网络数据库丰富图书馆文献信息的内容和形式,紧密连接各数据库与检索系统,构成一个有机的整体,便捷地进行信息检索。(4)智能检索。使检索系统具有强大的“智能性”,如通过统计借阅和查询记录、检索词的同义转换等。
4 构建图书馆的云检索系统
4.1 图书馆云检索系统架构
构建图书馆的云检索系统,首先要建立一个适合图书馆信息检索的分布式检索架构,根据图书馆信息检索的需求,我们借助技术较为成熟的开源云计算平台 Hadoop,[4]构建一个基于 HDFS、MapReduce、Hive相结合的图书馆云检索架构。Hadoop是开源组织A-pache的一个具有高可靠性和良好扩展性的分布式系统;分布式文件系统HDFS能够高容错、可靠地存储海量数据;MapReduce[5]是一个分布式计算模型,根据检索要求对书目信息进行分布式并行计算;Hive是一个分布式的仓库,用于保存海量的书目信息。图书馆云检索系统一般分为四层,分别为访问层、应用接口层、基础管理层和存储层(如图1所示)。

图1 图书馆云检索系统模型结构
(1)访问层。图书馆用户通过公用应用接口登录图书馆云检索系统,读者享受各种信息检索服务,而各个图书馆向检索系统中加载书目信息。(2)应用接口层。应用接口层是云检索系统最灵活的组件,图书馆的云服务提供商根据实际业务类型提供不同的应用服务,比如图书馆信息检索平台,各种web服务,还提供公共的API供开发者来扩展云检索平台。(3)基础管理层。基础管理层是云存储最核心的组件,基础管理层通过分布式文件系统HDFS、分布式计算模型MapReduce和分布式数据仓库Hive等技术,实现云检索系统中设备之间的协同工作,对外提供统一的服务,并提供强大的信息检索能力。(4)存储层。存储层是系统最基础的组件,可以是NAS和iSCSI等存储设备,云检索系统中的元数据存储设备和文件系统存储设备往往数量庞大且分布在不同地域。存储设备由一个统一的设备管理系统管理,采用分布式文件系统Hadoop实现存储设备的逻辑虚拟化管理,以及硬件设备的状态监控和故障维护等。
4.2 基于Hadoop的图书馆云检索系统具体设计
通过在Hadoop平台上搭建HDFS、MapReduce和Hive系统来实现图书馆的书目信息检索。其中,Hive负责书目信息关键字的存储和统计分析,MapReduce负责处理实际的统计分析计算,HDFS主要负责实际数据的存储,而Hadoop负责设备的虚拟化与管理。基于Hadoop的图书馆云检索系统如图2所示。

图2 基于Hadoop的图书馆云检索系统示意图
图书馆的云检索系统中HDFS架构如图3所示,并对其进行了具体的描述如下。(1)控制节点可以看成HDFS中的管理者,负责管理文件系统的命名空间、集群配置和存储块的复制等。控制节点将文件系统的元数据存储在内存中,元数据主要包括文件信息、文件对应文件块的信息和文件块在数据节点的信息等。(2)数据节点是文件存储的基本组成部分,它将以块文件存储到本地文件系统,保存块文件的元数据,并周期性地将所有存在的块信息发送给控制节点。(3)客户的主要功能是获取分布式文件系统HDFS中的文件。
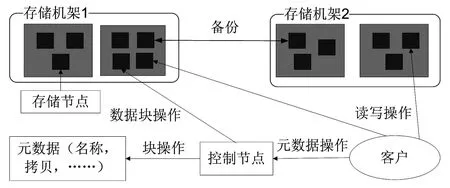
图3 HDFS架构
图书馆的云检索系统中MapReduce架构[6]如图4所示,作业节点全权负责调度作业的运行。任务节点负责具体任务的执行,作业被分成多个切片,任务节点负责对输入切片数据进行映射和规约计算。客户就是向MapReduce提交检索查询的计算作业。HDFS提供存储功能,用于向所有的节点共享作业所需的资源。

图4 MapReduce架构
图书馆的云检索系统中Hive架构[7]如图5所示,并对其功能进行了具体的描述如下。(1)解析器用于分析查询,在不同的查询块和查询表达式上进行语义分析,并最终通过从元数据存储节点中查找表与分区的元数据生成执行计划。(2)元数据存储节点存储数据仓库里所有的各种表与分区的结构化信息,包括列与列类型信息,序列化器与反序列化器,从而能够读写HDFS中的数据。(3)执行器执行由解析器创建的执行计划。此计划是一个关于阶段的有向无环图。执行引擎管理不同阶段的依赖关系,并在合适的系统组件上执行这些阶段。(4)处理节点是接受查询的组件,处理和接受查询命令。(5)客户主要有命令行接口和基于Web的接口访问Hive。
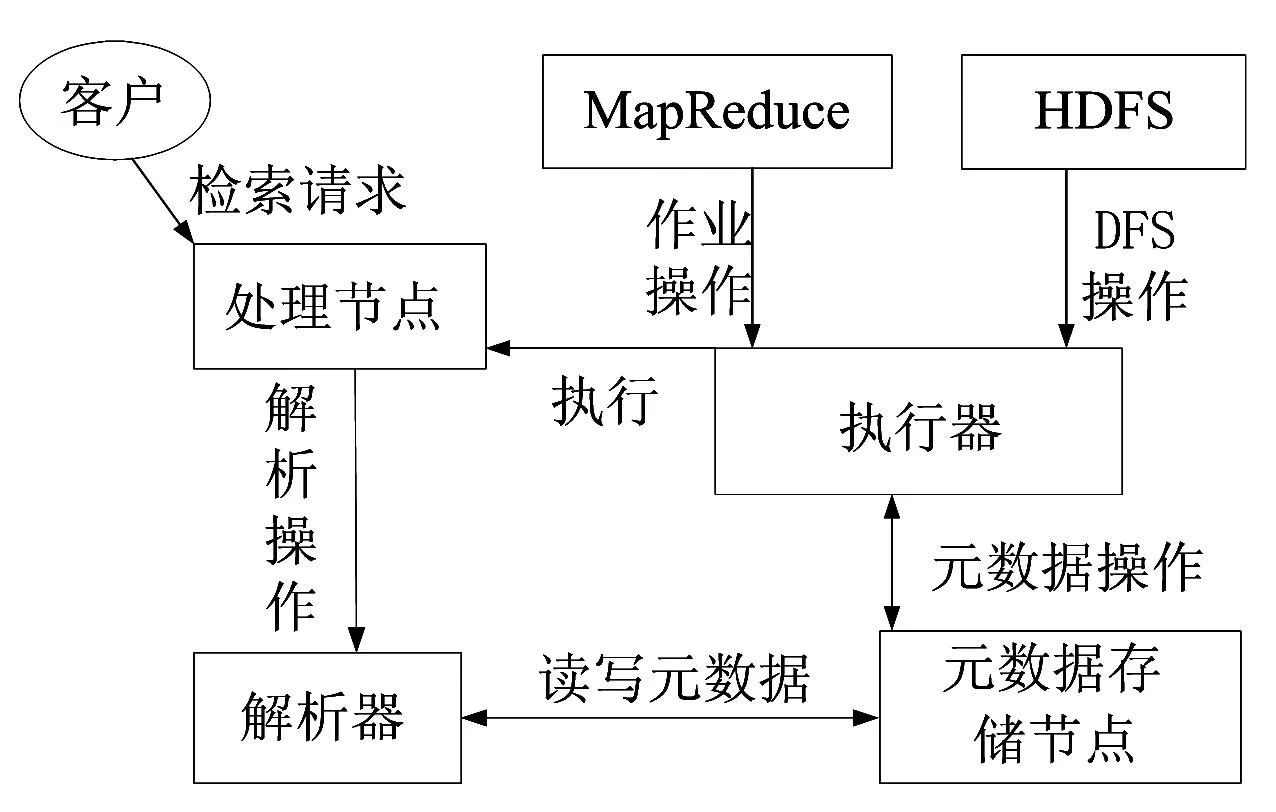
图5 Hive架构
4.3 实验分析
本实验使用9台计算机搭建云环境,实验平台中电脑 CPU为 Intel Core 2.66GHz,内存为 2G,硬盘120G,通过100Mbps交换机局域网连接。实验采用操作系统为CentOS5.4(Red Hat Enterprise Linux 4.1.2)系统,相关软件为Jdk-1.6.0,Hadoop-0.19.2和Hive-0.4.1版本。SQL server 2005安装在Window xp professional,硬件实验平台中电脑CPU为Intel Core 2.66GHz,内存为2G,硬盘240G,虚拟内存设置为2G。数据集1~8分别对应1百万条-8百万条记录。将这些数据集分别在SQL server和不同机器数的Hive平台上执行检索操作。
实验结果表明在8台机器组成的Hive平台和SQL server平台上对数据集8执行检索任务时,Hive的执行时间略微少于SQL server,而且Hive增长趋势明显小于SQL server。选择更大数据量或搭建计算机数更多的平台时,Hive平台的性能将具有更大的优势(见图6)。
通过开源云平台Hadoop搭建图书馆的云检索系统,借助Hadoop的高容错、高可靠、高可扩展等特性,图书馆用户可以放心地将海量的书目信息存储到云平台上,并提供可靠的信息检索服务。Hive用来分析统计海量的书目信息,供用户快速的检索。我们采用HDFS、MapReduce和Hive相结合的方式提供强大的图书信息检索服务,实现图书检索一站式服务、用户个性化服务和智能检索等。

图6
[1] What's In Store for the Library Automation Industry in 2012?[EB/OL].[2012-12-07].http://www.alatechsource.org/blog/2012/01/whats-in-store-for-the-library-automation-industry-in-2012.html.
[2]陆颖隽,等.美国图书馆的云服务[J].图书与情报,2012(3):16-21.
[3]王文清,陈凌.CALIS数字图书馆云服务平台模型[J].大学图书馆学报,2009(4):13-18.
[4] White T.Hadoop:TheDefinitiveGuide:TheDefinitiveGuide[M].O'ReillyMedia,2009.
[5] Jeffrey Dean,Sanjay Ghemawat.Map Reduce Simplified Data Processing on Large Clusters[C].Communications of the ACM, New York, USA, 2008:107-113.
[6] FangWei,PanWubin.Map ReduceProgrammingModel, Methods and Applications[J].IETE Technical Review,2012,29(5):380-387.
[7] Thusoo A,etal.Hive:AWarehousingSolution Over a Map-Reduce Framework [J].Proceedings of the VLDBEndowment,2009,2 (2) :1626-1629.
猜你喜欢
都市人(2022年3期)2022-04-27 00:44:57
信号处理(2018年1期)2018-09-03 07:53:04
信号处理(2018年5期)2018-06-28 02:16:02
信号处理(2018年4期)2018-06-27 03:34:16
信号处理(2018年3期)2018-06-27 03:30:18
新闻传播(2016年18期)2016-07-19 10:12:06
现代计算机(2016年11期)2016-02-28 18:35:15
河南科技(2014年11期)2014-02-27 14:10:19
图书馆界(2013年5期)2013-03-11 18:50:29
中国民间疗法(2012年1期)2012-07-27 09:31:30
