
基于兴趣模型的查询扩展
2014-07-03 08:15田永昌
计算机与现代化 2014年7期
田永昌,李 颖
(1.装甲兵工程学院信息系,北京 100072;2.装甲兵工程学院科研部,北京 100072)
0 引言
当前,绝大多数搜索引擎的搜索结果依据的是用户输入的关键词和网页的权值,并没有考虑不同用户的个性化差异。一种情况是不同用户在输入相同的查询关键词时得到的结果基本相同,没有表现出用户兴趣的差异化;另一种情况是语言存在同义词、近义词以及其他一些复杂语义关系的现象[1],用户提供的关键词往往只是其查询意图的某一种表达形式,这就会导致与其他表达形式相关的网页没有被搜索到,从而降低搜索效率甚至导致搜索失败。这2种情况都不可能令用户满意。所以,信息检索领域的一个关键问题就是怎样使用户从海量的信息中获取对自己有价值的内容,从而提高检索效率。
查询扩展技术作为查询处理和优化的关键技术之一,能有效提高信息检索的效率。查询扩展技术在上个世纪70年代就已经被提出来了[2]。它在初始查询的基础上加入新的查询词,从而能更加准确地把握用户的查询意图,减少查询请求与相关文档不能匹配的现象,提高搜索性能。目前查询扩展技术的方法很多,大致可以归结为3类:基于词典的查询扩展、自动局部分析方法和自动全局分析方法[3-5]。基于词典的查询扩展一般采用WordNet、MindNet和HowNet等词典[6-8],选择与初始查询存在同义、近义或者上下文关系的词进行扩展,例如李力沛等人[9]采用个性化词典,提出了一种改进的基于二级向量的搜索引擎个性化服务模型并通过实验证明了其有效性;自动局部分析是基于初始查询所得到的结果集中的相关文档,利用相关文档的有关信息来扩展查询,例如王旭阳等人[10]提出了一种基于本体和局部上下文分析的查询扩展方法,通过改进筛选函数并结合局部上下文对候选扩展概念集进行2次筛选,在一定程度上提高了查询性能;自动全局分析是对全部文档中的词或词组进行相关分析,计算每对词或词组间的关联程度,根据预先计算的词间相关关系将与查询用词关联程度最高的词或词组加入原查询以生成新的查询,例如王卫国等人[11]提出了一种混合的个性化查询扩展模型,该模型通过潜在语义分析建立潜在语义空间,并在潜在语义空间中计算得到查询的概念相关扩展词和兴趣相关扩展词,较好地提高了检索效率。通过分析这些方法可知:采用词典的查询扩展方法,虽然在一定程度上提高了查全率,但同时也降低了查准率,而且词典大都是人工建立的,不可能包含所有的词条,比较有局限性;自动局部分析方法的一个重要前提是假设前N篇初始检索文档是相关的,但如果这个前提假设不成立,就会造成选取的扩展词与查询意图不相关,从而导致查询结果与主题不相符,降低检索性能;自动全局分析方法的扩展词来源于整个语料库,需要对总的文档集进行训练,而这必然会导致系统开销过大,所以单纯地将自动全局分析方法应用到互联网的海量信息中进行检索的可行性不大。
本文通过从用户的兴趣或者偏好中挖掘出来的兴趣知识建立兴趣知识库,并结合查询扩展策略实现个性化服务,提出一种基于兴趣模型的搜索引擎查询扩展方法。该方法能通过兴趣模型优化查询扩展词,使得用户的搜索更加快速、准确,实现个性化查询扩展。
1 相关工作
1.1 兴趣知识的获取
获取用户的兴趣知识是实现查询个性化的研究基础。通过获取的兴趣知识能够更准确地把握用户的查询意图。用户的兴趣知识来源主要包括以下4个方面[12]:1)用户的浏览信息和查询关键词,这些信息都保存在搜索引擎的用户日志里面;2)用户保存在收藏夹中的网页或者下载到本地的文档信息;3)用户在网页停留的时间以及点击次数,时间越长,点击次数越多,表明用户对该网页越感兴趣;4)用户在与系统进行交互时,提交的个人信息。Agent智能代理[13-14]作为一种软件实体,封装了很多Web挖掘算法。它能在复杂的计算环境中持续自主地挖掘用户的兴趣知识,并对兴趣知识进行保存和更新。用户可以根据实际需要定义Agent信息。本文采用基于A-gent智能代理的数据挖掘模式,实时获取用户兴趣知识,建立兴趣知识库。
1.2 兴趣知识的表示
传统上的查询一般以关键词作为查询扩展的中心,它只是一种符号层面上的机械式扩展,割裂了词语之间的语义关系,这会导致查询扩展词与用户的查询意图不匹配,出现查询偏移的现象,最终降低查询效率。而基于概念的查询扩展,能以初始查询为中心,对查询关键词进行深层次的语义扩展。因此,本文中的关键词都采用HNC理论[15]中的概念符号体系表示。HNC理论是由黄曾阳先生建立的一套相当完备的关于语言概念空间的理论,它用基元化的符号表示自然语言的语义知识,对语义的表达具有概念化、层次化和网络化的特性。HNC概念表述体系简单概括起来就是把概念分为抽象概念和具体概念,对抽象概念用五元组和语义网络来表达,对具体概念采取挂靠展开近似表达,因此概念越相近,其概念表示式就越相似。例如下面几组HNC符号:

HNC概念符号虽然只是一种词语语义的表达方式,但它可以将词语的文字符号有效地映射到概念基元符号上。它蕴含着概念联想的丰富知识,使得建立在概念基元上的相关运算更加方便。
1.3 兴趣模型的建立
在获取用户兴趣知识和用HNC概念符号表示这些兴趣知识后,就要对用户的兴趣建立一个模型。对于一个任意给定的文档,都可以看作是由若干个特征项组成的一个集合,这些特征项包括字、词以及短语等。所以,本文对用户的兴趣知识和历史查询都采用向量空间模型进行表示。向量空间模型一般都会选择文本的关键词作为特征项,但是本文采用关键词对应的HNC概念符号作为特征项,这样可以将文本从关键词层面提升到语义空间层面,在一定程度上可以提高识别用户查询意图的能力。
假设用户兴趣知识向量有n个关键词,每个关键词和其对应的权重作为一个二元组,这n个二元组就构成了用户的兴趣向量,所以用户的兴趣向量可以形式化表示为:
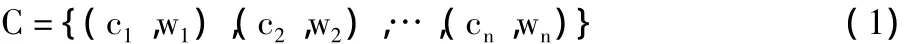
其中,特征项 ci(1≤i≤n)表示兴趣知识关键词,用HNC概念符号表示,wi为ci对应的权重值。例如:

一个用户历史查询向量的表达式为:
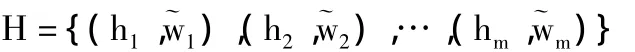
其中,特征项hj(1≤j≤m)为历史查询的关键词,也用HNC概念符号表示,˜wj是hj对应的权重值。
2 基于兴趣模型的查询扩展
一般情况下,用户感兴趣的信息都包含在用户的历史搜索信息中,这些历史搜索信息包括用户的兴趣知识和历史查询。所以,本文的查询扩展的数据都来源于这些历史搜索信息。系统根据需要,从用户兴趣模型库中调用这些历史搜索信息来指导用户查询,并重新调整用户查询的表达式,从而对用户的查询请求进行优化扩展。
假设用户在系统中输入了一个查询,经过预处理之后,得到初始查询表达式Q,即一个关键词序列q1,q2,...,qn(n为查询概念的个数)。则将一个关键词qn'(1≤n'≤n)和兴趣向量C的相关度作为该查询关键词的权重,表示如下:

式(2)中,wi表示兴趣向量中第i个兴趣知识关键词对应的权重,sim(qn',Ci)表示当前查询关键词qn'和兴趣向量中第 i个关键词Ci的概念相似度,HNC提供了概念相似度计算方法[16],这里不再赘述。
初始查询Q的向量表达式为:
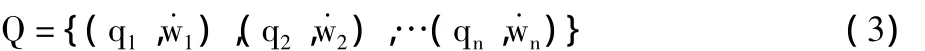
当前查询Q和一个历史查询H的相似度表示为:
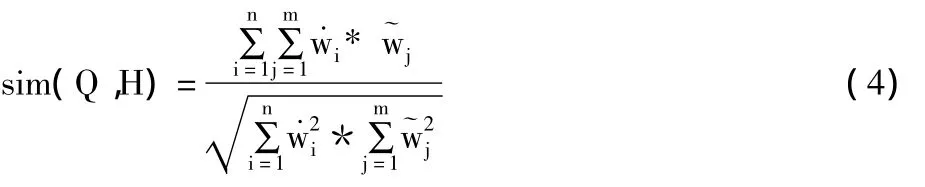
假设,在历史查询的记录中,与当前查询Q的关键词有相同概念表达式的查询记录有n个,其中,第k个查询记录对应的浏览文档有rk条,则可计算出用户对第k个查询记录的关注度为:

从式(5)不难看出,当某一历史查询中包含浏览文档的记录数目越多,用户对这个查询记录的关注度越高,也就是说用户对其更感兴趣。
假设,在历史查询的记录中,与当前查询Q的关键词有相同概念表达式的历史查询记录有n个,第k个历史查询记录H与当前查询Q的相似度为sim(Q,H)k,且用户对第k个查询记录的关注度为Ak,那么第k个历史查询记录的用户兴趣度可表示为:
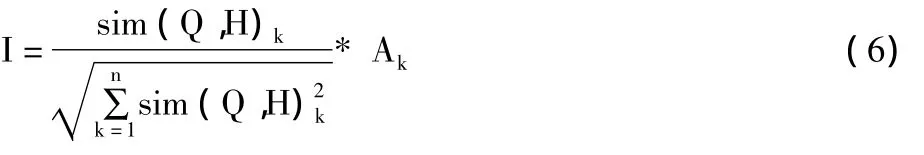
3 查询扩展工作流程
根据用户兴趣模型来调整用户查询的表达式,实现查询扩展的工作流程如图1所示。

图1 查询扩展的工作流程图
查询扩展的主要步骤如下:
1)系统获得用户的查询输入以后,对其进行预处理,主要是分词和概念识别,得到初始查询概念序列表达式;
2)根据式(2)计算初始查询概念序列的每个关键词qi与兴趣向量C的概念相关度˙w,作为关键词qi的权重值,根据公式(3)得到初始化的查询向量Q;
3)根据式(4)计算当前查询Q与历史查询H的相似度sim(Q,H);
4)根据式(5)计算与当前查询Q有相同概念表达式的历史查询记录的关注度;
5)在步骤3)和步骤4)的基础上,根据式(6)计算用户对相关历史查询记录H的兴趣度I;
6)对用户兴趣度I进行判断,如果大于阈值,则从相关历史查询记录Q'的关键词中选出k个最大的作为查询扩展词;如果小于阈值,说明当前查询是一个新查询,此时查询不能实现扩展。
4 实验结果及分析
为了衡量搜索引擎查询性能,实验使用与原查询最相关的前100篇文档作为查询扩展的基础,并选择前10个与原查询兴趣度最高的词加入到原查询中形成新的查询,然后对前100篇返回文档进行人工分析,并以查全率和查准率作为主要性能指标,在查全率为10%到100%这10个区间内分别比较查准率的变化情况,并将本文的查询扩展方法与基于关键词的查询扩展方法相比较,统计结果如表1所示。
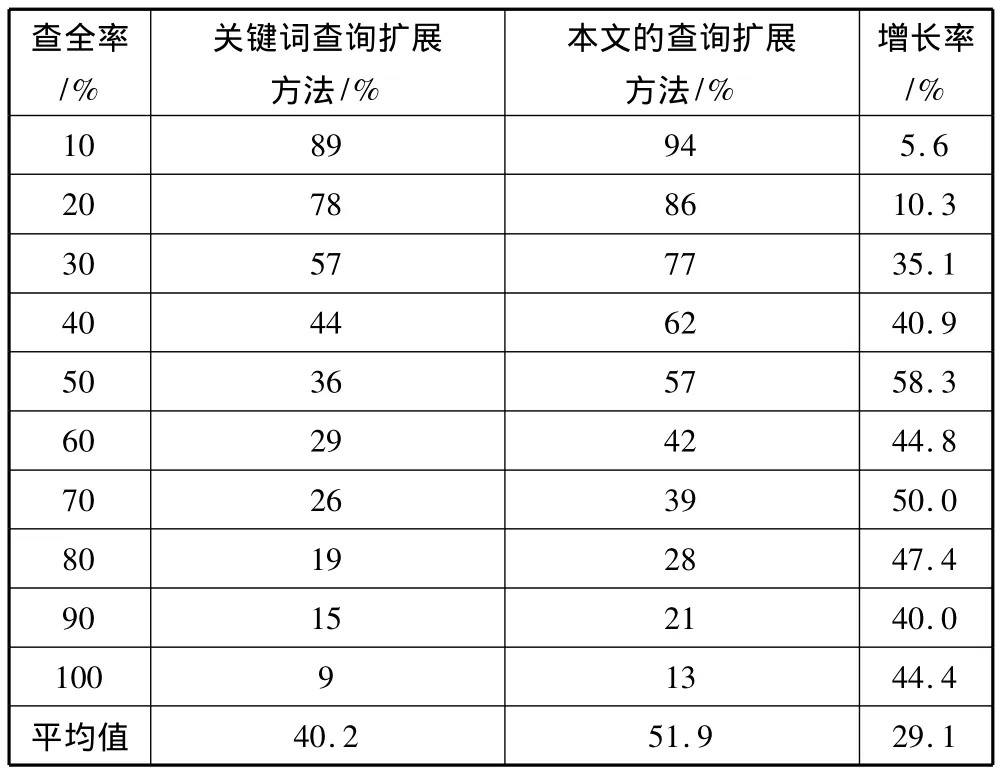
表1 查询性能比较
通过表1可得到本文的查询扩展方法的平均查准率为51.9%,查询性能相对于基于关键词的查询扩展的原查询提升了29.1%,效果明显。
另外,实验中还发现,并不是查询扩展词越多,查询性能就越好。不同扩展词个数对查准率的影响如图2所示。
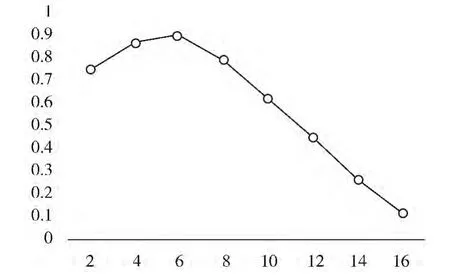
图2 不同扩展词个数对查准率的影响
当初始查询加入6个扩展词时查询的性能最好,超过6个扩展词后性能下降明显,这是由于权重低的扩展词不但不能起到优化查询的作用,反而会加入噪声从而产生查询歧义,造成“查询漂移”,所以查询扩展词不是越多越好。
5 结束语
本文在用户兴趣知识库的基础上,提出了一种基于兴趣模型的查询扩展方法,并对查询扩展的工作流程作了比较详细的叙述。实验表明,这种基于兴趣模型的查询扩展方法能够有效地辅助用户利用搜索引擎搜索到自己感兴趣的信息,在一定程度上弥补了用户查询信息不足的缺陷。由于本文的方法依赖用户浏览结果文档的数目,所以并没有考虑浏览记录是否含有不符合用户需求的噪声结果数据,考虑在下一步工作中加入权值的影响因素,从而进一步改善整个搜索模型的性能。
[1] 胡泽文,王效岳,白如江.基于SUMO和WordNet本体集成的文本分类模型研究[J].现代图书情报技术,2011(1):31-38.
[2] 马云龙,林原,林鸿飞.基于权重标准化SimRank方法的查询扩展技术研究[J].中文信息学报,2011,25(1):28-34.
[3] 董守斌,袁华.网络信息检索[M].西安:西安电子科技大学出版社,2010:129-139.
[4] 刘畅.基于用户兴趣及本体术语关系的查询扩展[D].保定:河北大学,2013.
[5] 黄名选,严小卫,张师超.查询扩展技术进展与展望[J].计算机应用与软件,2007,24(11):1-4.
[6] 李海芳,史俊冰,段利国,等.一种基于含糊同义词的查询扩展方法[J].计算机应用与软件,2011,28(12):41-43.
[7] 王磊.基于概念语义空间的语义查询扩展技术研究[D].洛阳:河南科技大学,2012.
[8] 王水利,黄广君,霍亚格.基于语义分析的查询扩展方法[J].计算机工程,2011,37(16):77-79.
[9] 李力沛,罗颖.基于个性化词典的搜索引擎查询扩展模型[J].电脑知识与技术,2012,8(28):6764-6770.
[10] 王旭阳,萧波.基于本体和局部上下文分析的查询扩展方法[J].计算机工程,2012,38(7):57-59.
[11] 王卫国,徐炜民.基于潜在语义分析的个性化查询扩展模型[J].计算机工程,2010,36(21):43-45.
[12] 张璇.油田信息搜索引擎个性化排序方法研究[D].大庆:东北石油大学,2013.
[13] 李春杰,崔红霞.基于多Agent搜索行为分析的用户兴趣模型[J].吉林大学学报(信息科学版),2010,28(2):182-185.
[14] 梁美玉,杜军平,高田.基于领域知识的个性化智能语义检索系统[J].中南大学学报(自然科学版),2011,42(z1):865-869.
[15] 黄曾阳.HNC(概念层次网络)理论[M].北京:清华大学出版社,1998.
[16] 晋耀红.HNC(概念层次网络)语言理解技术及其应用[M].北京:科学出版社,2006.
猜你喜欢
客联(2022年3期)2022-05-31
新高考·高一数学(2022年3期)2022-04-28
中国新闻周刊(2021年26期)2021-07-27
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
开放教育研究(2020年2期)2020-03-31
信息安全研究(2016年4期)2016-12-01
现代语文(2016年21期)2016-05-25
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
