
一种基于最优路径搜索的图像分类方法
2014-07-02 00:30陈洁萍
电视技术 2014年23期
陈洁萍,甘 泉,张 慧
(1.广西职业技术学院计算机与电子信息工程技术系,广西南宁530226; 2.平顶山学院计算机科学与技术学院,河南平顶山467002;3.清华大学软件学院,北京100083)
一种基于最优路径搜索的图像分类方法
陈洁萍1,甘 泉2,张 慧3
(1.广西职业技术学院计算机与电子信息工程技术系,广西南宁530226; 2.平顶山学院计算机科学与技术学院,河南平顶山467002;3.清华大学软件学院,北京100083)
目前已经有多种基于树的算法来解决多类别图像分类问题,然而由于选择的学习和贪婪预测策略不当,这些算法在分类精度和测试时间效率间不能实现很好的均衡。提出一种新的分类器,当树形架构已知时能在效率和精度间实现很好的折中。首先,将图像分类问题转化为树结构中最优路径的搜索问题,提出新的类似于分支界定的算法来实现最优路径的高效搜索。其次,使用结构化支持向量机(SSVM)在多种边界约束下联合训练分类器。仿真实验结果表明,相对于当前最新“基于树”的贪婪算法,当应用于Caltech-256、SUN和ImageNet1K等数据集时,该算法在效率较高时的精度分别上升了4.65%,5.43%和4.07%。
图像分类;分支界定;最优路径;贪婪算法;效率;精度
1 算法简介
大规模视觉分类是计算机视觉的核心问题。随着ImageNet[1]和SUN数据集[2]等大规模数据集的采集工作不断推进,研究人员正努力研究可以处理大量类别的新算法。其中,基于树的算法[3-4]由于分类精度较高得到了广泛关注。这些算法将大量图像类别组织为树形结构。在每个内部节点,分类器将类别分为低层节点的较小子集。图1为图像分类器工作过程示例(原图为彩色图片)。其中,图1a给出了树形结构的示例,其中数字表示对象类别;图1b给出了贪婪算法给出错误预测的一个示例(带有“x”标记的节点),此时该算法在高层次上发生错误。本文BB类似算法给出正确预测(带有笑脸的节点),且没有评估整个树(绿盘中的节点被修剪)。红色节点和边缘表示已经被评估过。图1c阐述了基于树模型的内部节点和叶节点标记法。图1d给出了分段(红色边缘)、路径(从根到叶的绿线)和分支(路径集合)的定义。
为了提高测试时间效率,从结构最顶层到最底层运行分类器使用贪婪预测算法来逐渐降低类别数量。因此,算法在测试期间获得了预期中的“准线性复杂度”(相对于类别数量)。
另外,这些算法采取的主要方法是学习树形架构及对应的分类器集合,在分类精度和测试时间效率间只能实现次优平衡效果,这主要是因为:1)采用的预测算法只利用了树形架构中的一条路径;根据使用的分类器次序,贪婪选择路径(见图1b左)。这表明结构中更高层次生成的误差无法在以后纠正;2)大多数基于树的算法没有联合学习所有分类器,而是从最顶层到最底层一次学习一个分类器,使用对应于类别子集的图像数量也变少。因此,底层分类器训练时使用的数据要少于高层训练时。本文提出一种高效准确的图像层次分类器,当树形结构已知时在精度和效率间实现更好的均衡。本文的主要贡献如下:
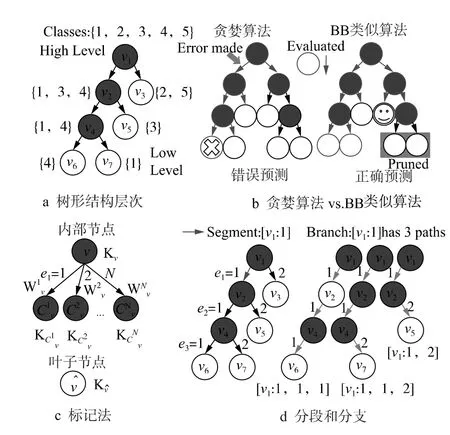
图1 图像分类器工作过程示例(截图)
1)将图像分类问题建模为树结构中的最优路径搜索问题,提出一种类似于分支界定的搜索方法,在既不利用整个树也不贪婪修剪类别的情况下实现最优路径的高效搜索(见图1b右)。
2)使用拓展SSVM在更多的边界约束下对边界和模型参数展开联合学习,使得可以在精度和效率间实现更好折中。
3)本文方法的最优精度优于一对多算法的精度;本文方法在精度和效率间的平衡效果要优于当前最新的基于树的贪婪算法。更重要的是,当使用Caltech-256、SUN和ImageNet1K数据集时,与文献[4]算法相比,本文方法在效率较高时的精度分别提升了4.65%,5.43%和4.07%。
2 相关工作
图像分类问题是计算机视觉领域的研究热点问题之一,相继有众多研究者提出了一系列有代表性的方法,陈荣等[5]提出了一种新的图像分类方法。通过基于最优标号和次优标号的主动学习去挖掘那些对当前分类器模型最有价值的样本进行人工标注,并借助CST半监督学习进一步利用样本集中大量的未标注样本,使得在花费较不标注代价的情况下,能够获得良好的分类性能。张淳杰等[6]综合考虑局部特征之间的上下文信息,提出一种基于有判别力仿射局部特征上下文的图像分类方法。对于一幅图像上的某一位置,采用该区域的局部特征,及其周边一定距离、角度内的局部特征来进行描述;然后对这些局部特征上下文进行仿射变换,并通过最小化编码损失的策略来进行有判别力的仿射局部特征上下文的选择,得到更有判别力的特征。最后通过实验结果验证了该方法的有效性。徐杰等[7]提出一种基于超边相关性的图像分类方法,有效地将图像相关的标注信息作为判定图像类别的指标引入到图像分类中,进而对图像进行更准确的分类。在LabelMe和UIUC数据集上的实验验证该方法的有效性。
另外,文献[8-9]提出基于一对多策略的算法和基于一对一策略的图像分类算法,这些算法的分类精度往往较高。然而,评估分类器性能的时间复杂度与类别数量呈“线性”关系。文献[10-11]通过利用类别的分层结构来降低时间复杂度,提出了不同的方法来自动构建图像类别结构。其中,大多数方法均依赖贪婪算法来利用结构中的一条路径进行类别预测并分别在结构中的每个节点上训练分类器。因此,往往是牺牲精度来实现“准线性”时间复杂性。鉴于此,本文将图像分类问题转化为树结构中最优路径的搜索问题,提出了一种新的类似于分支界定的算法来实现最优路径的高效搜索,最后通过仿真实验验证了本文算法的有效性。
3 本文模型
本文的目标是设计一种图像结构分类器,更好地在精度和效率间实现平衡。在本节中,首先定义了“基于树”的模型,然后给出如何将模型转换为“最优路径模型”。
3.1 基于树的模型

模型已知后,往往使用贪婪算法来预测输入x∈RD的类别。算法从根节点开始探索树的单条路径直到叶节点,具体过程如下:从根节点开始(索引v=1),选择与最大分类器得分相对应的边缘e(即e=argmaxj(x)),然后算法推进至子节点。对所访问的所有子节点重复相同的选择步骤,直到到达叶节点。因此,可以使用开始节点v=1串联上被选边缘 [e1,e2,…,eL]来表示预测路径P(即P=[v;e1,e2,…,eL]),其中L是路径的长度。显然,算法具有准线性复杂度,因为在最优情况下,L=log K。
另外,大多数基于树的方法不是联合学习所有分类器,而是从最顶层到最下层缓慢地一次学习一个分类器,使用与类别子集相对应的图像也较少。因此,低层分类器训练时用到的数据集低于高层训练。为了解决上述两个问题,大多数基于树的算法[3-4]通过学习类别结构,以便:1)避免贪婪算法出错;2)通过约束结构的深度来避免用较少数据训练分类器。本文方法的重点不是学习结构,而是在结构已知时解决这两个问题,同时保证图像分类预测的效率。
3.2 最优路径模型

式中:P1是树中从根节点υ=1开始到达叶节点的所有路径的集合。最优路径模型可以看成是一对多支持向量机的特殊情况,因为沿着每条路径的分类器参数的累积和可以看成是一对多支持向量机中一个类别的所有分类器参数。关键差别在于,树结构要求2条路径的参数根据路径的重叠情况部分共享。换句话说,本文模型利用结构知识在类别间共享参数,以便结构中距离更近的类别有更为相似的参数,这一属性有助于提升相对一对多支持向量机的精度。
4 分支界定预测算法
本节提出了一种新的类似于分支界定的算法来实现最优路径的高效搜索。该算法不是搜索树中的所有路径,而是只搜索树中的部分路径,且一般情况下可以在“准线性”时间内结束。算法的伪代码描述如下:
算法1:高效的分支界定预测
要求:输入x∈RD,树T,得分函数S,各节点的上界{Uυ}υ。
目的:见式(1)。
1)将Q初始化为空优先级队列;
5)for e=1:N do;
9)end for;
进行常规健康教育,健康教育6 个月后,对病人集体进行1次 60 min的骨质疏松预防知识讲解,同时为每例病人免费提供1本 2 型糖尿病病人骨质疏松预防小册。
12)设置P*=[]。
4.1 分支界定类似搜索(BB)
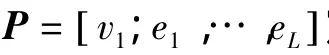
对每个分支,计算分支中路径对于输入x能够取得的最大得分的上限(x)。在搜索开始时,从与整个树p1=[1;)的路径集合相应对的分支开始(见算法1的第2行)。然后,将工作分支不断分割为N个子分支见算法1的第4行),然后更新(x)的上限(算法1的第7行)。[[v;e1,…,eF)e)=[v;e1,…,eF,e)表示串联。BB算法按照最佳优先策略对候选分支组织搜索。因此,工作分支始终对应于上限最大的一个(见算法1第10行)。当已经找到由单个路径构成的分支(即==1),且分值至少与所有剩余候选分支的上界相等(见算法1第11行)。最佳优先策略可以保证寻找到最优路径。算法的效率主要取决于边界的紧凑度。在本文实验中,本文高效预测算法的速度要远快于最差情况下的复杂度。
4.2 边界计算
假设每个节点υ缓存分支Pυ中从节点υ开始到达叶节点的路径的上界Uυ。因此,分支[1;e1,…,eF)的上界(x)等于分段 [1;e1,…,eF]累积得分(x)及分段[1;e1,…,eF]最后一个节点缓存的上界Uυ之和(见算法1第7行)。

每个节点缓存的最紧凑上界是与输入有关的Uυ(x),当已知输入x时通过评估树中的所有分类器可以确定最紧凑上界。然而,确定边界的成本与最优路径蛮力搜索算法的成本相同。此外,对每个输入均需计算一次。另一方面,提出利用训练输入X来估计与输入无关的上界Uυ,且模型训练后上界只需估计一次。请注意,Uυ边界未必一定合理,因为Uυ可能小于未知测试输入x∧的上界Uυ(x∧)。然而,笔者发现在实践中估计的可靠性较高,因为分类精度一般没有被牺牲,如图2所示(其中,节点表示没有边界下降率约束条件下且松驰度(ρ)不同时进行训练获得的模型)。于是,将其称为分支界定类似算法。

图2 分支界定类似算法对Caltech-256数据集的有效性
虽然BB算法在找到了最优路径时才会终止,但是有更多信息存储于可对评估过的分支进行分级的队列Q中(算法1)。分级可以保存丰富的预测结果集合,而且这一集合既包括共享类似路径段的分支(比如猫和狗),也包括路径段非常不同的分支(比如工具和动物),这一特点可用于人机交互。例如,用户更希望看到一组多样化预测,然后选择最合适的一个,而不是看到一组互相类似但可能所有都不适用的预测。
5 结构化SVM学习
可以使用结构化SVM(SSVM)来学习得分函数,并采用结构化输出P对树形结构中的路径进行编码。考虑到有一组训练输入及树的真实路径{xm,Pm}m=1~M,求解如下SSVM问题
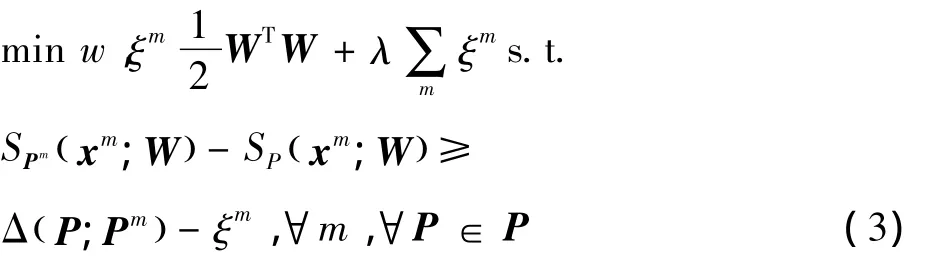
式中:W={Wυ}υ∈v是边缘模型参数的向量串联而成,Δ(P;Pm)是衡量估计路径P误差度的损耗函数,λ控制扰乱项之和(∑mξm)相对正则化项(WTW)的权重。在本文部署中,使用简单的0-1损失(即当P≠Pm时Δ(P;Pm)=0,否则Δ(P;Pm)=1)。使用文献[13]的双坐标下降求解方法来解决上述问题,以实现快速收敛并减少内存使用。
通过避免学习模型参数然后估计各节点的上界U={Uυ}υ,可以把式(3)的SSVM问题进行拓展,以联合学习模型参数W和各节点的上界U

式中:γ是边界Uυ的减少率;合理边界是以v为起点的路径∈Pυ的得分(xm;W)必须小于各节点的上界Uυ;减少率是指子节点的上界的γ倍应该小于母节点的边界Uυ。
与求解式(3)类似,只添加了式(1)和式(2)中的扰乱约束,并用文献[14]中的双坐标下降求解方法求解式(4)。在图3中,证明通过更改γ数值,可以调整精度和效率间的平衡。
6 实验
本文基于3个公开数据集(Caltech-256,SUN-397和ImageNet1K)来评估本文算法性能。目标是:1)验证本文方法的精度高于一对多算法;2)与当前最新基于树的算法[4]相比,更好地实现精度和效率间的平衡。

图3 针对Caltech-256数据集,在γ={1(无下降率约束),2,3}且ρ=0.8的学习边界条件下,相对复杂度和精度间的平衡结果
6.1 基本设置
对于精度,采用文献[4]的方法,给出每个类别的精度均值。对于效率测试,因为树模型中每个节点是线性分类器且复杂度相同,所以总体测试效率取决于分类器评估的次数。计算每个实例的分类器评估次数均值,并给出“相对复杂度”(即用一对多算法分类器评估次数进行正规化后的均值)。将本文算法与当前最新基于树算法[4]和一对多SVM算法做比较。所有算法使用相同的SVM部署和局部限制线性编码特征(LLC)。利用训练集4重交叉验证来选择每种方法的参数λ(式(4))。为了训练树形结构,使用文献[4]公布的代码,并允许树最多有8层结构。已知树形结构后,使用第5节的SSVM来训练模型,以更好实现精度和效率的平衡。用MATLAB进行SSVM训练时,Caltech和Sun数据集需要2 h左右,ImageNet数据集需要6 h左右。
6.2 Caltech-256
Caltech-256数据集包括256个对象类别。对每个对象类别,与文献[4]类似,随机提取40个图像作为训练数据,40个图像作为测试数据。使用带有21K维度的LLC特征来重现文献[4]给出的一对多精度。与松弛度ρ={0.5,0.6,0.7,0.8,0.9}相对应的5种结构接受训练以便进行比较。
首先证明了分支界定类似算法在已知模型训练没有使用边界约束(式(3))条件下,没有过多损失精度(见图2)的同时实现效率提升。然而,如果没有强迫结构中的边界按照一定速率下降,则实现的效率提升非常有限。在图3中,证明了通过利用与γ={1,2,3}且ρ= 0.8相对应的约束来训练本文模型,可以实现不同的精度和效率平衡效果(式(4))。下面进一步尝试不同的ρ (松驰度)和γ(边界紧凑度)组合,并选择对于验证集合可以实现最优精度和效率平衡效果的模型(1/4的训练图像用于模型选择)。图4给出了测试集的效率和精度性能。可以看到,本文方法以更低的复杂度实现了更高的精度。以9%左右的相对复杂度,实现了4.65%(相对值24.82%)的显著性能提升。本文的最优精度(35.44%)优于一对多算法(34.78%)。另外,图5表明了第1分级到第5分级的预测精度提升了10%,而复杂度只有准线性上升。
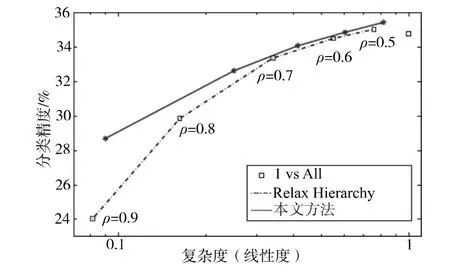
图4 针对Caltech-256数据集,本文方法、松弛结构[4]和一对多SVM算法的精度和相对复杂度平衡结果
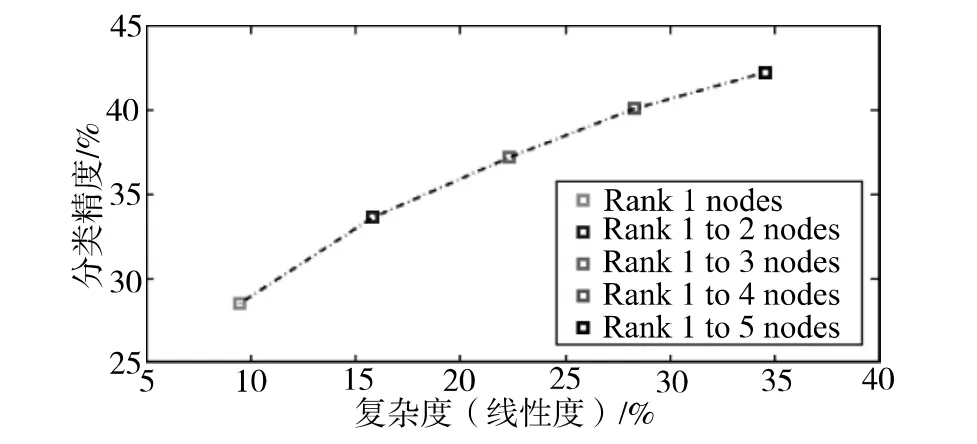
图5 针对Caltech-256数据集使用ρ=0.9模型时,分类精度相对第1分级至第5分级预测相对复杂度的变化情况
6.3 Sun-397
基于SUN数据集来评估场景分类任务的性能。与文献[2]的设置类似,使用397个经过适当采样的类别来评估本文算法。对每一种类别,随机采样50个图像作为训练数据,另外50个图像作为测试数据。使用具有16K维度的LLC特征,以重建文献[15]给出的一对多精度。与松弛度ρ= {0.6,0.7,0.8,0.9,1.0}相对应的5处结构接受训练以便进行比较。本文算法的精度为25.69%,优于一对多SVM的24.08%,且精度和效率平衡效果优于文献[4],如图6所示。与Caltech 256数据集类似,本文算法的复杂度更低,但精度更高。本文算法的复杂度相对只有5%,但是其精度实现了5.43% (相对值41.64%)的显著提升。
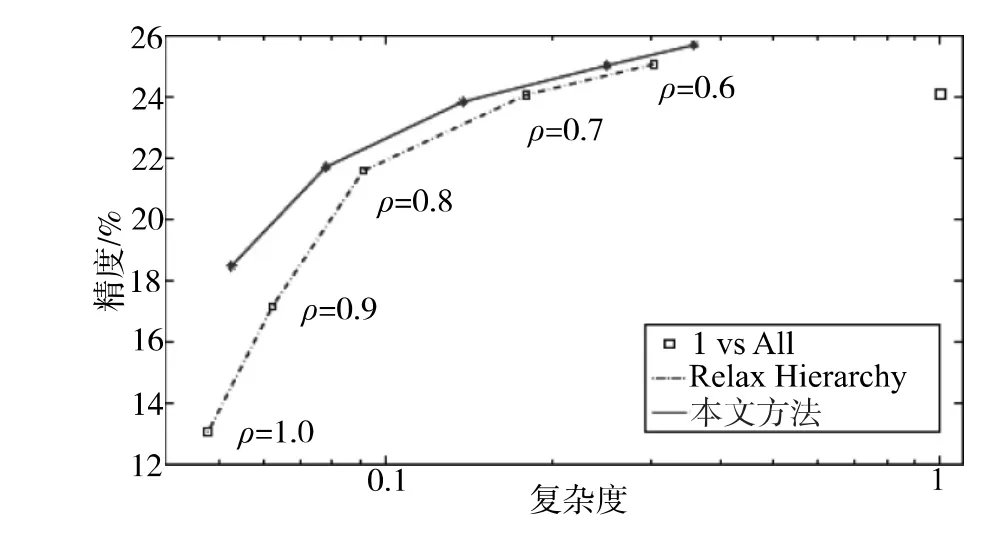
图6 针对Sun-397数据集,本文方法、松弛结构[4]算法和一对多SVM算法的精度和相对复杂度平衡结果
6.4 ImageNet数据集
该数据集包括1K对象类别和120万个图像。使用与文献[15]相同的训练和测试图像分配方法。使用带有10K维度的LLC特征来重建文献[8]给出的一对多基准精度。与松弛度ρ={0.9,0.75,0.6,0.45}相对应的4处结构接受训练以便进行比较。已知树形结构后,基于SSVM训练本文模型(第5节)。本文算法的精度为22.99%,优于一对多SVM的21.2%,且精度和效率平衡效果优于文献[4],如图7所示。与Caltech 256数据集类似,本文算法的复杂度更低,但精度更高。本文算法的复杂度相对只有5%,但是其精度实现了4.07% (相对值109.79%)的显著提升。此外,在边界约束条件下学习而得的模型,其性能要优于未在边界约束下学习而得的模型性能。

图7 针对ImageNet数据集,带有边界约束的本文方法、不带有边界约束的本文方法、松弛结构[4]算法和一对多SVM算法的精度和相对复杂度平衡结果
7 结论
本文提出一种图像结构快速准确分类算法,在精度和效率间实现更好的平衡。本文贡献如下:1)提出一种基于树结构的新的高效预测BB类似算法;2)提出经过拓展的SSVM,使得可以在精度和效率间实现更好的平衡。利用Caltech-256、SUN和ImageNet1K数据集进行仿真,证明了本文方法的精度优于一对多算法,且相对文献[4]当前最新的基于树的算法,可以实现更好的精度和效率平衡。更重要的是,与文献[15]算法相比,本文算法的复杂度更低,且对3种数据集分别实现了4.65%,5.43%,4.07%(相对值 24.82%,41.64%,109.79%)的性能提升。在下一步工作中,将研究基于本文算法多样性输出(比如类别预测等级)的人机交互应用问题。
[1]DENG J,DONGW,SOCHER R,et al.ImageNet:A large-scale hierarchical image database[EB/OL].[2014-05-15].http:// www.researchgate.net/publication/221361415_ImageNet_A_largescale_hierarchical_image_database.
[2]XIAO J,HAYSJ,EHINGER K,et al.Sun database:Large-scale scene recognition from abbey to zoo[EB/OL].[2014-05-15].http:// www.researchgate.net/publication/221362554_SUN_database_Largescale_scene_recognition_from_abbey_to_zoo.
[3] BENGIO S,WESTON J,GRANGIER D.Label embedding trees for largemulti-class tasks[EB/OL].[2014-05-15].http:// www.researchgate.net/publication/221618910_Label_Embedding_ Trees_for_Large_Multi-Class_Tasks?ev=auth_pub.
[4] GAO T,KOLLER D.Discriminative learning of relaxed hierarchy for large-scale visual recognition[EB/OL].[2014-05-15].http:// www.sciweavers.org/publications/discriminative-learning-relaxedhierarchy-large-scale-visual-recognition.
[5]陈荣,曹永锋,孙洪.基于主动学习和半监督学习的多类图像分类[J].自动化学报,2011,37(8):3601-3605.
[6]张淳杰,熊威,张一帆,等.融合有判别力仿射局部特征上下文的图像分类[J].计算机辅助设计与图形学学报,2014,26(5):762-766.
[7]徐杰,景丽萍,于剑.基于超边相关性的图像分类方法[J].模式识别与人工智能,2014,27(2):120-126.
[8]LIL.Multiclass boosting with repartitioning[EB/OL].[2014-05-15]. http://www.researchgate.net/publication/221345684_Multiclass_boosting_ with_repartitioning.
[9]ALLWEIN E L,SCHAPIRE R E,SINGER Y.Reducing multiclass to binary:a unifying approach formargin classifiers[J].J.Mach.Learn. Res.,2011,2(1):113-141.
[10]BEYGELZIMER A,LANGFORD J,LIFSHITS Y,et al.Conditional probability tree estimation analysis and algorithms[EB/OL].[2014-05-15].http://www.researchgate.net/publication/24166858_Conditional_Probability_Tree_Estimation_Analysis_and_Algorithms.
[11]BEYGELZIMER A,LANGFORD J,RAVIKUMAR P.Error-correcting tournaments[EB/OL].[2014-05-15].http://www.researchgate.net/ publication/24013513_Error-Correcting_Tournaments.
[12]LAND A H,DOIG A G.An automaticmethod for solving discrete programming problems[M].[S.l.]:Springer Berlin Heidelberg,2010: 105-132.
[13] YANG Y,RAMANAN D.Articulated pose estimation with flexible mixtures of parts[EB/OL].[2014-05 -15].http:// www.ics.uci.edu/~dramanan/software/pose/.
[14] DENG J,BERG A,LI K,et al.What does classifying more than 10,000 image categories tell us?[EB/OL].[2014-05-15].http://www.docin.com/p-388937151.html.
[15]KRIZHEVSKY A,SUTSKEVER I,HINTON G E.Imagenet classification with deep convolutional neural networks[EB/OL].[2014-05-15].http://papers.nips.cc/paper/4824-imagenet-classificationwith-deep-convolutional-neural-networks.
Image Classification Algorithm Based on Optimal Path Search
CHEN Jieping1,GAN Quan2,ZHANG Hui3
(1.Department of Computer and Electronic Information Engineering,Guangxi Vocational and Technical College,Nanning 530226,China; 2.College of Computer Science and Technology,Pingdingshan University,Henan Pingdingshan 467002,China; 3.School of Software,Tsinghua University,Beijing 100083,China)
Many algorithms based on tree are proposed to solve the image classification problem for a large number of categories.Due to learning and greedy prediction strategy choice ofundeserved,methods based on tree-based representations cannotachieve good trade-off between accuracy and test time efficiency.In this paper,a classifier is proposed which achievesa better trade-offbetween efficiency and accuracywith a given tree-shaped hierarchy.Firstly,the image classification problem is converted as finding the best path in the tree hierarchy,and a novel branch and bound-like algorithm is introduced to efficiently search for the best path.Secondly,the classifiers are trained using a Structured SVM(SSVM)formulation with various bound constraints.Simulation results show that,thismethod achieves a significant 4.65%,5.43%,and 4.07%improvement in accuracy at high efficiency compared to state-of-the-art greedy“tree-based”methods on Caltech-256,SUN and ImageNet1K dataset,respectively.
image classification;branch and bound;optimal path;greedy algorithm;efficiency;accuracy
TP393
A
陈洁萍(1980—),女,硕士,讲师,主要研究方向为图像处理、云计算;
��健男
2014-07-17
【本文献信息】陈洁萍,甘泉,张慧.一种基于最优路径搜索的图像分类方法[J].电视技术,2014,38(23).
国家自然科学基金项目(61373070/F020501)
甘 泉(1980—),硕士,讲师,研究方向为图像处理、数据挖掘;
张 慧(1978—),女,博士,副教授,硕士生导师,主要研究方向为计算机图形学、计算机辅助几何设计。
猜你喜欢
中国惯性技术学报(2019年6期)2019-03-04
民族古籍研究(2018年1期)2018-05-21
计算机应用(2017年4期)2017-06-27
中央民族大学学报(自然科学版)(2017年2期)2017-06-11
光学精密工程(2016年4期)2016-11-07
光学精密工程(2016年3期)2016-11-07
火控雷达技术(2016年3期)2016-02-06
新校长(2016年8期)2016-01-10
浙江理工大学学报(自然科学版)(2015年10期)2015-03-01
浙江大学学报(工学版)(2015年1期)2015-03-01
