
一种面向不确定图的SimRank算法
2014-06-15 17:06董宇欣王莹洁宁鹏飞张耀元
哈尔滨工程大学学报 2014年11期
董宇欣,王莹洁,宁鹏飞,张耀元
(哈尔滨工程大学计算机科学与技术学院,黑龙江哈尔滨150001)
一种面向不确定图的SimRank算法
董宇欣,王莹洁,宁鹏飞,张耀元
(哈尔滨工程大学计算机科学与技术学院,黑龙江哈尔滨150001)
针对以往的搜索引擎日志分析都主要集中在用户行为分析、查询推荐及搜索引擎评价等方面,采用社会网络分析法对搜索引擎进行日志分析。以不确定图的方式逻辑表示搜索引擎的日志中查询词和网页的链接关系,通过基于不确定图的SimRank算法,计算查询词与网页的相似度,最终以相似度和查询词的加权方式建立网页描述库。针对概率抽样的3点基本要求,提出一种渐进式的抽样策略,从而保证采用抽样技术对于不确定图中SimRank值计算的准确性。实验表明该算法具有较好的准确率和可行性。
搜索引擎;社会网络;不确定图;SimRank;相似度;抽样策略
传统搜索引擎在商用过程中,都设计一套日志系统,记录下用户在搜索引擎上的使用信息。用户每进行一次查询及在查询结果中的浏览信息,日志系统会将用户查询词、点击URL、用户ID、查询时间、浏览时间等信息记录下来。搜索引擎的长期运行,使得日志文件中记录信息极为丰富,庞大的日志信息量背后蕴藏着很多知识、经验及用户行为。
关于社会化排序算法,多数研究是利用社会网络中的社会标注改进搜索引擎排序结果。Hotho等[1]提出的FolkRank算法是面向社会标注系统的网页排序,社会标注系统在该算法中被视作用户、资源和标签三元集合关系图,是对PageRank算法的一种改进。包胜华等[2]提出了利用社会标注计算用户、网页及标注间的相似度排序算法SSR和标注网页排序算法SPR,这种算法类似于SimRank算法的相似传播矩阵迭代计算。刘凯鹏等[3]提出一种基于社会性标注的网页排序算法,这是一种有机结合网页和用户的查询相关性与互增强关系的网页排序算法。微软的研究人员Liu等[4],提出一种BrowseRank算法,以日志中所记录的用户的搜索行为来计算网页权重,融入了社会网络中用户的参与。
针对以往的搜索引擎日志分析都主要集中在用户行为分析、查询推荐及搜索引擎评价等方面,本文采用社会网络分析法对搜索引擎进行日志分析,以不确定图的方式逻辑表示搜索引擎的日志中查询词和网页的链接关系,通过基于不确定图的SimRank算法,计算查询词与网页的相似度,最终以相似度和查询词的加权方式建立网页描述库。此外,针对概率抽样的三点基本要求,论文提出一种渐进式的抽样策略,从而保证采用抽样技术对于不确定图中SimRank值计算的准确性。
1 日志数据的逻辑表示
搜索引擎用户在进行一次查询请求时,会在搜索结果中主动筛选出自己认为内容相关的网页进行浏览,搜索引擎的设计者会将这些查询浏览信息记录下来保存到日志文件当中。
搜索引擎日志文件中一般包括用户ID、搜索时间、查询关键词、用户所点击的链接URL、该链接在返回结果中的排名等信息[5]。日志中蕴藏着丰富的用户兴趣、群体发现、行为评价等信息,需要采用多种手段进行日志挖掘,这都为搜索引擎的演化改进提供了有力的支撑[5-7]。

图1 搜索引擎日志二部图Fig.1 Bigraph of search engine log
如图1所示为搜索引擎日志二部图。本文处理搜索引擎日志,剔除多余内容,只保留查询关键词与网页链接两部分内容。同时,根据日志中两项的对应关系建立查询词到网页的链接关系,链接上标注对应关系出现的次数。
图1中搜索引擎日志二部图就是一个不确定图,本文采用不确定图刻画搜索引擎日志,下面介绍不确定图。
不确定图一般由3个要素组成,图中的节点、边以及边存在的概率。形式化表示就是G=<V,E,P>,其中G代表不确定图,V和E代表图中结点和边的集合,概率函数P代表图中2个节点存在连接的概率。对于不确定图G的每一条边,其存在的概率是p(e),不存在的概率是1-p(e),则P(g)=表示不确定图一部分节点存在,另一部分节点不存在派生的新图g的概率,图g叫做不确定图G所对应的确定图,也叫做不确定图的可能世界。
不确定图G中的边的关联概率函数P,由图1搜索引擎日志二部图中的边的权重W(q,d)通过归一化处理计算得到。连接关键词qi和网页dj的边的存在概率为

此外,本文通过社会网络分析法进行日志挖掘获取网页理想关键词的一个构想。分析搜索引擎观点、用户观点、关键词流行度这3部分内容,正是根据长尾理论的思想挖掘日志文件中网页的理想关键词[8]。其中,搜索引擎观点是通过WEB爬虫爬取网页HTML文件中的关键词标签内容得到,用户观点由在日志文件的一条查询记录得到体现,关键词的流行度可通过日志文件的逻辑图描述方法统计分析。基于长尾理论获取的网页理想关键词最能够描述网页的主体内容,它不再由网页的制作者决定,而是社会网络中用户共同决定[9]。
2 提取网页描述信息的策略
社会网络的长尾理论揭示了社会群体对于一个发散特征的事物的描述方法。将这种方法转移到提取网页描述信息,往往一个网页会拥有若干关键词,这些关键词根据与网页内容的相似程度可以分为主关键词与长尾关键词,如图2所示,正是对一个介绍苹果手机的网页的若干关键词的分布所构成的长尾曲线,这些关键词可能不是网页中出现过的内容,像智能手机、Siri就是社会网络大众对于网页内容的个性理解,它们都是长尾关键词,都是对网页信息的潜在描述。
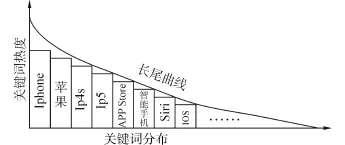
图2 长尾模型下的网页关键词分布Fig.2 Keywords distribution of webpage under longtail model
相关联的事物之间有一定的相似度。在第1节日志数据的逻辑表示方法中,查询关键词与网页是相互链接的,可以通过SimRank算法[10-14]计算关键词与网页的相似度来获取到网页的主关键词与长尾关键词。本节将改进SimRank算法,其基本思想是,同一个类型下的2个对象,如果经常连接到相同的其他对象,那么这2个对象的相似性应该很高。基于这种思想,SimRank算法可以用来计算任意2个对象之间的相似度,这种相似度的度量取决于相互连接的节点的上下文节点,建立在与它们相邻节点的关系基础之上。更进一步说,SimRank算法认为:如果2个节点与相似的节点都有连接关系,那么这2个节点也是相似的。
不确定图中节点相似度的计算问题:在不确定图G=<V,E,P>中,计算集体V中节点之间的相似度。首先,关于面向不确定图的SimRank算法的若干定义。
定义1 节点a与节点b关系阈值。设ε为判断阈值,当2个节点a,b相似值小于给定阈值ε,即S(a,b)<ε时,就可以认为节点a和b基本不相似,这时称a与b无关;否则,认为a与b是相关的。这一点采用了SimRank优化算法的剪枝技术。
定义2 节点a与节点b在不确定图G中的SimRank值的相关概率统计定义[15]。概率分布函数:
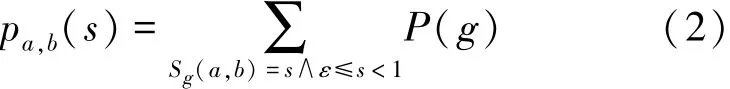
期望:
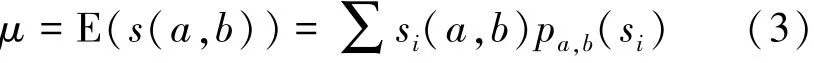
方差:

不确定图G中,节点a与节点b并没有确切的SimRank值,SimRank算法只适用于确定图。通过第1节所介绍的不确定图的性质可知,不确定图G可以以一定的概率P(g)派生出确定图g,在这个确定图g上就可以进行SimRank计算。不确定图的SimRank值是一个概率事件,虽然不能确切计算,但可以得到其概率分布函数、期望及方差值,这是非常有意义的。本文就是用期望值刻画不确定图中2个节点的相似关系的。
根据用户行为在搜索引擎日志中的表现,论证SimRank概率分布服从正态分布。
定理1 g1,g2,…是不确定图G的所有可能世界,令它们代表独立同分布的节点a和b的Sim-Rank值随机变量序列,序列的均值为μ,方差为δ。当不确定图G的可能世界的个数n充分大时,记G=g1+…+gn,则G~N(nμ,nδ2)。由中心极限定理可知,令Gn的分布函数的极限分布为标准正态分布函数Φ(x),故G服从正态分布。
不确定图G所派生出来的所有可能世界g上的节点间的SimRank值,它们共同组成概率事件不确定图G上的SimRank值,由定理1可知,不确定图G上的SimRank值服从正态分布。
2.1 不确定图中SimRank基本算法
输入:不确定图G,查询点a,阈值ε
输出:节点a与有关节点的信任关系
执行流程:
for(i=0;i<2|E|;i++)
对不确定图的每个可能世界g,计算节点a与其他节点的SimRank值;
求出可能世界g存在的概率P(g);
end for
根据定义3,求出点a与其他相关节点的Sim-Rank期望值。
基本算法比普通SimRank算法更为复杂,它包含了计算不确定图的所有可能世界的任务,并在每个可能世界中都要进行一次SimRank计算。由上文对于SimRank算法效率的分析,可知每个可能世界SimRank计算的代价为O(|V|3)。在忽略不确定图可能世界的计算代价的前提下,不确定图中的SimRank计算的时间复杂度为O(2|E|·|V|3)。同时,算法的时间消耗会随着节点个数的增加,以指数形势增长。
针对SimRank限制传播半径的方法,本文又继续提出如下定义。
定义3 半径子图与概率半径子图。子图就是一个图的子集,对于任意不确定图G=<V,E>或者其对应的确定图g=<V,E>,以点a为中心,由近及远遍历图中的各个节点,限制遍历路径长度不超过r,将生成不确定图G和其确定图g的以a为中心,r为半径的半径子图,简称子图。其中不确定图G的子图也称作概率半径子图,简称概率子图。
定理2 设g′为确定图g的一个以点a为中心、r为半径的子图,给定阈值ε,C代表SimRank公式中的衰减因子,则对于∀b∈g-g′,当r>时,a与b无关。
证明:定义2个随机游走者,分别从图g中的节点a和b出发,他们经过k步后首次相遇的概率为Rk(a,b),由文献[16]可知,节点a和b的SimRank相似度为

将图分割为2个部分,一部分为以a为中心,半径为r的节点构成的图g′,另一部分为g′对于g的补集g–g′,b为补集中的一个点。那么游走者最早在步第一次相遇。此时相遇概率为
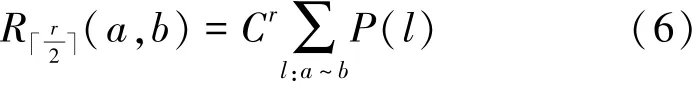
式中:l表示随机游走第一次相遇的路径,C为Sim-Rank公式中的衰减系数,P(l)表示每条路径存在的概率。则相遇路径概率最大情况如图3所示,假设这样的路径有k条,路径长度为r,除了始点与终点的度数为k,路径上其他节点度数为2,这种情况下,P(l)取得最大值。于是


图3 相遇路径概率最大情况Fig.3 Maximum probability for path to meet
根据式(7)推导得
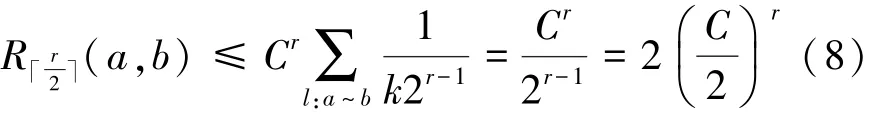
最终得出


这就是限制传播半径优化SimRank计算时间的方法。限制传播半径,不确定图就会变为其对应的概率子图,概率子图仍然是一个不确定图,于是,在概率子图上进行SimRank计算可以替代算法2.1。
2.2 在概率子图上进行SimRank计算
输入:不确定图G、起始点a、阈值ε
输出:点a与有关节点的信任关系
执行流程:
1)计算限制传播半径r,将不确定图G转化为其对应的以r为半径的概率子图
2)采用概率抽样中的系统抽样法,对概率子图所派生的所有确定图进行抽样,计算样本中节点a与其他节点的SimRank值
3)对样本确定图的存在概率进行加权归一化处理,获得样本确定图新的存在概率
4)最后求出概率子图中SimRank值的期望。
关于优化算法中的构造概率子图的方法,生成概率子图的算法是在不确定图G中,以查询点a为起点,按照类似于图的广度优化遍历算法,使广度优化遍历算法的每条路径长度不超过r。将图中的节点以a为中心按连接路径长度进行层次划分,取r层以内的所有节点。将所有记录到的节点集合构成一个新的图,如此,可得到以不确定图G的以点a为中心,r为半径的概率子图。
概率抽样以概率理论为基础,对于事件总体空间内的每个个体,都会有一个预定的概率被抽到。抽样过程是一种随机化的流程,根据概率理论中的大数定律,当抽取的样本达到一定数量时,随机抽取的样本在一定程度上可以替代总体,在这个样本空间内的各种概率计算,都可以表示总体的性质。
进行概率抽样应当遵循3个基本原则:1)随机性,对总体抽样时,每个个体被抽到的概率是相同的;2)可行性,抽样在现实条件下是可操作的,不能超越实现情况;3)信息性,所抽到的样本应当符合总体分布规律,反映出总体的分布特征。
概率抽样包括简单随机抽样、系统抽样、分类抽样、整群抽样、多阶段抽样等多种抽样方案。简单随机抽样:在包含N个个体的总体中,以相同的概率逐一抽取M个样本。简单随机抽样在总体中的个体数较多的情况下显得原始粗糙又耗时,系统抽样则适用于这种情况,将总体分为均匀的M等份,在每一份中随机抽取个体,可得到M个样本。分层抽样与系统抽样类似,都是将总体分为M等份,充分考虑到总体的分布规律,对各等份依照比例采取抽样。依据上述主要的概率抽样类型的适用情况,不确定图的概率子图的派生样本较多,且已知不确定图中SimRank的概率分布规律,故系统抽样方法是本文所面临问题的理想方案。
根据定理1可知,不确定图中节点间SimRank值的概率公布服从正态分布,则由概率抽样方法中的简单随机抽样方法计算SimRank值。针对概率抽样的3点基本要求,论文提出一种渐进式的抽样策略,首先是确保抽样个数达到一定程度,使得样本在一定可信度下可以代替整体,其次是按正态分布的规律针对抽样个数进行抽样,在抽样个数m确定的情况下,将样本空间平均分为m份,每一份抽取一个样本。
设优化算法的抽样个数为m,抽样前第i个样本确定图的存在概率为pi,由于抽样后样本的存在概率的和不为1,所以需要归一化处理,归一化处理后第i个样本确定图的存在概率为pi′。算法2.2的第3步将按下进行:

定理3 对于不确定图G=<V,E,P>,构造其以节点a为中心、r为半径的概率子图G′,并设ε为阈值。{G′}P是G′对于边的存在概率集合P所派生出的m个可能世界的样本集合,且在每个可能世界中的所有节点都是相关的,S(a,b)代表每一个可能世界中的节点对(a,b)的SimRank值,则对于任意的θ>0,当抽样样本个数会使得成立。

证明:由Hoeffding不等式可知,对于相互独立的随机变量ξ1,ξ2,…,ξN,满足ai<ξi<bi,记则对于任意的θ>0,都有
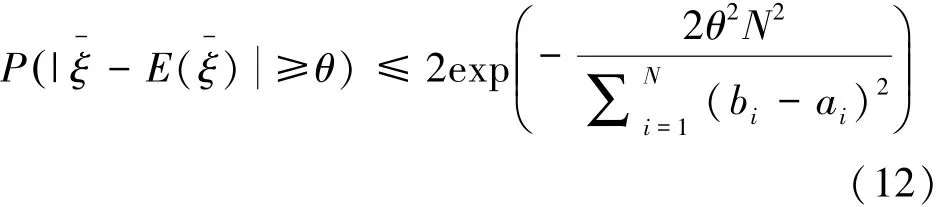
概率子图G′基于概率P所派生的m个可能世界样本,是相互独立的随机变量序列,根据定义1中的相关性可知,每一个可能世界的节点对(a,b)的SimRank值S(a,b)的取值范围在都区间[ε,1]之内,并且样本均值为μ,将这些条件依次代入Hoeffding不等式,可得


由式(14)推导可得

证毕。
由定理3,本文的抽样方法保证了采用抽样技术对于不确定图中SimRank值计算的准确性。另外,在确定抽样个数后,进行随机抽样,样本很可能出现扎堆的现象,若继续提高抽样样本的质量,还需要针对不确定图中SimRank值服从正态分布这一规律,使所抽取到的样本也大致服从正态分布。
前面已经提供了获取概率子图的方法,再令概率子图中的每一个节点以0.5的概率存在(即节点在概率子图中存在和不存在是等可能事件),然后将存在的节点保留,不存在的节点剔除,依然保持所剩节点间的概率连接,所得到的图即可作为一个抽样样本。以同样的方式进行抽样,进而可以抽取得到m个样本,这些样本出现扎堆现象的概率为,样本个数越大,扎堆现象出现的概率就越低。
通过本文所提出的采样技术进行不确定图中SimRank计算,时间复杂度会大大降低。与Sim-Rank的基本迭代算法(2.1.1节)相比,优化算法(2.1.2节)中增加了构建概率子图和抽样环节,其中,生成概率子图与子图中的抽样所需要的时间仅与限制传播半径后的子图的节点数和边数呈线性关系,而限制传播半径后的子图规模与不确定图相比已大大减小。所以优化算法是在小规模图中进行Sim-Rank计算,时间复杂度与样本数量及子图节点个数相关。在样本数为m,子图节点个数为v的情况下,时间复杂度为O(mv3),样本m和子图节点个数均远远小于不确定图中节点个数n,与基本迭代算法的时间复杂度O(n4)相比,优化算法的效率得到了显著的提高。
3 实验与分析
3.1 数据获取及预处理
目前,已有很多搜索引擎公司公开了自己的日志数据,如AOL、搜狗等。本实验所使用的查询日志数据为搜狗公司的搜狗实验室面向学术研究公开的搜狗搜索引擎查询日志数据,日志数据是2008年6月搜狗搜索引擎所记录的用户搜索请求关键词及用户所浏览的网页链接集合。搜狗日志的数据格式为:访问时间\t用户ID\t[查询词]\t该URL在返回结果中的排名\t用户点击的顺序号\t用户点击的URL。这份日志数据中包括了总共46 389 567条记录。
实验首先数据预处理,过滤冗余的和无效的查询;剔除日志数据中无用的信息,只保留查询词与链接URL2列。将所得到的干净的数据转换为关键词与网页链接的二部图,关键词与网页链接的共同现次数作为图中各个边的权重,通过式(1)中边的存在概率的计算方法,生成日志不确定图。图中有关键词节点4 605 412个,URL链接节点2 316 342个。
3.2 实验设计与评价
SimRank是一个很耗时的算法,本文的改进算法就是要提高它在不确定图上的计算效率,同时还需要保证结果的准确性。
根据2.1节中对于算法的时间分析可知,Sim-Rank算法的时间复杂度是O(n4),而优化算法的时间复杂度为O(mv3),其中m为采样个数,v为子图节点个数。验证算法效率的提高,最直接的办法就是比较n、m、v三者的关系。优化算法就是期望抽样个数的减少和子图节点个数的减少。
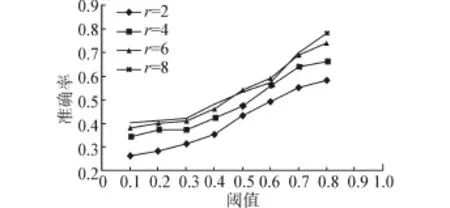
图4 概率子图上求SimRank值的准确率Fig.4 The accuracy of SimRank on probability graph
第1部分实验,分析概率子图节点个数和不确定图中节点个数的比例,同时,由于采用的是剪枝优化法,还需要分析概率子图中边的个数与不确定图中边的个数的比例。在这里,节点个数和边的个数的减少都会降低概率抽样方法的采样个数。对于传播半径的分析,选择性设置传播半径为2、4、6、8的4个值作对比,衰减系数设置与PageRank算法中C值相同同为0.85。在经过预处理后的数据中,随机选择1 000条记录,包括1 383个查询关键词、927个URL链接及1 564条边,对这些查询关键词都进行优化算法,然后计算准确率的平均值。
由图4可知,随着阈值的增大,优化算法的准确率逐渐提高。同时,传播半径的延长,准确率也会随之提高,但半径越大,准确率的提高越不明显。这也说明定理2对于传播半径限制的作用,半径长度以外的其他节点对于SimRank值的影响可以忽略。
有了优化算法准确率的保证,则在图5中,概率子图与不确定图上的点和边比例关系可以看出,使用采样及剪枝方法后,节点和边的个数大幅度减少,准确率则并没有受到影响,且传播半径越大,这种节点和边比例的变化越不显著。
第2部分实验,验证优化算法的计算时间是否降低,其中随机取5个查询点,以不同的抽样值m得到SimRank计算的平均时间。所采用的服务器配置为Intel i3 2350M处理器(主频2.3 GHz),6 G内存,windows7SP1 64位操作系统。

图5 概率子图与不确定图上的点和边比例Fig.5 The proportion of nodes and edges on probability graph and uncertain graph

表1 不确定图上的SimRank计算时间Table 1 SimRank computing time on uncertain graph
表1中,基本算法是不需要抽样的,而优化算法中选择抽样个数为17、36、84,在对随机挑出的100个URL链接计算其相似的关键词所需要的时间消耗求算术平均值,就是表中的平均计算时间。随着抽样个数的增加,平均计算时间也在增加,但远远低于基本算法的计算时间,可见本文所提的优化算法相比基本算法可行性很强。
4 结束语
本文所研究内容由搜索引擎日志通过社会分析方法逐步形成网页描述库。网页描述库的建立是搜索引擎社会化的一个体现,是本文社会化搜索排序的一个重要参考因素。着重介绍了如何将日志数据抽象为一个不确定图,并用形式化语言表达了描述信息的组成。在日志不确定图的基础上改进Sim-Rank算法,提出了一种基于抽样和限制传播半径的优化算法,提高了算法的时间效率。
在今后的研究中,将进一步研究用户的行为,建立更加准确的网页描述库,并进一步提高算法的时间效率。
[1]HOTHO A,JÄSCHKE R,SCHMITZ C,et al.Folkrank:a ranking algorithm for folksonomies[C]//Proc FGIR.Hildesheim,Germany,2006:111-114.
[2]BAO S,XUE G,WU X,et al.Optimizing web search using social annotations[C]//Proceedings of the 16th International Conference on World Wide Web,ACM.Alberta,Canada,2007:501-510.
[3]刘凯鹏,方滨兴.一种基于社会性标注的网页排序算法[J].计算机学报,2010,33(6):1014-1022.LIU Kaipeng,FANG Binxing.A novel page ranking algorithm based on social annotations[J].Chinese Journal of Computers,2010,33(6):1014-1022.
[4]LIU Y,GAO B,LIU T Y,et al.BrowseRank:letting web users vote for page importance[C]//Proceedings of the 31st Annual International ACM SIGIR Conference on Research and Development in Information Retrieval,ACM.Singapore,2008:451-458.
[5]陈红涛.基于搜索日志的用户行为研究及应用[D].北京:北京邮电大学,2007:14-29.
[6]NOLL M,MEINEL C.Web search personalization via social bookmarking and tagging[J].The Semantic Web,2007,4875:367-380.
[7]靳延安,李瑞轩,文坤梅,等.社会标注及其在信息检索中的应用研究综述[J].中文信息学报,2010,24(4):52-62.JIN Yan'an,LI Ruixuan,WEN Kunmei,et al.A survey on social annotation and its application in information retrieval[J].Journal of Chinese Information Processing,2010,24(4):52-62.
[8]CHOOCHAIWATTANA W,SPRING M B.Applying social annotations to retrieve and re-rank web resources[C]//Proceedings-2009 International Conference on Information Management and Engineering,ICIME.Kuala Lumpur,Malaysia,2009:215-219.
[9]BALFE E,SMYTH B.An analysis of query similarity in collaborative web search[J].Advances in Information Retrieval,2005,3408:330-344.
[10]JEH G,WIDOM J.SimRank:a measure of structural-context similarity[C]//Proceedings of the Eighth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,ACM.Edmonton,Canada,2002:538-543.
[11]ANTONELLIS I,MOLINA H G,CHANG C C.SimRank++:query rewriting through link analysis of the click graph[C]//Proceeding of the 17th International Conference on World Wide Web 2008.Beijing,China,2008:408-421.
[12]李亚楠,许晟,王斌.基于加权SimRank的中文查询推荐研究[J].中文信息学报,2010,24(3):3-10.LI Yanan,XU Sheng,WANG Bin.Chinese query recommendation by weighted SimRank[J].Journal of Chinese Information Processing,2010,24(3):3-10.
[13]CAI Y,LI P,LIU H,et al.SimRank:combining content and link information to cluster papers effectively and efficiently[J].Advanced Data Mining and Applications,2008,5139:317-329.
[14]马云龙,林原,林鸿飞.基于权重标准化SimRank方法的查询扩展技术研究[J].中文信息学报,2011,25(1):28-34.MA Yunlong,LIN Yuan,LIN Hongfei.A weight normalization based SimRank approach for query expansion[J].Journal of Chinese Information Processing,2011,25(1):28-34.
[15]张应龙,李翠平,陈红,等.不确定图上的kNN查询处理[J].计算机研究与发展,2011,48(10):1850-1858.ZHANG Yinglong,LI Cuiping,CHEN Hong,et al.K-nearest neighbors in uncertain graph[J].Journal of Computer Research and Development,2011,48(10):1850-1858.
[16]MORRIS M R,PAEPCKE A,WINOGRAD T.Teamsearch:comparing techniques for co-present collaborative search of digital media[C]//Proceedings of the First IEEE International Workshop on Horizontal Interactive Human-Computer Systems,TABLETOP'06.Adelaide,Australia,2006:97-104.
An uncertain graph oriented SimRank algorithm
DONG Yuxin,WANG Yingjie,NING Pengfei,ZHANG Yaoyuan
(College of Computer Science and Technology,Harbin Engineering University,Harbin 150001,China)
In this paper,the social network analysis(SNA)method is adopted to analyze search engine logs according to previous search engine logs analysis that mainly focuses on user behavior,query recommendation and search engine evaluation.The objective of SNA is to exam the structure of relationships between social entities.This method uses an uncertain graph to logically indicate the link relationship between the query term and the webpage of search engine log.It also computes the similarities between query term and webpage based on the SimRank algorithm of an uncertain graph.As well as,establishes a webpage description library by similarity and query term in a weighted way.In addition,this paper proposes a progressive sampling strategy to ensure the calculation accuracy of the SimRank value in an uncertain graph.Experiments show that the algorithm has good accuracy and feasibility.Keywords:search engine;social network;uncertain graph;SimRank;similarity;sampling strategy
10.3969/j.issn.1006-7043.201305037
http://www.cnki.net/kcms/doi/10.3969/j.issn.1006-7043.201305037.html
TP301
A
1006-7043(2014)11-1390-07
2013-05-14.网络出版时间:2014-10-30.
国家自然科学基金资助项目(61272186,61100007);黑龙江省基金资助项目(F200937,F201110);中央高校基本科研业务费专项资金资助项目(HEUCF100608);黑龙江省博士后基金资助项目(LBH-Z12068);哈尔滨市基金资助项目(RC2009XK010003).
董宇欣(1974-),女,副教授.
董宇欣,E-mail:dongyuxin@hrbeu.edu.cn.
猜你喜欢
华人时刊(2021年13期)2021-11-27
心声歌刊(2020年4期)2020-09-07
同济大学学报(自然科学版)(2019年2期)2019-04-02
计算机与数字工程(2019年3期)2019-03-26
小学生(看图说画)(2017年6期)2017-11-06
电子科技大学学报(2016年2期)2016-08-31
中国卫生(2015年12期)2015-11-10
新疆大学学报(自然科学版)(中英文)(2014年2期)2014-11-06
华东师范大学学报(自然科学版)(2014年1期)2014-04-16
电子设计工程(2014年19期)2014-02-27
