
基于BSP的SPARQL基本图模式查询算法
2014-06-06 10:46李国鼎冯志勇饶国政
计算机工程 2014年9期
李国鼎,冯志勇,b,饶国政,b,王 鑫,b
(天津大学a.计算机科学与技术学院;b.天津市认知计算与应用重点实验室,天津300072)
基于BSP的SPARQL基本图模式查询算法
李国鼎a,冯志勇a,b,饶国政a,b,王 鑫a,b
(天津大学a.计算机科学与技术学院;b.天津市认知计算与应用重点实验室,天津300072)
随着语义网的不断发展,发布在互联网上的资源描述框架(RDF)数据达到百亿级三元组规模,并且呈现几何增长趋势,针对RDF数据的单机SPARQL查询方法已经不再适用。为此,提出一种基于整体同步并行(BSP)模型的SPARQL基本图模式查询算法。根据RDF有向图数据特性及基本图模式定义,将整个查询过程分成匹配和迭代2个阶段,在匹配出所需查询的三元组模式后,通过迭代使部分解逐步逼近完全解,得到最终查询结果。利用HAMA分布式计算框架进行算法实现,实验结果表明,与基于MapReduce的SPARQL查询算法相比,该算法具有较高的查询效率,能为大规模RDF数据的快速SPARQL查询提供支持。
语义网;资源描述框架;SPARQL查询;基本图模式;整体同步并行模型;HAMA框架
1 概述
资源描述框架(Resource Description Framework,RDF)是语义网中表示和交换机器可理解信息的标准数据模型[1-3]。RDF数据是一类典型的图数据,主语和宾语分别形成图中的点,谓语是图中的边[4]。SPARQL作为一项W3C推荐标准,可以用来对 RDF数据集进行查询[5]。SPARQL(Simple Protocol and RDF Query Language)查询的核心是基本图模式(Basic Graph Pattern,BGP)[6-8]。基本图模式是图模式匹配问题的一个子集,而图模式匹配问题实际上是最大团问题的子问题,其复杂度是N-P的[9]。同时,在关联数据运动的推动下,RDF数据规模以爆炸式的速度快速增长,由TB级向PB级甚至EB级递进,并已经达到了大数据的规模[6]。在RDF图数据增长为大数据的情况下,单机性能的增长已经不能满足RDF数据的增长,在单机上处理RDF大数据有明显瓶颈,甚至已经变得不可能。
为解决单机性能不足的问题,文献[10-12]提出基于MapReduce分布式计算模型实现的SPARQL基本图模式算法,这些算法一般分为2个阶段:选择阶段和连接阶段。在选择阶段,针对每个RDF三元组依次用所有SPARQL三元组模式进行匹配,过滤出满足条件的三元组,并加以标识。在连接阶段,通过一定的选择策略得到连接点序列,根据该序列将选择阶段得到的结果合并成新的三元组。合并过程中不断迭代,最终得到完整的SPARQL查询结果。
由此可见,现有的SPARQL基本图模式算法存在以下问题:(1)由于单机性能的增长满足不了RDF数据几何级增长,用于单机的算法在大数据情况下不适用。(2)MapReduce方法不是原生的图算法,而且大量事实表明,MapReduce只适合批处理。
针对以上问题,利用整体同步并行(Bulk Synchronous Parallel,BSP)模型适用于图计算的特点,以及BSP模型的实现框架——HAMA的高效率,本文提出基于BSP的SPARQL基本图模式查询算法,并与基于MapReduce的算法进行比较。
2 基本定义
为描述方便,给出RDF基本图模式查询以及相关定义[7-8]。
定义1 (RDF三元组)三元组由主语、谓语和宾语构成,记为spo:

其中,I表示国际化资源标识符(Internationalized Resource Identifiers,IRI);B为空节点;L为RDF文字。为描述方便,记:

定义2 (RDF图)RDF图是一系列的三元组集合,简写为RDF_G:
定义3 (三元组模式)三元组模式和三元组相似,但是允许变量的使用,三元组模式记为t:

其中,V是所有变量的集合。SPARQL查询中最简单的图模式就是三元组模式。
定义4 (基本图模式)基本图模式(Basic Graph Pattern,BGP)由一系列的三元组模式组成:

定义5 (查询映射)假设变量V到RDF_T的映射为μ:V→RDF_T,则针对BGP的查询为:

其中,μ(BGP)表示在映射μ下BGP中替换了变量的三元组集合。μ(BGP)集中任意一个元素是BGP查询的一个解,对μ(BGP)集合的求解是算法的最终目的。
3 基本图模式查询算法
3.1 BSP算法框架
BSP计算模型由哈佛大学Viliant教授于1990年提出[13-14]。宏观上,BSP计算模型由一系列超步组成,这种结构类似于串行程序结构,而具体到一个超步内部,又分为3个部分:(1)本地计算阶段:各个计算节点对本地数据进行计算;(2)全局通信阶段:计算节点对非本地数据进行通信和处理;(3)同步阶段:等待所有同步结束。
基于BSP的这些特性,Google在2010年提出了一个基于BSP模型的商业系统——Pregel系统,把BSP模型运用在分布式计算中[15]。Google用Pregel来处理大型的图数据,把图中一个点看成是BSP模型中一个计算节点。HAMA是BSP模型的一个开源实现[16]。HAMA计算框架可以用来进行图、矩阵、复杂网络等大型科学计算,HAMA图编程模型具体如下:

该模型描述了一个BSP超步的计算过程,以点为计算单元,主要包括3个部分:
(1)定义相关数据的数据结构,包括一个点中值的类型VertexType、边的类型EdgeType、消息的类型MessageType。
(2)每个点的输入都来自上一个超步的消息。
(3)在每个计算函数中定义2类操作:修改该点值的操作setValue()和发送消息操作sendMessageTo()。
3.2 HAMA图编程模型实例化
MessageType与VertexType是HAMA编程模型中定义的抽象数据类型,针对RDF数据的特点,把VertexType实例化为Vertex变量,把MessageType实例化为Message变量。为了更清晰地描述这2种类型的数据结构,定义了相关中间变量。
定义6 中间量定义:
(1)Path表示当前已经匹配的SPARQL三元组模式,是BGP的一个部分解,满足:

(2)Description表示变量V和RDF_T之间的对应关系,Description由一系列变量和RDF_T对组成的集合,即:

(3)value集合表示一个RDF_T点当前获知的所有Path和相应的Description:

定义7 BSP图编程模型中MessageType的数据类型Message:

其中,BSP计算过程中消息的数据结构则可以用Message表达,一条消息包括了一条Path和Path相应的Description。
定义8 BSP图编程模型中VertexType的数据类型Vertex:
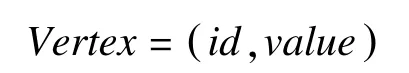
其中,在BSP模型中,RDF_G图的RDF_T点中的值用Vertex表示,每个点除了有唯一的id之外,还有对应的value。当Path等于BGP时,整个SPARQL查询完成,此时部分解等于完全解,整个运算过程停止。
3.3 RDF基本图模式查询算法
通过对整个基本图模式计算过程的分解,根据计算任务的不同,定义2类超步:
(1)原子匹配超步:每个点匹配出该点满足的SPARQL三元组模式。
(2)构建SPARQL超步:每个点根据已知的信息和收到的消息,逐步构建完整的SPARQL查询。
原子匹配超步在整个基本图模式计算过程中只迭代一次,这个过程称为匹配。构建SPARQL超步要迭代多次,这个过程称为迭代。
3.3.1 RDF三元组模式匹配
BSP匹配过程可以看作是整个计算过程的初始化阶段。这个过程含有一个原子匹配超步(算法1)。此过程可以描述为:每个点对其作为起点的所有边匹配SPARQL查询中的每一个三元组模式,如果匹配成功则更新Vertex值并发送相应的Message。这一步目的是获得初始的原子匹配信息,并把这些信息告诉下一个阶段。
算法1 原子匹配超步


3.3.2 RDF基本图模式查询迭代
迭代过程的输入是匹配过程的输出。为了使匹配信息扩散到每一个相关计算节点,包含多个构建SPARQL超步(算法2)。由于Path是BGP的一个部分解,Path中含有部分的匹配信息。每一个超步都是Path不断逼近BGP的过程,也是匹配信息不断完善的过程。当Path等于BGP时,则完整的基本图模式查询构建完成。
算法2 构建SPARQL超步

对照BSP模型,算法2中一个超步主要含有2个动作,对来自上一个超步Message的处理,以及向下一个超步发送Message。算法2提到的Message和Path比较Description信息是否冲突,主要是看变量V和RDF_T点之间的映射关系μ是否有不一致的情况。
在整个算法结束之后,HAMA计算框架输出的是RDF_G的点集。此时,还需要把 Vertex值中Path=BGP的点过滤出来,根据Description信息,最后得到SPARQL查询结果。
4 实验结果与分析
为分析本文提出的BSP基本图模式算法的时间复杂度,对SPARQL基本图模式查询进行详细实验。实验主要考察比较本文算法和MapReduce基本图模式算法在运行时间上的差异。
4.1 实验设计
本文实验的软硬件环境配置如下:三节点的集群服务器,所有节点的配置都相同。每个节点的操作系统均为64位Ubuntu 12.04,JDK采用64位1.6.25版本,HAMA采用6.0版本,Hadoop采用1.0.4版本。硬件配置,CPU均为Intel i3-2120 3.30 GHz,内存为4 GB。
由于HAMA计算框架不同于Hadoop,要求一个Job的所有Task同时参加计算。由于实验机器性能的限制,每一台机器只能进行3个HAMA Task, 3台机器一共只能进行9个HAMA Task。所测试的数据集为DBpediapage_link_en数据集的一个子集。
不失一般性,考察3个查询。

4.2 实验结果
图1展示了基本图模式算法在MapReduce和BSP下的处理时间。可以看出,针对直径长的BGP查询,本文提出的BSP算法相对MapReduce算法有优势。在Q1和Q2中,BSP算法比MapReduce算法查询时间短,在Q3中,BSP算法与MapReduce算法性能接近。

图1 算法查询时间比较
4.3 实验分析
本节主要对算法的时间复杂度进行分析。


BSP计算一共有N个超步。ms,ghs和ls分别表示是一个超步中本地计算、通信、同步的时间。MapReduce模型的计算时间TMR为:

MapReduce计算一共迭代L步。mi,si和ri分别表示一次迭代中 Map,Shuffle-sort,Reduce的时间。
将本文提出的基于 BSP模型的算法与基于MapReduce模型的算法进行对比,可以看出,2种算法的复杂度在一个级别。但是2种算法的并行度不一样,而并行度可以通过迭代次数反映出来,迭代次数越少并行度越高,反之也成立。
在BSP方式中,由于SPARQL查询可以通过信息传递,因此每个节点中记录的SPARQL三元组模式的增长是扩散性的,整个计算过程的迭代次数是lb(D)。其中,D是SPARQL模式图中点的直径。MapReduce根据选择连接点策略的不同,会有不同的迭代次数。本文选用目前普遍使用的贪婪选择策略做比较,贪婪选择策略即每次选取出现次数最多的变量作为连接点,在这种选择策略下迭代次数小于等于N。
根据不同的模式图可以得到不同的比较结果。例如,在图 2(a)中,BSP需要迭代 lb(N)次, MapReduce需要迭代N次。而在图2(b)中BSP和MapReduce都只需迭代有限常数次,BSP迭代3次, MapReduce迭代2次。可以看出,BSP迭代次数的最坏情况和 MapReduce迭代次数最好情况基本一致。
同时,本文提出的BSP算法也有不足,在一些情况下,该算法会产生大量消息,称为消息风暴。在图1中Q3的处理时间BSP比MapReduce更长。因为在该RDF图中,谓语全部是“dbpedia-owl:wikiPage-WikiLink”,所以“?x,dbpedia-owl:wikiPageWikiLink,? y”中匹配了全部的RDF_T点,并且消息会在这些点之间反复传递,形成性能瓶颈。
5 未来工作方向
为满足更大数据量和更低运算复杂度的要求,未来将对以下优化策略进行进一步研究:
(1)合并多个查询:在本文算法中,都是针对一个SPARQL查询的算法。在现实场景中,用户会同时提交多个SPARQL查询。在该算法基础上,可以通过更名和合并策略来实现同时处理多个SPARQL查询。比如有2个查询“SELECT who1,who2 WHERE{? who1 like?who2}”和“SELECT who1,who2 WHERE {?who1 hate?who2}”可以更名合并为“SELECT who1,who2,who3,who4 WHERE{?who1 like? who2,?who3 hate?who4}”。由于BSP的并行特性,因此在处理多个查询中使用更名和合并策略会减少查询时间。
(2)预处理:在查询前可以对RDF数据进行预处理,去除一些在计算过程中会增加计算量和通信量,但与计算结果无关的点和边。比如,对于数据“: tom:like:kate.:kete:hate:jim.:jim:like:tom”和SPARQL查询“SELECT who1,who2,who3 WHERE {?who1 like?who2,?who2 hate?who3}”在RDF图中,三元组“:jim:like:tom”和结果集并无太多关系,但是在BSP计算过程中,该边仍然要参与计算,同时增加消息传递量。
(3)改善HAMA图划分:BSP实现模型HAMA默认对图数据中的点哈希划分到各个计算节点上。为提高运算速度,可以修改HAMA源代码来改善对图数据中点哈希划分策略,使每个计算节点中的点联系更加紧密,从而减少计算节点之间的通信量,达到提高运算速度的效果。
6 结束语
本文根据BSP计算模型适用于图数据的特性,提出一种基于BSP的SPARQL基本图模式查询算法。该算法将SPARQL基本图模式分解成2个阶段:匹配阶段和迭代阶段,先匹配出每个要查询的三元组模式,然后通过迭代使部分解逐步逼近完全解,最后得到查询结果。利用BSP模型计算框架——HAMA,验证了该算法的正确性,并与基于 MapReduce的SPARQL基本图模式算法进行对比,具有较好的查询效率。在后续工作中,将对算法进行改进,降低时间和空间复杂度,并且进一步完善SPARQL查询,从而覆盖更多的SPARQL查询语法。
[1] Berners-Lee T,Hendler J,Lassila O.The Semantic Web [C]//Proceedings of ASWC'09.Shanghai,China: [s.n.],2009:6-9.
[2] 姜龙翔,王 鑫,李 旭,等.一种大规模RDF语义数据的分布式存储方案[J].计算机应用与软件,2011, 28(11):30-32.
[3] Bizer C,Heath T,Berners-Lee T.Linked Data——The Story So Far[J].International Journal on Semantic Web and Information Systems,2009,5(3):1-22.
[4] Jiang Yang,Feng Zhiyong,Wang Xin,et al.Adapting Property Path forPolynomial-time Evaluation and Reasoning on Semantic Web[J].Transactions of Tianjin University,2013,19:130-139.
[5] 杜 方,陈跃国,杜小勇.RDF数据查询处理技术综述[J].软件学报,2013,24(6):1222-1242.
[6] 陶 俊,孙 坦.基于Linked Data的RDF关联框架综析[J].现代图书情报技术,2011,12:1-8.
[7] Perez J,Arenas M,Gutierrez C.Semantics of SPARQL [R].Universidad de Chile,Tech Rep:TR/DCC-2006-17,2006.
[8] Pérez J,Arenas M,Gutierrez C.Semantics and Complexity of SPARQL[M]//Isabel C,Stefan D,Dean A,et al.The Semantic Web.Berlin,Germany:Springer, 2006:30-43.
[9] Gallagher B.Matching Structure and Semantics:A Survey on Graph-based Pattern Matching[C]//Proceedings of AAAI FS'06.[S.l.]:AAAI Press,2006:45-53.
[10] 何少鹏,黎建辉,沈志宏,等.大规模的RDF数据存储技术综述[J].网络新媒体技术,2013,2(1):8-16.
[11] Myung J,Yeon J,Lee S.SPARQL Basic Graph Pattern Processing with Iterative MapReduce[C]//Proceedings of 2010 Workshop on Massive Data Analytics on the Cloud.[S.l.]:ACM Press,2010:6-12.
[12] Kulkarni P.Distributed SPARQL Query Engine Using MapReduce[D].Edinburgh,UK:The University of Edinburgh,2010:18-31.
[13] Valiant L G.A Bridging Model for Parallel Computation [J].Communications of the ACM,1990,33(8): 103-111.
[14] Valiant L G.Bulk-synchronous Parallel Computer:USA, 5083265[P].1992-01-21.
[15] Malewicz G,Austern M H,Bik A J C,et al.Pregel:A System forLarge-scale Graph Processing[C]// Proceedings of the 21st Annual ACM Symposium on Parallelism in Algorithms and Architectures.Calgary, Canada:ACM Press,2010:135-146.
[16] HAMA[EB/OL].(2013-05-24).http://hama.apache.org/.
[17] Campbell D K G.A SurveyofModelsofParallel Computation[D].York,UK:University of York,1997.
编辑 陆燕菲
SPARQL Basic Graph Pattern Search Algorithm Based on Bulk Synchronous Parallel
LI Guo-dinga,FENG Zhi-yonga,b,RAO Guo-zhenga,b,WANG Xina,b
(a.School of Computer Science and Technology;b.Tianjin Key Laboratory of Cognitive Computing and Application,Tianjin University,Tianjin 300072,China)
With the advance of semantic Web,the Resource Description Framework(RDF)data published on the Web reaches the scale of ten billion triples,and it shows a geometric growth trend.Simple Protocol and RDF Query Language (SPARQL)query methods on stand-alone machine are no longer applicable.For this problem,this paper proposes a SPARQL Basic Graph Pattern(BGP)search algorithm based on Bulk Synchronous Parallel(BSP)model.According to the graph nature of RDF data and the definition of BGP,it divides the whole process into“matching”stage and“iteration”stage.First match each triple patterns and then iterate to get the query results eventually.It implements the algorithm by HAMA distributed computing framework.Experimental results show that it has higher query efficiency than SPARQL algorithm based on MapReduce,and it can support the SPARQL query of the large scale RDF data.
semantic Web;Resource Description Framework(RDF);SPARQL search;Basic Graph Pattern(BGP); Bulk Synchronous Parallel(BSP)model;HAMA framework
1000-3428(2014)09-0037-05
A
TP311
10.3969/j.issn.1000-3428.2014.09.008
国家"863"计划基金资助项目(2013AA013204);国家自然科学基金资助项目(61373165,61070202)。
李国鼎(1989-),男,硕士研究生,主研方向:语义网,软件工程;冯志勇,教授、博士、博士生导师;饶国政(通讯作者),博士;王 鑫,讲师、博士。
2013-08-28
2013-10-15E-mail:leeguoding@tju.edu.cn
猜你喜欢
小资CHIC!ELEGANCE(2022年1期)2022-01-11
山西大学学报(自然科学版)(2021年1期)2021-04-21
数学物理学报(2020年3期)2020-07-27
五邑大学学报(自然科学版)(2019年3期)2019-09-06
山东青年(2016年1期)2016-02-28
计算机工程与设计(2015年1期)2015-12-20
华东理工大学学报(自然科学版)(2015年2期)2015-11-07
现代防御技术(2014年6期)2014-02-28
当代修辞学(2014年3期)2014-01-21
公务员文萃(2013年5期)2013-03-11
