
基于Hadoop平台的事实并行处理算法
2014-06-02 07:50李继云
计算机工程 2014年3期
孙 莉,何 刚,李继云
基于Hadoop平台的事实并行处理算法
孙 莉,何 刚,李继云
(东华大学计算机科学与技术学院,上海 201620)
针对传统的抽取、转换和加载工具在面临数据仓库中海量事实数据时效率较低的问题,从事实表查找代理键和多粒度事实预聚合2个角度出发,提出在渐变维度表上的多路并行查找算法和在不同粒度上对事实数据进行聚合的算法。第1种算法综合考虑了渐变维度和大维度的情况,运用分布式缓存方法将小维度表复制到各个数据节点的内存中,同时对事实数据和大维度数据采用相同的分区函数进行分区,从而解决内存不足的问题,在Map阶段实现多路查找代理键,避免由于数据传输产生的网络延迟。第2种算法在Reduce阶段之后增加Merge阶段,可有效解决事实数据按照不同粒度进行聚合的问题。实验结果表明,与Hive数据仓库相比,2种算法在并行处理数据仓库的事实数据的问题上具有更高的处理效率。
MapReduce模型;维度;事实;代理键;并行查找;聚合
1 概述
在数据仓库[1]领域,数据抽取、转换和加载(Extract, Transform and Load, ETL)过程负责从异构的数据源收集数据,按照用户定义的业务规则和需求,对收集的数据集进行各种转换和清洗,最后加载到数据仓库。然而,随着数据量的不断增长,越来越多的用户希望用最短的时间将大量的业务数据通过ETL过程加载到数据仓库中,以便尽可能快地为高层管理者提供决策服务。
文献[2]提出的星型模型广泛应用于数据仓库,星型模型是指中间一张事实表,周围是与事实表通过主外键相连的维度表。由于事实的数据量较大,因此ETL过程是一个相当耗时的工作。目前,对事实并行处理的研究主要集中于利用多线程的思想在单个CPU上运行ETL任务,对ETL过程的数据流采用分割、并行转换和管道并行处理3个方面进行优化,从而解决争夺CPU资源的冲突[3]。然而,当数据量较大、中间转换逻辑复杂和数据源多样时,这种方法往往很难保证负载均衡和进程之间不产生死锁。文献[4]提出的基于MAS的分布式ETL,利用AGENT的协作性、主动性、反应性和交互性来构建分布式ETL,从而改进了分布式的负载均衡问题。以上方法虽然在一定程度上提高了处理数据的效率,但是当分布式处理上的节点之间通信和ETL任务调度出现故障时,恢复起来是相当困难的,而且负载均衡也很难控制,甚至当节点越来越多时,其网络开销也会越大,而且多个节点对同一个表的处理产生并发冲突的概率也会增加。
目前,一个可编写和运行分布式应用的处理大规模数据的开源框架——Hadoop[5-7]的兴起,吸引了众多用户的关注,他们将部署在昂贵的服务器上的应用程序迁移到价格低廉的商品机集群中进行各种各样的分布式应用,这不仅为企业解决大数据问题提供了便利性,而且还为企业节省了大量成本。文献[8-10]给出了在Hadoop平台下进行表之间连接的相关研究,可以有效地解决在Hadoop平台下表之间的连接操作。因此,为了能够提高数据仓库中事实处理的效率,本文采用Hadoop作为ETL的执行平台,基于Map- Reduce-Merge框架[11],考虑渐变维度表和大维度表的情况,针对事实表查找代理键和事实数据按照不同粒度聚合的问题分别提出相应的算法。
2 相关概念
Google提出的MapReduce[5]是一个用于处理和生成大数据集编程模型。它是基于集群计算的体系结构,用于处理密集型数据的并行计算范式,是基于Hadoop框架的一种通用编程模型。该编程模型主要是基于2个可编程的函数:

用户编写的函数有2个输入变量:键1和值1,函数输出的是中间结果的键值对[(2,2)]列表,这些键值对列表将由MapReduce类库中的分区函数按照键2进行分区,同一个键2的值列表将属于同一个分组。另外,函数同样需要由用户编写,该函数有2个输入变量:中间键2和中间值列表[2],输出为值列表[3]。


Map-Reduce-Merge框架的和函数和MapReduce框架是类似的,两者主要的区别在于函数是输出键值对列表,而不是值列表。最后加入的阶段是为了合并输出的键值对列表。
3 渐变维度表上的多路并行查找算法
为了跟踪维度的变化情况,文献[2]在维度建模中提出的渐变维度主要有2种类型,即类型1和类型2。类型1的渐变维度采用直接更新的方法,不需要记录维度的历史变化;类型2的渐变维度采用更新-插入的方法,此类型的渐变维度需要添加2个时间戳字段和一个标识字段,其中, 2个时间戳字段分别表示维度的开始生效时间和失效时间,标识字段表示维度是否为当前正在使用。图1为含有类型1和2的渐变维度的星型模型。

图1 产品销售的星型模型
从图1可以看出,商店store是类型1的渐变维度,产品product是类型2的渐变维度(因为可以通过validatefrom和validateto 2个时间戳字段记录产品维度的历史变化情况),事实表与维度表之间按照主外键的关系进行关联,事实表的主键是由各个维度表的代理键复合而成的。
本文提出的在渐变维度表上的多路并行查找算法(MPLK-SCD)主要考虑了2种情况:
(1)当渐变维度表的数据量比较小时,可以完全装入到内存中,首先在MapReduce作业启动之前将类型1的渐变维度表的自然键和代理键或者类型2的渐变维度表的自然键、代理键和2个时间戳字段存储到每一个Tasktracker的内存中,然后调用setup函数(见算法1中第1步~第5步),从本地缓存中将维度表读取出来,只需要在Map阶段(见算法1中第6步~第11步)处理每一行事实数据时,将事实记录与刚才从内存中读取的维度表关联查找出相应的代理键。如图2所示,如果为类型1的渐变维度表,则只需要将维度表的自然键store_no和事实表的自然键store_no关联;如果为类型2的渐变维度表,则不仅需要将维度表的自然键product_no与事实表的自然键product_no关联,而且还需要将事实记录的事务日期order_ date与维度的2个时间戳字段validatefrom和validateto进行匹配,从而查找出正确的代理键。

图2 2类渐变维度中代理键的查找
(2)当渐变维度表的数据量比较大时,导致其无法完全被存储在主存中,那么为了解决该问题,本文引入分区的方法。该方法的主要思想是将渐变维度表与事实表按照相同的分区函数进行分区,经过分区后,自然键相同的维度和事实数据将会出现在同一个分区中。如图3所示,假设MapReduce作业含有个map任务,事实数据按照分区函数分成1,2, …,,渐变维度数据按照相同的分区函数分成1,2 ,…,,缓存中的维度统称为,其中每一个map任务分别读取映射在相同分区的事实数据和渐变维度数据,而且在每一个tasktracker的主存中均含有小维度数据的复本,接下来就可以在map阶段完成多路查找过程。

图3 基于分区方法在渐变维度上的多路并行查找过程
因此,针对以上2种情况均可以在Map阶段完成代理键的并行查找,从而消除在reduce阶段之前由于数据迁移产生的网络延迟。在渐变维度表上的多路并行查找算法见算法1。
算法1在渐变维度表上的多路并行查找算法
输入
输出
//setup阶段,用于获取本地缓存渐变维度
第1步初始化维度数据集Dims=F,同时从本地缓存中获取渐变维度数据集CacheDims,跳至第2步。
第2步如果CacheDims是类型2的渐变维度,则跳至第3步,否则跳至第4步。
第3步如果CacheDims未遍历结束,则从中读取一行记录,记为Dim,从Dim获取自然键NK、代理键SK、维度开始生效时间ST和维度失效时间ET,并存入Dims数据集中,继续第3步,否则跳至第5步。
第4步如果CacheDims未遍历结束,则从中读取一行记录,记为Dim,从Dim获取自然键NK和代理键SK,并存入Dims数据集中,继续第4步,否则跳至第5步。
第5步输出Dims。
//map阶段,用于查找渐变维度的代理键
第6步如果value不为空,则跳至第7步,否则跳至第11步。
第7步如果Dims为类型2的渐变维度,跳至第8步,否则跳至第9步。
第8步遍历Dims,按照图2,将value中相应的字段和NK、ST和ET进行匹配,查找出正确的SK,将SK作为key',value中的度量值作为value',跳至第10步。
第9步遍历Dims,按照图2,将value中相应的字段和NK进行匹配,查找出正确的SK,将SK作为key',value中的度量值作为value',跳至第10步。
第10步输出
第11步算法结束。
4 不同粒度上聚合事实的算法
在数据仓库的OLAP应用中,在不同粒度上对事实表的聚合是一种十分常见的操作。在Hadoop平台下,可以直接使用Hive的类SQL语句实现不同粒度的聚合,然而Hive的类SQL语句最终会转化为map和reduce任务去执行,因为每一次在某个粒度上聚合事实数据时都会造成重大的开销,而且Hive无法一次性实现多粒度的聚合,所以为了提高在不同粒度上的查询响应时间,将不同粒度上的事实数据一次性聚合后存储到Hive中。利用Map-Reduce-Merge框架的思想,在Reduce阶段之后加入了Merge阶段(见算法2)。
算法2在不同的粒度上聚合事实的算法(Agg-MPM)
输入
输出
//merge阶段,用于合并2个Reduce端产生的相同粒度//的事实数据
第1步开始遍历value1和value2 2个数据集,初始化度量值sum为0。
第2步如果value1和value2 2个数据集均为空,则跳至第7步;否则跳至第3步。
第3步如果value2数据集为空且value1数据集不为空,则从value1中获取一个值设为left,同时计算sum=sum+left,继续第3步;否则跳至第4步。
第4步如果value2数据集不为空且value1数据集为空,则从value2中获取一个值设为right,同时计算sum = sum + right,继续第4步;否则跳至第5步。
第5步如果value1和value2 2个数据集均不为空,则分别从其中获取一个值,设为left和right,如果left和right的代理键相等,则计算sum=sum+left+ right,跳至第2步;否则跳至第6步。
第6步将当前粒度加一后作为key,代理键和sum作为value,输出
第7步算法结束。
比如时间维度含有年-半年-季度-月-日的层次结构,现需要按该层次结构聚合成不同粒度的事实数据,首先通过map和reduce阶段的处理之后将输出以日作为键,其他字段作为值的键值列表,然后通过Merge阶段合并这些键值对,可以将粒度为日的事实合并成粒度为月的事实,同样,将粒度为月的事实合并成粒度为季度的事实,依此类推,最终可以合并成粒度为年的事实。在不同的粒度上聚合事实的算法见算法2。
5 实验与结果分析
本文实验采用TPC-H[12]生成的数据集在Hadoop分布式集群平台上进行仿真测试,从算法的效率进行了验证分析。首先搭建了Hadoop集群,该集群由7台PC机组成。其中,1台是NameNode节点;6台作为DataNode节点。另外,在7台PC机中均安装了Ubuntu12.04、Hadoop1.0.3和JDK6,实验平台采用Eclipse3.7.2作为集群开发工具。
本文实验采用表1中的4类数据集进行测试,其中,渐变维度表为Supplier;事实表为LineItem和时间维度表为Dimdate。4类测试数据集的行数统计见表1。

表1 测试数据集行数统计
从图4可以看出,在渐变维度上处理事实的过程中,虽然2种算法随着数据量的增加,运行时间也在不断的增加,但是本文提出的算法MPLK-SCD要比Hive处理效率要高,因为只在map端查找维度键可以避免在reduce端之前由于数据迁移产生的网络延迟,而且当维度数据量越来越大时,Hive无法将维度缓存在各个tasktracker节点上,因此Hive必然要通过map-reduce 2个阶段进行维度键的查找。然而,该过程可以进一步优化,即一开始就对维度表采用垂直分区的方法,过滤掉一些不必要的数据,可为其他操作提供更多的内存空间,如果是类型1的维度,则只需要考虑维度表的代理键和自然键两列;如果是类型2的维度,除了代理键和自然键以外,还需要考虑维度的有效时间段。

图4 渐变维度处理事实所用时间
从图5可以看出,在不同粒度上聚合事实的过程中,当数据量越来越大时,本文提出的算法Agg-MPM和Hive的处理时间都在不断的增加,但是由于Hive通过map- reduce2个阶段聚合时无法一次性实现多粒度的聚合,导致磁盘I/O增加,而Agg-MPM利用低粒度的中间结果向高粒度聚合时,可以减少数据量的迁移,因此Agg-MPM算法的处理效率要优于Hive。
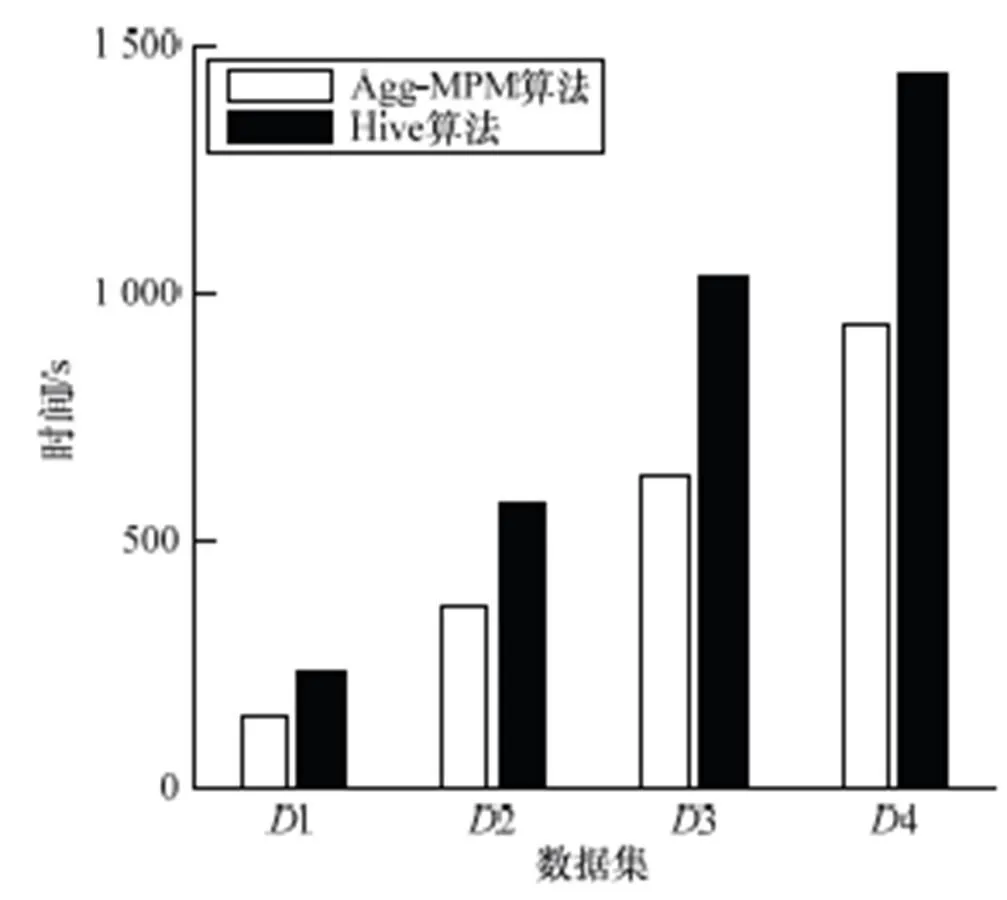
图5 不同粒度聚合事实所用时间
6 结束语
在目前大数据时代,并行处理数据仓库中的海量事实数据是当前热门的研究方向。本文提出的基于Hadoop平台的2个并行处理事实的算法,即在渐变维度表上的多路并行查找算法和在不同粒度上聚合事实的算法,可以有效地解决数据仓库中海量事实数据的处理问题。通过实验结果表明,与Hive相比,MPLK-SCD算法和Agg-MPM算法,具有更高的处理效率,可以及时地为用户提供决策支持。下一步将研究事实的增量聚合和Merge阶段合并时选择并行性更高的工作流等问题。
[1] Inmon W H. Building the Data Warehouse[M]. Indianapolis, USA: Wiley, 2005: 33-43.
[2] 谭明金. 数据仓库工具箱: 维度建模的完全指南[M]. 北京:电子工业出版社, 2003.
[3] 王 欣. 基于分布式ETL的电子政务决策系统设计和实现[D]. 上海: 复旦大学, 2012.
[4] 徐艳华, 郭朝珍. 基于MAS的分布式ETL模型[J]. 郑州大学学报, 2007, 39(4): 118-121.
[5] Dean J, Ghemawat S. MapReduce: Simplified Data Processing on Large Clusters[C]//Proc. of the 6th Symposium on Operating System Design and Implementation. Berkeley, USA: [s. n.], 2004: 137-150.
[6] Ghemawat S, Gobioff H. The Google File System[C]//Proc. of the 19th ACM Symposium on Operating Systems Principles. New York, USA: ACM Press, 2003: 29- 43.
[7] White T. Cluster Specification Hadoop: The Definitive Guide[M]. [S. l.]: O’Reilly Media, 2009: 255-259.
[8] Wang Yuxiang, Song Aibo, Luo Junzhou. A MapReduce Merge-based Data Cube Construction Method[C]//Proc. of the 9th International Conference on Grid and Cloud Computing. Washington D. C., USA: IEEE Computer Society, 2010: 1-6.
[9] Liu Xiufeng, Thomsen C, Pedersen T B. CloudETL Scalable Dimensional ETL for Hadoop and Hive[D]. Aalborg, Denmark: Aalborg University, 2012.
[10] Miner D, Shook A. MapReduce Design Patterns[M]. [S. l.]:O’Reilly Media, 2013: 103-123.
[11] Yang H C, Dasdan A, Hsiao R L, et al. Map-Reduce-Merge Simplified Relational Data Processing on Large Clusters[C]// Proc. of ACM SIGMOD International Conference on Management of Data. New York, USA: ACM Press, 2007: 1029-1040.
[12] TPC-H. Homepage[EBOL]. [2013-05-07]. http://www.tpc.org/ tpch/default.asp.
编辑 索书志
Parallel Processing Algorithms for Facts Based on Hadoop Platform
SUN Li, HE Gang, LI Ji-yun
(School of Computer Science and Technology, Donghua University, Shanghai 201620, China)
In view of that traditional Extract, Transform, Load(ETL) tools face the efficient problem of the massive fact data in data warehouse, two algorithms about parallel processing facts are designed and implemented based on Hadoop platform. From the two perspectives of surrogate key lookup of fact table and aggregation for fact data on the different granularity, a multi-way parallel lookup algorithm on slowly changing dimensions and an algorithm of aggregation for fact data on the different granularity are presented. The first algorithm considers slowly changing dimensions and big dimensions synthetically. In order to solve the problem of out of memory, the algorithm adopts an approach to the distributed cache to copy small dimensions to every date nodes’ memory. And implementing multi-way lookup of dimension keys in the stage of map is to avoid network delay result from data transmission. The second algorithm adds merge stage after reducing stage, so it is beneficial to solve the aggregation problem of the fact data according to different granularity effectively. Experimental results show that the two algorithms have better efficient than Hive data warehouse with respect to the problem of parallel processing facts data in data warehouse.
MapReduce model; dimension; fact; surrogate key; parallel lookup; aggregation
1000-3428(2014)03-0059-04
A
TP311
孙 莉(1964-),女,副教授、博士,主研方向:数据库技术,面向对象分析与设计;何 刚,硕士研究生;李继云,副教授、博士。
2013-09-02
2013-10-25 E-mail:sli@dhu.edu.cn
10.3969/j.issn.1000-3428.2014.03.012
猜你喜欢
环球时报(2022-03-29)2022-03-29
北京大学学报(自然科学版)(2021年3期)2021-07-16
东北师大学报(自然科学版)(2021年1期)2021-03-27
电脑爱好者(2020年19期)2020-10-20
电子制作(2019年13期)2020-01-14
自然资源信息化(2019年4期)2019-03-29
知识经济·中国直销(2018年7期)2018-07-27
电子制作(2016年15期)2017-01-15
山东工业技术(2016年15期)2016-12-01
中国教育信息化(2015年10期)2015-08-23
