
基于数据挖掘技术的门诊合理用药分析
2014-05-31 01:41:10韩蓉吴俊
中国医疗设备 2014年4期
韩蓉,吴俊
南通市肿瘤医院 信息科,江苏 南通266000
0 前言
数据挖掘是指从大量的、不安全的、有噪声的、模糊的、随机的数据中提取隐含在其中人们未知的、但又具有潜在应用价值的数据,建立模型,提供给分析预测部门[1]。将数据挖掘技术应用于门诊合理用药分析的研究不仅有利于门诊用药信息结构化,促进门诊用药合理化研究,还有利于提示门诊用药与季节、科室、医保政策是否允许等多层关联属性的研究。近年来,国内将数据挖掘应用于医学、药学的研究越来越多,秦莉花等人[2]将其应用于绝经综合征焦虑、抑郁的相关因素的研究中;于红艳等人[3]将其应用于中药药性属性与其他属性的研究。临床上利用数据挖掘算法找出提高孤立性肺结节(solitary pulmonary nodul,SPN,一种肺癌的先兆病症)的诊断率[4];用数据挖掘方法来分析早期乳腺癌诊断的X光片,达到了比较满意的准确率(70%以上)[5]。大量研究证明,医学数据挖掘有广阔的应用前景[6]。
1 目的
遏制药品不当促销行为,控制药品费用不合理增长,使患者用上既安全又经济的药品一直是医院药事管理部门追求的目标,针对用药的不合理性,国内大部分医院的操作模式是从各个科室抽调负责人或技术骨干成立处方点评小组,由他们负责对门诊处方用药及配伍的合理性、用药规范性进行考核及点评。这样的手工模式效率低、误差高,而且有时因人为原因不能及时进行处方点评,导致问题不能及时发现。因此本文尝试将数据挖掘的方法应用于医院门诊用药的合理性分析,从海量的医疗数据中找出门诊各科室医生、处方金额、药品用量、是否医保政策允许范围药品等之间的关联规则,找出门诊用药可能存在的问题,及时指导、更正甚至处罚,真正做到减轻患者经济负担,解决人民群众“看病难、看病贵”问题。
2 方法
2.1 数据预分类
数据预处理主要目的是消除或减少数据噪声和处理缺失数据,尽量减少数据“不一致性”“不完整性”等干扰因素,提高数据质量[2]。针对本文挖掘的目的,我们将数据分成以下几大类:
(1)疾病诊断类。病史类中的属性是为了说明病人来院前和当时的病情状况及相关情况。这部分属性分疾病主诊断,疾病次诊断等。
(2)检查类。检查类中的属性主要是反映病人入院后所做检查的结果。该数据主要从病人的检验、体检和其他检查及病程记录中抽取,如:血压、脉搏、呼吸、血常规、大生化、凝血三项、超声、胸片等属性。该类属性大多会有多属性和多次检查值,因此要建立这些属性间的关联及属性值间的关联。
(3)用药类。该类中的属性主要反映病人在我院门诊开药的情况,药品单价、药品数量、药品金额、开单医生等。
(4)医保政策类。该类中的属性主要反映病人的参保类型,有自费、医保、农保等。
2.2 数据处理
对于抽取后存入数据库的原始数据不完整和不一致的采用填充空缺值、纠正非法值和纠正数据不一致性的方法进行处理。这部分主要是如何将数据转换成统一的格式,以适合数据的再处理。一般在海量的数据上进行复杂的数据分析和处理将花费很长的时间,甚至有时导致处理无法完成。而数据归约技术则可以得到小数集的归约表示,但仍能保持数据的完整性。
本文在研究过程中用到概念分层技术,主要涉及到的部分有开药的日期、疾病诊断、开药药品单价、开单医生、所属科室等。医保政策属性则被归约成医保政策允许与不允许两种。
维归约技术是通过删除不相关维来减少数据量的,属性子集的选择可以用基本子集的启发式方法,这种方法主要包括逐步向前选择、逐步向后删除、向前选择和向后删除的结合和判定的归纳技术。本文采用逐步向后的删除技术。
维归约技术涉及到的维有病人症状、病人病史、个人史、辅助检查、病人参保性质等。下面举例说明维归约技术在本文中的应用。
(1)医保政策是否允许(Sfzl)。门诊病人的医保属性有好多种,有农保、市区医保、县区医保等,我们就将其归约为医保政策允许与不允许。
(2)药品处方金额(Jined)。处方金额设定≥300元即为大处方,用d表示,反之用j1表示。
(3)开药日期(yf)。这部分数据是以月份形式表示的,所以我们根据医院专家的建议将其开药时间分为4段,即0~3月为1段,4~6月为2段,7~9月为3段,10~12月为4段,也就是春夏秋冬四季,这样划分的意义在于,评估病人用药的多少是否和季节有关。
(4)药品单价(ypdjd)。根据抽取的数据,最小金额为1.12元,最大金额为2596元。所以将其划分为0~50元、50~100元、100~150元、150~200元等几部分,分别用b1、b2、b3、b4、b5、b6 表示。
(5)药品数量(shuld)。根据抽取的数据,最小药品数量为1支(粒),最大为1~10支(粒)、10~20支(粒)、20~30 支(粒)、30~40支(粒),40~50 支(粒)、50~100 支(粒),分别用 a、b、c、d、e、f表示。
(6)医生科室(ksdm)。因为在数据库中抽取的科室代码均为数值型,我们将这些代码均用字母代替,如 93、141、83、175、84、81 用 字 母 表 示 为 a、b、c、d、f、g。映射后得到的部分属性数据库,见表1。
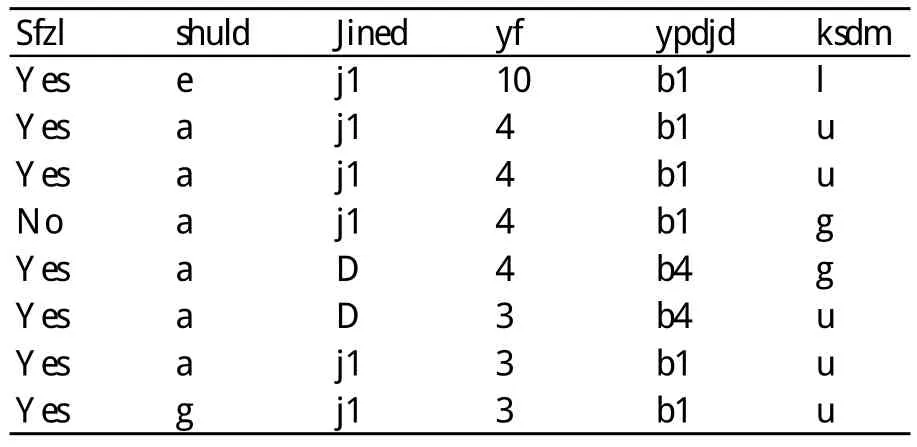
表1 映射后的部分属性数据库
3 关联规则挖掘与结果分析
根据研究目的的数据源数据属性特点,本文采用关联规则方法,关联规则就是从事务数据库、关系数据库和其他信息存储中的大量数据的项集之间发现有趣的、频繁出现的模式关联和相关性。若2个或多个变量的取值之间存在某种规律,就称为关联。关联规则[7]是R.Agrawal等人于1993年首先提出的。关联规则的挖掘过程:
找出所有的频繁项集,即找出所有那些支持度大于事先给定的最小支持度的项集。由频繁项集产生强关联规则:这种规则必须同时满足最小支持度和最小置信度。对每一频繁项目集A,找到A的所有非空子集a,如果比率support(A)/support(a)≥min_conf,就生成关联规则a≥(A-a)。support(A)/support(a)即规则a≥(A-a)的置信度。即此过程分为两个步骤,第一步找出频繁项集,第二步再从频繁项集中找出置信度,或者说满足置信度的关联规则。这些既满足置信度,又满足支持度的关联规则,就是强关联规则,也就是我们挖掘的结果。
收集2012年某三甲医院门诊用药信息,采用自主开发的软件经过抽取、清理、转换数据、最终装载入数据库,分析是否存在大处方的可能性,给定最小支持率minsup=0.1,最小置信度minconf=0.7,挖掘出74条关联规则,这些关联规则中有意义的部分及其最小支持度与最小可信度,见表2。
根据这些规则我们可以分析得出大处方存在的可能性,是否是医保政策允许范围的病人等。从表2可以看出,如果是医保政策允许的病人则其处方金额≥300元,药品单价<50元的可能性为81%,支持度为0.190752;同时我们也发现如果药品数量<10且科室代码为l(经查为妇科),则不是医保政策允许范围的病人且开的药品单价<50元的小处方的可能性为91%,支持度为0.168519。
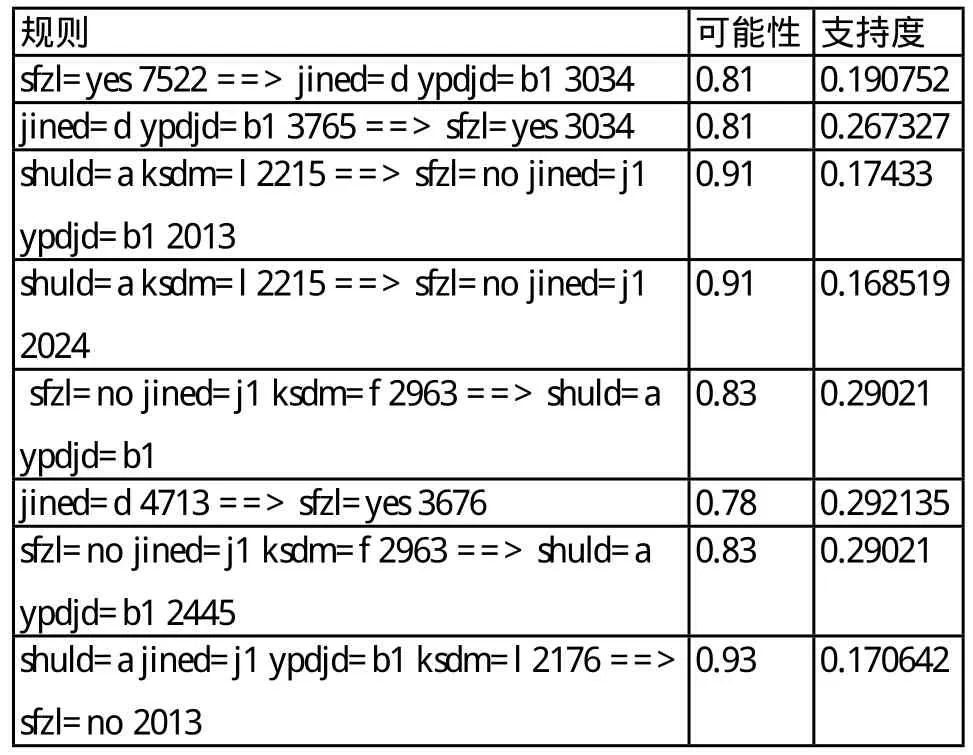
表2 有意义的关联规则(minsup=0.1,minconf=0.7)
经过挖掘实例演示分析发现:关联规则与输入的参数有很大的关系,输入的参数值不同,产生的关联规则也不同,有时甚至产生大量模糊的关联规则。同时若数据源选取的不同,也是会产生不同的关联规则。
经过评估,数据挖掘阶段发现出来的模式可能满足用户的需求,也可能不满足。这就需要管理员在不断完善挖掘过程中积累的经验,对挖掘模型的参数进行调整,以达到更好的挖掘效果。
因为用户在挖掘过程中也可能存在冗余或无关的模式,这时则需要整个发现过程回退到前一阶段,如需要用户重新选择数据源,设定新的参数值,直到达到用户满意为止。
挖掘结果应用:① 门诊有大处方存在,但是药品单价并不高,而且一般是医保政策允许范围的病人,药事管理部门就此情况在医生处得到证实,这种情况比较普遍,因为参保病人(医保政策允许范围的病人)认为医保帐户上的款项取不出来,自己开药也就顺带帮家人开些药;② 分析看出,如果是自费病人(非医保政策允许的病人),存在大处方的可能性很小;③ 我们还发现,该院妇科医生开的处方一般性价比较高,金额都比较小。所以整体来说该院2012年全年门诊用药情况还算良好。
4 结论
本文采用自主开发的软件抽取、清理、转换数据、装载入库,通过设定最小支持度,最小可信度,挖掘出有意义的关联规则,对这些规则分析解释得出的结与门诊科室真实情况大体一致,证明了关联规则挖掘在门诊合理用药分析中的有效性。这些结论为药事管理部门分析门诊用药合理性提供了重要的依据,得到药事管理部门的认可与好评。随着数据库、人工智能等新技术的发展,在数据挖掘技术应用于医学领域必会有很多知识发现[8],本文只是提供了一个用数据挖掘来指导门诊用药合理性分析的一种方法,下一步将尝试其他合理用药的分析研究,以后还会进一步尝试将关联规则的挖掘方法应药理分析、抗菌素等其他合理用药分析中。
[1]崔园.数据挖掘在中文病历分类中的应用[J].计算机与数字工程,2011,(3):160-163.
[2]秦莉花,陈晓阳.基于数据挖掘的绝经综合征焦虑、抑郁的相关因素研究分析[J].时珍国医国药,2013,24(6):1431-1432.
[3]于红艳.许成刚关联挖掘技术在中药药性及其他属性间关系的应用研究[J].中国实验方剂学杂志,2013,19(14):343-346.
[4]Rakesh Agrawal,Tomasz Imielinski,Arun Swami.Data Mining:Medical and Engineering Case Studies[A].Proceedings of thd ILE Research 2000 conference[C].Cleveland, OH,May 2000:1-7.
[5]翟爱珍,庄人戈.计算机辅助医学诊断系统的数据挖掘和知识发现研究[J].国外医学生物医学工程分册,2002, 25 (3):97-103.
[6]蒋仪,陈辉,管晓福,等.浅谈抗菌药物信息系统建设[J].中国医疗设备,2013,28(10)64-66.
[7]A kusiak,KH Kernstine,JA kern,et al.Database mining:A Performance Perspecetive[J].IEEE Transactions.on Knowledge and Data Engineering,1993,Vol.5:914-925.
[8]童元元,霍刚.数据挖掘技术在中药研究中的应用进展[J].中华中医药学刊,2010,(5):1067-1069.
猜你喜欢
中国医院院长(2022年6期)2022-04-27 02:22:50
大众投资指南(2021年35期)2021-02-16 01:06:26
当代陕西(2019年15期)2019-09-02 01:52:00
学苑创造·A版(2018年11期)2018-02-01 06:29:20
电力与能源(2017年6期)2017-05-14 06:19:37
读者(2017年5期)2017-02-15 18:04:18
学生天地·小学低年级版(2016年4期)2016-11-19 08:41:24
学生天地·小学低年级版(2016年9期)2016-05-14 15:59:39
学生天地·小学低年级版(2016年8期)2016-05-14 15:59:38
信息通信技术(2015年6期)2015-12-26 01:16:46
