
中文微博热点话题挖掘研究
2014-05-12 10:22:54帅马恋
统计与信息论坛 2014年6期
何 跃,帅马恋,冯 韵
(四川大学 商学院,四川 成都 610064)
中文微博热点话题挖掘研究
何 跃,帅马恋,冯 韵
(四川大学 商学院,四川 成都 610064)
微博热点话题代表公众对现实生活问题的态度,对微博热点话题的识别有益于网络舆情监控。基于话题检测与跟踪技术设计出中文微博热点话题识别流程。首先通过K-means文本聚类归纳出话题,然后进行话题影响力计算和分析,最后通过话题影响力大小识别热点话题。实证结果表明,热点话题的“召回率”较高,影响力较大。话题影响力的构建为相关企业或政府针对话题热度大小采取不同的舆情监测策略提供了理论依据。
微博;话题影响力;话题检测与跟踪
一、引 言
微博已经成为公众信息传播的主要网络平台之一,微博上的热点话题也代表了众多网民关注的热点。掌握微博热点话题,对政府舆情监测与引导和企业制定营销策略都具有十分重要的意义。
微博起源于国外,作为近年来最热门的互联网应用,相关研究逐步增加。从目前相关研究文献来看,与微博相关的基础性研究较为普遍,如微博(特别是twitter)的内容特点、技术特点、使用微博的原因或社会目的等,同时,网络信息爆炸式增长和网络舆情分析的需求也使网络热点话题研究在国外受到广泛关注。目前具有针对性地利用网络信息进行的研究主要包括两类:一类是Web数据挖掘研究,另一类是利用话题检测与跟踪(Topic Detection and Tracking,TDT)技术进行热点话题识别与跟踪研究[1-2]。TDT技术已逐渐成为当前信息处理领域的研究热点。该项技术中涉及许多算法与模型的运用,因此相关算法及模型的优化也成为研究热点,如Changki Lee等针对TDT技术中unigram和bigram语言模型的弱点,提出了结构依赖语言模型[3]。
随着国内学术界对大量网络信息利用价值认识的逐步加深,关于网络热点话题识别与发现的研究也逐渐丰富,如从BBS挖掘热点话题、从Blog上发现热点话题、网页舆情观点挖掘等,但基于微博平台的热点话题研究比较少。孙胜平结合现有的普通网页的TDT技术,重点研究了适用于中文微博的网页采集、信息抽取、热点话题检测以及话题跟踪技术,侧重研究了相关技术与算法,并对每一种技术通过实验进行测评,但对热点话题的识别缺少系统研究[4]。杨冠超结合微博平台上的时间序列和文本特点提出话题热度预测模型TopicRank,通过划分时间片,结合话题的关键词集对话题在连续时间段内的影响力进行计算,从而预测话题在未来一段时间内的影响力变化趋势,但该研究是在定性的基础上先判断出热点话题后再去跟踪,并对话题的未来热度进行预测,略显不够严谨[5]。赵前东等也通过构建话题活性模型以寻找热点话题,后期也通过TDT进行效果验证,但是在数据预处理中采用正则表达式,略显客观性不足,且不能自动化处理[6]。可见,TDT技术被引入到微博研究中已成趋势,但现有研究主要针对某些相关技术进行研究或改进,是在热点话题已出现的基础上再利用TDT技术对热点话题进行热度分析。本文试图通过TDT技术对微博话题进行热度分析,挖掘出潜在的热点话题。
本文借鉴TDT技术,结合中文微博的特点,设计出一种较为简易的热点话题发现与分析流程。首先通过文本聚类找出话题,再结合用户行为对微博热度的影响提出衡量话题热度的热点话题影响力,最后通过TDT技术中的效果检验标准来衡量话题影响力对话题热度衡量的有效性。这不仅为热点话题的识别提供了科学依据,还为后续热点话题的深度分析与趋势预测提供了支撑。
二、相关理论
(一)话题检测与跟踪技术
TDT作为一种主题检索技术,其特点主要在于关注与特定事件主题相关的数据。传统的检索技术是从内容来检索、确定文档的分类,而TDT技术是基于事件,利用分析文档与事件主题联系来获取特定主题信息,它从来源数据流中自动发现主题并把与主题相关的内容联系在一起。TDT的研究任务主要包括五部分:对新闻广播等报道进行切分(报道切分),检测未知话题(话题检测),跟踪已知话题(话题跟踪),检测未知话题首次相关报道(首次报道检测)以及检测报道间相关性(报道关联性检测)[7]。
(二)中文分词及词性标注
中文分词就是将汉字序列切分成有意义的词,以字为单位,句和段则通过标点等分隔符来划界。目前主流的中文分词算法分为四类:基于字符串匹配的分词,基于理解的分词,基于统计和基于语义的分词[8]。
词性标注是根据句子上下文环境给句中的每个词标记一个正确的词性,主要是机器针对多标记词(即有多种词性的词)和未登录词(即在训练语料中未出现的词)标记词性。词性标注技术与分词技术一样,在自然语言处理、机器翻译、文本自动检索及分类、文字识别、语音识别等实际应用中占有重要地位[5]。目前比较典型的标注算法归纳起来有:基于规则的方法,基于统计的方法,规则与统计相结合的方法。本文选用的是规则与统计相结合的方法。
(三)向量空间模型
向量空间模型(Vector Space Model,VSM)是一个应用于信息过滤、信息撷取、索引评估相关性的代数模型,文本分析对象通常是以词为单位的VSM数据[9]。运用这个模型把文本表示为向量,就可以将文本处理简化为向量空间中的向量运算。当文档转化为向量时,文档中每个词对应向量的每个特征项维度,所有文档中的词所对应的维度构成了整个空间,而特征权重则是每个词对应每一维的取值,于是,一个文档Dj转化为特征向量可表示为:
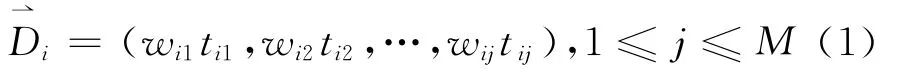
其中tij是特征项,wij是特征权重,M是文本tij中的特征项总数。另外,文本中作为特征项的词不能重复,即各特征项tij互异,且文本的内部结构不需要考虑,因此特征项tij无先后顺序。
(三)K-means文本聚类
K-means算法以欧式距离作为相似性的评价指标,即认为两个对象的距离越近,其相似度就越大,得到紧凑且独立的簇是聚类的最终目标。K-means算法中距离的计算公式如下:
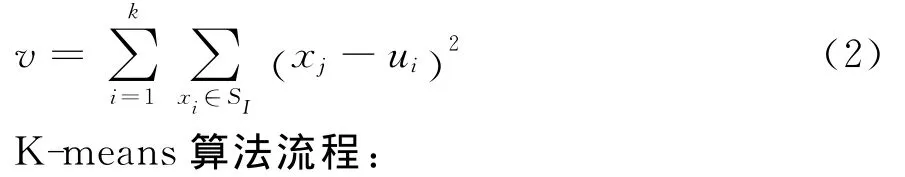
第一步,从数据对象中任意选择K个对象(K值需要预先设定)作为初始聚类中心。第二步,计算剩下的对象与这些聚类中心的相似度(距离),并分别将它们分配给最相似的(聚类中心所代表的)类。第三步,重新计算每个新类的聚类中心(该聚类中所有对象的均值)。第四步,不断重复第二、三步,直到标准测度函数开始收敛为止,一般采用均方差作为标准测度函数。
该算法在处理大数据集时是相对高效和可伸缩的,计算的复杂度为O (Nkt),其中N是数据对象的数目,t是迭代的次数(一般K≤N,t≤N,同时算法对顺序不太敏感,因此较适合对VSM表示的文本集进行聚类。本文聚类效果的验证采用类平均相似度,公式为:
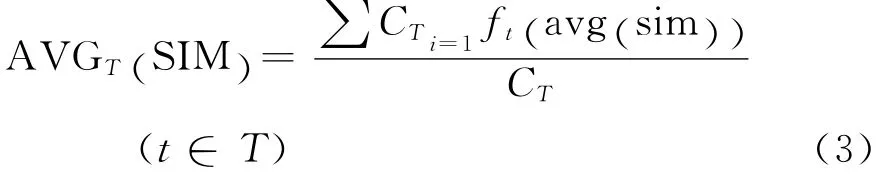
其中AVGT(SIM)表示类T的平均相似度;CT表示类T所包含的微博条数;ft(avg(si m ) )表示类T中单条微博文t的个体平均相似度,即t与类T中其余微博文的相似程度之和取平均值。将类中所有微博文的个体平均相似度之和取一次平均值,从而得到类的平均相似度。
三、研究设计
(一)识别流程
本文基于TDT技术设计出中文微博热点话题识别流程,主要环节如图1所示。

图1 中文微博热点话题识别流程图
首先通过微博爬虫系统获取所需的数据,如微博内容、评论数、转发数、受众数等;接着从获取数据中提取话题识别的数据源,利用中文分词处理过滤数据;对预处理后的微博内容中的每个特征词,利用特征词权值计算方法TF-IDF(Term Frequency–Inverse Document Frequency)计算特征权重并建立向量空间模型,再利用K-means文本聚类来归纳出多个话题;最后对多个话题的影响力进行计算并分析,通过效果验证识别出热点话题。
(二)热点判定——话题影响力设计
本文基于微博特点和话题本身,提出热度的判定因素——话题影响力。微博热点话题影响力为该话题中单条相关微博内容的影响力总和,单条微博内容的影响力又分为直接影响力和间接影响力。由于用户发表的微博文直接呈现给关注该用户的受众,因此单条微博的直接影响力与该条微博发布用户的关注人数(受众数)相关[10]。本文此处只考虑微博评论数与第一层的转发数。定义话题影响力相关计算公式如下:

其中Inf()T为话题T的影响力;n为该类中与话题相关的微博条数;Inf()t为单条相关微博内容t的影响力。一个话题的影响力为话题中所包含的所有相关微博内容影响力之和。

其中InfD()t为单条相关微博内容t的直接影响力;InfI()t为单条相关微博内容t的间接影响力。单条微博的影响力为直接影响力与间接影响力之和。话题T的影响力为:


其中comments为微博t的评论条数,retweets为微博t的直接转发次数,系数α>0,β>0,α+β=1。微博被评论一次仅表明该条微博对评论者有所影响,而转发一次后,该条微博的影响将会扩散,转发对微博影响力有放大效应,因此一般情况下β>α,具体参数值可运用经验或专家打分等手段来确定。
四、实证分析
本文实验数据随机选取了2011年12月8日到2011年12月14日这7天内的微博数据,通过新浪微博API接口共爬取微博内容2 103条。根据研究设计的热点话题挖掘流程,对该周内新浪微博热点话题挖掘进行实证研究。
(一)数据预处理
首先对微博内容进行文本预处理,即进行去重、分词、无效信息过滤、降维等操作。实验中使用C#版本的中科院ICTCLAS中文分词系统对微博文本进行分词处理,同时标注词性,并过滤微博内容,保留名词及名词性词语,然后将所有的单字过滤,再去除所有的英文字符、数字和一系列数学符号等非中文词,只留下有意义的中文词语。图2为关于“2012年伦敦奥运会期间英国女王出租宫殿套间”话题文本示例。

图2 词性过滤后的文本图
(二)话题识别
文本预处理后,针对每条微博内容,利用特征词权值计算方法TF-IDF计算各个单词权重,以构成一个向量空间模型用于聚类。实验中,K值在最大值范围内通过多次实验结果验证来选取。经过多次试验,最终将该周的微博内容聚为10类,并对各类进行类关键词提取,结果如表1所示。

表1 类关键词提取结果表
以上10类中,所提取的关键词具有较强实时性的有6个,关键词所包含信息较为日常的类有4个。此时若设置类平均相似度阈值为0.01,则恰好包含较强实时信息的6个类别。将类平均相似度高于阈值且包含较强实时信息的类定义为一个话题,则从微博内容中发现话题数目为6个,分别为类3、4、6、7、8、10。
(三)话题影响力排序
大多关于热点发现的算法认为,在聚类后出现的热点词频率较高,则该话题即为热点话题。这种原理是基于热点词与话题的附属关系,但却忽略了当话题较分散的情况下聚类也能进行,同时在聚类结果中,可能有些话题只是局部较热的小话题,整体来讲算不上热度很高[11],因此可以设置一个阈值来区分话题冷热,话题热度(本文中以话题影响力来衡量)高于阈值则表示聚类出来的话题为“热点话题”,低于阈值则视为“非热点话题”。热点与非热点的概念是相对的,因此也可以根据话题影响力公式计算出每个话题的热度,然后按照热度分数排序,分数越高表示话题影响力越大,热度越高。
实验中,挖掘热点话题的数据来源时间段Δh为2011年12月8日至2011年12月14日。由于实验中发现话题的总数较少,故本实验不以预先设定话题影响力阈值来划分“热点”与“非热点”,只将话题按影响力大小排序,即设定所发现话题均为热度不同的热点话题。
根据话题影响力相关计算公式(4)~(8),计算得到实验中所提取的6个话题在当前时段的影响力评分及排名,如表2所示。考虑到微博转发会使微博的影响扩散,相对于评论其影响力更大,因此公式(8)中α取值为0.4,β取值为0.6。

表2 话题影响力及排位表
从以上分析结果可以看出,在实验识别出的2011年12月8日到2011年12月14日的6个话题中,影响力从大到小依次是江苏丰县校车事故、南京大屠杀纪念日、韩国海警被刺事件、电影《金陵十三钗》即将上映、广东陆丰乌坎村群体事件、双子座流星雨爆发。
(四)效果验证
话题识别与跟踪的效果一般使用准确率和召回率两个参数来衡量,公式如下:

其中A表示已提取出的与话题相关内容,B表示已提取出的与话题不相关内容,C表示未提取出的与话题相关内容。在全部文本数据中,与话题相关的数目为A+C,而被判定与话题相关的数目为A+B。
召回率和精度是不可能两全其美。当召回率较高时,精度反而降低;反之精度高时,召回率就会有所降低。因此,本文用这两个度量值融合而成的一个度量值F来衡量这个效果。F值公式如下:

实验以“召回率”、“准确率”验证热点话题发现效果,根据公式(9)、(10)、(11)计算出每个话题的召回率与准确率,如表3所示。
从表3可以看出,6个热点话题召回率从高到低依次为:韩国海警被刺事件,江苏丰县校车事故,南京大屠杀周年纪念,双子座流星雨,陆丰乌坎村群体事件,电影《金陵十三钗》话题,各类话题召回率均较高。相反,各类话题准确率均较低,最高为双子座流星雨,仅为0.769,最低为广东陆丰群体事件,仅为0.641。聚类准确率低与微博内容零散、谈论话题范围极其广泛有关,即话题聚类时噪声数据太多,导致β值较大。实验表明微博热点话题发现的“召回率”较高而准确率较低,这与微博内容的不规范性、随意性等特点有关。从综合衡量召回率和准确率的F值来看,热点识别取得了良好的效果。尽管微博内容存在一定的不规范和随意性,但从实证分析中可以看到,聚类所选取出的6类热点话题F值均保持在0.75以上。

表3 热点话题识别效果验证表
五、结论
本文借鉴TDT技术,设计了一套中文微博热点话题挖掘流程,并利用一段时间内的少量新浪微博数据进行热点发掘实证研究。该流程可以使微博站点外部用户利用少量微博数据便能挖掘微博热点,以满足其监控舆情或发现商机的需要。本文主要的创新工作有以下两点:
第一,将识别热点话题的主流技术TDT运用于中文微博平台,同时还在流程设计中结合了中文微博的特性。
第二,微博平台往往以单一的微博数量指标来衡量话题热度,而本文则提出了以话题影响力的大小来评判话题热度。
由于新浪爬虫程序爬取的数据有限,因而本文仅限于对能收集到的数据进行研究,实证结果难免有一定的局限。另外,微博内容较杂乱,噪声信息较多,话题聚类效果也有待提高,因此相关聚类算法的改进也是未来研究的方向。话题影响力验证方法还需完善,后期可以对热点话题进行动态跟踪,以发现热点话题的整体趋势变化 。
[1] Kuo-Jui Wu,Meng-Chang Chen,Yeali Sun.Automatic Topics Discovery From Hyperlinked Documents[J].Information Processing and Management,2004,40(2).
[2] Aurora Pons-Porrata,Rafael Berlanga-Llavori,Jose Ruiz-Shulcloper.Topic Discovery Based on Text Mining Techniques[J].Information Processing and Management,2007,43(3).
[3] Changki Lee,Gary Geunbae Lee,Myunggil Jang.Dependency Structure Language Model for Topic Detection and Tracking[J].Information Processing and Management,2007,43(5).
[4] 孙胜平.中文微博客热点话题检测与跟踪技术研究[D].北京:北京交通大学硕士学位论文,2011.
[5] 杨冠超.微博热点话题发现策略研究[D].杭州:浙江大学硕士学位论文,2011.
[6] 赵前东,叶猛.微博热点话题检测系统的设计与实现[J].电视技术,2013,37(3).
[7] 洪宇,张宇,刘挺,李生.话题检测与跟踪的测评及研究综述[J].中文信息学报,2007,21(6).
[8] 张启宇,朱玲,张雅萍.中文分词算法研究综述[J].情报探索,2008(11).
[9] 薛薇,陈欢歌.文本聚类中罚多项混合模型的特征选择及其在互联网舆情分析中的应用[J].统计与信息论坛,2012,27(1).
[10]Gaonkar S,Choudhury R R.Micro-blog:Map-casting from Mobile Phones to Virtual Sensor Maps [Z].Sydney,Australia,2007.
[11]程军军,刘云.基于新闻评论的热点话题发现系统研究[J].网际网路技术学,2008,9(5).
Research on Chinese Micro-Blogging Hot Topic Mining
HE Yue,SHUAI Ma-lian,FENG Yun
(Business School,Sichuan University,Chengdu 610064,China)
Micro-blogging hot topic represents the public attitude to the problems of real life,and the recognition of the micro-blogging hot topic is beneficial to monitor of network public sentiment.The paper based on Topic Detection and Tracking(Topic Detection and Tracking,TDT)designs the recognition path of Chinese micro-blogging hot topic,which analysis extracted micro-blogging hot topic by impact of topic to identify the hot topic.The result shows that according to the size of the impact of hot topics of the experimental period,the ranking list is confirmed well by the evaluation of TDT.The topic influence building provides a theoretical basis for relevant enterprises or government to take a different control strategy of public opinion for the topic of heat size.
micro-blogging,impact of topic,TDT
G203
A
1007-3116(2014)06-0086-05
2013-11-18
何 跃,男,重庆人,教授,管理科学与工程博士,研究方向:宏观经济,数据挖掘,信息管理与决策;
帅马恋,女,湖南醴陵人,硕士生,研究方向:数据挖掘,信息管理与信息系统;
冯 韵,女,四川巴中人,硕士生,研究方向:数据挖掘,信息管理与信息系统。
(责任编辑:杜一哲)
猜你喜欢
智富时代(2019年6期)2019-07-24 10:33:16
NBA特刊(2018年14期)2018-08-13 08:51:40
作文通讯·高中版(2017年6期)2017-07-10 03:21:34
人大建设(2017年11期)2017-04-20 08:22:49
高中生·天天向上(2016年9期)2016-11-22 09:10:34
网络空间安全(2016年3期)2016-06-15 20:27:07
瞭望东方周刊(2015年12期)2015-04-14 23:28:02
人间(2015年21期)2015-03-11 15:24:39
中国有色金属(2014年23期)2014-03-13 02:10:27
计算机工程(2014年6期)2014-02-28 01:28:00
