
融合全局灰度模板的改进CT算法
2014-04-03 07:34李广三杨大为
计算机工程与应用 2014年18期
李广三,杨大为,王 琰
LI Guangsan,YANG Dawei,WANG Yan
沈阳理工大学 信息科学与工程学院,沈阳 110159
School of Information Science and Engineering,Shenyang Ligong University,Shenyang 110159,China
1 引言
目标跟踪是指在视频图像序列中估计被跟踪目标的时间状态序列(包括位置、方向、尺度大小等)。目标跟踪在计算机视觉领域(视频索引、安全监控、人机交互等)中发挥着重要作用。最近几十年已经出现了一些在现实中应用广泛的目标跟踪算法。在目标跟踪过程中,光照变化、运动模糊、部分遮挡等情况会导致目标发生明显的表观变化,这使得维持目标跟踪算法的鲁棒性成为一个难题[1-2]。
目标跟踪算法通常至少包括表观模型和运动模型两个部分。在任意一帧图像中,通常使用目标的某个或某些特征构建该目标的表观模型,在随后的跟踪过程中使用这个表观模型表示该目标。然后,在下一帧图像中,使用运动模型得到目标所有的预测样本,利用表观模型从众多预测样本中挑选一个预测样本作为跟踪结果。在目标跟踪算法中,表观模型是非常关键的部分。
构建表观模型至少要考虑两个因素。第一,使用什么特征来表示目标。目标一般包含多种特征,例如灰度[3-4]、颜色、纹理、HOG特征、Haar特征[5-6]等等。同时,根据提取特征的区域,还可以分成全局特征和局部特征。全局特征对于目标和背景都是清晰明白的,特别适用于判别模型[7]。局部特征能够有效处理部分遮挡问题[3]。第二,如何利用表观模型从众多预测样本中选择一个预测样本作为跟踪结果。根据选择方法,可以把表观模型分为生成模型和判别模型。利用运动模型提取众多预测样本,将目标的表观模型和预测样本的表观模型依次比较,选择两者表观模型最相似的预测样本作为跟踪结果,这就是生成模型[3-4,8-9]。利用运动模型提取众多正负样本和预测样本,利用正负样本的表观模型构建分类器,选择分类器分数最大的预测样本作为跟踪结果,这就是判别模型[5,10-13]。两者各有优缺点,判别模型实时性更好,生成模型鲁棒性更好。为了充分利用生成模型和判别模型各自的优势,已经出现了结合使用生成模型和判别模型的目标跟踪算法[7,14-15]。
Compressive Tracking(CT)算法[12]是一种判别跟踪算法,它使用矩形窗口表示跟踪结果,窗口内的像素大部分来自目标,小部分来自背景。当在窗口中提取稀疏局部Haar-like特征时,背景中的像素会影响算法的鲁棒性。无论是对于目标还是对于背景,全局模板都是清晰明白的,因此更适用于判别模型。为了提高CT算法的鲁棒性,本文提出了一种融合全局灰度模板的改进CT算法。首先构建一个稀疏Haar-like特征表观模型M1,然后构建一个全局灰度直方图表观模型M2,将M1和M2这两种表观模型结合起来用于跟踪算法。实验表明融合全局灰度模板的改进CT算法与CT算法相比,提高了鲁棒性,减轻了漂移问题。
2 融合全局灰度模板的改进算法
本文算法在构建表观模型时使用了稀疏Haar-like特征和归一化灰度直方图特征。
在构建稀疏Haar-like特征表观模型M1时,首先利用一个矩阵R在窗口中随机提取稀疏Haar-like特征,其公式如下:

其中 R∈ℜn×m(n<<m)是基于压缩感知理论[6,9]构建的一个非常稀疏的随机投影矩阵,X∈ℜm×1是窗口列向量,V∈ℜn×1为窗口列向量经过R投影之后的Haar-like特征列向量。矩阵R的定义方法直接关系到表观模型的性能,文献[12]中的矩阵R定义如下:

其中s等概率在2、3、4中随机选取。本文算法中详细的稀疏Haar-like特征提取公式如下:

其中 Haari,k表示在某个窗口中提取第i组Haar-like特征时所提取到的第 k个Haar-like特征,i=1,2,…,50,k=1、2、3、4。由公式(3)可知窗口的稀疏Haar-like特征就是s个矩形窗口的积分图像的加权之和,如图1所示。
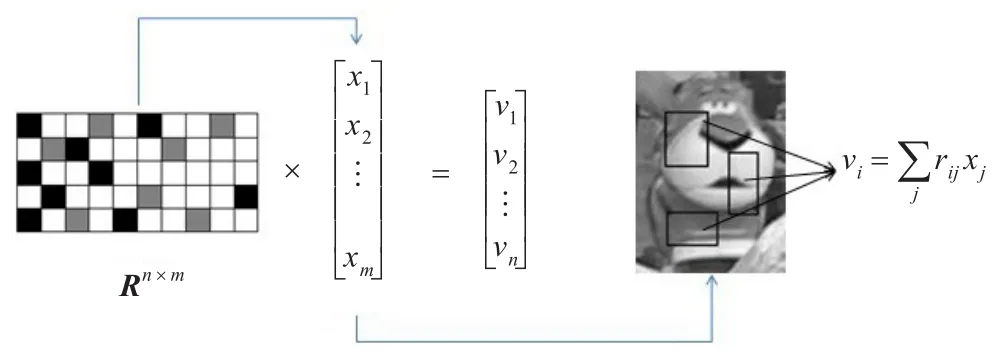
图1 稀疏Haar-like特征提取示意图
在构建稀疏Haar-like表观模型M1的过程中,本文算法使用的运动模型是密集抽样方法,并且假设使用矩阵R提取的稀疏Haar-like特征相互独立并满足高斯分布,于是可用高斯分布密度函数来衡量图像样本的分布。
在构建全局灰度直方图表观模型M2时使用归一化灰度直方图特征,这里仍然使用M1模型中的正负样本和预测样本,首先计算t时刻跟踪目标的归一化灰度直方图特征historigin、t+1时刻预测样本的归一化灰度直方图特征histall,使用historigin和histall之间的巴氏距离来衡量预测样本和跟踪目标的相似度。本文算法流程如下:
输入 视频序列中第t帧图像、跟踪目标位置Lt。
步骤1在输入视频序列的第t帧图像中已知跟踪目标位置Lt。Lt包含4个元素,分别是窗口左上角的x坐标、y坐标、窗口的宽度w、高度h。计算Lt对应窗口的归一化灰度直方图特征historigin。
步骤2在Lt周围一个圆形区域内基于公式(4)提取正样本若干:

对Dα中的正样本使用矩阵R提取Haar-like特征。求出所有正样本的均值和方差,分别记为μ1和σ1。
步骤3在Lt周围一个环形区域内基于公式(5)提取负样本若干:
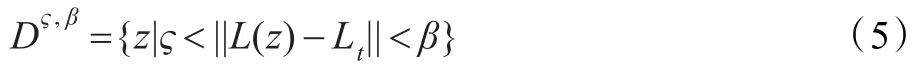
其中 α<ς<β。对 Dς,β中的负样本使用矩阵 R提取Haar-like特征。求出所有负样本的均值和方差,分别记为 μ0和 σ0。
步骤4在输入视频序列的第t+1帧图像中,在Lt周围一个圆形区域内基于公式(6)提取预测样本:

对Dγ中的预测样本使用矩阵 R提取Haar-like特征。使用矩阵x表示预测样本的Haar-like特征。对每个预测样本求归一化灰度直方图特征histall。
步骤5利用正样本的均值μ1和方差σ1、负样本的均值 μ0和方差σ0构建预测样本的高斯分布函数 p(vi|y=1)和 p(vi|y=0),公式分别如下:
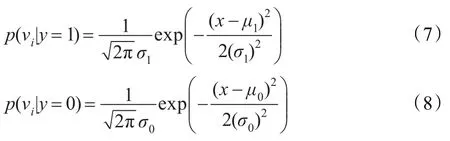
步骤6利用朴素贝叶斯准则求出衡量预测样本与跟踪目标相似度的第一个标准H(v),计算公式如下:
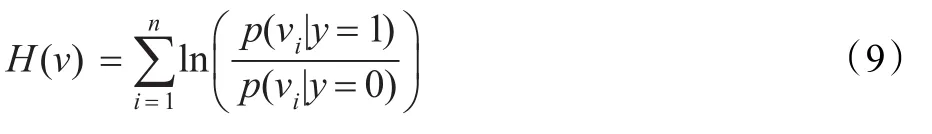
步骤7计算histall和historigin之间的巴氏距离HD,把它作为衡量预测样本与跟踪目标相似度的第二个标准,公式如下:
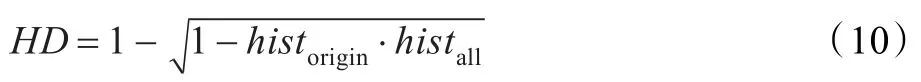
步骤8在选择预测样本时,综合考虑预测样本在模型M1中的H(v)值以及在模型M2的HD值,把这两个值的乘积Hdv作为衡量预测样本和跟踪目标相似度的最终标准,计算公式如下:

步骤9在输入视频序列的第t+1帧图像中,重复步骤2、3,根据公式(12)、(13)更新公式(7)、(8)的参数。

式中φ是一个学习参数,表示稀疏Haar-like表观模型更新的程度。
步骤10重复步骤1~9。
输出 跟踪位置Lt+1、分类器参数。
3 实验结果及分析
实验中对本文算法、CT算法进行了比较。两种算法对David视频序列和sylv视频序列进行跟踪的部分结果分别为图2、图3,其中,实线框代表CT算法的跟踪结果,虚线框代表本文算法的跟踪结果。David视频序列和sylv视频序列的跟踪误差曲线分别为图4和图5,实线表示CT算法,点线表示本文算法。
CT算法简单、实时性好,但是在提取局部Haar-like特征时,有可能会提取背景中的Haar-like特征,导致算法鲁棒性降低。本文算法在CT算法的基础上,增加了一个全局灰度模板,所构建的表观模型更加具有判别能力,在一定程度上缓解了跟踪结果的漂移。在David视频序列中第69帧、第101帧、第175帧、第241帧、第297帧、第358帧图像,在sylv视频序列中第56帧、第144帧、第223帧、第297帧、第365帧、第430帧图像,可以看到本文算法的跟踪结果比CT算法鲁棒性提高了。

图2 对David视频序列的跟踪结果(第69、101、175、241、297、358帧)

图3 对sylv视频序列的跟踪结果(第56、144、223、297、365、430帧)

图4 David视频序列的跟踪误差曲线图
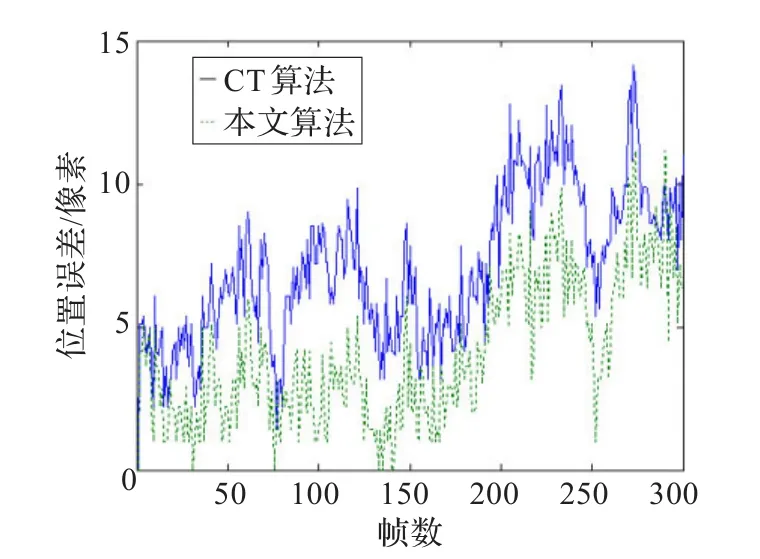
图5 sylv视频序列的跟踪误差曲线图
4 结束语
针对文献中CT算法的不足和全局灰度模板在判别跟踪算法中的优点,提出一个增加全局灰度模板的改进CT算法。在构建表观模型时,首先使用局部稀疏Haar-like特征构建一个表观模型M1,然后使用全局归一化灰度直方图特征构建一个表观模型M2,把M1和M2共同用于跟踪算法。对不同视频序列的实验结果表明,改进CT算法提高了鲁棒性,减轻了漂移问题。但是,全局灰度模板的引入必然会降低算法的实时性。如何更好地解决这个问题是本文后续研究的重点。
[1]Yilmaz A,Javed O,Shah M.Object tracking:a survey[J].ACM Computing Survey,2006,38(4):1-45.
[2]郭岩松,杨爱萍,侯正信,等.压缩感知目标跟踪[J].计算机工程与应用,2011,47(32):4-6.
[3]Adam A,Rivlin E,Shimshoni I.Robust fragments-based tracking using the integral histogram[C]//IEEE International Conference on Computer Vision and Pattern Recognition,2006.
[4]Ross D,Lim J,Lin R S,et al.Incremental learning for robust visual tracking[J].International Journal of Computer Vision,2008,77(1/3):125-141.
[5]Grabner H,Grabner M,Bischof H.Real-time tracking via online boosting[C]//British Machine Vision Conference,2006:47-56.
[6]Wrigh J T,Yang A Y,Ganesh A,et al.Robust face recognition via sparse representation[J].IEEE Trans on Pattern Analysis and Machine Intelligence,2009,31(2):210-227.
[7]Zhong Wei,Lu Huchuan,Yang M H.Robust object tracking via sparsity-based collaborative model[C]//IEEE International Conference on Computer Vision and Pattern Recognition,2012.
[8]Mei X,Ling H.Robust visual tracking using L1 minimization[C]//IEEE International Conferenceon Computer Vision,2009.
[9]Li H,Shen C,Shi Q.Real-time visual tracking using compressive sensing[C]//IEEE International Conference on Computer Vision and Pattern Recognition,2011:1305-1312.
[10]Avidan S.Ensemble tracking[J].IEEE Trans on Pattern Analysis and Machine Intelligence,2007,29(2):261-271.
[11]Babenko B,Yang M H,Belongie S.Visual tracking with online multiple instance learning[C]//IEEE International Conference on Computer Vision and Pattern Recognition,2009.
[12]Zhang K,Zhang L,Yang M H.Real-time compressive tracking[C]//European Confernece on Computer Vision,2012.
[13]朱秋平,颜佳.基于压缩感知的多特征实时跟踪[J].光学精密工程,2013,21(2):438-444.
[14]Yu Q,Dinh T B,Medioni G G.Online tracking and reacquisition using co-trained generative and discriminative trackers[C]//European Conference on Computer Vision,2008.
[15]Santner J,Leistner C,Saffari A,et al.PROST:Parallel Robust Online Simple Tracking[C]//IEEE International Conference on Computer Vision and Pattern Recognition,2010.
猜你喜欢
数学物理学报(2022年4期)2022-08-22
北京航空航天大学学报(2022年6期)2022-07-02
数学物理学报(2022年2期)2022-04-26
河北果树(2021年4期)2021-12-02
高技术通讯(2021年3期)2021-06-09
上海公路(2019年3期)2019-11-25
福建基础教育研究(2019年10期)2019-05-28
金桥(2018年4期)2018-09-26
自动化学报(2017年5期)2017-05-14
光学精密工程(2016年1期)2016-11-07
