
多通道助听器语音降噪算法研究
2014-04-03 07:32:24梁瑞宇王国伟仇晓梅马安骏
计算机工程与应用 2014年11期
奚 吉,梁瑞宇,王国伟,仇晓梅,马安骏
XI Ji1,LIANG Ruiyu2,WANG Guowei2,QIU Xiaomei2,MAAnjun2
1.常州工学院 计算机信息工程学院,江苏 常州 213002
2.南京工程学院 通信工程学院,南京 211167
1.School of Computer Information and Engineering,Changzhou Institute of Technology,Changzhou,Jiangsu 213002,China
2.School of Communication Engineering,Nanjing Institute of Technology,Nanjing 211167,China
改善噪声环境下的语音理解度,一直是助听器性能提高的瓶颈。研究表明,在限定的背景噪声下,听障患者要达到正常人的理解水平的前提是将语音信号提高大约30 dB[1]。由于环境噪声的复杂性,以及其可能与语音存在的强相关性,使得提高噪声环境下听障患者的语音理解度存在很多挑战。
目前,改善方法主要有两类:方向性麦克风和语音降噪算法[2]。前者是基于语音和噪声在空间上的差异性设计,利用方向性麦克风或波束形成技术来增强特点方向上的语音信号。但是此类方法受麦克风的数量或尺寸限制,性能改善有限,而且不适用于深耳道助听器。第二种方法旨在利用语音和噪声的时间和频谱上的差异,将语音从含噪信号中分离出来。但是,语音和噪声可能在时间和频谱上存在重叠,因此很多学者针对这个问题进行了深入研究。
在助听器降噪算法中,常采用多通道降噪策略,即在噪声占优时减小频道的噪声干扰。目前,语音降噪算法主要有谱减法、维纳滤波法[3-4]、子空间法[5]、听觉掩蔽法[6]等。但是谱减法虽然实现简单,容易产生音乐噪声;子空间法的计算量大。而维纳滤波算法采用短时谱估计算法削弱子带信号,即使期望信号和噪声覆盖相同的频率域。为此,本文在维纳滤波研究的基础上,提出一种多通道助听器语音降噪算法。
算法首先结合人耳听觉特性和助听器响度补偿的特点,将语音信号进行Gammatone分解为多路子带信号。然后在每个子带内用基于先验信噪比估计的维纳滤波器进行语音增强处理。最后通过综合子带信号,得到增强的语音。此外,为了改善维纳滤波算法噪声谱估计的问题,本文提出一种基于包络估计的语音活动检测算法,并用于改善维纳滤波性能。实验表明,与传统维纳滤波法相比,该方法能更有效地抑制残留噪声,提高语音可懂度,具有较高的实用价值。
1 多通道滤波器分解
耳蜗基底膜上每个部位的最大位移都具有频率选择性,耳蜗的部位-频率特异性在整个听觉系统中都有所体现。这种频率选择性通常由一组基于等效矩形带宽(Equivalent Rectangular Band,ERB)刻度的伽马通滤波器实现。伽马通滤波器模拟基底膜不同部位最大位移处的响应。n阶伽马通滤波器的时域表示如式(1)所示。

这里ϕ代表相位,b代表带宽,n是滤波器阶数,f为中心频率。仿真实验选择n为4,因为此时伽马通滤波器的幅度特征与人耳听觉滤波器形状更匹配[7]。本文中滤波器的路数选择基于两点考虑:(1)等响度补偿算法是助听器的常用算法之一[8],因此多通道语音分解是助听器的基本操作,所以该算法可和等响度补偿算法相结合。(2)虽然滤波器分解的路数越多越能符合人耳的特性,更能细致地计算不同频率对算法性能的影响,效果更佳。但是,路数的增加同时意味着计算量的增加,而助听器受体积的限制,其功率和内存有限。目前新声公司的瑞翼系列已可做到128路的滤波处理,因此本文选用24路滤波器组进行研究,存在集成到现有的助听器算法中的可能。
根据Moore的论述,人耳听觉滤波器的中心频率只覆盖50~15 000 Hz(对应ERB尺度范围为1.8~38.8)的频率范围。但是,受信号采样频率限制,本研究所需的中心频率在50 Hz到8 000 Hz之间(采样频率16 000 Hz)。
2 子带维纳滤波
2.1 维纳滤波算法的基本原理
对于第m帧带噪语音信号:

式中sm(n)是第m帧纯净语音信号,nm(n)为第m帧噪声信号,维纳滤波器就是在最小均方误差准则(MSE)下实现对语音信号sm(n)的估计。在sm(n)与nm(n)不相关且均为平稳随机过程条件下,对式(2)进行离散傅里叶变换,得:
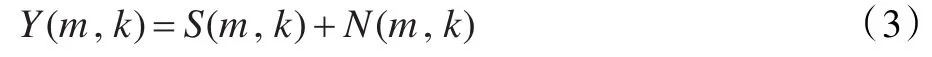
设维纳滤波的频域响应函数为G(m,k),则最佳估计ŝm(n)的傅里叶变换为 Ŝ(m,k):
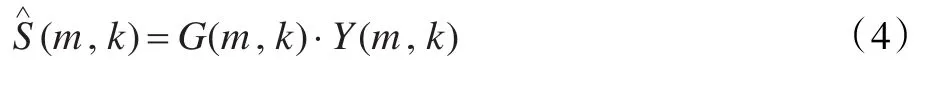
以Ŝ(m,k)与S(m,k)的最小均方误差为准则,可得:
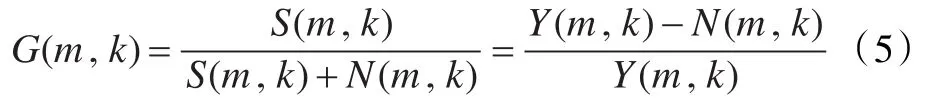
由上式可知,Y(m,k)为带噪信号的FFT变换,可直接求得。因此,维纳滤波的关键在于获得对噪声功率N(m,k)的准确估计值N^(m,k)。
2.2 改进的子带噪声估计算法
在维纳滤波语音增强算法中,需要估计当前帧的噪声功率谱,经典的算法是通过计算无声期间的统计平均来估计噪声功率谱。这种算法存在两个问题:(1)在噪声环境下,尤其是低信噪比情况下,无声检测的效率低,从而使噪声估计出现偏差;(2)没有考虑噪声的功率谱在发声期间的变化。
为了解决上述问题,在维纳滤波算法基础上,本文提出了一种改进的算法,包括:(1)提出一种基于包络估计的VAD算法,提高无声段检测效率,并估计当前帧的信噪比,实时调整系统参数;(2)在传统的估计噪声功率谱的方法基础上,结合每帧带噪语音功率谱推导当前帧的噪声功率谱;(3)提出基于估计信噪比的维纳滤波频响参数调整算法。
算法步骤与实现如下:
(1)对带噪语音进行端点检测确定语音起始帧。一般情况下,语音段信噪比要比噪声段的信噪比要高。因此本文提出一种基于信号调制率的VAD算法,通过计算信号调整率,计算信号信噪比,并根据信噪比变化判断语音是否开始。具体方法如下:
①变换子带输入信号 ym(n)到dB域:ydBm(n)=20lg(abs(ym(n)))。
②平滑 ydBm(n),求波形包络VS:VS(n)=τS·VS(n-1)+(1- τS)·ydBm(n)。
③采用最小值追踪法估计噪声包络VN:

④估计信噪比Snr(n)=VS(n)-VN(n)。
⑤无声段的判断:取前10帧的信噪比作为阈值,信噪比大于此阈值的信号段为语音段。
(2)标记语音段的起始时刻,通过计算语音段前的无声期间统计平均的噪声方差作为噪声功率谱的初值。
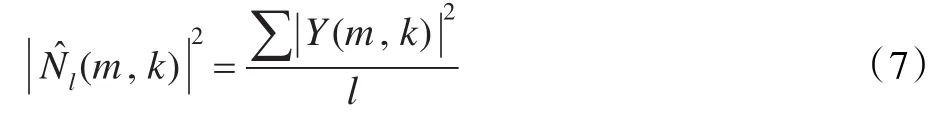
(3)计算每帧语音出现的概率 f(m,k):
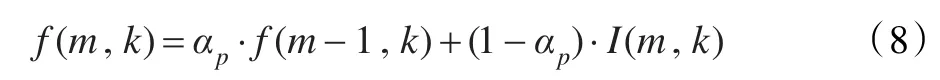
式中,I(m,k)为静音标记函数。该帧信号为静音时,I(m,k)为0;否则为1。αp为语音出现的概率系数。
(4)实时估计当前帧的噪声功率谱:

此处,第一帧噪声功率谱按式计算获得。而α=a+b·αp,其系数a和b可根据信噪比进行实时更新。
3 实验结果及分析
3.1 VAD算法比较实验
对于维纳滤波算法来说,VAD算法是基础。本文比较了传统的基于信号能量的算法和本文提出的算法。实验语音为一段英文,内容为“I wish I could”。因为,在高信噪比情况下,VAD检测的效果都比较好,因此实验选用的信噪比为-10 dB。实验结果如图1所示。
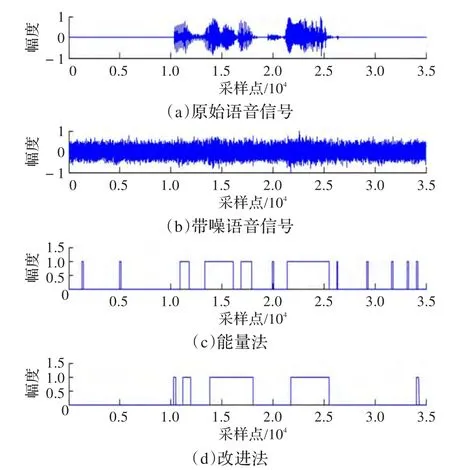
图1 静音检测算法比较
从图1可以看出,在低信噪比情况下,从带噪语音信号中几乎没法识别出语音信号。因此,基于能量法的静音检测算法存在很大偏差,而且在非语音段存在很多虚假语音段。相比来说,本文提出的方法的静音检测效果较好,除了“I could”中的“I”没有检测到外,但是少了很多虚假检测。因此,该算法能改善噪声谱估计效果,有助于提高维纳滤波算法性能。
3.2 语音客观性能比较
利用Matlab对本文提出的语音增强方法进行测试,并与传统维纳滤波算法和基于先验信噪比估计的维纳滤波算法[9]进行对比。实验语音为录制的一段语音,噪声选自NOISEX-92噪声库中的白噪声、闹市声和驱逐舰引擎噪声,在输入信噪比为-10 dB、0 dB、10 dB下分别测试。实验中语音信号的采样率为8 kHz,帧长为256点,帧移50%。
客观评价指标包含对数似然率(Log-Likelihood Ratio,LLR)、信噪比(Signal to Noise Ratio,SNR)、加权谱倾斜测度(Weighted-Slope Spectral distance,WSS)和语音质量的感知评价值(Perceptual Evaluation of Speech Quality,PESQ)四个指标[10]。原始语音的各项指标分别为0(LLR),无穷(SNR),0(WSS)和4.5(PESQ),由此可知LLR和WSS指标的数值是越小越好,而另两种指标的数值是越大越好。
从表1可知,本文提出的方法相比于其他两种方法,四种性能指标都较为优越。如相比于传统的维纳滤波算法来说,四种指标的改善程度为-0.36,7.67,-41.13和0.48,而相比于基于先验SNR的维纳滤波算法,四种指标的改善程度为-0.34,6.68,-40.15和0.35。而三种噪声类型中,提出的算法的四种指标差别不大,其中闹市声的LLR和SNR指标最佳,白噪声的WSS指标最佳,而驱逐舰引擎声的PESQ指标最佳。而随着信噪比的降低,系统的各项指标都有所降低,这符合实际情况。
3.3 语音主观性能比较
为了确定客观性能评估,进行了主观评价。语音信号选自汉语普通话词库,分别通过三种算法进行降噪处理。在平均意见得分(Mean Opinion Score,MOS)测试中选用20位试听者,要求试听者根据自己的认可度从1~5给出每种测试语音的印象得分,从而得到三种算法的平均意见得分。
从图2可知看出,本文提出算法的主观评价性能比其他两种算法都好,且随着信噪比的提高,MOS的值越来越高。由于在低信噪比下,其他两种算法的静音检测算法不准确,从而影响了算法的噪声估计性能,也影响了语音质量。而本文的算法由于改善了静音检测性能,且综合考虑语音帧和噪声帧来实时评估噪声帧,从而有效地抑制了残留噪声,减少了语音的听觉失真,所以提高了语音的可懂度。
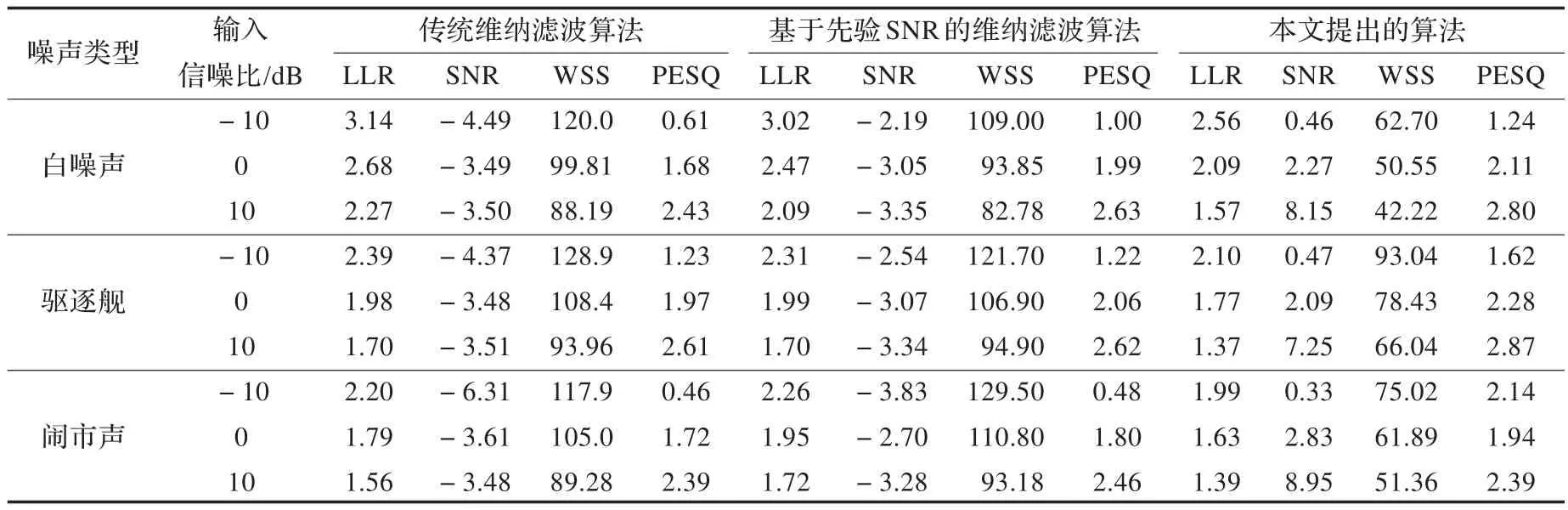
表1 降噪算法客观评价指标对比
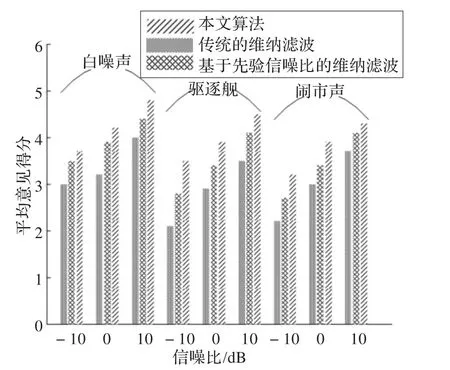
图2 算法主观性能比较
4 结语
本文提出一种改进的多通道维纳滤波算法的助听器语音降噪算法。首先结合人耳听觉特性和助听器响度补偿的特点,将语音信号进行Gammatone分解为多路子带信号。然后在每个子带内用基于先验信噪比估计的维纳滤波器进行语音增强处理。最后通过综合子带信号,得到增强的语音。此外,为了改善维纳滤波算法噪声谱估计的问题,本文提出一种基于包络估计的语音活动检测算法,并用于改善维纳滤波性能。实验表明,与传统维纳滤波法相比,该方法能更有效地抑制残留噪声,提高语音可懂度,具有较高的实用价值。算法能有效地抑制残留噪声,对语音增强有较好的效果,能提高听力损伤患者的语音可懂度。
[1]Edwards B.The future of hearing aid technology[J].Trends in Amplification,2007,11(1):31-46.
[2]Chung K.Challenges and recent developments in hearing aids.Part I.Speech understanding in noise,microphone technologies and noise reduction algorithms[J].Trends in Amplification,2004,8(3):83-124.
[3]Van Den Bogaert T,Doclo S,Wouters J,et al.Speech enhancement with multichannel Wiener filter techniques in multimicrophone binaural hearing aids[J].The Journal of the Acoustical Society of America,2009,125(1):360-371.
[4]Klasen T J,Den Bogaert T,Moonen M,et al.Binaural noise reduction algorithms for hearing aids that preserve interaural time delay cues[J].IEEE Transactions on Signal Processing,2007,55(4):1579-1585.
[5]Sarradj E.A fast signal subspace approach for the determination of absolute levels from phased microphone array measurements[J].Journal of Sound and Vibration,2010,329(9):1553-1569.
[6]Hamacher V,Chalupper J,Eggers J,et al.Signal processing in high-end hearing aids:state of the art,challenges,and future trends[J].Eurasip Journal on Applied Signal Processing,2005,18:2915-2929.
[7]Wrigley S N,Brown G J.A computational model of auditory selective attention[J].IEEE Transactions on Neural Networks,2004,15(5):1151-1163.
[8]王青云,赵力,赵立业,等.一种数字助听器多通道响度补偿方法[J].电子与信息学报,2009,31(4):832-835.
[9]张亮,龚卫国.一种改进的维纳滤波语音增强算法[J].计算机工程与应用,2010,46(26):126-131.
[10]Wojcicki K,Milacic M,Stark A,et al.Exploiting conjugate symmetry of the short-time Fourier spectrum for speech enhancement[J].IEEE Signal Processing Letters,2008,15:461-464.
猜你喜欢
空间电子技术(2021年4期)2021-11-10 07:06:04
中老年保健(2021年7期)2021-08-22 07:40:58
电子制作(2019年22期)2020-01-14 03:16:24
舰船电子对抗(2019年4期)2019-09-10 02:05:08
太原科技大学学报(2019年3期)2019-08-05 01:18:20
计算机应用与软件(2017年3期)2017-04-14 00:59:00
洛阳师范学院学报(2017年2期)2017-03-12 00:41:44
小布老虎(2016年12期)2016-12-01 05:47:08
发明与创新(2016年26期)2016-08-22 03:23:28
系统工程与电子技术(2016年2期)2016-04-16 05:16:50
