
动态云模型大规模数据挖掘算法
2014-03-26 07:33:00黄取治
长春工业大学学报 2014年3期
黄取治
(福建师范大学信息技术学院,福建福州 350007)
0 引 言
云计算的发展为互联网的发展提供了新的机遇,它有效地降低了企业在IT设备上的成本投入,提高了企业的工作效率。数据挖掘是从大量数据中找到需要、有用数据中有的过程。数据挖掘从统计学上可以认为,是通过计算机对大量的复杂数据集的自动分析。数据挖掘是为了确定数据的模式,它需要对观察到的数据库进行处理。数据挖掘涉及对数据库管理、人工智能、模式识别以及数据可视化等内容。
1 云计算和数据挖掘简介
云计算是一种新的计算模型,它可以将计算任务用分布式技术通过大量互连的计算机协同工作,从而得到需要的计算资源和其它服务信息。云计算为互联网时代海量数据的处理和分析提供了高效的平台。云计算可以将海量数据分解为同样大小的信息并且进行分布存储,然后利用MapReduce等模型进行编程,这种技术已经在搜索引擎中得到了广泛的应用并且取得了良好的效果[1]。用云计算的方式来进行数据挖掘,主要是由于数据挖掘所面临的数据是海量的,在云技术出现以前都希望由高性能机或者是大规模的计算设备来完成,但是计算机服务器的功能总是有限的。同时,在海量数据的挖掘中还有比较特殊的要求,这对数据挖掘的开发环境和应用环境提出了新的要求,而云计算的方式能够有效满足数据挖掘的特殊需要。
数据挖掘是从大量的数据中挖掘出有用的信息,来满足人们的特定需要。有专家预测随着互联网时代数据的不断积累和计算机的普及,数据挖掘将在我国形成一个新的高科技产业。数据挖掘使数据库技术进入到了一个新的发展阶段,它不仅能够实现对数据的查询,而且能够找到数据之间的联系,从而促进信息的应用和传递。数据挖掘能够实现真正的按需服务,用户可以根据自己的需求选择相应的服务模式。基于云计算的数据挖掘计算的一般过程如图1所示。
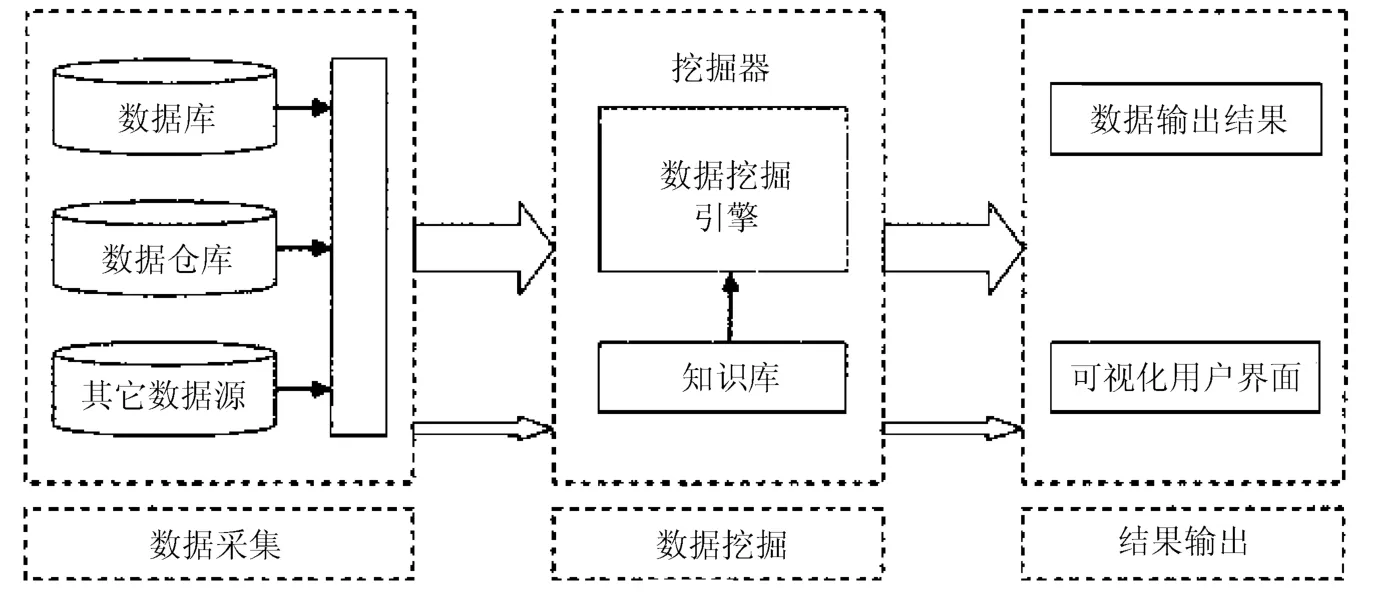
图1 云计算数据挖掘计算过程
2 云计算和数据挖掘之间的关系分析
云计算是一种基于互联网的的计算模式,其计算过程、计算能力、交互能力等功能是一个动态、虚拟化的过程[2]。云计算的动态和可伸缩的计算能力为数据挖掘技术的实现带来了可能性,云计算环境为新的数据挖掘方法的研究提供了新的环境,云计算也使面向大众的数据挖掘成为了可能。同时,云计算的发展也离不开数据挖掘的支持,在基于云计算的搜索中就包含了网页存储、搜索处理等内容。数据挖掘在搜索服务中具有广泛应用,在网页存储中网页去重、搜索处理中网页排序等,其中每项服务的实现都需要数据挖掘技术来提供支持[3]。
新型的数据挖掘技术包括了面向异构数据、同构数据和跨域数据等不同的数据挖掘方法,在同构海量数据挖掘方法中,节点所存储的数据都具有同样的属性。云计算平台采用集成学习的方式来完成预测分析,并且在同构节点的基础上实现了数据挖掘的增量学习方法,从而满足了实时性的要求。在异构数据挖掘技术中,云计算平台能够根据数据的模态将数据进行分类,并提供数据相关性度量和集成。同时数据挖掘技术还存在特殊性的应用,而云计算平台能够为海量数据的迁移挖掘提供方法上的支持,这不仅扩大了云计算环境下数据挖掘应用的范围,同时也更好地满足了数据挖掘用户的需要。
3 数据挖掘算法研究
树型机构是一种非线性的结构,在数据库的信息组织中得到了广泛的应用。1986年,Quinlan提出了数据网挖掘的ID3算法,然后Quinlan在ID3算法的基础上又提出了C4.5算法。同时为了满足海量数据处理的需要,又提出了一系列的改进的算法,其中SLIQ和SPRINT是比较有代表性的两个算法[4]。
ID3算法是一种分类预测算法,其核心是信息熵,信息上是一种数据所包含的信息。一组无序数据的信息熵越高,那么其熵也就越大。分类预测法可以对目标数据进行分级处理,具体表现在构建决策树的过程中。通过生成决策树并且按照相应的规则来判断数据。ID3算法用信息增益作为属性的选择标准,ID3算法在工作中需要检测所有数据的属性,然后将信息增益最大的属性来作为决策树的结点。信息增益作为判断属性的标准,通过计算每个属性的信息增益,然后比较它们的大小,就能够得到最大信息增益的属性。可以假设S是包含了s个数据样本的集合,其中类标号属性有m个不同值,定义为m个不同类Ci(i=1,2,…,m),其中假设si是类Ci中的样本数量。假设属性A具有v个不同的值,其集合为{a1,a2,…,av}。用属性A将S划分为v个不同的子集{S1,S2,…,Sv},其中Sj中的样本表示在属性A上具有同样的值aj(j=1,2,…,v),设sij是子集Sj中Ci的样本数量。C4.5算法延续了ID3算法的优点,并且对ID3算法进行了优化改进。用信息增益率来选择属性,避免了利用信息增益过程中属性不足的现象。在构建树的过程中进行了剪枝处理,并且对连续属性的离散化处理。C4.5算法具有独特的优点,其分类规则更容易被理解,而且准确率也比较高。但是其缺点也比较明显,需要对数据集进行多次排序,因此在数据挖掘的过程中其算法的效率比较低。C4.5在一些驻留内存的数据集中应用比较广泛,当数据集在内存无法容纳时程序就难以有效地运行[5]。
SLIQ算法对C4.5分类算法进行了有效的改进,在决策树的构造过程中采用了预排序和广度优先策略两种技术来对数据的采集进行优化。在C4.5算法中预排序是在连续属性内部结点中寻找最优分裂标准时,对训练集按属性值的大小进行排序,而排序则需要一定的时间等待。为了提高数据采集的效率,SLIQ算法应用了预排序技术。预排序是通过对每个属性进行取值,并且把所记录的数据属性值按照从小到大的顺序进行排序,从而避免在决策树建立的过程中对每个结点数据集进行排序而花费大量额外的时间。在实际的操作时需要根据训练数据集的属性来创建针对性的属性列表,同时根据类别的属性创建相应的类别列表。在C4.5算法中树的构造是根据深度的优先来进行的,在具体的工作时需要对每个属性列表的结点都进行扫描,需要花费大量的时间。为了提高数据挖掘的效率,SLIQ算法采用了广度优先的方法来构建决策树,在决策树的每一层上只需要对属性列表扫描一次就可以为决策树中的每个结点找到最佳的分裂标准[6]。
Bayes法是一种在已知先验概率与类条件概率的情况下的模式分类方法,待分样本的分类结果取决于各类域中样本的全体。设训练样本集分为M类,记为C={c1,…,ci,…cM},每类的先验概率为P(ci),i=1,2,…,M。当样本集非常大时,可以认为P(ci)=ci类样本数/总样本数。对于一个待分样本X,其归于cj类的类条件概率是P(X/ci),则根据Bayes定理,可得到cj类的后验概率P(ci/X):
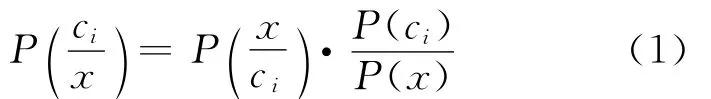
若
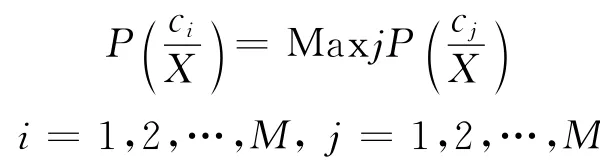
则

式(2)是最大后验概率判决准则,将式(1)代入式(2),则有,若
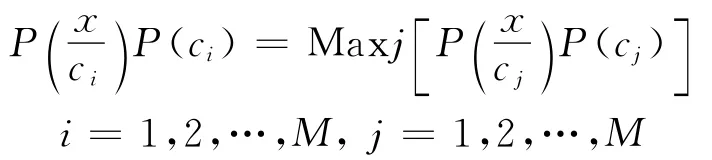
则
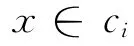
这就是常用到的Bayes分类判决准则。经过长期的研究,Bayes分类方法在理论上论证得比较充分,在应用上也是非常广泛的。Bayes方法的薄弱环节在于实际情况下,类别总体的概率分布和各类样本的概率分布函数(或密度函数)常常是不知道的。为了获得它们,就要求样本足够大。另外,Bayes法要求表达文本的主题词相互独立,这样的条件在实际文本中一般很难满足,因此,该方法往往在效果上难以达到理论上的最大值。
为了减少内存中的数据量,SPRINT算法又对决策树中的算法数据结构进行了进一步的改进,SPRINT算法改变了SLIQ算法中保存在内存中的类别列表,将类别列表合并到了属性列表中。这样在扫描属性列表寻找结点的最佳分裂标准时,不需要参考其它的信息就可以将结点的分裂划归到属性列表中进行分裂,将每一个属性列表分成两个分别存放各个结点的记录。SPRINT算法使寻找每个结点的最佳分裂标准变得更简单,但是也存在着对非分裂属性列表进行分裂时比较困难[7]。为了改变这种缺点,在对分裂属性进行分裂时,可以用哈希表记录属于某个属性的结点,如果内存能够容下整个哈希表,那么其它不同的属性列表的分裂可以只参照哈希表。哈希表的大小和训练集的大小成正比,当训练集很大时,哈希表仍然可能完成保存在内存中,这种情况下分裂只能进行分批进行,这说明了SPRINT算法的可伸缩性仍然需要继续改进。
基于云计算的并行数据挖掘服务模式是将同一个算法分布到不同的多个节点上,这些算法在工作的过程中是并行的、互不干扰的,而且计算资源能够进行按需分配。分布式计算采用了云计算的模式,而数据挖掘的关键就是实现数据挖掘算法的并行化。云计算采用MapReduce等新的计算模型,所以现有的数据挖掘算法和并行化不能直接应用到云计算平台上,它需要经过一系列的改造才能满足数据挖掘的要求。因此在云计算的模式下,需要研究数据挖掘算法的并行化策略,从而实现云计算平台下的并行数据挖掘算法。并行数据挖掘算法包括并行分类算法和并行聚类算法等,能够进行数据分类或者预测,以及数据总结、聚类、异常和趋势发现等。通过借助并行处理技术,在基于数据挖掘算法的特点上对云计算模型进行优化,使其能够更加满足数据挖掘的需要。分布式计算是解决数据挖掘任务的需要,它能够有效地提高数据挖掘的效率。分布式数据挖掘技术主要有基于网格的分布式数据挖掘、基于云的分布式数据挖掘等,同时数据挖掘一个核心问题是实现数据挖掘算法的并行化[8]。
在利用云计算进行数据挖掘时需要选择恰当的算法,不是所有的算法都能够满足数据挖掘的策略。通过选择合适的算法,并且应用相应的并行办法才能有效地提高数据挖掘的效率。在数据挖掘中存在着很多不确定性,所以在应用数据挖掘算法的过程中,应当注意不确定性所带来的消极影响。数据挖掘任务存在着比较大的不确定性,数据的预处理和采集也存在非常多的不确定性,数据挖掘方法和结果也存在比较大的不确定性,所以要快速找到需要的数据信息[9]。在利用云计算进行数据挖掘时还需要对评价的结果进行评价,用户的需求不同评价的目标也不同,所以导致了对挖掘结果评价的不确定性。同时在云计算环境下进行数据挖掘,对于云服务软件的可信度也比较重要,例如其服务是否正确或者恰当,对隐私数据的保护等,都是数据挖掘所关注的内容。数据挖掘的算法和模型应当保持一致性,这样才能保证数据挖掘结果的正确性。
4 结 语
通过云计算的海量数据存储和分布计算,为云计算环境下的数据挖掘提供了新方法和手段,有效解决了海量数据挖掘的分布存储和高效计算问题。通过开展基于云计算特点的数据挖掘算法的研究,可以为更多、更复杂的数据挖掘提供新的应用平台。通过云计算满足了数据挖掘的个性化和多样性的需要,同时由于数据的多样性,如高维的、动态的数据,都需要云计算技术来实现。
[1] 郭鑫,颜一鸣,徐洪智,等.动态云平台下的快速闭树聚类并行算法[J].计算机工程,2013(9):80-83.
[2] 郭鑫,李云,黄云,等.最小闭树特征集的聚类与分类方法[J].计算机应用,2010,30(2):423-426,448.
[3] 郭鑫,颜一鸣.一种动态云模型下树数据挖掘算法[J].小型微型计算机系统,2013,34(12):2749-2752.
[4] 宋晶.基于云模型和粗糙集的分类挖掘方法研究[D]:[硕士学位论文].成都:西南交通大学,2007.
[5] 迟庆云.基于决策树的分类算法研究和应用[D]:[硕士学位论文].济南:山东师范大学,2005.
[6] 黄华.基于大云数据快速挖掘过程的研究与仿真[J].计算机仿真,2013,30(4):386-389.
[7] 宛婉,周国祥.基于并行抽样的海量数据关联挖掘算法[J].合肥工业大学学报:自然科学版,2013,36(8):933-937.
[8] 程苗.基于云计算的用户浏览偏爱路径挖掘算法[J].计算机工程与应用,2011,47(29):85-89.
[9] 陈湘涛,张超,韩茜.基于Hadoop的并行共享决策树挖掘算法研究[J].计算机科学,2013,47(11):258-259.
猜你喜欢
小学生学习指导(高年级)(2024年4期)2024-05-07 03:28:46
北京航空航天大学学报(2022年8期)2022-08-31 08:58:18
小学生学习指导(中年级)(2021年4期)2021-04-27 10:14:56
课堂内外(初中版)(2020年5期)2020-06-19 08:11:11
当代陕西(2019年14期)2019-08-26 09:42:00
数学物理学报(2018年1期)2018-03-26 08:16:42
中学数学杂志(初中版)(2016年5期)2016-11-01 09:00:33
华东师范大学学报(自然科学版)(2014年3期)2014-03-11 16:18:15
电子设计工程(2014年12期)2014-02-27 11:58:23
测绘科学与工程(2014年2期)2014-02-27 07:05:49
