
Hadoop云计算框架中的分布式数据库HBase研究
2014-03-25 01:18王静蕾
商丘职业技术学院学报 2014年2期
王静蕾
(郑州旅游职业学院,河南 郑州 450000)
1 Hadoop概述
Hadoop 是一个能够对海量数据分布式处理的平台,其中,包括软件和众多子项目,它是用 Java 语言实现的,而Java 是一个可移植性很高的语言.因此, Hadoop可以部署到非常广泛的机器上,低成本和前所未有的高扩展性是它被广泛采用的原因之一.Hadoop系统的原理是在计算机集群上利用简单编程模型处理大数据集.它的专长是海量数据的存储和处理,它的优点在于将本地计算与本地存储结合,在运行时不用移动数据而只需移动计算,这样既简化了管理又节省带宽和开销,同时还提升计算的可靠性.
Hadoop 系统共包括4个核心模块: Hadoop Common、Hadoop Distributed FileSystem(HDFS)即Hadoop 分布式文件系统、Hadoop YARN 以及 Hadoop Mapreduce(并行计算框架).其中HDFS是Hadoop的最底层的文件系统,它存储了Hadoop 集群中所有存储节点上的文件数据,是其他项目实现的基础.
2 分布式文件系统HDFS 的系统架构
分布式文件系统HDFS的理念是实现高度容错性和高扩展性,可以部署在低廉的硬件上.HDFS 内部的所有通信都基于标准的 TCP/IP 协议.因此,数据传输率较高,适合有超大数据集的应用程序.HDFS包含2种数据节点,一是用来管理文件系统命名空间的元数据节点(NameNode),它将所有的文件和文件夹的元数据保存在一个文件系统树中,作为辅助NameNode从元数据节点(secondaryNameNode),用于周期性将NameNode的命名空间镜像文件和修改日志合并,可以防止日志文件过大;二是数据节点(DataNode),用来存储数据文件.当前HDFS包含2层结构:一层:Namespace 管理目录,它支持常见的如创建文件,修改文件,删除文件等文件系统操作.二层:Block Storage ,这一层有2部分组成,一是Block Management维护集群中NameNode的基本关系,它支持数据块相关的操作,如:创建数据块,删除数据块等,同时,它也会管理副本的复制和存放.二是Physical 存储实际的数据块并提供针对数据块的读写服务.Block Storage的这2部分分别在NameNode和DataNode上实现,所以,该模块由这2种节点分工完成.
如图1所示,图中NameNode为主控节点,多个DataNode为从属节点.NameNode对文件的操作进行记录,DataNode负责响应客户端的请求并接收和传送实际存储的数据.HDFS工作原理是,客户端要读取一个文件,首先,在NameNode节点中查看Namespace,获取数据块的物理位置,然后,在诸多DataNode节点中选择距离自己最近的节点进行读取.客户端若要写数据时同样先请求NameNode节点,获取合适的DataNode节点存储数据块副本[1].
此结构使HDFS存在一个潜在的问题是当集群大到一定程度后,单个的NameNode会显得力不从心.此时,所有的元数据信息的读取和操作都需要与NameNode进行通信,这无疑成了这种大集群的性能瓶颈.为此,Hadoop 2.0里的HDFS Federation采用联盟结构使得上述问题迎刃而解,但在此处不对这种联盟结构过多的论述.
3 分布式数据库 HBase
HBase (Hadoop Database)是一个构建在HDFS上分布式的、高可靠性与容错性、可伸缩的、面向列的非结构化数据库,和Hypertable同为Apache的Hadoop的子项目.需要关注的是,Hbase不是关系型数据库,而是用来解决关系型数据库处理海量数据(TB或是PB级的)瓶颈的,面向列的分布式数据库.
HBase位置在HDFS之上,属于Hadoop系统结构化存储层,底层的HDFS为其提供了高可靠性的底层存储支持,因此,利用Hbase技术可实现在廉价计算机客户端上组建大规模结构化存储集群.如图2所示,MapReduce为HBase提供了高性能的计算能力,Hbase利用MapReduce来处理海量数据,但其外部API屏蔽了MapReduce编程的细节,这样更容易被不熟悉MapReduce的开发者使用.Zookeeper为HBase提供了稳定服务和failover机制,Hbase利用Zookeeper作为集群协调工具,将数据节点注册其中,使得它的管理节点随时感知每个数据节点的状态,同时也避免了管理节点的单点问题;Hive和Pig为HBase提供了高层语言支持,使得数据查询和统计处理变的非常简单. Sqoop则为HBase提供了方便的关系型数据库中数据相互转移的功能,使得Hbase和传统数据库之间的数据迁移变得非常方便.

图1 HDFS层次结构
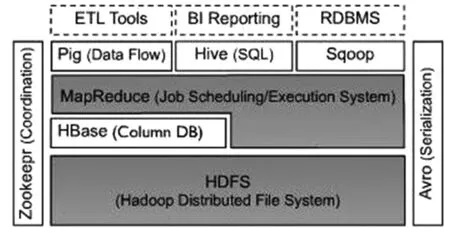
图2 Hadoop子项目关系
3.1 Hbase的访问接口和数据模型
一般而言,Hbase接口主要有以下六种[2]:1)Native Java API,适合Hadoop MapReduce Job并行批处理HBase表数据的最常规和高效的访问接口;2)HBase Shell,适合管理使用的最简单接口,是Hbase的命令行工具;3)Thrift Gateway,利用Thrift序列化技术,适合其他异构系统在线访问HBase表数据,同时支持PHP,C++, Python等多种语言;4)Pig,利用Pig Latin流式编程语言来操作HBase中的数据,适合做数据统计;5)REST Gateway,解除了语言限制,用REST 风格的Http API访问Hbase;6)Hive,编译成MapReduce Job来处理HBase表数据.
Hbase的数据模型和Bigtable的数据模型是一致的,适用于数据密集型的系统.HBase以HTable数据表形式存储数据,它的特点是基于列存储.如表1(以当前两个知名度较高的网购网站为例)所示.表结构由行(row)和列(column)组成,表中有3个基本的列,分别是 Row Key、Timestamp 和 Column Family.其中,Row Key 是表的主键(行键)用来检索表中的记录,可以是任意字符串,最大长度64KB,按照字典序存储,表中的各行记录是按照它进行排序的;Timestamp是每次数据操作对应的时间戳,类似于数据的version number;Column Family是表的列簇,一个表在水平方向可以有一个以上的Column Family组成,但超过2~3个列簇的表HBase就处理的不好.一个Column Family中可以由任意多个Column组成,它支持动态扩展,不用预先定义Column的数量以及类型,Column均以二进制格式存储,用户需要自行进行类型转换.

表1 Hbase表结构实列
在创建HBase表时,一般情况下会自动创建一个region分区.在需要进行数据导放时,客户端均向region分区中写数据,到了足够大之后进行分割.若要加快批量写入的速度,可以预先多创建更多的空的region分区,当数据需要写入时,便可集群内做负载均衡,写入不同的分区中.
3.2 HBase的实现思路
Hbase适合作为站点数据统计工具的存储系统.对于实时数据的统计,它可提供较低延迟的读写访问,承受高并发的访问请求,对于如站点访客流水信息这样的实时数据展示,只要设计了合理的key,根据key取单条访问记录时响应速度会很快;对于历史数据的统计,HBase可以被视为一个巨大的Key-Value存储系统,存储各个网站上历史访问信息用于做离线的数据分析与报表生成;对于像PV、IP、UV此类的操作,要对HBase表中相关记录进行扫描求和计算,如果被统计站点的数据量很大,可能会保证不了较快的响应速度.从前端发出一个查询请求到最终结果的响应,时间会超过1s或更长.
图3是一个使用HBase作为存储系统的结构示意图,应用程序分别通过入库端与查询端对HBase进行写操作与读操作.HBase服务端就是指HBase集群.从应用角度上看,Hbase可以分成2个方向:一是将HBase视为一个可靠可用的容量巨大的Key-Value存储系统,按照设计好的表结构存储具有稀疏结构的数据.这种思路是将其作为一个黑匣子来使用,如果它无法完全满足业务需要,需要在应用程序层次做一些设计和优化工作来解决问题.第2种是基于HBase是开源的,那么对Hbase本身机制进行完善和扩展,以达到满足业务需要的稳定可用的HBase版本.
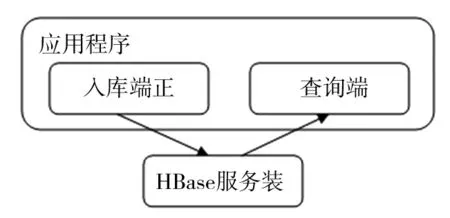
图3 HBase存储系统
对于前文提出的对于PV、IP、UV此类的操作,无法保证很快的响应速度的问题,可以用2种方式进行解决.第1种是在HBase服务端进行聚合计算,这样应用程序查询端只需请求服务端计算后的结果,而不必请求HBase响应大量数据进行传输,节省了响应的时间. 第2种方式是改善Hbase表设计,加入空列专用于统计以减少Hbase服务端到查询端的数据传输量. 另外,也可以在入库端,加入一个专门用于存储累加结果的表,每次有新数据时,先查询表上记录的数值,判断是否加1,重新写回相应的Key下,查询端就能直接通过一次get操作得到结果. 同样,也可以在查询端加入缓存,在查询请求来时,在现有的缓存值基础上,加上新增行的记录数,一般缓存更新时间周期很短,因此,新增数也很小,这样查询响应的时间会很短.
4 结语
“大数据”已成为今后互联网发展趋势,文章分析了 HBase 数据库的存储特点、数据存储方式,为利用Hbase存储海量数据理清了思路,也为进一步解决对海理数据快速有效的分析、挖掘数据的潜在价值的研究起到铺垫作用.
参考文献:
[1] 魏家宾.基于Hadoop的海量交易记录查询系统研究[D].江苏:南京邮电大学,2013.
[2] HBase技术介绍[EB/OL].http://www.searchtb.com/2011/01/understanding-hbase.html,2011.
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
哈尔滨轴承(2020年2期)2020-11-06
军事运筹与系统工程(2019年4期)2019-09-11
当代陕西(2019年14期)2019-08-26
发明与创新·大科技(2019年12期)2019-03-17
电子制作(2018年11期)2018-08-04
中国交通信息化(2017年3期)2017-06-08
知识就是力量(2017年2期)2017-01-21
中学数学杂志(初中版)(2016年5期)2016-11-01
中国教育信息化(2015年12期)2015-08-24
