
基于Syntax 级分组和多线程处理的HEVC 熵编码并行算法*
2014-03-18 05:49:56邸金红张克新张鑫明
电讯技术 2014年10期
邸金红,张克新,祁 跻,张鑫明
(1.郑州航空工业管理学院 电子通信工程系,郑州450015;2.阿拉巴马大学,美国 塔斯卡卢萨870118;3.中国舰船研究院,北京100192)
1 引 言
高效视频编码(High Efficiency Video Coding,HEVC)是由ISO 的动态图像编码专家组(Moving Pictures Experts Group/Motion Pictures Experts Group,MPEG)和ITU 的视频编码专家组(Video Coding Experts Group,VCEG)共同提出和制定的下一代视频编码标准。作为现行视频编码标准H.264/AVC的继任者,HEVC 的目标是较H. 264/AVC 有2 倍的压缩效率并支持到7680×4320 的视频分辨率[1]。HEVC 以算法复杂度的增加来换取压缩效率的进一步提高[2-3],然而,算法复杂度越高,运算消耗的资源也就越大,从目前HEVC 标准测试代码HM 的运算时间来看,难以满足实际应用中实时编码的需求。针对这一难题,面向并行多核/众核处理器的视频编码并行算法为大数据量运算问题提供了一种重要的解决手段,也是当前多媒体技术领域研究的热点之一。
不同于H.264/AVC 中分别应用与基本档和高档编码配置的两种熵编码算法,HEVC 仅采用一种熵编码模式,即基于上下文的自适应二进制算术编码(Context- Adaptive Binary Arithmetic Coding,CABAC)[4]。熵编码模块以其与其他模块的紧耦合性和数据之间的强相关性,成为并行化处理的瓶颈。针对HEVC 测试模型,K. Misra[5]等提出了Entropy Slice 的概念,它具有较高的并行粒度,并且良好地解决了负载不均衡的问题。Clare[6]提出行波并行处理算法(Wave-front Parallel Processing,WPP),波面用于实现帧层次的并行,相当于多帧多线程处理。随后在WPP 的基础上提出相应的CABAC 编码方法[7]。Arild[8]提出一种对宏块分割的新结构Tiles,有利于减小并行中宏块分割所带来的失真。对于CABAC,随着下文模型动态更新机制的引入,使得整个熵编码过程成为了一个高度紧耦合的串行过程。强行进行图像块的划分,必然会导致编码性能的下降。因此,基于现有串行的编码框架体系,使用并行计算加速编码的总体效果并不理想。
为了提高HEVC 编码速度,本文依据并行计算的适用特点,提出了一种基于Syntax 分组流水线处理和多线程处理的并行算法,并在HM 10.0 平台上进行了仿真。
2 HEVC 熵编码并行策略分析
HEVC 熵编码的并行策略主要有Bin 级并行处理、Slice 级并行处理和Syntax 级并行处理3 种。
2.1 Bin 级并行处理
Bin 级的并行策略主要是在二进制算术编码部分进行并行处理。输入的句法元素经过二值化被映射成一个二进制序列,这个二进制序列在经过上下文建模和概率估计后,以比特为单位被分拆成若干部分分别进行算术编码,编码完后再进行组合最终形成输出码流。Bin 级并行处理策略的并行粒度取决于上下文建模和概率估计的处理能力,因此对提高系统性能方面影响不大,有时反而会引起系统性能的下降。
2.2 Slice 级并行处理
根据H.264/AVC 中Slice 分割的思想,HEVC在保留传统Slice 的基础上引入了Entropy Slice[5,9]的并行编码策略。与传统的Slice 不同的是,Entropy Slice 将邻近编码片的位置信息写入码流,使其在重建图像的时候可以利用邻近Slice 中包括运动估计及帧内预测在内的编码信息,编码性能得到进一步提高。Entropy Slice 允许在一个Slice 内部再切分成多个Entropy Slices,这样熵编码器可以并行编码,从而提高了并行处理能力,使编码器的负载更加均衡。利用Entropy Slice 并行方案,可以同时调动CPU 和GPU 进行运算,使整个编码系统的运算能力得以充分发挥。无论是传统Slice 还是Entropy Slice,其并行粒度依然局限于编码片的划分。对于当今大规模并行计算的需求,依然有很大的差距。随着HEVC编码框架的完善和新的方法不断涌现,该技术已不再被标准所推崇[6-8]。
2.3 Syntax 级并行处理
Syntax 级的并行策略不将一组二进制符号分配到不同的熵编码器中,也不按照实际编码单元进行分割,而是按照语法元素的不同进行分割从而实现并行处理。在现行的熵编码框架中,对于每种语法元素,都使用特定的上下文模型进行建模,因此,按照语法元素进行分类,可以使这些上下模型进行尽可能多的训练过程,从而使编码概率估计更加精确,因此本文采用了Syntax 级并行策略。此外,无论是大型数据工作站还是个人计算机,其核心CPU 都具备多线程架构,并且随着CPU 技术的发展,其核心数会越来越多。多线程技术是并行计算的一个重要组成部分,因此可以利用CPU 的多线程计算能力来实现HEVC 帧级的并行编码。结合两者的优点,本文提出了基于Syntax 级分组和多线程处理的并行算法,下面详细介绍具体实现过程。
3 提出的熵编码并行算法
3.1 Syntax 级分组
与H.264/AVC 相类似,HEVC 中的语法元素同样可以进行分组以实现Syntax 级的并行处理。对于HEVC 中一个编码树单元(Coding Tree Unit,CTU)里的编码信息,按照语法元素进行划分可以分为以下几组:编码块划分信息SpiltFlag,编码方式PredMode,块划分方式PartSize,预测信息PredInfo,变换系数块标志位Cbf,非零变换系数位置信息Sig-Map 和非零变换系数信息Coeff。具体来说,PredInfo 包括IntraDirLumaAng、IntraDirChroma 等帧内角度预测信息和MergeFlag、SkipFlag、MergeIndex、RefFrmIdx 和Mvd 等帧间运动估计信息;SigMap 包括LastSignificantX/Y、SignificantCoeffFlag、SignificantCoeffGroupFlag 等非零变换系数位置信息;Coeff 包括C1Flag、C2Flag、AbsCoeff 和CoeffSigns 等非零变换系数幅值和符号信息。
这些语法元素之间具有信息间的依赖性,如图1所示。需要注意的是语法元素SkipFlag,该语法元素和其对应的语法元素MergeIndex 虽然也属于PredInfo 一组,但并不同其他属于PredInfo 的语法元素一样依赖于PartSize 和PredMode 的信息,因此,需要将此语法元素单独分离出来。基于上述分析,构建一个如图2所示的Syntax 级并行编码器。
将CTU 中的语法元素进行分组后,需要在每组语法元素之前设置一个标志位(StartFlag)以与其他组进行区分。在本文提出的并行算法中,利用一元码来设置StartFlag。对于图2中9 组语法元素,按照流水线的先后处理顺序分别赋予0、10、110、1110、11110、111110、1111110、11111110 和111111110 作为标志位码字。
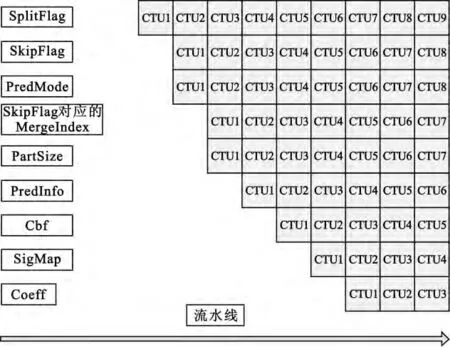
图2 HEVC 中Syntax 级并行编码器结构Fig.2 The parallel structure based on syntax-level in HEVC
3.2 多线程处理
在HEVC 中,如果采用全I 帧编码,则各帧之间编码数据相互独立,各帧在编码时不需要数据间的相互通信。在本文提出的多线程编码方法中,需要单独开辟一个线程进行码流的排序和拼接。以八线程处理为例,首先将视频序列的前7 帧依次送入第1~7 个线程后分别进行编码,编码完毕后这7 个线程进行同步,并输出码流到第8 个线程,在第8 个线程中进行码流的排序和拼接。同时,将视频序列的第8~14 帧再依次送入到前7 个线程中进行编码,以后依次类推,整个编码过程如图3所示。
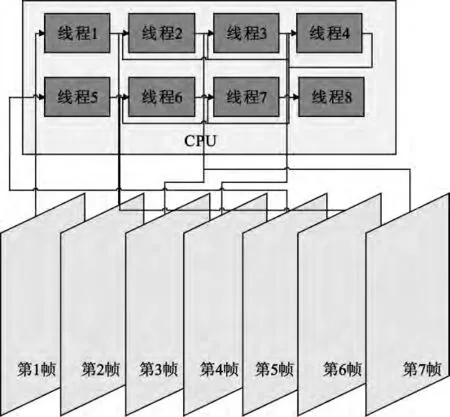
图3 全I 帧八线程编码方案Fig.3 Eight-thread coding scheme for I frame
如果采用I/B/P 帧编码,则各帧之间数据不相互独立,B/P 帧进行编码时都需要利用参考帧的信息,因此需要数据间的相互通信。在本文提出的多线程编码方法中,不仅需要单独开辟一个线程进行码流的排序和拼接,还需开辟一个线程进行参考帧管理。以八线程处理为例,首先将视频序列的前6帧依次送入第1~6 个线程,然后在第一个线程编码第一帧,进而将编码完后的数据信息送入用于参考帧管理的第7 个线程,将码流送入用于输出码流的第8 个线程,接着开启第2~6 帧的编码。在这5 帧编码期间,第7 个线程需要不断地进行数据通信和协调同步处理,以完成帧间编码运动估计,然后这5帧将码流输入到第8 个线程,在第8 个线程中进行码流的排序和拼接。同时,将视频序列的第7~12帧再依次送入到前6 个线程中进行编码,以后依次类推,整个编码过程如图4所示。
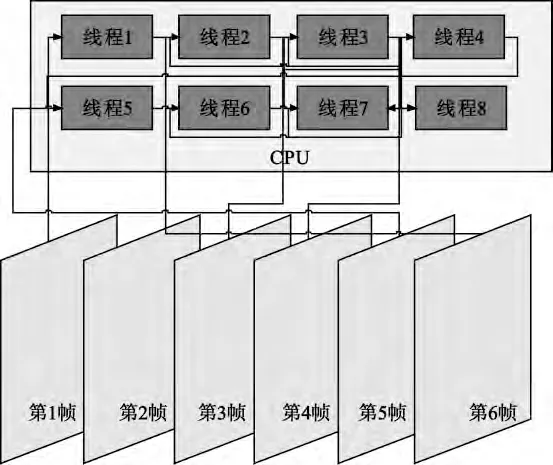
图4 I/B/P 帧八线程编码方案Fig.4 Eight-thread coding scheme for I/B/P frame
HEVC 中参考帧列表管理非常复杂,如果将完整的双向预测放入一个线程中进行管理,就会导致该线程负荷过重,反而会降低处理速度。因此,为了提高多线程计算效率,本文提出的方法中帧间预测中仅采用前向预测。
4 实验结果及分析
算法测试的硬件平台所用的CPU 型号为Intel Core i7,主频为3.5 GHz,核心数为四核,可支持八线程计算。由于是并行算法,实验主要是从时间加速方面来验证算法的有效性,同时也考虑了视频压缩的主客观质量,其中,客观质量是用PSNR 来衡量的。在验证并行算法效果时,对于全I 帧并行处理,选用官方编码器中只支持全I 帧编码的All Intra(AI)设置与其进行比较;而对于I/B/P 帧并行处理,由于算法中帧间预测仅采用前向预测,因此,选用官方编码器中只支持前向预测的LowDelay(LD)设置与其进行比较。
仿真实验选用HEVC 官方标准视频序列库Class B(1920× 1080,1080P)中的Kimono、Park-Scene、BQTerrace、BasketballDrive 序 列 和Class C(832× 480,WVGA)中的BasketballDrill、BQMall、RaceHorses 和PartyScene 序列,这两组序列分别在AI、LD 两种编码条件下进行测试。表1和表2为4个1080P 序列分别在AI、LD 设置下的性能比较结果,表3和表4为4 个WVGA 序列分别在两种不同设置下的性能结果比较。
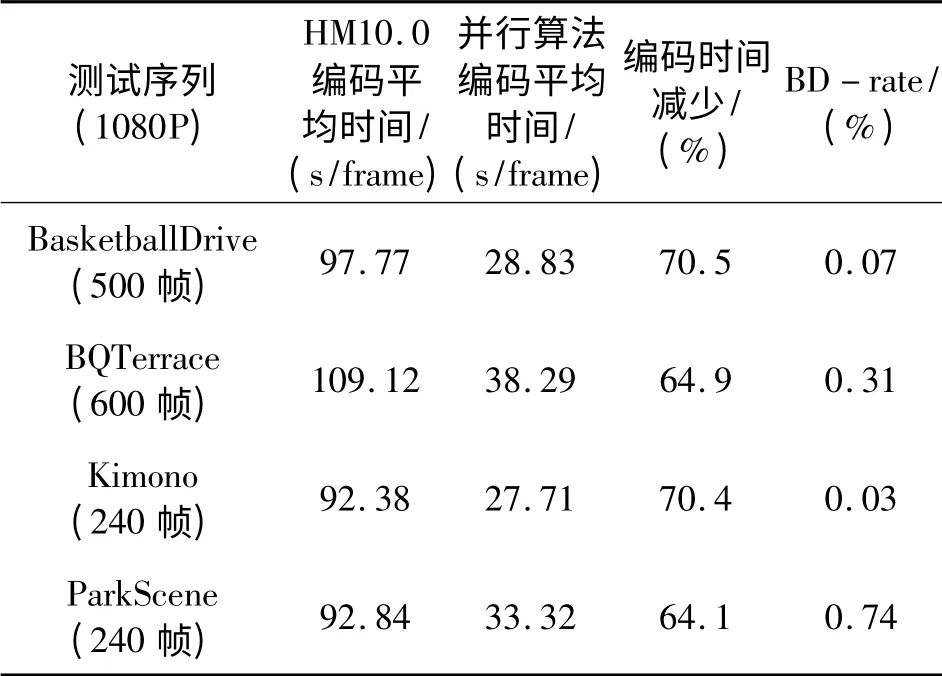
表1 AI 设置编码1080P 序列串行计算与并行计算速度性能比较Table 1 The performance comparison between serial computing and parallel computing for 1080P(AI)
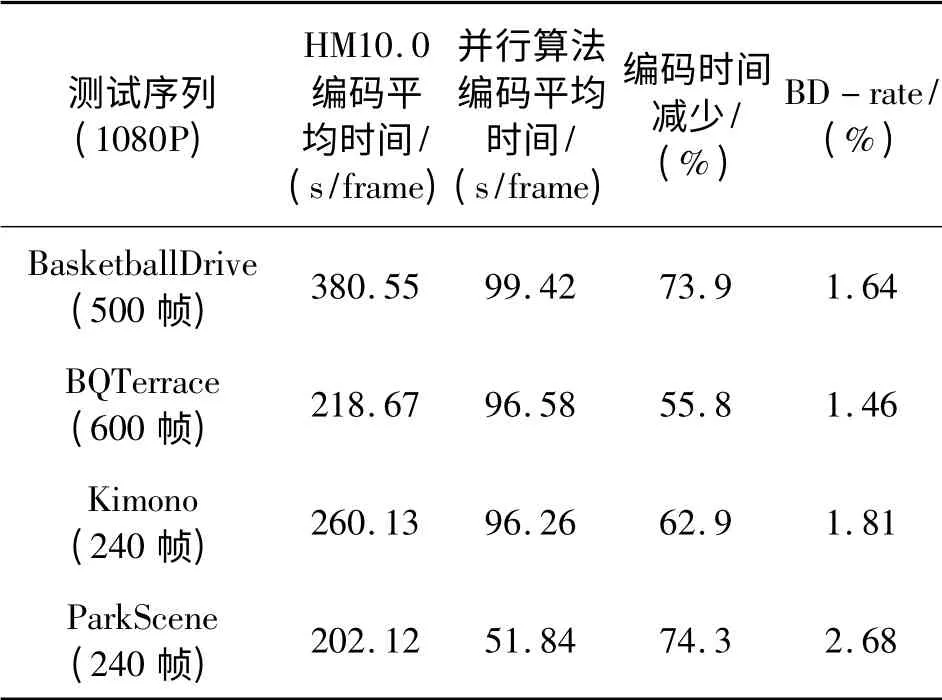
表2 LD 设置编码1080P 序列串行计算与并行计算速度性能比较Table 2 The performance comparison between serial computing and parallel computing for 1080P(LD)
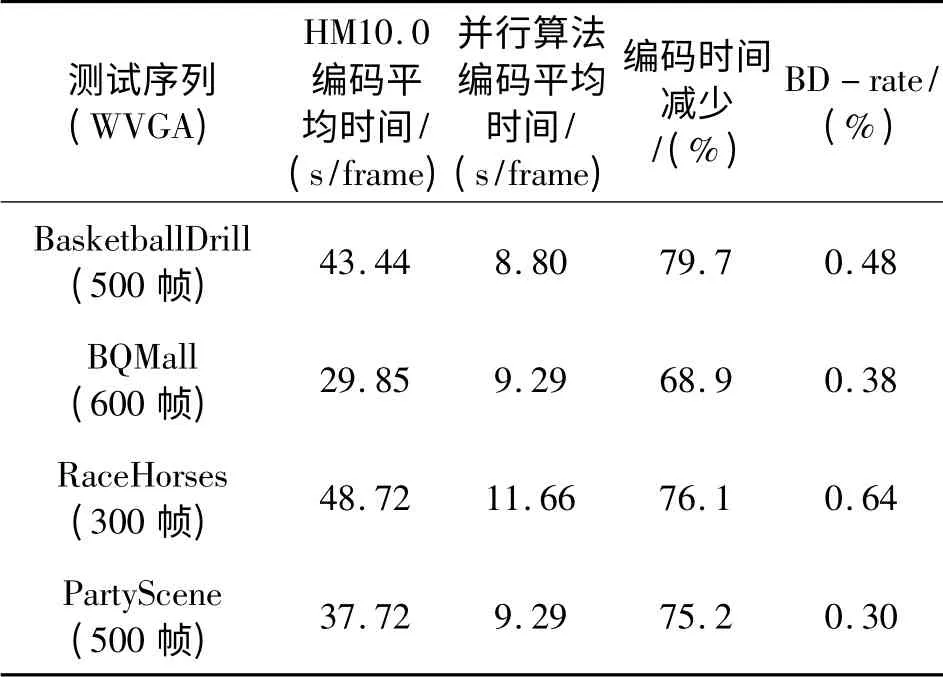
表3 AI 设置编码WVGA 序列串行计算与并行计算速度性能比较Table 3 The performance comparison between serial computing and parallel computing for WVGA(AI)
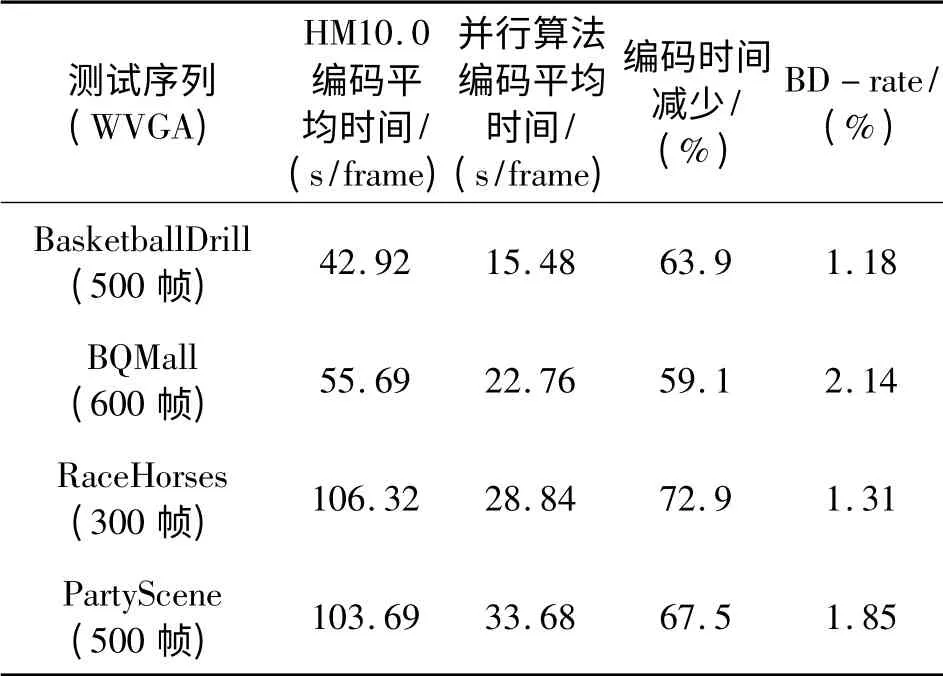
表4 LD 设置编码WVGA 序列串行计算与并行计算速度性能比较Table 4 Theperformance comparison between serial computing and parallel computing for WVGA(LD)
由表1~4可见,从编码时间上来看,本文提出的并行算法与HM10.0 相比,在AI 设置上平均有70%左右的编码时间节省,在LD 设置上平均有65%左右的编码时间节省。从这一数据可以看出,多线程计算并不能达到完全的成倍加速,其原因在于线程间数据需要相互通信,线程间并行处理需要不断进行同步,这些过程都需要消耗一定的时间。从编码图像的BD-rate 来看,本章提出的并行算法与HM10.0 相比,在AI 设置上平均有0.4%左右的BD-rate 损失,在LD 设置上平均有1.8%左右的BD-rate 损失,其原因在于并行处理还是损害了编码数据之间的相关性,从而使得熵编码的上下文建模过程和概率估计过程精确度下降。而由图5可见,应用本节的并行算法后,输出的编码图像相比于HM10.0 在主观质量上并没有太大的变化。

图5 Kimono 序列Fig.5 Coding results of Kimono sequence
5 结束语
为了提高HEVC 编码系统的运算速度,本文提出一种基于Syntax 分组流水线处理和多线程计算的并行算法。该算法借鉴H.264/AVC 中Syntax 级的并行算法思路,将码流中的语法元素分组并以流水线形式实现并发处理,同时,采用多线程并行处理技术,充分利用CPU 的核心数量,合理进行资源调度。将所提出的并行算法与传统的串行算法进行比较,验证了该算法的有效性。但是当前并行算法框架加速比不够高,远远不能满足实时视频编码的要求,需要进一步研究视频编码中的各种编码数据之间的依赖关系,找到更优的压缩效率与计算速度的折衷方案,加大整个系统的并行计算粒度。
[1] JCTVC-A124,Samsung's response to the call for proposals on video compression technology[S].
[2] Correa G,Assuncao P,Agostini L,et al. Performance and Computational Complexity Assessment of High-Efficiency Video Encoders[J]. IEEE Transactions on Circuits and Systems for Video Technology,2012,22(12):1899-1909.
[3] Frank B,Bross B,Sühring K,et al.HEVC Complexity and Implementation Analysis[J]. IEEE Transactions on Circuits and Systems for Video Technology,2012,22(12):1685-1696.
[4] Vivienne S,Budagavi M. High Throughput CABAC Entropy Coding in HEVC[J]. IEEE Transactions on Circuits and Systems for Video Technology,2012,22(12):1778-1791.
[5] JCTVC-B111,Entropy slices for parallel entropy coding[S].
[6] JCTVC-F274,Wavefront Parallel Processing for HEVC Encoding and Decoding[S].
[7] JCTVC-F275,Wavefront and CABAC Flush:Different Degrees of Parallelism Without Transcoding[S].
[8] JCTVC-F335,Tiles[S].
[9] JCTVC-D070,Lightweight slicing for entropy coding[S].
猜你喜欢
电视技术(2021年8期)2021-10-21 08:19:48
视听(2021年8期)2021-08-12 10:53:42
科技创新导报(2021年31期)2021-05-10 14:55:00
环球市场(2017年36期)2017-03-09 15:48:21
湖南城市学院学报(自然科学版)(2016年2期)2016-12-01 04:06:43
电子技术与软件工程(2014年20期)2014-11-19 09:55:45
电视技术(2014年19期)2014-03-11 15:37:52
电子设计工程(2014年18期)2014-02-27 12:00:14
吉林建筑大学学报(2012年3期)2012-08-15 00:54:52
杭州电子科技大学学报(自然科学版)(2010年5期)2010-01-08 07:28:38
