
基于相对贡献率的特征选择方法
2014-02-19 07:28杨杰明曲朝阳
东北电力大学学报 2014年4期
杨杰明,王 静,曲朝阳
(东北电力大学信息工程学院,吉林吉林132012)
1 引 言
随着因特网技术的高速发展,各种类型的数据呈爆炸式的增长,人们难以借助手工操作对海量数据进行分析和管理[1]。目前,已有越来越多的基于统计理论和机器学习的方法用于信息的自动处理[2]。其中,文本分类方法成为组织和处理大量文档数据的关键技术。但是,在文本分类系统中,文本特征表示通常采用向量空间模型进行描述[6]。然而原始特征向量空间的维数十分巨大,高维的特征集一方面造成文本表示的数据稀疏问题,另一方面也造成了分类器过分拟合的现象[7]。这两个问题直接影响文本分类的效率和精确度。有效的特征选择方法可以降低文本的特征向量维数,去除冗余特征,保留具有较强类别区分能力的特征,从而提高分类的精度和防止过拟合[8]。因此,在文本分类过程中,如何进行有效的特征选择成为很多学者研究的热点。目前已有很多特征选择方法应用在文本分类过程中,例如:信息增益[9],互信息[10],几率比[11]和 DIA 相关因子[12]等。
本文提出一种新的特征选择算法,该算法从相对贡献率的角度度量一个特征对于分类的重要性,并在20-Newgroups数据集上与信息增益、互信息、几率比和DIA相关因子等算法进行了对比。实验结果表明,该算法能有效提高文本分类器的性能。
2 相关技术
2.1 信息增益
信息增益是机器学习领域常用的算法。如果一个特征的信息增益值越大,则表明该特征对分类所起的作用越大。特征tk相对于类别ci的信息增益可表示为:

其中:p(c)表示类别c的文档总数在所有文档中所占的比例,P(t,c)表示文档c类中包含词t的文档在所有文档中所占的比例。P(t)是文件包含特征词t的文档在所有文档中所占的比例。
2.2 互信息
互信息是信息理论中的一个概念。互信息用来衡量特征tk和类别ci之间的相关性。一个特征tk拥有类ci的互信息越多,该特征包含更多的类ci信息就越多。计算互信息公式如下:

2.3 几率比
几率比是信息检索的一个重要方法。它是计算特征tk在类别ci中出现的概率与在其它类别中出现的概率之比。如果特征tk在一个给定的类别ci中的几率比较高,那么就认为特征tk对类ci越重要。几率比定义如下:

2.4 DIA相关因子
DIA相关因子方法用于衡量一个包含特征tk的文档被分到类别ci中的概率,从而确定该特征对于类别ci的重要性,公式如下:

2.5 歧义值度量
Saket和Mengle等人提出了一种基于歧义值度量的特征选择算法,该算法从特征集合中挑选出具有明确类别指示度的特征项。公式如下:

其中,tf(tk,ci)表示特征tk在类别ci中出现的概率,tf(tk)表示特征tk在整个数据集中出现的概率。
3 算法描述
表1是两个特征在五个类中的特征-频度矩阵。DIA相关因子和歧义值度量AM是常用的特征选择方法。DIA相关因子是估计特征tk在类别ci中出现的概率,而歧义值度量AM是从特征集中挑选出具有明确类别指示度的特征项。分析DIA相关因子和歧义值度量方法,可以发现特征tk在某个类别ci中出现的频度越高,特征tk在类别ci中就越重要。换言之,当特征tk在类别ci出现的概率比其它特征在类别ci中出现的概率大,那么与其它特征相比特征tk就越能够代表类别ci。据此本文推断,当特征tk在类别ci出现的概率与其它特征在类别ci中出现的概率之差的总和越大,特征tk对类别ci的贡献就越大,越能够代表类ci。由此本文引入一个基于相对贡献率的特征选择方法来判断特征tk在类别ci中的重要性,即基于相对的特征频度来衡量一个特征的重要性。
相对的特征频度为一个特征tk在类别ci中的频度与在其它类中的特征频度的差值的总和,差值的总和越大证明这个特征在类别ci中越重要,说明它的贡献率越大。基于该思想,可计算图1中所示的两个特征t1,t2在类别c1中的重要性,分别为:t1在c1中的相对特征频度为t1在c1中的绝对特征频度(216)减去t1在其它类中的绝对特征频度的差值的总和,即(216-230)+(216-200)+(216-180)+(216-190)=64,t2在c1中的相对特征频度为t2在c1中的绝对特征频度(80)减去t2在其它类中的绝对特征频度的差值的总和,即(80-16)+(80-50)+(80-20)+(80-10)=224,所以t2特征对类别c1的贡献率大,其在类别c1中比t1重要。从图1可以看出t2的相对特征频度(所有绿色直线距离之和)比t1大的多。
观察表1发现特征t1在数据集所有类别当中所占的比例是很大的,特征t1在每个类别中的特征频度都大于特征t2。由图1也可以看出,t1曲线整体在t2曲线之上,但是这并不能证明特征t1在每个类别中都是重要的,为了削弱与类别相关的影响,本文使用每个类中的特征总频度对特征tk在类别中的贡献进行了平衡。计算公式如下:

为了让结果曲线较圆滑,防止特征频率为0的情况,对上述算法进行了进一步的处理,如下:
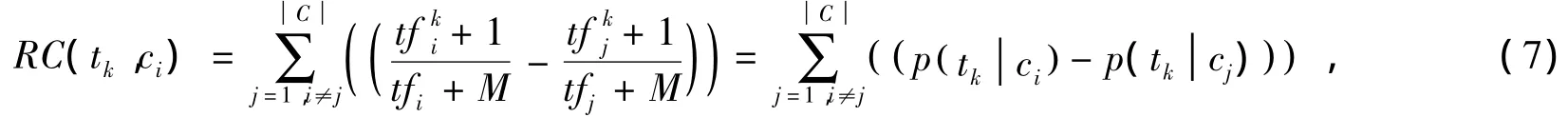


表1 特征 ×类别矩阵
4 实验环境设置
4.1 分类器
本实验,采用了两种常用的分类器,即:朴素贝叶斯(NB)和支持向量机(SVM)。其中,朴素贝叶斯[13]是建立在出现于一个文本中的特征与其他特征无关的假设基础上的分类算法。常用贝叶斯分类器模型有两种:一种是多项模型,另一种是多元的伯努利模型[14]。而多项式模型比多元伯努利模型的精度更高。因此,本文使用多项式模型。支持向量机是由Dluke等人提出来的,并且在垃圾分类和文本分类中的分类精度很高,是一种高效的分类器[15]。本文中使用了LIBSVM工具包,并选择了线性核支持向量机。

图1 两个特征在不同类别中的特征频率曲线图
4.2 数据集
为了评估本文所提出的特征选择算法的性能。在实验过程中,采用基准数据集(20-Newgroups)进行了验证,该数据集包含了19997个新闻组,所有的文件被均匀分配到20个不同类别之中[16]。在数据的预处理过程中,所有单词转换成小写,并且删除了标点符号,使用了停词表,词根提取。最后,采用10折交叉验证的方法进行了性能测试。
4.3 评价指标
本文采用了三个评价标准,即:微平均F1micro宏平均F1macro和准确率Accuracy对RC算法进行了评价。在文本分类领域中常用精度P、召回率R结果进行度量[17]。精度P为正确分类的样本数量与测试样本总数之比。召回率R是正确分类的样本数量与预先标记的样本数量之比。而F1micro和F1macro度量是结合了精度和召回率[18]进行的评价的指标,计算公式如下:

准确率为正确分类的百分比,常被用来衡量分类器的性能,计算公式如下:

5 数据分析
表2和表3显示了在五种不同的特征选择算法在20-Newgroups数据集上,分别使用贝叶斯和支持向量机分类器得到的微平均F1micro性能。表2表明了使用贝叶斯分类器时基于RC算法的微平均性能优于其它几个特征选择算法,并且随着特征数的增多性能越来越好。当特征数量为达到2000时,性能最好。表3表明使用支持向量机上的RC算法的微平均性能优于其它特征选择算法,并且当特征数量为2000时性能最好。图2显示五种特征选择算法应用在20-Newgroups数据集时贝叶斯分类器的微平均精度,RC曲线在其它算法曲线之上,精度优于其它特征算法的。图3显示五种特征选择算法应用在20-Newgroups数据集时支持向量机分类器的微平均精度,RC曲线在其它算法曲线之上,但增加比较平缓,但精度也优于其它特征算法。
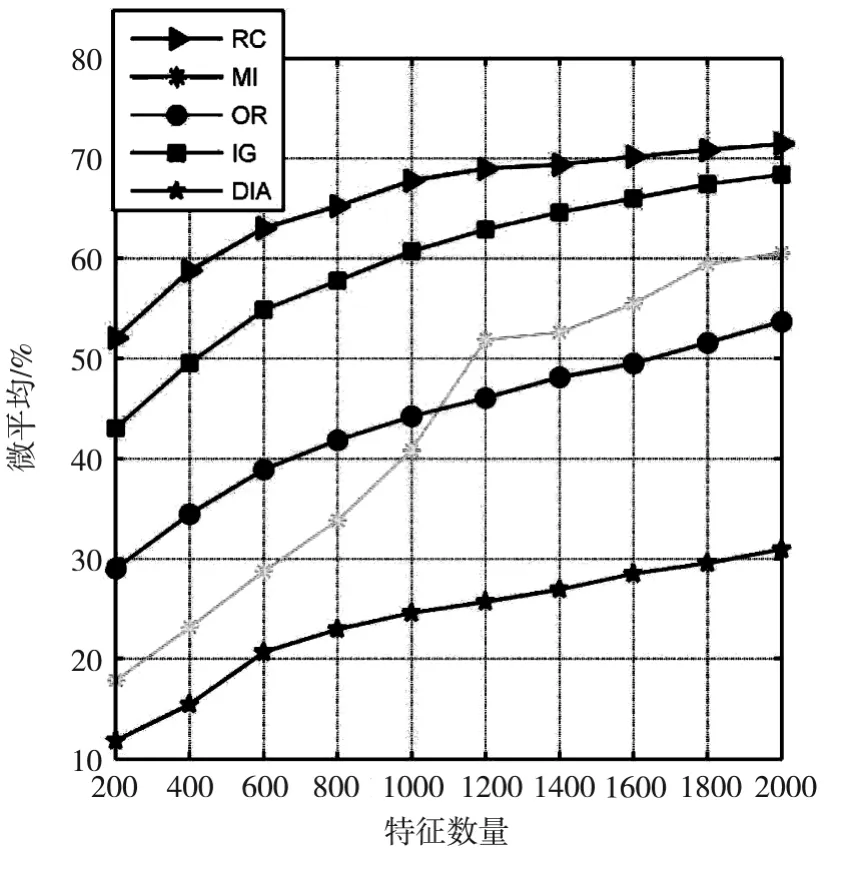
图2 不同特征选择算法应用在20N数据集时贝叶斯分类器的微平均曲线图

图3 不同特征选择算法应用在20N数据集时支持向量机分类器的微平均曲线图

表2 不同特征选择算法应用在20N数据集时贝叶斯分类器的微平均性能比较(%)

表3 不同特征选择算法应用在20N数据集时支持向量机分类器的微平均性能比较(%)
表4和表5显示了五种不同的特征选择算法在20-Newgroups数据集上,分别使用贝叶斯和支持向量机分类器得到的宏平均结果。表2表明使用贝叶斯分类器时,基于RC算法的宏平均性能优于其它特征选择算法,并且随着特征的增多性能越来越好,并且当特征数量为2000时性能最好。表3表明使用支持向量机分类器时,基于RC算法的微平均性能优于其它特征选择算法,并且当特征数量为2000时达到最好。图4显示了五种特征选择算法在20-Newgroups数据集上使用贝叶斯分类器时的宏平均精度,RC曲线在其它算法曲线之上,优于其它特征选择算法。图5显示五种特征选择算法在20-Newgroups数据集上使用支持向量机分类器时的宏平均精度,RC曲线在其它算法曲线之上,但增加比较平缓,但也优于其它特征选择算法。
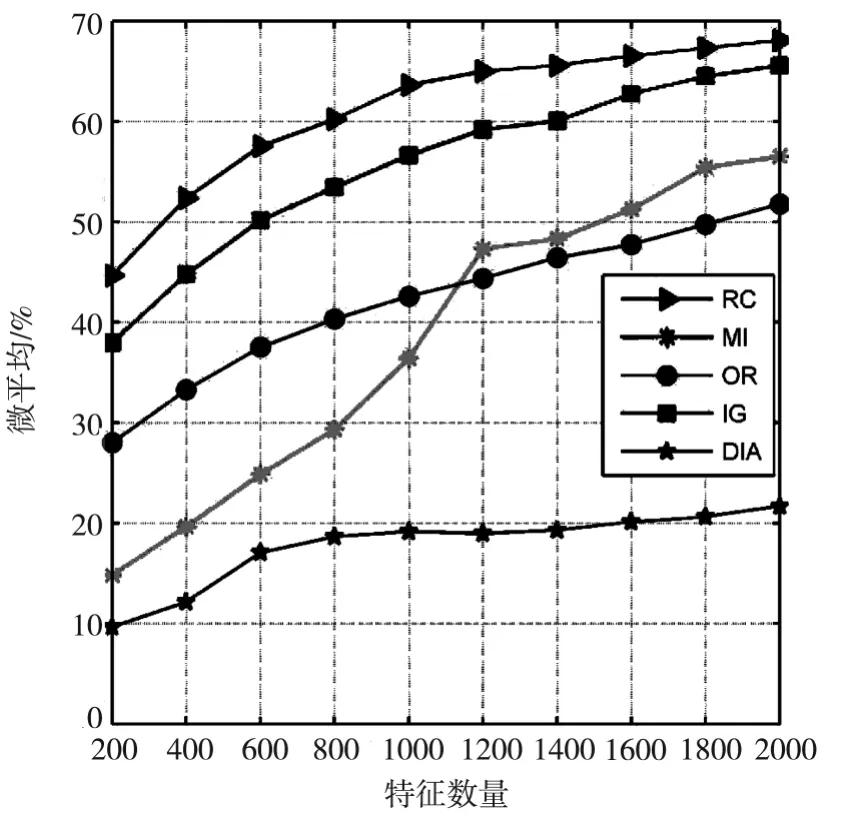
图4 不同特征选择算法使用20N数据集时的贝叶斯分类器的宏平均曲线图
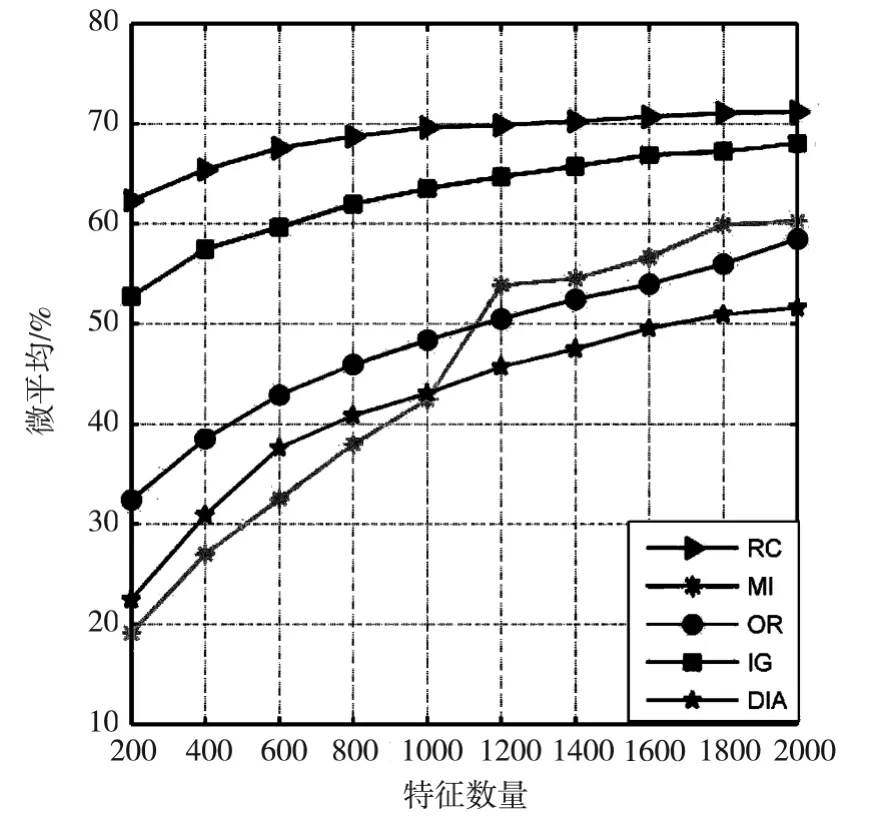
图5 不同特征选择算法使用20N数据集时的支持向量机分类器的宏平均

表4 不同特征选择算法应用在20N数据集时贝叶斯分类器的宏平均性能比较(%)

表5 不同特征选择算法应用在20N数据集时支持向量机分类器的宏平均性能比较(%)
表6和表7显示了五种不同的特征选择算法在20-Newgroups数据集上分别使用贝叶斯和支持向量机分类器时的准确率测试结果。表6表明使用贝叶斯分类器时,基于RC算法的准确率优于其它特征选择算法,并且随着特征数量的增加准确率越来越高,当特征数量为2000时达到最高。表7表明使用支持向量机分类器时,基于RC算法的准确率优于其它特征选择算法,当特征数量为2000时达到最高。图6显示五种特征选择算法使用20-Newgroups数据集时,贝叶斯分类器的准确率,RC曲线在其它算法曲线之上,精度优于其它算法。图7显示五种特征选择算法使用20-Newgroups数据集时,支持向量机分类器的准确率,RC曲线在其它算法曲线之上,准确率也优于其它算法。
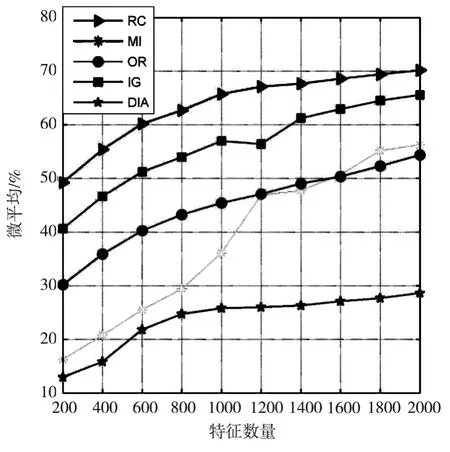
图6 不同特征选择算法应用在20N数据集时贝叶斯分类器的准确率曲线图
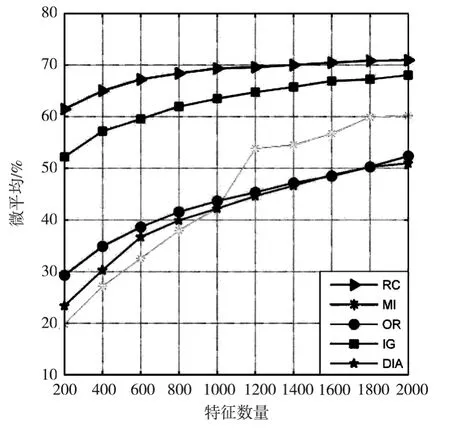
图7 不同特征选择算法应用在20N数据集时支持向量机分类器的准确率曲线图

表6 不同特征选择算法应用在20N数据集时贝叶斯分类器的准确率性能比较(%)

表7 不同特征选择算法应用在20N数据集时支持向量机分类器的准确率性能比较(%)
6 结束语
本文提出了一种新的特征选择算法,即基于相对贡献率的特征选择方法(RC算法)。文中基于20N数据集,使用了NB和SVM分类器进行了实验验证,实验结果表明RC算法的性能优于其它几个流行的特征选择算法,即:信息增益(IG),互信息(MI),几率比(OR),DIA相关因子(DIA)。但是本文所选的数据集是相对数据比较平衡的数据集,未来的研究工作将选择不平衡的数据集进行实验验证。
[1]Blum,A.L.,& Langley,P.Selection of relevant features and examples in machine learning[J].Artificial Intelligence,1997:97:245-271.
[2]Shang,W.,Huang,H.,& Zhu,H.A novel feature selection algorithm for text categorization[J].Expert Systems with Applications,2007,33:1-5.
[3]Chen,J.,Huang,H.,Tian,S.,& Qu,Y.Feature selection for text classification with Naïve Bayes[J].Expert Systems with Applications,2009,36:5432-5435.
[4]Chen,Z.,& Lü,K.A preprocess algorithm of filtering irrelevant information based on the minimum class difference[J].Knowledge-Based Systems,2006,19:422-429.
[5]Cover,T.,& Hart,P.Nearest neighbor pattern classification[J].Information Theory,IEEE Transactions on,1967,13:21-27.
[6]Drucker,H.,Wu,D.,& Vapnik,V.N.Support Vector Machines for Spam Categorization[J].IEEE TRANSACTIONS ON NEURAL NETWORKS,1999,10:1048-1054.
[7]Fragoudis,D.,Meretakis,D.,& Likothanassis,S.Best terms:an efficient feature-selection algorithm for text categorization[J].Knowledge and Information Systems,2005,8:16-33.
[8]郭新辰,李成龙,樊秀玲.基于主成分分析和KNN混合方法的文本分类研究[J].东北电力大学学报,2013,33(6):60-65
[9]He,H.,& Garcia,E.A.Learning from Imbalanced Data[J].IEEE Trans.on Knowl.and Data Eng.,2009,21:1263-1284.
[10]Iman,R.L.,& Davenport,J.M.Approximations of the critical region of the Friedman statistic[J].Communications in Statistics,1980,18:571-579.
[11]John,G.H.,Kohavi,R.,& Pfleger,K.Irrelevant Features and the Subset Selection Problem[C].Proceedings of the Machine Learning:Proceedings of the Eleventh International Conference,San Francisco,CA:Morgan Kaufmann Publishers,1994:121-129.
[12]Yang,J.,Liu,Y.,Liu,Z.,Zhu,X.,& Zhang,X.A new feature selection algorithm based on binomial hypothesis testing for spam filtering.Knowledge-Based Systems,2011,24:904-914.
[13]Yan,J.,Liu,N.,Zhang,B.,Yan,S.,Chen,Z.,Cheng,Q.,Fan,W.,& Ma,W.-Y.OCFS:optimal orthogonal centroid feature selection for text categorization.Proceedings of the Proceedings of the 28th annual international ACM SIGIR conference on Research and development in information retrieval,Salvador Brazil:ACM,2005:122-129.
[14]Mladenic,D.,& Grobelnik,M.Feature selection on hierarchy of web documents[J].Decision Support Systems,2003,35:45-87.
[15]Ogura,H.,Amano,H.,& Kondo,M.Feature selection with a measure of deviations from Poisson in text categorization[J].Expert Systems with Applications,2009,36:6826-6832.
[16]Schneider,K.-M.A Comparison of Event Models for Naive Bayes Anti-Spam E-Mail Filtering[C].ACM Transactions on Asian Language Information Processing(TALIP),2004,3:243-269.
[17]Shang,W.,Huang,H.,& Zhu,H.A novel feature selection algorithm for text categorization[J].Expert Systems with Applications,2007,33:1-5.
[18]Forman G,An Extensive Empirical Study of Feature Selection Metrics for Text Classification[J].Journal of Machine Learning Research,2003,3:1289-1305.
猜你喜欢
法律方法(2021年4期)2021-03-16
妇女之友(2017年3期)2017-04-20
电子制作(2017年23期)2017-02-02
铁道通信信号(2016年6期)2016-06-01
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
西北工业大学学报(2015年4期)2016-01-19
智能系统学报(2015年4期)2015-12-27
中国药物应用与监测(2015年5期)2015-12-11
郑州大学学报(理学版)(2014年2期)2014-03-01
振动工程学报(2014年4期)2014-03-01
