
互联网预定制信息的采集和监督研究
2014-02-17 09:32赵志超刘畅
计算机与网络 2014年16期
赵志超刘畅
(1 河北中信联信息技术有限公司 河北 石家庄 050091)
(2 国网冀北电力有限公司秦皇岛供电公司 河北 秦皇岛 066000)
互联网预定制信息的采集和监督研究
赵志超1刘畅2
(1 河北中信联信息技术有限公司 河北 石家庄 050091)
(2 国网冀北电力有限公司秦皇岛供电公司 河北 秦皇岛 066000)
针对互联网海量数据和目标对象的信息获取和状态监控需求,采用预定制特征元素集控制信息采集,经过去重、正文抽取、净化去噪、分词和过滤后,构建词汇/文本向量矩阵,采用隐性语义分析、奇异值分解、正则逼近和伪文本压缩等处理技术,实现了对获取向量信息的相似计算和排序,得出最佳搜索结果和监测目标的状态向量,同时降低了相似文本排序的计算量。
信息采集词汇/文本向量矩阵隐性语义分析
1 引言
互联网每天都在产生TB以上规模的数据,人们每天都在追逐着这些人们制造出来的海量“大数据”,知道其中有人们求之难得的,能解决所需问题的信息和知识,却常常苦于被这个大海淹没,没有顺手的方法和工具,能快速、准确和高效地从这浩瀚的“数据洋”中挖取人们需要的数据,然后再从中提炼满足人们需要的信息和知识。虽然,有些著名的搜索引擎可用,但是他们找到的数据常常也是动辄十万和百万条,甚至更多,在这些被排序的数据中找到为人们所用的数据,也是费时耗力且低效的。
运用网络数据挖掘技术、语义分析技术、统计分析和机器学习等方法,对特定需求的目标进行信息挖掘和状态监控仍具有实用意义,可以广泛应用于情报研究、科技探索、舆情监督、行业市场跟踪、用户研究和竞争对手分析等领域,讨论的采集和处理方法的目标对象均以中文和英文信息表述。
2 面向主题信息搜索系统的需求
人们经常有从互联网挖掘由多元数据集限定的,而不是仅仅靠一两个词或语句用搜索引擎完成的,面向特定主题信
息的搜索采集需求。这些多元数据集从多个方面对人们需要搜寻的主题信息进行了限定,当各元素之间没有次序关系时,构成特征元素集合;如果各元素之间具有次序关系要求,则构成特征数据向量。经过对互联网上内容信息的按特征元素集信息的采集提取,可以获得更准确吻合人们需要主题的信息。这些特征元素集是随着每次的采集挖掘主题需求不同而改变的,也就是可以灵活调整和定制的。
主题特征元素集的构成,可以是结构化数据,非结构化数据,甚至可以是网站的结构信息。当特征元素集是普通文字、数据或音视频数据时,人们关心的是网站内容的差异;当特征元素集是网站结构信息时,人们关心的是网站的特定功用,是网站状态间的差异。
通过对特征元素集的搜索、定位和定期比对,可以实现对重点信息和网站的动态监督。研究准确和高效地从互联网上找到含有人们需要特征元素集的信息,并且能随时掌握这些信息的动态变化的应用软件系统,对于快速准确地情报分析研究、科技发展探索、舆情动态监督、行业市场走向跟踪、用户需求趋势研究和竞争对手动向分析等领域应用具有重要意义。
3 预定制信息搜索系统构成
根据上述需求和目前技术发展,预定制信息挖掘系统的实现需要综合运用搜索引擎技术、文本处理技术、自然语言处理、智能分析技术和网站结构分析等技术,其系统基本构成如图1所示。
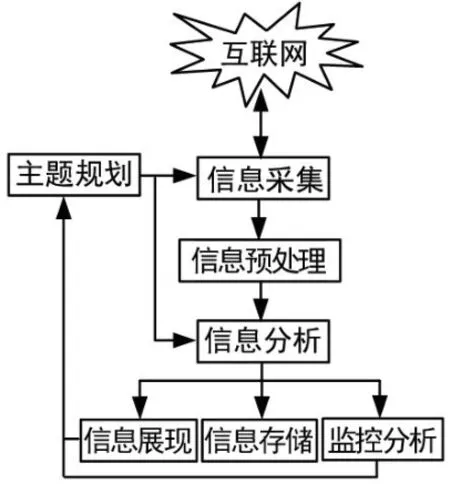
图1 系统构成示意图
4 特征主题规划
该模块确定信息采集的特定目标、主题集合和模式等参数,对信息采集模块的行为进行定性控制。主题特征元素集信息可以采用人工录入,或者由系统反馈的指令,如进行深入采集和监控采集指令等,实现连续自动采集和跟踪。
当系统采集的信息经过处理后,可能需要调整元素组合集;深入挖取或拓展采集时,当设定的监控对象发生状态变化时,或者进行必要的停止和持续追踪时或扩展挖取时,都需要调整特征元素集的主题规划。
5 信息采集
互联网信息采集常用爬虫技术实现,此类系统可用的开源程序很多,在此基础上开发对特征组合信息进行动态配置的爬虫。系统采用主题和限定爬虫,根据特征元素集组合的需求,设置爬虫的挖掘行为参数[1,2]。爬虫模块负责从互联网上采集信息,爬虫的数量、抓取速度、起始URL和符合采集要求的URL正则表达式和爬虫线程终止条件等的设置受到特征元素集要求的约束。对获取的网页,通过网页清洗预处理模块清除网页中与特征元素集要求和正文无关的材料,如广告和导航条信息等噪声,提取出相关网页内容的标题、正文、链接地址和时间戳等信息,导入数据库。
6 采集信息的预处理
该模块主要任务是将信息采集模块所获取的网页内容材料作进一步的信息处理,包括文本去重、净化抽取、文本分词、虚词及停用词的净化等。
⑴文本去重
互联网存在着大量的重复内容,有些网页是完全一样的,为了减少后续工作量、提高搜索质量和节省空间,需要先去除重复以及近似重复的文档。
此阶段采用比较文档内容checksum值的方法来判断完全相同的文档,如果2个文档的checksum值不匹配,则认为这2个文档不相同。当然,也可能有不同的文档具有相同的checksum值,但可选择适当的checksum计算过程,使得不同的文档产生相同的checksum值的概率很小,从而大大缩减后续处理的工作量。在后续的正文抽取、分词、矢量化的过程中仍会根据处理的方法进行不同层面的去重工作。
⑵正文抽取
人们需要的内容常常都在网页和文档的正文中,可以根据网页及文件存储结构的格式,利用统计分析技术、HtmlParser、PDFBox和Apache的POI等抽取工具从中抽取文本内容,并剔除广告、分割条、导航链接、搜索服务和版权信息等噪声[1]。
网页净化过程一般可以分为网页内容结构的表示和网页内容块的取舍。HTML标识语言定义了一套标签来刻画网页显示时的页面布局。因此,对于HTML网页最常用的结构表示方法是构造网页的标签树。根据内容差异,网页可以分为主题
网页、目录网页和图片网页3类,其净化方法各不相同。目录网页是将网页中间区域的内容块作为网页的主题内容,而边缘的内容块则通过与主题内容计算相似性的方法来决定取舍。图片网页则采用保留网页中间区域的图片型内容块达到网页净化。主题网页净化方法为:先识别出网页中的主题内容块,再依据主题内容在剩余内容块中识别出与主题相关的内容块,最后区分出噪音内容块。
⑶正文的分词、过滤
经过去噪后的文本仍然只是数据形式,进行语义分析需要对其分成具有意义的独立词元组合。英文的分词可以采用空格和标点符号进行分割实现,而中文词法分析是中文信息处理的基础与关键。采用中国科学院汁算技术研究所研制的汉语词法分析系统(Institute of Computing Technology,Chinese Lexical Analysis System,ICTCLAS),ICTCLAS采用了层叠隐马尔可夫模型(Hierarchical Hidden Markov Model),主要功能包括中文分词、词性标注、命名实体识别和新词识别,同时支持用户词典,支持繁体中文,是目前最好的汉语词法分析器[3]。
对去噪后的文本用ICTCLAS进行分词,分词后根据得到的词性标注将介词、助词、叹词、语气词、拟声词、标点符号和停用词去掉,得到该文本内容的特征文档词条。
7 信息分析与处理
为了避免因使用常见的词条检索方法,可能导致作者选定使用的特征元素集中的词汇隐含意义相同,但字面不同而使文本被漏检,选用隐性语义分析法(Latent Semantic Analysis, LSA)完成最接近特征元素集的文本集合的采集提取。LSA是一种自然语言处理的方法。其出发点是假设文本中的词汇与词汇之间存在某种联系,即存在某种隐性的语义结构,这种隐性的语义结构隐含在文本中词汇的上下文中[4,5]。
⑴构建表示词汇/文本的矩阵
为了便于分析处理,将经过预处理的文本词条表示成在向量模型空间中的所有特征元素集词汇的向量,m个特征元素集词汇和n篇文本被表示为词汇/文本矩阵,其中每一行代表主题规划确定的特征元素集的一个词汇ti在各文本中的权重,每一列代表文本集中的一个文本dj针对主题规划确定的特征元素集的参数向量,如下式所示。
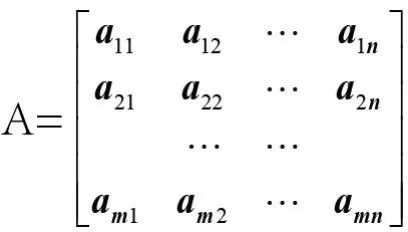
式中,aij代表特征词ti在文本dj中的权重,采用目前广泛采用的权重计算公式TF-IDF公式:
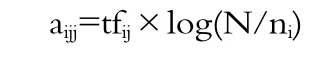
式中,tfij代表特征词ti在文本dj中出现的频率,称为“词频因子”;N表示采集到文本集中全部的文本数;ni表示这些文本中出现特征词ti的文本频数;自然对数log(N/ni)代表特征词ti反比于特征词出现的文本频数,称为“反文档频数因子”
[5-6]。
⑵对矩阵A的奇异值分解
隐性语义分析通过重点应用了矩阵的奇异值分解(SVD)将词和文档映射到隐性语义空间,去除了原始向量空间中的一些“噪音”,提高了信息检索的精确度。
不失一般性,假设词汇/文本矩阵A是m行n列的一个稀疏矩阵,已知rank(A)=r。可得A的奇异值分解为:
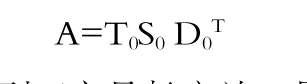
式中:T0的各列正交且长度为1,即T0T0T=I;D0的各列正交且长度为1,即D0D0T=I;S0称为矩阵A的奇异值标准型,是一个单值的对角矩阵,即:
S0=diag(λ1,λ2,…,λm),且有λ1≥λ2≥…≥λr≥λr+1=…=0是A的奇异值。
⑶构建词汇/文本矩阵的最佳逼近
当k满足贡献率不等式:

式中,θ为包括原始信息的阈值;选取前k个最大的奇异值,其余设置为0,获得新的对角矩阵S。同时,取T0和D0的前k个列,分别获得矩阵T和D,这样得到的矩阵运算结果记为Ak,是原始矩阵A的一个近似值,其秩为k。可以证明,矩阵Ak是所有秩为k的矩阵中与A用F-范数评价时的最佳逼近,且均方误差为1-θ[6]。
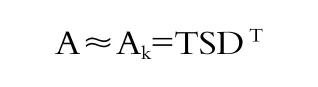
LSA通过对词汇/文本矩阵A进行截断的奇异值分解,得到秩为k的“近似矩阵”,得到的语义空间表示含有原始矩阵A的θ%的关键信息,达到信息过滤和去除噪声的目的。
⑷构建伪文本向量
系统根据主题规划特征元素集的词频信息生成查询向量q,把其当作一个“伪文本”,则在k维语义空间中可表示为:
q+=qTT S-1
这样,在k维空间中,q+和其他文本向量之间的相似度可用他们向量间夹角的余弦来进行计算,如:
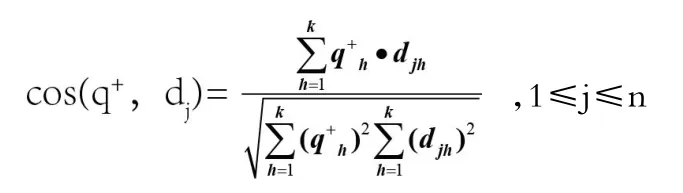
式中,q+h为查询向量的第h个词汇的权重;djh为第j个文本向量的第h个词汇的权重;k为语义空间的维度。cos(q+,dj)的绝对值越接近于1,说明向量q+和dj之间的夹角越小,相互
关联性越大。
⑸按相似度高低排列文本
通过反复计算比较q+和dj(1≤j≤n)文档向量之间的余弦夹角数值,最后按相似度高低排列文本,根据用户的要求将文本列表提供给用户。对于监控对象,则根据初始需求确定出目标对象的状态向量。
8 反馈展现和跟踪
实际上从特征元素集信息采集的目标需求,近似重复的文档也是具有一定的保留和参考价值的。因此,需要将有序文本集提供反馈展示,供用户选择,并根据需要进行存储。
对关注目标的状态监控分析需求,状态向量前后变化的差异才是需要对比跟踪的。监督跟踪可以根据需要设定为定期的和不定期实施。实施中采用决策树结构[5],将监督目标对象的初始多维状态向量设定为决策节点,节点通过率传达了目标状态变化的程度,可供选择跟踪决策。获取的信息和监控状态都可能成为新的规划主题,或者调整特征元素信息的新需求,继续深化进行上述过程[6]。
9 结束语
在文档词条构建向量矩阵过程中,原始文档中的次序信息损失了,且类似语句结构的语义信息也损失了,但这样的词条向量在后续检索中仍是非常有效的。
采用LSA将文本和词汇的高维表示投影在低维的隐性语义空间中,缩小了问题的规模,得到词汇和文本的不再稀疏的低维表示,同时这种低维表示揭示出了词汇/文本之间语义上的联系。使用k-秩近似矩阵使得原m个特征元素集伪文本压缩到k维向量,降低了相似文本夹角余弦计算量,对于固定的查全率,提高了检索的查准率。阈值θ与k的相关,也即与奇异值序列分布相关,适当选择θ可以在查准率损失不大的情况下,使k的选择尽量小,从而降低运算量。
[1]罗刚,王振东.自己动手写网络爬虫[M].北京:清华大学出版社,2010.
[2]MARMANIS H.智能web算法[M].阿稳,等,译.北京:电子工业出版社,2011.
[3]刘群,张华平,等.基于多层隐马模型的汉语词法分析研究[OL].http://www.ictclas.org/.
[4]DAVID H.数据挖掘原理[M].张银奎,等译.北京:机械工业出版社,2003.
[5]PETER H.机器学习实战[M].李锐,等译.北京:人民邮电出版社,2013.
[6]CHRISTOPHER D M,HINRICH S,PRABHAKAR R.信息检索导论[M].王斌译.北京:人民邮电出版社,2010.
Research on Acquisition and Monitoring of Predetermined Information on Internet
ZHAO Zhi-chao1LIU Chang2
(1.Hebei UniWin Information Technology Co.,Ltd.,Shijiazhuang Hebei 050091,China)
(2.Qinhuangdao Power Supply Company of State Grid Jibei Electric Power Co.,Ltd.,Qinhuangdao Hebei 066000,China)
Aiming at the requirements of information acquisition and status monitoring of mass data and goal object on Internet,this paper uses the predetermined characteristic element set to control the information acquisition,builds the term-document matrix after reduplication removing,text extraction,purification and de-noising,word segmentation as well as filtering,uses such technologies as latent semantic analysis,singular value decomposition,regularized approximation and pseudo-text compression to implement the similarity calculation and seqencing of acquired vector information,get the best search result and the status vector of monitoring target, and reduce the amount of calculation of similarity text sequencing at the same time.
information acquisition;term-document matrix;latent semantic analysis
TP393
A
1008-1739(2014)16-69-4
定稿日期:2014-07-26
猜你喜欢
客联(2022年3期)2022-05-31
新高考·高一数学(2022年3期)2022-04-28
中国新闻周刊(2021年26期)2021-07-27
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
电子制作(2018年10期)2018-08-04
电子制作(2017年2期)2017-05-17
信息安全研究(2016年4期)2016-12-01
高中生学习·高三版(2016年9期)2016-05-14
电子测试(2015年18期)2016-01-14
新高考·高二数学(2015年11期)2015-12-23
