
LIBSVM回归算法在话务预测中的应用
2014-02-10 01:29:44
电信工程技术与标准化 2014年9期
(福建省邮电规划设计院有限公司,福州 350001)
LIBSVM回归算法在话务预测中的应用
钟坛旺,林昭语
(福建省邮电规划设计院有限公司,福州 350001)
话务量预测在工程规划建设中有重要的意义,但常用的预测方法总体准确率不高,而LIBSVM算法在解决回归问题上表现出优良的性能。本文以H市连续587天早忙时话务量样本作为LIBSVM模型训练,之后用60个样本点作为测试数据,验证LIBSVM模型的预测性能,并对结果进行均方误差和平均相对误差的指标评价分析。
话务量预测;LIBSVM;模型训练;样本集
在工程规划与建设中需要根据对目标期的话务量预测来确定目标无线网络容量、扩容需要的设备类型和数量等,话务预测结果的准确与否直接关系到目标无线网络利用率、投资效益等企业发展的关键指标,因此以相对准确的话务量预测来指导运营商网络建设,能成功应对用户行为的变化及其趋势,为移动网络长久、稳定的运行奠定基础。在通信网络的规划和设计中,常用的预测方法主要有趋势外推法、回归预测法、业务模型法、市场调查法等,常用的预测方法在网络快速工程建设中,起到一定的积极作用,但总体准确率不高。
支持向量机(SVM,Support Vector Machine)是近年来出现的一种机器学习方法,在解决分类和回归问题方面都表现出优良的性能。借助于支持向量机方法,通过使用LIBSVM工具箱对话务量的特征向量进行学习训练,经过交叉验证确定了回归机的最优参数组合,经实验验证预测效果较理想,针对话务量的预测提供了一种新思路。
1 SVM 综述
SVM是建立在统计学的VC维理论和结构风险最小化原则基础上的机器学习方法,它能够根据有限样本信息,在模型的复杂性和学习能力之间寻求最佳折衷,是SLT的一种成功实现。
当SVM用于回归估计时,称为SVM回归机。假设训练样本为(xi,yi),(i=1,…,l)。最简单的SVM回归机使用线性函数对样本点进行拟合。对于无法用线性函数拟合的问题,则将样本映射到高维特征空间,在高维特征空间中建立线性模型,其中是将样本点映射到高维空间的非线性变换,SVM回归机可以表示为

满足以下约束条件:

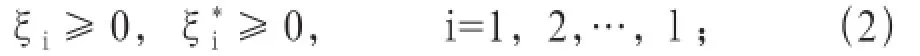
式(1)中,‖ω‖2代表与模型复杂度相关的因素;C>0为惩罚系数,它控制对超出误差的样本的惩罚程度;ε为不敏感损失函数,其取值大小影响支持向量的数目;为松弛变量,表示样本偏离ε不敏感区域的程度。
对于式(1),通常通过求解上述模型的Lagrange对偶问题获得原问题的最优解

其中,K(xi+xj)称为核函数,满足Mercer条件且K(xi+xj)=φ(xi)φ(xj)。径向基核(radial basis function,RBF)是普适的核函数,K(x+x')=exp(-‖x+x'‖2/σ2) =exp(-γ‖x+x'‖2),其中σ>0是核宽度系数,γ=1/σ2。惩罚系数C、不敏感系数ε、核函数及相关参数的选择,对SVM的效果有显著影响。
LIBSVM是国立台湾大学林智仁博士等开发设计的通用SVM软件包,可以解决分类问题(包括C-SVC、v-SVC)、回归问题(包括SVR、v-SVR)以及分布估计(one-class-SVM)等问题,提供了线性、多项式、径向基和S形函数4种常用的核函数供选择,可以有效地解决多类问题、交叉验证选择参数、对不平衡样本加权、多类问题的概率估计等。
2 基于LIBSVM的话务量预测方法
采用支持向量机求解回归问题,关键是核函数与参数的选择,通过对LIBSVM软件包中核函数类型及其相关参数的对比分析,以找到最适合本预测方法的模型。基于LIBSVM的话务量预测方法流程如图1所示。

图1 基于LIBSVM的话务量预测方法流程图
2.1 数据样本采集、构造特征向量、预处理
2.1.1 数据样本采集、构造特征向量
话务量是一种动态的、随机的时间序列,受政策因素、经济发展、人口数量、季节及其它自然因素等的影响,这些因素均与预测目标值有一定的关联,但较难完全量化为回归模型的输入向量,而历史话务量数据在时间序列上一定程度的反映了某些因素的影响;因此选取容易量化的时间序列与历史的话务量相结合,构造一个多元回归预测特征向量如下。

式中:year(d),mon(d),day(d)为数据样本的对应年月日,体现出话务数据与时间序列的对应关系。
user(d)为数据样本的对应日期的VLR登记用户数,用户规模的发展趋势与话务量的发展密切相关,加入该维度用来表达话务量与用户数量间的关联性。
x(d-1),x(d-2),x(d-3)为数据样本对应前3天的话务量实际值,加入该维度体现相邻时段话务量的相关性。平均话务量,体现相邻时段话务量的相关性及一定时段内的发展趋势,同时弱化短期内不合理的话务波动。
预测过程就是通过LIBSVM算法,以获取能反映上述特征向量模型的最优函数关系f。本文中取H市连续647天早忙时的话务量,按以上的特征向量模型建立样本集,其中用587个样本点进行模型训练,之后用60个样本点作为测试数据。
2.1.2 样本集预处理
将样本数据按LIBSVM要求的数据格式进行整理,具体格式为(1abel>[index1]: [value1] [index2]:[value2]……
其中:label是训练数据集的目标值,index是从l开始的整数,表示特征的序号;value是用来训练或预测的数据,即预测模型的相关输入维度,部分样本集实例如表1所示。

表1 部分样本集实例
为了避免输入向量中各变量数量级相差过大影响训练效果,调用scale工具对训练数据和测试数据进行归一化处理,归一化区间设为[-1,1]。
2.2 样本集训练建模及预测
2.2.1 样本集训练建模
LIBSVM回归算法关键步骤之一,就是选取最合适的参数,以达到最佳的预测效果,而进行人工试验工作量大且较难实现最优化。因此本文中直接调用gridregression.py函数进行自动寻优,通过设定SVM类型、核函数、10分交叉验证方式等,得到模型训练中所需的最优参数为c=1 024,g=0.25,p=128。
应用e -SVR与RBF函数,并结合以上的参数进行模型训练,得到预测模型显示为
#iter=1 368(为迭代次数);
nu=0.658 622(n-SVC、one-class-SVM与 n-SVR中参数);
obj=-150 064 894.68(SVM文件转换为的二次规划求解得到的最小值);
rho=-7 462.401(为判决函数的常数项b);
nSV=407(为支持向量个数);
nBSV=369(为边界上的支持向量个数)。
2.2.2 预测
根据得到的预测模型对测试样本进行预测,输出结果包括均方误差(Mean Squared Error)=251 743;相关系数(Squared Correlation Coefficient)=0.692 042,同时输出预测的话务量数据,拟合的效果如图2所示。

图2 LIBSVM模型话务量预测拟合的效果
从图2中可以看出预测数据曲线与真实数据曲线的趋势基本吻合,预测曲线更为平缓,当实际值波动较大时,预测结果出现较大偏差。
2.3 预测结果评价
本次的评价过程是将LIBSVM模型预测结果与趋势外推法的预测结果进行指标对比。
2.3.1 评价指标定义
对不同的预测结果进行均方误差和平均相对误差这两个指标的评价,这两个指标定义如下:

式中:mse为均方误差,n为样本总个数,yi表示实际值,表示预测值。

式中:E为平均相对误差,n为样本总个数,yi表示实际值,表示预测值。
2.3.2 趋势外推法的预测结果
将587天的忙时话务量样本模型进行指数、线性、对数、幂、移动平均、二次曲线和三次曲线等的拟合,选择拟合度最高的三次曲线建立趋势模型,如图3所示。

图3 话务量增长趋势拟合曲线
根据图3中的趋势模型y=-3E-05x3+0.0183x2+9.456x+4500.9,计算得到的60个测试样本的预测值与实际拟合的效果如图4所示。
2.3.3 评价指标对比
两种预测方法的均方误差和平均相对误差指标对比如表2所示。
从以上评价指标可以看出,LIBSVM回归方法通过时间序列和活跃用户数刻画趋势量、相邻时段的相关维度输入等,并利用SVM突出的高维识别能力进行拟合,预测数据曲线与真实数据曲线发展趋势基本吻合,与趋势外推法相比预测精度有较大的提高。

表2 两种预测方法指标对比

图4 趋势外推法话务量预测拟合的效果
3 结论
LIBSVM回归算法通过分析建立合适的输入样本集、通过参数选优确定最优参数,并利用SVM突出的高维识别能力进行拟合,能实现与目前常用预测方法相比误差更小的预测,体现LIBSVM回归算法的优越性。在无线网络工程规划建设中,应用本算法对规划期的目标预测值进行必要的修正,在设备配置合理化等方面将会起到积极的作用。
Application of LIBSVM regression algorithm in traffic prediction
ZHONG Tan-wang,LIN Zhao-yu
(Fujian Posts and Telecommunications Planning and Design Institute Co., Ltd., Fuzhou 350001, China)
Traffic prediction has an important significance in the project, overall accuracy is not high by some common methods, but the LIBSVM algorithm shows good performance quality in solving the regression problems. This paper takes the samples as LIBSVM model training ,basing on the early busy traff c of H city for 587 consecutive days, and verify the predicted performance of LIBSVM model by testing data for following 60 samples. Finally, analyzes the results by the methods of evaluation error and average relative error.
traff c prediction; LIBSVM; model training; sample set
TN929.5
A
1008-5599(2014)09-0080-04
2014-07-08
猜你喜欢
九江职业技术学院学报(2022年1期)2022-12-02 09:46:54
新高考·高一数学(2022年3期)2022-04-28 07:02:46
保定学院学报(2022年2期)2022-04-07 02:26:50
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19 08:28:36
中小企业管理与科技(2019年3期)2019-03-07 06:31:08
许昌学院学报(2018年4期)2018-05-02 12:27:37
中华建设(2017年1期)2017-06-07 02:56:14
湖南邮电职业技术学院学报(2016年1期)2016-10-18 01:43:05
高中生学习·高三版(2016年9期)2016-05-14 09:12:05
新高考·高二数学(2015年11期)2015-12-23 18:17:44
