
几种基于XML的流式文档访问方式分析
2014-02-09 07:46:52田英爱刘旭红
计算机工程与设计 2014年4期
唐 燕,田英爱,李 宁,刘旭红
(1.网络文化与数字传播北京市重点实验室,北京100101;2.北京信息科技大学计算机学院,北京100101)
0 引 言
在信息化建设发展的过程中,作为信息主要载体的文档,成为我们工作生活中不可或缺的一部分,其中对基于XML格式的流式办公文档的应用最为广泛[1]。目前世界主流的流式办公文档格式主要有3种:标准为ISO/IEC 26300:2006的开放文档格式(open document format,ODF)[2]、标准为ISO/IEC 29500:2008的OOXML(office open XML)[3]以及标准为GB/T20916-2007的标文通(uniform office format,UOF)[4]。这3种流式文档格式都基于XML,相应的处理技术也由原来的VBA、宏等方式逐渐过渡到利用XML相关技术进行处理。
在早期,用户对流式文档的操作,主要基于办公文档处理软件,并可以使用VBA、宏等方式扩展对办公文档的处理。带来的问题是,传统的方式效率低,速度慢,所能处理的文档格式单一,因其过分依赖办公软件产品,使之对于不同格式的流式文档而言,无法通过同一个办公软件实现操作互通,给用户带来不便。
流式办公文档采用基于XML的格式之后,对XML文档的各种访问技术也被用于对流式办公文档的处理。针对基于XML格式的文档,出现了很多XML数据访问技术,如:XPath、XSLT、DOM和SAX、XQuery、LINQ、相应格式的API/SDK、UOML、ODQ等。
本文针对流式文档处理的需求,对XQuery、DOM、相应格式的API/SDK、ODQ这4种流式文档处理技术进行了较细致的研究,并从基本查询功能、处理流程、格式无关性、查询粒度等多方面进行了分析比较。
1 流式文档处理需求与处理技术
1.1 流式文档的处理需求
随着对流式办公文档应用领域的不断扩展,对其访问与操作的需求也呈现了多样化的趋势,具体如下:
(1)格式无关性需求。由于目前存在的流式办公文档格式不统一,对文档内容的访问与操作都要依赖于支持相应格式的办公软件产品,无法实现离线文档操作。因此需要有一种统一的方式,能够对各种格式文档进行相应的访问与操作,以屏蔽文档底层存在的格式差异,实现文档格式的互操作;
(2)文档访问查询粒度适中性需求。对于流式办公文档而言,用户常常希望能够以段落、列表、表格、图片等基本元素,即文档的功能点[5]进行访问与操作,而目前对于流式办公文档的访问操作,要么是利用文档中提供的元数据对整个文档实现获取,粒度较粗糙,无法很好地从文档真实的内容中准确获得数据,很多流式文档的数据资源无法得到有效的共享和利用;要么就是利用XML的相关技术,访问文档的结构粒度过于细致,效率不高的同时,也不利于流式文档上下文环境内容理解。因此,流式办公文档访问查询粒度的适中性,也成为流式文档得以进一步应用的阻碍;
(3)文档操作的简便实用性需求。利用XML技术对流式文档进行访问,无论是专业开发人员还是普通用户,都需要学习复杂的语言及编程思想,编写繁琐的代码,并且,对文档逻辑结构要有一定的了解,访问方式不够简单。此时,迫切需要一种简便实用的流式文档访问技术。
1.2 流式文档处理技术
访问流式办公文档的处理需求的增加,使得相应的处理技术变得非常关键。这里给出XML数据访问技术的简要介绍:
(1)XPath。W3C的XPath主要是对XML文档底层元素和属性等节点直接进行操作的技术,它是直接针对XML的树形结构的路径表达式导航来定位XML文档中的各个节点。表达直观,但表达式构造复杂容易出错,如果不借助其它工具,则需要手工编写完成,耗时耗力[6]。
(2)XSLT。XSLT是以XPath为基础发展起来的,是利用XPath获取所需节点,并进行相应处理,但表达能力有所限制,不够灵活。
(3)DOM和SAX。DOM技术是利用树型结构来对XML文档中的各个元素(节点)进行处理,使对XML的文档处理更为灵活,但DOM处理需一次将整个XML文档载入内存,尤其是对于规模较大的XML文档,其处理速度较慢[7];为避免DOM加载慢的问题,SAX技术被提出来,利用SAX处理时,不是一次性把整个文件加载到内存中,而是对XML文件按其对应节点的访问次序,将文件的一部分加载入内存[8],相比DOM处理速度大大提升。
(4)XQuery技术。XQuery的查询描述能力较强,相比其它访问方式来说,可支持多文档联合查询[9],但语言过于复杂,普通用户不易完全掌握。
(5)LINQ技术。随着对文档访问技术的简化需求增加,微软在Visual Studio 2008中引入了LINQ,其关键技术包括LINQ to XML,该技术提供了一套比DOM更轻量的API,相比使用以往的操作方法,使得处理XML更为容易[10]。
(6)相应格式的API/SDK。目前主流的流式办公文档格式ODF,OOXML以及UOF,都提供了相应的API或SDK,那么,利用API或SDK来对流式文档的访问就可以直接针对文档的功能点进行直接获取并进行各种操作,便于实现对文档的进一步应用或二次开发。
(7)UOML。UOML是OASIS的正式标准,是电子文件领域针对基于XML的版式文档的接口标准,它定义了一整套非结构化文档的操作规范[11],可以很方便地对版式文档进行访问与操作,屏蔽底层细节问题,能够实现不同格式文档的互相读写。
(8)ODQ。ODQ是一种专门针对流式办公文档的访问技术[12],它从用户使用需求出发,能够脱离办公软件,利用较为通俗的语句,对不同格式的文档直接获取其局部内容并进行相应的操作,方便用户使用;同时对开发人员来说,能够屏蔽底层的操作细节,使之更专注于上层应用开发。
2 流式办公文档查询的典型方法
目前,流式办公文档多采用文件打包形式,例如ODF、OOXML以及UOF都支持zip打包结构,因此对流式文档进行访问查询时,首先必须对其进行解压,生成多个XML文件,此外,由于流式办公文档中除了包含呈现给我们的具体逻辑内容(文字、表格、图片等)外,还有诸多的显现式样信息和页面版式信息,这些信息都分散在流式文档解压后的各个XML文件中,在对流式文档访问处理时,就必须先识别即将访问的信息在流式文档中的哪个XML文件中,这就要求处理人员具有一定的专业知识。
本节以XQuery、DOM、相应格式的API/SDK这3种对流式办公文档的主流查询方法为例,分析各自查询的实现机制以及在访问流式文档方面的不足之处。
2.1 DOM方法
DOM是跨平台、与语言无关的,访问XML的标准接口。在利用DOM处理XML文档时,文档模型以树型的数据结构映射到内存中,并将文档中的元素、属性等看作树结构的各个节点。那么,开发人员对文档中各个对象的访问操作,就可以通过DOM解析器中提供的相应接口来实现动态访问和更新XML文档中的各个节点。DOM解析器在解析文档的时候可以遍历到树的任意节点,还可以通过添加、删除或更新树中的节点把源文档转换为其它结构的文档[7],以实现对文档中各个对象的操作。
当利用DOM对流式文档进行访问时,首先,需要将办公文档解压并生成多个XML文件,必要时还需要将解压后的多个XML文件进行合并,生成一个较大的XML文件;其次,需要根据用户的需求,由编程开发人员明确所要访问的文档对象在哪些具体XML文件或合成文件的哪些部分中,并且确定所要获取的对象包括了XML文件中哪些具体的节点;第三,构造DOM解析器,将确定的XML文件中的内容分成独立的元素、属性和注释等[13],装入内存;第四,实例化XML文件的XmlDocument类,在内存中生成描述XML文件的类,同时生成包含所有节点的树状结构,通过调用DOM提供的各种接口,遍历访问结构树中的节点,读取节点值并进行相应操作。DOM对流式文档的查询过程如图1所示。

图1 DOM查询过程
通过以上对处理过程的分析并在编程实践中发现,利用DOM对流式办公文档访问和处理时,存在一些问题,主要体现在以下几个方面:
(1)在对流式办公文档的访问处理时,用户通常直接针对文档的功能点进行访问处理,这些功能点不但包括了文档的逻辑内容,还包括修饰文档逻辑内容的式样信息或页面版式信息,这些信息会不规则地散布在文档中的各个部分,那么对于文档的某个具体功能点而言,其操作就不仅仅是XML文件的某个局部的节点信息,还可能需要处理和获取多个文档或文档的多个部分。这就需要开发人员对文档内部结构有深入的了解,并能够识别具体需要访问的内容在哪个文件中或文件的哪个部分,不能以较简单的方式直接访问文档。
(2)DOM方式中,每一次对普通XML文档内容的定位都是获取或修改文档中的节点,这些属于细粒度的操作。对于操作流式文档的用户来说,大多需要的是针对文档功能点的操作,如获取文档段落、图形、表格、式样信息等。文档功能点在XML描述时,需要用多个元素和属性进行描述,若用DOM方式进行访问操作时,则需多次调用DOM的各种接口,给编程带来复杂性。
(3)流式文档中,若要使逻辑内容和式样内容分离,文件结构中必然会存在大量的引用关系。需要根据所要访问的对象找到其关于式样的引用标识符,再通过标识符定位到所需式样,这时,可能需要重新遍历,或者再去寻找其它XML文件,对于专业开发人员来说,需要编写复杂的程序代码以获取所需信息。
还有一种与DOM类似的方法SAX,它不会一次性读取全部文档中的数据,而是将所需部分读入内存[14],是一种快速读写XML数据的方式。SAX访问方式尽管比DOM处理速度快,但仍然没有办法避免DOM在处理流式文档时存在的缺点。
2.2 XQuery方法
XQuery是基于一种XML结构的表达式语言,其查询被描述成简单的或是嵌套的表达式。XQuery应用XPath和FLWR表达式进行查询,建立在XPath规范之上[15],其核心是能够通过XPath表达式获取和操作文档中的节点序列,这也正是访问处理流式文档功能点的本质所在。这一点,XQuery比DOM方式更适合流式文档查询。在解析XML文档时,用一段XQuery表达式,通过XQuery处理器进行分析和计算,返回一个序列的值写入到XML文件中作为查询结果。
XQuery和DOM语言类似,对于一个流式文档的查询,都需要先将整个流式办公文档解压生成多个XML文件,并且对所要获取的数据是逻辑内容文件还是式样内容文件进行文档结构的识别。但是,对于编写的用于访问与操作的XQuery语句,需要单独保存于后缀名为.xquery的文件中。其次,启动XQuery处理器,以生成内部可解释代码,通过程序调用外部.xquery文件,解析出其中包含的查询条件、查询对象、查询结果格式;最后,执行查询语句并返回结果。一个基本的XQuery访问流式文档的处理过程如图2所示。
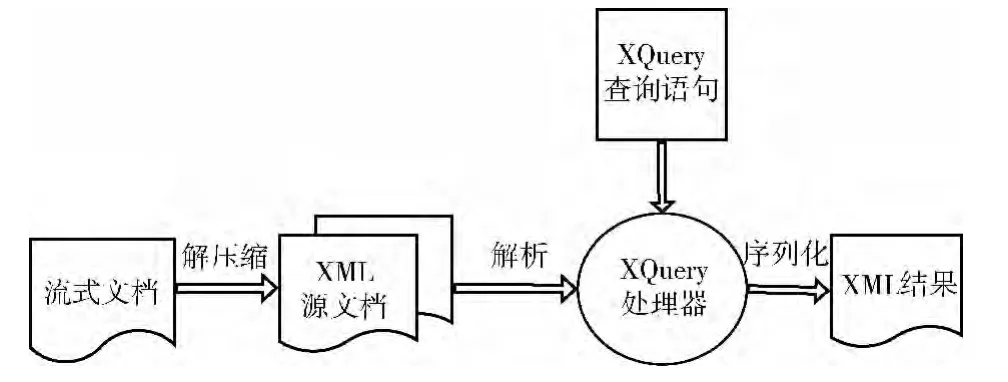
图2 XQuery查询过程
XQuery方法访问流式文档,也有其明显的不足之处:
(1)同样地,随着对通用XML文档操作功能需求的增加,XQuery方式也显示出访问粒度过细的问题,与文档功能点的访问处理粒度不符;
(2)W3C对XQuery不断进行更新,从最初的支持XML数据更新功能到支持动态网页开发和分布式软件开发,其功能正日益强大。但由于XQuery的嵌套和多关键字排序特性,使得其查询处理的复杂度增加[16]。此外,如前文所述,和DOM方式中存在的引用问题一样,专业开发人员需要编写复杂的程序代码;
(3)开发人员也是需要明确了解待查XML文档的内部结构,访问方式不够简单化。
2.3 API/SDK方法
为了能更有针对性的对流式办公文档的各个功能点进行提取,并以此进行更多的二次开发和扩展应用,各大标准组织机构和办公软件厂商都提供了对其相应格式文档功能点进行访问操作的API,如主流办公文档格式ODF、OOXML、UOF均设计了比较完善的应用编程接口。API将对XML文件的操作进行封装,为办公软件用户提供独立的文档操作功能,常用的是对文档内容的增、删、改、查操作,还包括一些基本式样的修改等操作,可以直接对办公文档的功能点进行操作。对于大多数API方法来说,处理步骤如下:
(1)创建一个代表整个文档的文档对象;
(2)利用API中相应的代表文档功能点的类定义所要访问的文档功能点对象;
(3)通过(1)中创建的文档对象调用API中提供的获取段落集、列表集等函数,返回代表指定文档所要访问的功能点对象的集合,用(2)中定义的对象接收这个集合;
(4)利用(3)中的对象获取到所要访问的功能点;
(5)取出功能点的值并返回结果。
API是直接面向流式文档各个功能点而设计的接口,使文档的应用不再依赖具体的办公软件产品,用户无需了解复杂的文档底层结构便可直接访问流式文档的各功能点,且访问较高效、简洁快速。此外,还方便了办公文档的在线处理以及文档的协作处理,为文档和其它应用的集成奠定基础,比DOM和XQuery更适合流式办公文档的查询处理。但是API方法仍表现出如下缺点:
(1)目前许多格式的API依赖于自身的产品。如ODF的API有其专门的UNO架构,OOXML的API则需要VBA/.NET和Windows环境,避免不了平台和语言的相关性[1]。3种文档格式的差异,导致相应格式的API只能针对各自的格式文档进行访问,格式的互操作问题存在障碍;
(2)虽然避免了对XML文档内部逻辑结构的直接操作,但仍需要专业开发人员具备一定的编程能力,且针对不同格式的文档访问需要了解不同的API或相应格式的SDK。
3 ODQ查询方法
目前对流式办公文档格式互操作要求提高,对文档功能点需要能够直接获取和操作,针对这类需求,本课题组在文献[12]中提出了ODQ,它是一种主要针对流式办公文档的新型查询语言,建立在三大主流办公文档格式对应API之上,是一种更高层次的API,对不同格式的文档可以直接获取其局部内容并进行相应的操作。目前,关于ODQ的需求分析、流式文档模型的构建、ODQ的形式化描述都已完成。
对于流式文档的主要功能点,用该方法可以实现概念级别的查询和操作,即类似元数据、段落、表格、图片这类的访问对象。不仅符合用户的使用习惯,也方便开发人员对所需内容数据的提取和进一步操作。
本节中,将围绕ODQ对其进行查询示例、架构及处理过程的描述。
3.1 ODQ查询示例
在ODQ设计中,定义了抽象的文档模型,将文档分为多个对象,对应于不同的文档功能点,对流式文档功能点的访问,都可看为是对这些对象及属性的操作。ODQ基本语法主要包括操作命令、操作对象和关键字。操作命令包括查询文档内容(GET)、删除对象(DELETE)、插入对象(INSERT)、更新对象(UPDATE SET)、统计对象(COUNT)等,前4种命令作为基本操作命令,COUNT作为统计命令,区分出对流式文档功能点的查询、删除、修改和统计操作;操作对象分为节(Section)、段落(Paragraph)、图片(Picture)、列表(list)、表格(table)等可直接访问的文档功能点;操作命令和操作对象通过关键字WHERE、FROM、of、AS、ALL、with、after、before等联系起来,并结合基本表达式运算符@、=、括号、&&、|等,共同构成了基本的ODQ语法。基本命令表达如下所示:
(1)查询获取命令GET
GET[@属性1,[@属性2]…|式样1,[式样2]…of]对象[all|序号|范围]
FROM Url/Document[of对象[all|序号|范围]]…
[WHERE{@属性1=值1,[@属性2=值2…]|式样1=值1,[式样2=值2]…}];
(2)更新修改命令UPDATE SET
UPDATE{[对象[序号|all][[of对象]…]}
SET{@属性1|式样1}of对象[序号|范围|all]AS{值1},
[{@属性2|式样2}of对象[序号|范围|all]AS{值2}…]
[WHERE{@属性1=值1,[@属性2=值2…]|式样1=值1,[式样2=值2]…}];
(3)删除对象命令DELETE
DELETE对象[序号]|[范围]|[all]
FROM {对象[序号|all|范围][of对象…]}
[WHERE{@属性1=值1,[@属性2=值2…]|式样1=值1,[式样2=值2]…}];
(4)插入对象命令INSERT
INSERT{Text|Rich Text|对象}
BEFORE/AFTER对象[[序号]of对象…]
[WHERE{@属性1=值1,[@属性2=值2…]|式样1=值1,[式样2=值2]…}];
(5)统计计数命令COUNT
COUNT对象FROM对象[[序号]of对象…]
[WHERE{@属性1=值1,[@属性2=值2…]|式样1=值1,[式样2=值2]…}];
这里以查询文字处理部分中的对象为例,简要给出ODQ对办公文档的一般查询。
(1)针对段落的操作
命令:GET Paragraph
FROM Section[1]of Document
WHERE FontSize=11;
功能:得到某个文档第一节中所有字号为11的段落
命令:UPDATE Paragraph[1]
of Section[1]of Document
SET Text AS“first Paragraph”;
功能:将某个文档中第一节下第一个段落内容设置成纯文本内容“first Paragraph”
(2)针对图片的操作
命令:GET Picture
FROM Paragraph[2]
of Section[1]of Document
WHERE@Pic Type=”jpg”
功能:从某个文档的第一节的第二段中查询所有格式为jpg的图片
命令:INSERT d:\20130619.jpg
BEFORE Run[1]of Paragraph[1]
of Section[1]of Document
功能:在某个文档的第一节的第一段的第一句之前插入图片20130619.jpg
从上述查询示例中,可以看出ODQ方式绕开文档结构的复杂性,用户不必考虑流式办公文档内容和式样混排后的结构,在应用层使用简单的形式构造查询语句即可进行处理,易于接受和使用。
3.2 ODQ架构及其处理过程
ODQ的整个架构分为解析器、抽象的文档模型、转换适配器3个主要部分。解析器对用户发出的ODQ命令进行语法和词法分析;抽象的文档模型综合ODF、OOXML以及UOF三大主流办公文档的文档模型,定义针对办公文档常用的操作对象及属性;转换适配器将办公文档中用户想要访问的对象及属性与抽象的文档模型进行映射。ODQ的系统整体架构如图3所示。
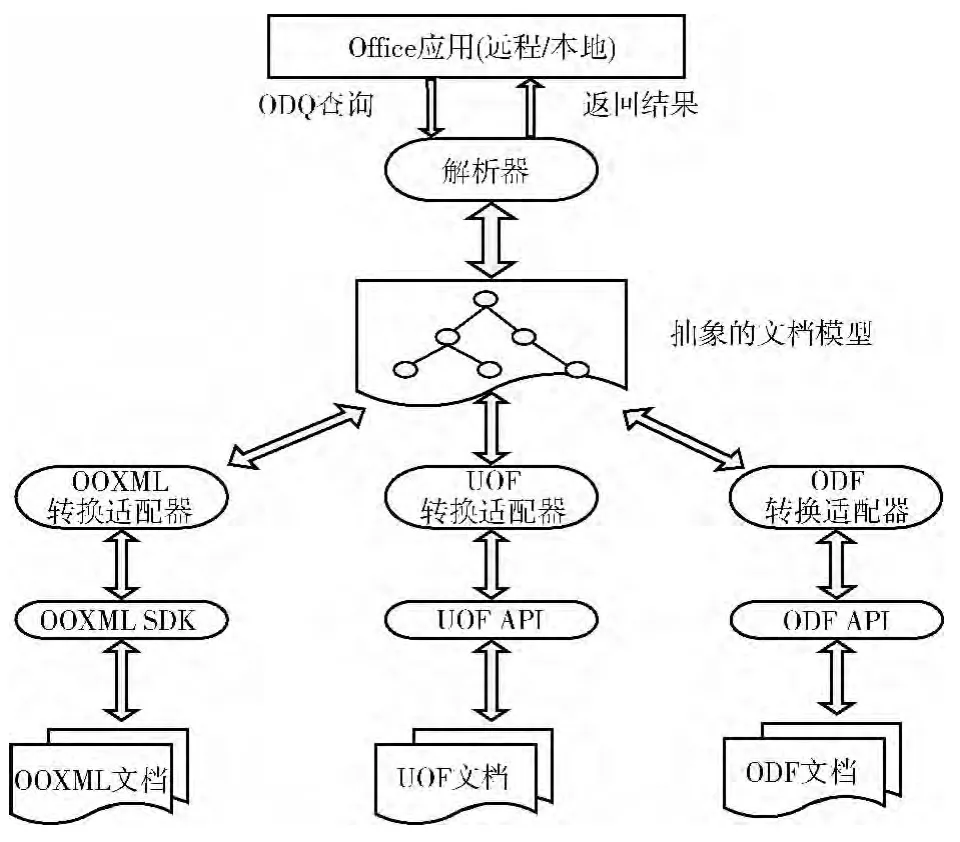
图3 ODQ系统整体架构
通过ODQ架构的介绍,对流式文档的访问与操作的处理步骤如下:
(1)解析器解析ODQ语句,识别出关键字GET、UPDATE、DELETE等以及要访问的对象和属性,以备之后到相应功能的API映射;
(2)将段落、图片和表格等对象和属性映射到抽象文档模型;
(3)适配器机制检测目标文档格式,得到对应格式的转换适配器;
(4)相应适配器将中间代码转换成目标代码;
(5)调用对应格式的API,根据(2)中抽象文档模型里的对象和属性访问文档中的数据内容;
(6)将获取到的数据内容经转换适配器映射到文档模型中,再由解析器将得到的结果返回给用户。
在ODQ的设计过程中,查询语句不仅支持常见的本地办公文档访问操作,而且考虑到了文档远程网络访问应用的需求;通过基于抽象文档模型设计出的ODQ底层架构,开发人员可以绕开对复杂文档内部结构的直接访问。
4 方法比较
上文中,对ODQ的形式语句进行了介绍,并分析了架构及处理过程,不难看出,使用ODQ对流式文档进行访问,与前3种访问方式进行比较,其优越性体现如下:
(1)针对流式文档,屏蔽文档格式和版本的差异,为用户提供统一的访问接口,达到了格式无关性;
(2)ODQ具有类似SQL的语法结构,符合用户使用习惯,代码简洁,开发人员无需花费过多时间去学习复杂的查询语言,只需发出“做什么”的命令,而不用考虑“怎么做”。为操作流式办公文档带来了很大的方便。
(3)查询粒度方面,与前3种访问方式做比较,如表1所示。因为需要的是通用文档操作功能,不是进行细粒度的访问,并不需要深入了解文档内部结构,在这方面,可以体现出ODQ和API的优越性。
(4)将在基于B/S结构的Web应用中,ODQ封装进协议中,大部分内容放在服务器端,对于客户端来说,不会耗用很大内存,可以较为快速地提取所需信息;
(5)在Web应用方面,文献[12]中对ODQ的返回值形式进行了扁平化研究,可以将访问结果以更容易的方式进行网络传输并解析。
综合上述分析,这里给出4种流式文档访问方式在代码精简度、查询粒度、对不同格式流式文档间互操作能力支持以及操作简便性的比较,见表1。
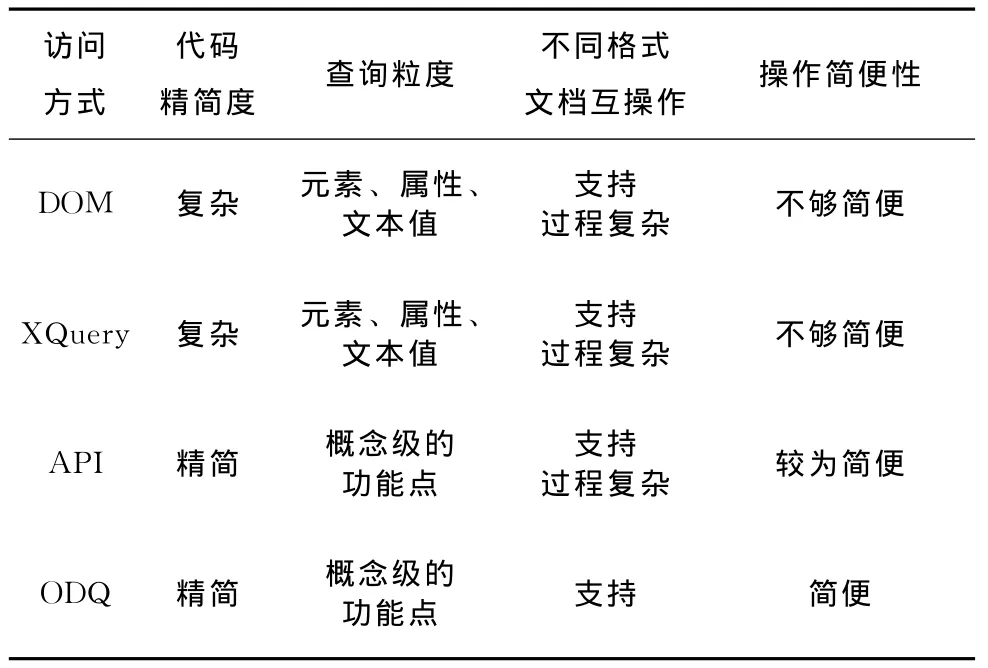
表1 4种访问方式比较
5 结束语
针对流式办公文档的新需求,本文较为系统地分析了XQuery、DOM、相应格式的API/SDK、ODQ这4种流式文档处理技术,从多方面进行分析比较的结果可知:ODQ是一种有发展前景的文档处理语言,将来可应用于桌面或基于Web的办公文档系统中,用于对文档进行访问与操作;对于Web应用,还可以通过HTTP协议,封装用户的查询请求和查询结果;在多人协同文档编辑方面,可方便地与某种宿主语言一起进行文档的二次开发、方便文档协议的构造;另外,在文档管理和电子政务等领域,也可得到广泛应用。
未来本课题组将围绕该查询语言进行与Web的结合,将ODQ封装到协议中,使对ODQ的处理能够扩展到网络以及其它应用领域。此外,关于文档的安全性也会做到重点考虑。
[1]TIAN Ying'ai,LI Ning,LIN Li,et al.Study and implementation of UOF 1.0 API specification[J].Journal of Beijing Information Science and Technology University,2011,26(2):30-35(in Chinese).[田英爱,李宁,林莉,等.“标文通”1.0 API规范的研究与实现[J].北京信息科技大学学报,2011.26(2):30-35.]
[2]OASIS.ISO/IEC 26300-2006:Information technology--Open document format for office applications v1.0[S].2006.
[3]ISO/IEC 29500-2006:Information technology--Document description and processing languages--Office open XML file formates-Par1-4[S].2008
[4]Chinese Office Software Basic Standards Working Group.GB/T20916 22007:Chinese office document format specification for the national standard of the People's Republic of China[S].Beijing:Standards Press of China,2007(in Chinese).[中文办公软件基础标准工作组.GB/T20916 22007:中华人民共和国国家标准中文办公软件文档格式规范[S].北京:中国标准出版社,2007.]
[5]LI Ning,LIANG Qi,HOU Xia,et al.Interoperability measurement of documents[J].Journal of Beijing Information Science and Technology University,2011,26(2):6-12(in Chinese).[李宁,梁琦,侯霞,等.文档互操作度量[J].北京信息科技大学学报,2011,26(2):6-12.]
[6]GONG Sha.XML-based database query system design[J].Coal Technology,2011,30(7):144-146(in Chinese).[龚莎.基于XML的数据库查询体系设计[J].煤炭技术,2011,30(7):144-146.]
[7]LUO Wentian,HOU Xia.An overview of converters between XML-based main office document formats[J].Journal of Beijing Information Science and Technology University,2010,12(Z2):109-116(in Chinese).[罗文甜,侯霞.基于XML的主流办公文档格式间的转换器研制情况概述[J].北京信息科技大学学报,2010,12(Z2):109-116.]
[8]LIU Yuxiao.Analysis and research of XML data analytical technique based on SAX[J].Modern Electronics Technique,2010,34(12):55-65(in Chinese).[刘雨潇.基于SAX的XML数据解析技术分析研究[J].现代电子技术,2010,34(12):55-65.]
[9]LI Xiaoqing,LIAO Husheng,ZHANG Xiaobo.Survey of XQuery implementation[J].Computer Science,2012,39(3):9-18(in Chinese).[李小青,廖湖声,张晓博.XQuery实现技术研究综述[J].计算机科学,2012,39(3):9-18.]
[10]ZHANG Xuejun.Application of using LINQ to XML to operate XML document[J].Digital Technology &Application,2010,28(12):44(in Chinese).[张雪军.使用LINQ to XML操作XML文档[J].数字技术与应用,2010,28(12):44.]
[11]WANG Donglin,JIANG Haifeng,ZHANG Changyou.UOML:An unstructured operation markup language[J].Information Technology and Information,2007,32(3):121-122(in Chinese).[王东临,姜海峰,张常有.UOML:一种非结构化操作标记语言[J].信息技术与信息化,2007,32(3):121-122.]
[12]LING Feng,LIU Xuhong,TIAN Ying'ai,et al.Flatten de-sign of open document query[C]//The International Conference on Cyberspace Technology,2013(in Chinese).[凌峰,刘旭红,田英爱,等.流式办公文档查询语言ODQ的扁平化研究[C]//国际网电空间技术大会论文集,2013.]
[13]WEI Xiaojuan,RAN Jing,LI Aihua,et al.XML parse and application based on DOM[J].Computer Technology and Development,2007,17(4):86-88(in Chinese).[蔚晓娟,冉静,李爱华,等.基于DOM的XML解析与应用[J].计算机技术与发展,2007,17(4):86-88.]
[14]FAN Shuyi,LI Yan,MENG Chen.Use SAX and DOM together to parse XML document[J].Microcomputer Applications,2011,27(12):42-44(in Chinese).[范书义,李岩,孟晨.XML文件解析中SAX和DOM的结合应用[J].微型电脑应用,2011,27(12):42-44.]
[15]LU Hao.Research on XQuery query over XML update streams[D].Baotou:Inner Mongolia University of Science and Technology,2010:1-62(in Chinese).[路皓.XML更新流的XQuery查询处理技术研究[D].包头:内蒙古科技大学,2010:1-62.]
[16]WU Xiaoyong,ZHANG Yu,SUN Donghai.Structural join in XQuery processing on XML stream[J].Computer Engineering,2008,34(4):63-70(in Chinese).[吴晓勇,张昱,孙东海.XQuery在XML流上查询的结构化连接[J].计算机工程,2008,34(4):63-70.]
猜你喜欢
工程与建设(2019年5期)2020-01-19 06:22:38
文化学刊(2019年12期)2019-12-26 06:56:36
中国信息化周报(2019年18期)2019-06-09 10:31:08
东方藏品(2018年9期)2018-09-10 02:59:51
城乡建设(2017年5期)2017-06-01 12:19:20
光学精密工程(2016年1期)2016-11-07 09:01:17
西南石油大学学报(自然科学版)(2015年4期)2015-08-20 09:05:28
江苏教育·中学教学版(2015年3期)2015-05-13 02:02:05
电脑迷(2015年12期)2015-04-29 23:22:51
电脑爱好者(2015年6期)2015-04-03 01:20:56
