
自由文本中汉语缩略语的自动抽取
2014-02-09 07:46:36张雷瀚吕学强
计算机工程与设计 2014年4期
张雷瀚,吕学强,李 卓
(北京信息科技大学网络文化与数字传播北京市重点实验室,北京100101)
0 引 言
缩略语作为一类典型的未登录词,在给人们的交流提供便利的同时,也给自然语言处理带来了很多挑战。例如,汉语分词、机器翻译以及信息检索等都无法避开缩略语问题。解决这些问题需要缩略语对照表资源的支撑,而自由文本中缩略语的自动抽取是获取缩略语资源的方法之一。
缩略语(记为A),在构造形态上是由一个较长的短语经过压缩、概括等操作,形成的长度缩短、意义不变的特殊“短语”。压缩之前的形式称为完整形式或全称(记为F)。为了方便,下文使用“缩略语对”表示“缩略语与对应完整形式”(记为(A,F))。
完整形式变换为缩略语有3种主要形式:缩合、截略和统括[1]。所谓缩合,是指将完整形式按照语义分成几部分,保留各部分中最能代表原义的字或词组合成为缩略语,如“调研(调查/研究)”。所谓截略,是指截取完整形式中某个连续的子字串作为缩略语,如“解放军(中国人民解放军)”。所谓统括,是指把完整形式的并列成分中共有的字、词或短语抽取出来,在其之前添加相应的数词或者数量短语,组合形成缩略语,如“三军(陆军、空军、海军)”。根据缩略语的形成方式,可以把缩略语相应地分为3类:缩合类、截略类和统括类。
目前已经有很多针对缩略语的研究。英语缩略语的研究工作主要集中在缩略语与完整形式的对应关系挖掘以及歧义消解。对应关系挖掘是指从文本中抽取缩略语及对应完整形式,得到缩略语与完整形式对照表。Okazaki[2]等提出了一个基于最大熵判别式的缩略语识别模型。此外,Stevenson[3]等使用朴素贝叶斯和支持向量机,对英语缩略语的歧义消解进行了研究。
汉语缩略语与英语缩略语有很大不同。其一,汉字本身蕴涵语义信息,而英文字母本身不代表特别的概念,这就导致汉语缩略语与英语缩略语的形成方式有所不同;其二,汉语缩略语中的非一对一现象远远少于英语缩略语。
鉴于以上不同,汉语缩略语的相关研究主要集中在:完整形式的缩略、缩略语的扩展、缩略语识别以及缩略语与完整形式的对应关系挖掘[4]。Sun[5]利用支持向量回归的方法对完整形式的缩略进行了研究。焦妍[6]利用条件随机场对完整形式进行标注,获得缩略语候选,然后借助搜索引擎对候选缩略语重新排序。谢丽星[7]从搜索日志和锚文字的主题相关性出发获取候选缩略语对,准确率达到了68.3%。该研究以搜索日志和锚文字为实验语料,方法本身具有一定的特殊性。刘友强[8]提出了一种从英汉平行语料库中获取中文缩略语的方法。
综上所述,当前缩略语对应关系挖掘的相关研究存在一些不足之处:方法仅适用于某些特殊的语料,通用性不强;操作复杂,且自动化程度不高;对应关系挖掘的准确率较低。
对袁晖的《现代汉语缩略语词典》[9]中八千余条缩略语对进行统计,发现缩合类缩略语占据了八成以上的比例。据此,本文以缩合类缩略语为研究对象,提出了一种从自由文本中自动抽取缩略语对的方法。分析缩略语与完整形式的词性构成规律,设计词性模板匹配法,获取候选缩略语与候选完整形式;并按照“字对齐”和“一对一”等约束规则匹配得到候选缩略语对。通过分析缩略语与完整形式之间的关联特性,分别从新闻文档、百科知识、搜索引擎的锚文字以及《知网》等相关资源中获取缩略语对的3组特征,构造决策树,进而判别候选缩略语对的真伪。
1 候选缩略语对的获取
缩略语和完整形式的识别是缩略语对应关系挖掘的基础。观察发现,缩略语和完整形式的词性构成存在一定的统计规律,且二者之间存在字词对应和统计共现的特性。据此,本文提出了词性模板匹配法和基于规则的缩略语配对法。
1.1 候选缩略语及完整形式的抽取
当前很多研究借助专用分词词典对缩略语进行定位。然而,缩略语的数量庞大,且随着时代的变迁而不断消失和产生。这就意味着要花费大量的人力、资金构造来维护此类词典。此外,缩略语的领域性和地域性也增加了构造这类词典的难度。
在术语抽取领域,短语的词性结构常被作为挖掘候选术语的依据。类似的,缩略语与完整形式也存在一定的词性结构。对《现代汉语缩略语词典》[2]收录的缩略语对进行统计,发现缩略语的词性模板频次分布遵循帕雷托法则(Pareto principle),即二八定律——约20%的词性模板的出现频次占据了约80%的模板总频次。完整形式的词性模板频次分布也遵循同样的规律。限于篇幅,只给出缩略语的词性模板频次分布图,如图1所示。

图1 缩略语词性模板的散点分布
上述词性模板频次的分布规律意味着,可以使用频次较高的词性模板从文本中抽取候选缩略语和完整形式。选择频次大于α的词性模板,分别构建缩略语和完整形式的词性模板库,依次记为TA和TF。表1列举了缩略语的部分词性模板,其中“#”代表汉字。类似的,表2给出了完整形式的部分词性模板实例。
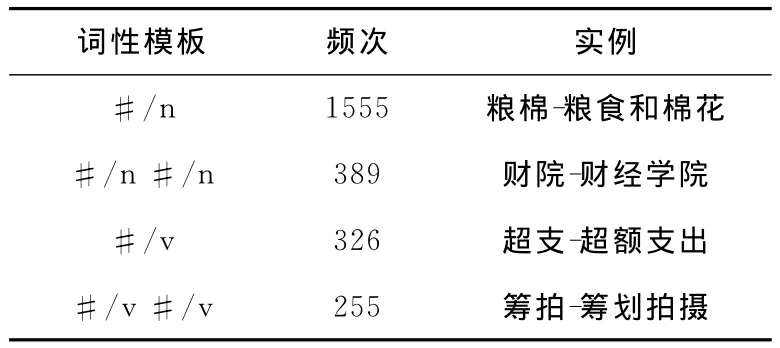
表1 缩略语词性模板实例
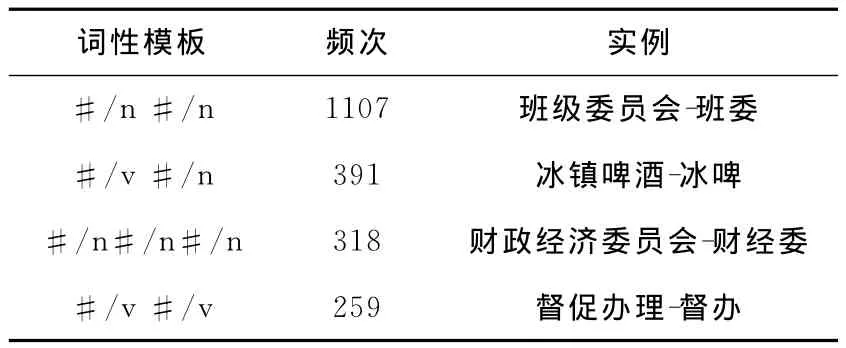
表2 完整形式的词性模板实例
有研究指出,汉语中长度大于、等于4的缩略语仅占总量不足1%的比例[5]。因此,根据构建的词性模板,利用模式匹配的思想,获取字长小于4且出现频次大于β的认定为候选缩略语;字长大于、等于4且出现频次大于γ的认定为候选完整形式。因为缩略语通常比完整形式有着更高的使用率,所以参数β的取值应大于参数γ。
1.2 缩略语与完整形式配对
缩合类缩略语中的字或词与完整形式中的词语存在一定的对应关系,即缩略语中的每个字或词都能在完整形式中找到一个词与之对应,本文将这一现象称为字面关联。此外,在文档集中,缩略语与其对应的完整形式趋向于聚集出现于同一篇文档的相邻区域内,本文将这种现象称为统计共现。综上,缩略语和完整形式在字面和统计两个方面存在一定的关联关系。本文从这两个方面出发,定义若干约束规则,对候选缩略语和候选完整形式进行配对。
定义 缩略语与完整形式的对应关系约束是一个三元组R=(Ai,Fj,A(Ai,Fj)),其中,Ai表示候选缩略语,Fj表示候选完整形式,A(Ai,Fj)表示Ai和Fj必须满足的约束规则集。
在对约束规则进行详细说明之前,列出将要使用的符号及函数。
s1、s2和s3代表字符串;
set表示文本集;
LCS(s1,s2)表示s1和s2的最长公共子序列;
uncon(s1,s2)表示s2不是s1的子字符串;
S(s1,λ)表示在百度搜索中搜索s1的返回结果集,即在百度搜索引擎中查找s1时返回的前λ条搜索结果的摘要集合;
exist(s1,set)表示字符串s1存在于文本集set中;
DF(s1,s2)表示字符串s1和s2在文档集中共现的文档数。
下面介绍约束规则:
约束规则1:非子串规则
形式表示
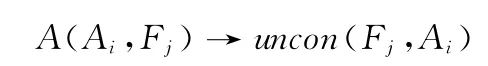
直观意义:对于缩合类缩略语,缩略语不能是完整形式的连续子字符串。
约束规则2:最长公共子序列规则
形式表示
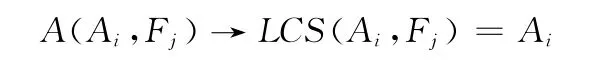
直观意义:缩略语中的每个字都可以映射到完整形式中,且在完整形式中必须有字词与之对应。
约束规则3:交叉共现规则
形式表示
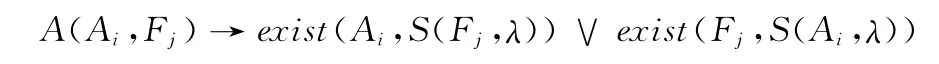
直观意义:缩略语与对应完整形式在文本中存在共现规律,而搜索引擎返回的结果蕴含丰富的缩略语信息。从统计的角度分析,缩略语应该在完整形式的搜索返回结果中出现或者完整形式应该在缩略语的搜索返回结果中出现。
约束规则4:一对一规则
形式表示
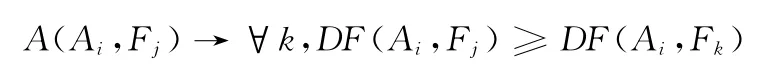
直观意义:本文研究的是一对一的缩略语现象,对于一个候选缩略语对应多个候选完整形式的现象,文档共现数最多的候选缩略语与候选完整形式最有可能是正确的缩略语对。
规则1和规则2是依据缩合类缩略语的字面关联特性设定的。规则3和规则4是利用缩略语与完整形式的统计共现特性,筛选得到一对一的候选缩略语对。
2 缩略语对的过滤
缩略语的形成受很多因素的影响,很难找到覆盖所有缩略语现象的完全统一的规律。分析缩略语与完整形式之间的关联关系,借助内外界资源,总结出3组关联特征,把候选缩略语对的判别问题转换为二元分类问题——候选缩略语与候选完整形式是否匹配。利用.3组特征构造ADTree(alternating decision tree)[10],进而对候选缩略语对进行过滤。
2.1 ADTree
ADTree的算法思想最早由Freund和Mason提出,是一种基于AdaBoost[11]的决策树学习算法。ADTree不同于一般的决策树,它的构成节点可以分为两类:一类是预测节点,另一类是决策节点。每个预测节点对应一个预测值。每个决策节点对应一个分裂判断,训练集中的样本元组经过一次分裂测试被划分到相应的预测节点中。ADTree模型通常通过t次迭代产生,t为经验值。一次迭代由评估分裂测试和执行分裂两个部分组成。前者评估所有的预测节点,得到最优分裂测试。后者只需对节点进行划分,生成新节点并更新样本元组。
ADTree能够有效地模拟小规模数据集中复杂的分类规则,多次迭代能够保证较高的分类准确率和鲁棒性。而缩略语与完整形式之间的关联关系也比较复杂,且缩略语的数据集规模也相对较小。因此,本文采用ADTree模型处理候选缩略语对的分类问题。
2.2 特征抽取
构造模型的关键是特征的选择。分析发现,缩略语与完整形式之间存在多种关联特征:缩略语和完整形式的字面语义相近、缩略语的构成字词趋向于均匀地分布于完整形式中、缩略语与完整形式在文本中的上下文存在一定的相似性[12]、缩略语与完整形式在百科文本中通常以关联的形式出现、缩略语与完整形式在搜索引擎的锚本文中存在共现现象、缩略语与完整形式在文本集中有较高的文档共现频率。以上特征可以归为3组:内在关联特征、外部语义特征和外部统计特征。内在关联特征描述的是缩略语与对应完整形式本身存在字面关联和语义同指特性;外部语义特征是指缩略语与对应完整形式的上下文语境存在一定的关联;外部统计特征指的是缩略语与对应完整形式在大规模文本集中所呈现出的统计规律。
2.2.1 内在关联特征
缩略语的形成遵循等义性原则,即缩略语表示的意义要与完整形式一致。缩略语和完整形式都是由若干字或词组成的短语,并且二者的组成字词之间存在一定的对应关系。本文提出基于《知网》的缩略语对相似度计算方法,通过计算缩略语与完整形式之间对应字词的语义相似度,得到缩略语与完整形式的语义相似度。
基于《知网》的词汇相似度计算方法[13],可以比较准确地计算两个中文词汇(单字词或多字词)的语义相似度。假设ui和vj为两个中文词汇,可以得到二者基于《知网》的语义相似度sim(ui,vj)。对于缩合类缩略语,构成缩略语的每个字都存在于完整形式中,而构成完整形式的词语在缩略语中却并非都有对应的缩略式。因此,可以把构成完整形式的词语分为两类:在缩略语中存在对应缩略式的一类和不存在对应缩略式的一类,依次用S1和S2表示。设A和F分别为缩略语及对应的完整形式,相应的S1={u1,u2,…,um},S2={w1,w2,…,wn},集合S1中的词语在缩略语中对应的缩略式集合为S3={v1,v2,…,vm}。例如,对于“二/战”和“第二/次/世界/大战”,相应的S1={“第二”,“大战”},S2={“次”,“世界”},S3={“二”,“战”}。借助《知网》语义相似度计算方法,计算A和F的语义相似度HS(A,F),方法如下

其中,m和n分别表示词集S1和S2包含元素的个数,sim(uk,vk)表示S1和S3中对应字词uk和vk的相似度,若二者的相似度为零,则使用一个极小值替代。
(2)缩略语对的覆盖均匀度
丁远钧[14]提出了缩略语对于完整形式的词汇覆盖重心的概念,以描述二者语义重心的重合度。完整形式通常由多个词语组成,在变换为缩略语时,完整形式的一个或多个词语可能被省略,但缩略语的构成字词趋向于均匀地分布在完整形式中。本文把缩略语中的字词在完整形式中分布的均匀程度称为覆盖均匀度,用以描述缩略语与对应完整形式之间字词覆盖的位置特性。
延用本节第一部分对A、F、S1和S2这4个变量的定义,设S1={u1,u2,…,um},S2={w1,w2,…,wn},cen(F)表示缩略语A对于完整形式F的词汇覆盖重心,直观意义为完整形式F中S1类词汇的位置中心。U(A,F)表示A和F的覆盖均匀度,量化表示为完整形式的S2类词语相对于cen(F)的距离的算术平均值
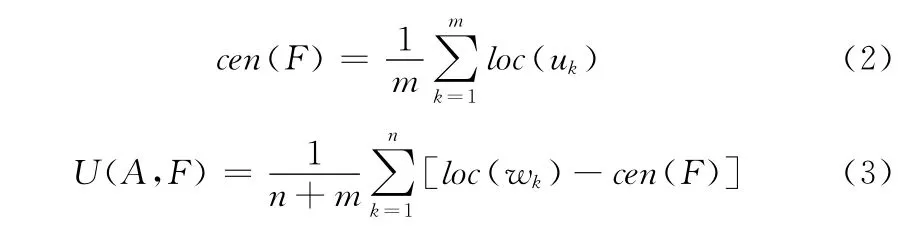
其中,loc(wk)表示wk在完整形式中相对于最左端词语的以词为单位的位置偏移量。
2.2.2 外部语义特征
除此以外,恶劣天气还影响车速、交通流量等。综合而言,恶劣天气对道路交通系统各要素的交通特性都有不同程度的负面影响,直接影响人们的工作生活出行。
(1)上下文相似度
缩略语与对应完整形式的指代意义相同,在同样的文本环境使用时存在一定的可替换性,可以认为二者具有相似的上下文[12]。因此,可以通过计算缩略语和完整形式上下文的相似度来反应缩略语与完整形式的匹配关系。
在文本中搜索包含目标短语的语句。由于不同的缩略语和完整形式在文本中出现的频次不同,抽取得到的对应语句的数量也相差很大。考虑上下文相似度计算的可操作性和有效性,从得到的包含目标短语的语句中随机选择ε个,并从目标短语的上文和下文各提取δ个词,最终获得A的上下文文本B(A),以及F的上下文文本B(F)。
文本对象T可以形式化地表示为TF(term frequency)向量TV=(tv1,tv2,…,tvn),其中tvi的取值为字典中第i个词在语料中的出现频次,i=1…n,n为字典收录字词的数量。对于B(A)和B(F),分别提取二者的TF特征向量TVA和TVF,通过计算向量TVA和TVF的余弦距离得到A和F的上下文相似度CS A,(F)

(2)基于百科知识的模式关联度
互联网的百科知识系统是利用“众包”(Crowdsourcing)的力量得到的知识库,通过大量人员整理、分析和筛选构建而成,蕴含丰富的可信度较高的缩略语信息。目前,百度百科收录了六百多万个词条,互动百科收集了七百多万个词条。在这庞大的知识库中,大量的缩略语与对应完整形式以关联的模式出现。如百度百科对缩略语“台海”有如下解释文本:台湾海峡(Taiwan Strait),简称“台海”。
对缩略语和完整形式在百科知识库中的关联出现现象进行观察和分析后,总结得到一个关联模式集。表3列举了本文总结出的4类关联模式,其中“*”代表汉字或者英文,“|”表示“或者”。

表3 关联模式及实例
如果候选缩略语对在百科知识中以前文所述的关联模式出现,那么二者匹配的概率就很大。本文提出基于百科知识的模式关联度的概念,在百科知识中,缩略语和完整形式能以表3中某种模式出现,则认定二者是关联的,用“1”量化这种关联现象,否则认为二者基于百科知识不关联,记为“0”。
2.2.3 外部统计特征
(1)基于搜索引擎的匹配度
焦妍[6]和谢丽星[7]的研究表明,搜索引擎的返回结果作为一种主题针对性较强的摘要性文本,蕴含密集的缩略语信息,对缩略语的对应关系挖掘有很强的辅助作用。缩略语和对应完整形式的统计共现规律在搜索引擎的返回结果中表现为:二者很可能共同出现于同一段摘要中。本文提出了基于搜索引擎的匹配度的概念,以缩略语和对应的完整形式在搜索引擎返回的摘要文本中的共现频次为主要依据,反映二者匹配程度的强弱。
候选缩略语对有3种主题组合方式:候选缩略语、候选完整形式和二者添加线索词后的组合形式。例如,“北大”、“北京大学”和“北京大学简称北大”。针对候选缩略语对的3类主题,可以得到相应的3类主题的返回结果。本文调用百度搜索分别得到3类主题的返回结果的前λ条摘要信息:SA表示以候选缩略语为查询对象获取的摘要文本集、SF表示以候选完整形式为查询对象得到的摘要文本集、SAF表示以候选缩略语对的线索词连接文字串为查询对象获取的摘要文本集。设T表示文本集,str表示字符串,CF(A,F,T)表示A和F在T中的共现频次,C(T,str)表示str在T中出现的频次。由于搜索引擎返回结果中的某些摘要信息为空,所以实际得到的摘要数目并非都为λ条,实际条数用size表示。
可以由式(5)计算得到基于文本集SA的A和F匹配度W1(A,F)
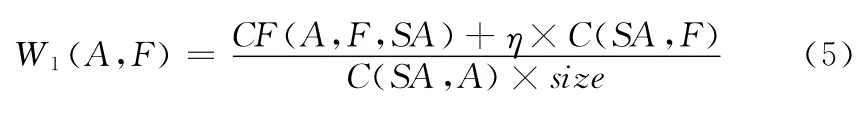
其中,C(SA,F)和C(SA,A)分别表示在摘要文本集SA中,候选缩略语A和候选完整形式F出现的频次,CF(A,F,SA)表示候选缩略语A和候选完整形式F在摘要集SA中共现的摘要数目。η为经验值,用于调节两个共现频次的影响权重。
类似的,可以计算由摘要文本集SF得到的A和F匹配度W2(A,F)
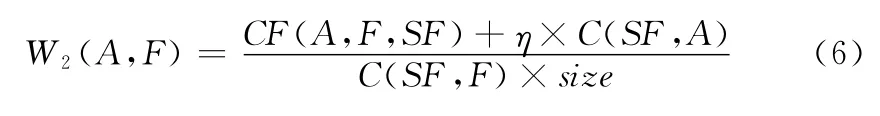
这里η与式(5)相同。
由摘要文本集SAF得到的A和F匹配度W3(A,F)
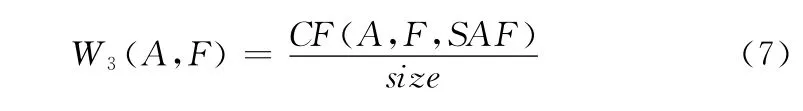
(2)文档共现频次比
缩略语与对应完整形式在大量文本中呈现出一定的统计规律。从单一文档的角度出发,当缩略语在正文中的某个位置出现,对应的完整形式在其附近的语句中出现的概率很大。这种分布规律反应到文档集中就表现为,二者共现的文档数与二者各自出现的文档数乘积的比值较大,本文称这个比值为文档共现频次比。二者的文档共现频次比越大,候选缩略语和对应的候选完整形式的匹配度就越高。
设CDF(A,F)表示候选缩略语对(A,F)在文档集中共同出现的文档数,DF(A)和DF(F)分别表示候选缩略语A和候选完整形式F在文档集中出现的文档数。A和F的文档共现频次比W4(A,F)的计算方法如下
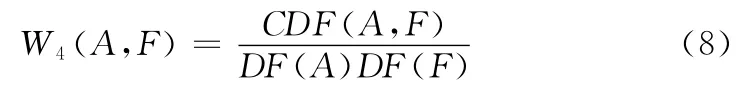
3 实验与分析
本文以2008年1-6月的搜狐新闻为实验语料,从中选择军事、旅行和健康3个领域的文本。经过去重、过滤等预处理,最终得到军事类文档14449篇,旅行类文档19883篇,健康类文档31859篇。把实验分为候选缩略语对的获取和构造ADTree进行缩略语对的过滤两个阶段进行。
对候选缩略语对的抽取结果,以准确率和候选缩略语对的数量作为评价指标;对ADTree的分类结果统计6个指标进行评价:ADTree模型判定为正确的缩略语对数量T1、判定为正确的缩略语对中实际正确的数量T2、候选缩略语对中实际正确的数量T3、准确率P、召回率R和F值,其中
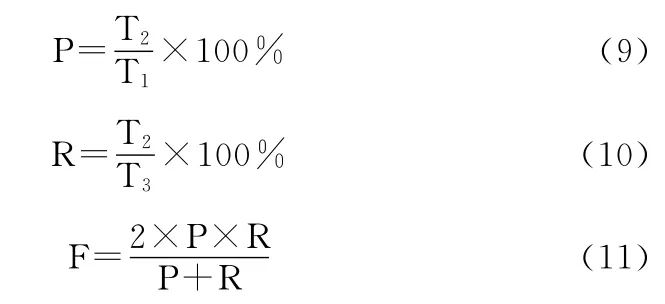
3.1 候选缩略语的获取
以袁晖的《现代汉语缩略语词典》[2]中的8321条缩略语对为数据源,选择在百度开放的搜索日志中出现过的3200条。使用ICTCLAS2013分词工具对缩略语和完整形式分词,按照1.1节所述方法,分别得到包含389个模板的缩略语词性模板库和包含472个模板的完整形式词性模板库。利用这些模板,分别从3个领域的语料抽取候选缩略语和完整形式,并采用基于规则的方法进行缩略语与完整形式的配对,得到候选缩略语对的结果。结果评测数据见表4。本步骤中的参数模板频次阈值α、候选缩略语频次阈值β、候选完整形式频次阈值γ和抽取搜索引擎摘要的条数λ分别取1、60、50和50,均为经验值。
观察表4数据可知,从语料规模的角度看,随着实验数据中文档数量的增加,获取的缩略语对数量也呈逐渐增加的趋势;从3类语料中获取的候选缩略语的准确率处于34%到45%之间,汇总后的候选缩略语集的准确率为36.86%;获取的候选缩略语对的数量不够丰富。总结以上结论,利用基于词性模板和规则匹配的方法能够获取一定数量的缩略语对,但是获取的数量并不够丰富。究其原因主要有以下3点:①受限于缩略语词典的规模以及缩略语本身的多变性,词性模板库不可能覆盖所有的缩略语现象;②配对约束规则过于严格,导致一部分缩略语对的流失;③获取的搜索引擎返回结果的数量不够充足,对应的共现语料的稀疏削弱了共现信息的影响效力。
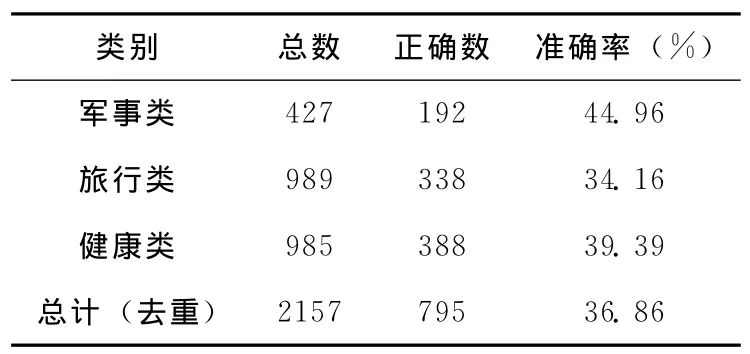
表4 候选缩略语对的数量及准确率
3.2 缩略语对的过滤
本阶段设计两组实验,分别用来对比每组特征的影响力和评估本文方法的有效性。
第一组实验,以上一阶段抽取得到的候选缩略语对的汇总为实验数据,分别使用内在关联、外部语义、外部统计以及所有特征的组合构造ADTree模型。将实验数据随机分成10份,进行10组交叉训练和测试,统计相应的P、R和F值。对比每组特征的影响力,实验数据和效果分别见图2和表5。图表中的“未使用特征的准确率”为分类前候选缩略语对汇总集的准确率,用以与采用特征分类后的准确率进行对比。

图2 不同特征组合的ADTree分类结果

表5 ADTree模型实验结果
由实验数据可知:①采用任何一种特征进行分类后,准确率都有大幅提升;②相比之下,内在关联特征与外部语义特征能保证较高的准确率,但只有外部统计特征能够得到较高的召回率,这说明内在关联特征和外部语义特征对缩略语现象的覆盖率不高,也间接反映了缩略语内在结构的多变性和语义理解的复杂性;③当3组特征联合使用时,3个评价指标都达到了最高值,验证了ADTree模型能够较好地融合3组特征。综上,缩略语的形成受多种因素的影响,很难找到单一的规律描述所有的缩略语现象。采用多种特征相组合的方式,选择合适的机器学习方法,可以近似地对缩略语现象建模;此外,鉴于缩略语的结构多变性和语义理解的复杂性,除了进一步探究其结构和语义特征之外,利用知识库对缩略语进行相关研究是个不错的选择。
第二组实验,分别在3个领域的候选缩略语对集和三者的汇总集上,综合使用所有特征构造ADTree模型。进行10组交叉训练和测试。统计对应的6个指标:T1、T2、T3、P、R和F值,实验结果见表6。本步骤中参数上下文取词个数δ、上下文选取语句个数ε和权重调节参数η分别取2、50和0.5。
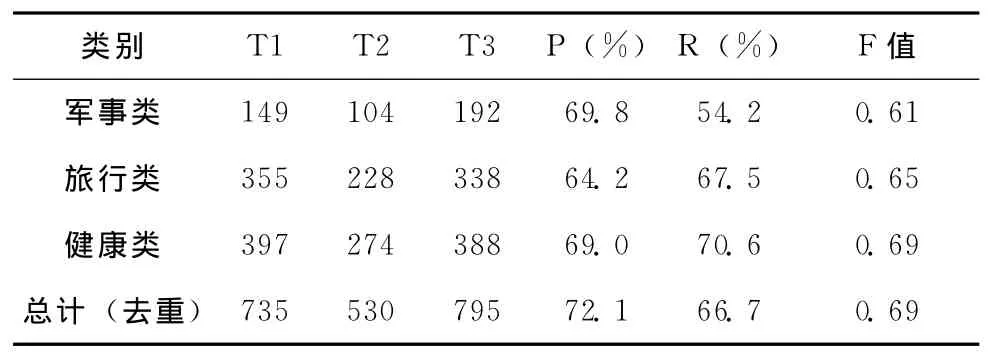
表6 ADTree模型实验结果
分析表6可知,在ADTree模型分类中,随着实验数据量的增加,分类的准确率保持平稳,召回率和F值都有稳步的提升;在汇总后的候选缩略语对集合上,准确率达到了最高的72.1%,召回率也达到了66%的平均水平,而综合评价指标也保持着较高的水平。与同类方法相比,本文方法获取的缩略语对准确率达到了72.1%,这比文献[7]方法的68.3%要好;其次,本文方法有较强的通用性和可扩展性,能够应用到其它领域语料的缩略语对应关系挖掘中。
4 结束语
本文给出了一种从自由文本中自动抽取缩略语对的方法。提出词性模板匹配方法和基于规则的缩略语配对方法。利用缩略语与完整形式之间的多种特征构造ADTree模型。相比于前人研究,本文方法突破了语料的限制,可以在保证较高准确率的前提下,从自由文本中抽取一定数量的缩略语对。此外,本文方法有着较强的通用性,可以作为构造大规模缩略语对照表的参考方法。本文方法仍存在一些局限,对缩略语的类别和字长都有一定的限制。下一步将在缩略语的配对约束规则及缩略语的非一对一现象等方面开展进一步的研究工作。
[1]WANG Houfeng.Survey:Abbreviation processing in Chinese text[J].Journal of Chinese Information Processing,2011,25(5):60-67(in Chinese).[王厚峰.汉语缩略语自动处理研究现状[J].中文信息学报,2011,25(5):60-67.]
[2]Okazaki N,Ananiadou S,Tsujii J.A discriminative alignment model for abbreviation recognition[C]//Proceedings of the 22nd International Conference on Computational Linguistics,2008.
[3]Stevenson Mark,Guo Yikun,Abdulaziz Al Amri,et al.Disambiguation of biomedical abbreviations[C]//Proceedings of the Workshop on BioNLP,2009.
[4]YANG Hua,HONG Yu,HUA Zhenwei,et al.Combination method of rules and statistics for abbreviation and its full name recognition[C]//Proceedings of the International Conference on Informatics,Cybernetics,and Computer Engineering,2012:707-714.
[5]Xu Sun,Wang Hofeng,Bo Wang.Predicting Chinese abbreviations from definitions:An empirical learning approach using support vector regression[J].Journal of Computer Science and Technology,2008,23(4):602-611.
[6]JIAO Yan,WANG Houfeng,ZHANG Longkai.Abbreviation prediction using conditional random field and Web data[J].Journal of Chinese Information Processing,2012,26(2):61-68(in Chinese).[焦妍,王厚峰,张龙凯.基于条件随机场与Web数据的缩略语预测[J].中文信息学报,2012,26(2):61-68.]
[7]XIE Lixing,SUN Maosong,TONG Zijian,et al.Identification of Chinese abbreviations using query log and anchor text[C]//Chinese Computational Linguistics Research Frontier,2009(in Chinese).[谢丽星,孙茂松,佟子健,等.基于用户查询日志和锚文字的汉语缩略语识别[C]//中国计算语言学研究前沿进展,2009.]
[8]LIU Youqiang,LI Bin,XI Ning,et al.A bilingual corpus based approach to Chinese abbreviation extraction[J].Journal of Chinese Information Processing,2012,26(2):69-74(in Chinese).[刘友强,李斌,奚宁,等.基于双语平行语料的中文缩略语提取方法[J].中文信息学报,2012,26(2):69-74.]
[9]YUAN Hui,RUAN Xianzhong.Modern Chinese abbreviations dictionary[M].Beijing:Language and Literature Press,2002(in Chinese).[袁晖,阮显忠.现代汉语缩略语词典[M].北京:语文出版社,2002.]
[10]Freund Y,Mason L.The alternating decision tree learning algorithm[C]//Proceeding of the Sixteenth International Conference on Machine Learning,1999:124.
[11]Freund Y,Schapire RE.A decision-theoretic generation of on-line learning and an application to boosting[G].LNCS 904:Computational Learning Theory.London:Springer-Verlag London,1995:23-37.
[12]Akira Terada,Takenobu Tokunaga,Hozumi Tanaka.Automatic expansion of abbreviations by using context and character information[J].International Journal of Information Processing and Management,2004,40(1):31-45.
[13]LIU Qun,LI Sujian.Word similarity computing based on Hownet[J].Computational Languistic and Chinese Information Processing,2007,31(7):59-76(in Chinese).[刘群,李素建.基于《知网》的词汇语义相似度计算[J].计算机语言学及中文信息处理,2007,31(7):59-76.]
[14]DING Yuanjun.Extracting abbreviated names for Chinese entities from the Web[J].Computer Science,2012,39(3):174-182(in Chinese).[丁远钧.从中文Web网页中获取实体简称的研究[J].计算机科学,2012,39(3):174-182.]
猜你喜欢
传染病信息(2022年2期)2022-07-15 08:52:24
医药与保健(2022年2期)2022-04-19 08:17:34
中国新闻周刊(2021年26期)2021-07-27 04:02:12
宁夏医学杂志(2020年3期)2020-02-27 14:17:11
当代陕西(2019年15期)2019-09-02 01:52:00
学苑创造·A版(2018年11期)2018-02-01 06:29:20
护理实践与研究(2017年1期)2017-04-07 05:58:41
读者(2017年5期)2017-02-15 18:04:18
信息安全研究(2016年4期)2016-12-01 06:06:54
Asian Pacific Journal of Reproduction(2015年1期)2015-12-22 12:09:35
