
图书馆大数据处理研究
2014-02-05 06:37郎川萍杨仁怀张丽霞
微型电脑应用 2014年4期
郎川萍,杨仁怀,张丽霞
0 引言
近几年以来,信息技术快速发展,特别是物联网、云计算、移动互联网等技术发展迅猛,数据不断增长,且增长趋势正不断加快,因而信息社会已进入大数据(Big Data)时代[1]。图书馆也不例外,特别是数字图书馆[2]、智慧图书馆[3]的建设,给人们的生活带来方便的同时,正在不断累积这大数据。
本文在第 2节中重点介绍了图书馆中大数据的来源以及这些数据的特点;第3节分析了电子商务行业在处理大数据方面取得的成功,分析了大数据能够给图书馆带来的帮助;第4节介绍了现阶段处理大数据的技术,以及大数据在图书馆行业的应用现状;第5节归纳分析了图书馆大数据的存储以及展现大数据分析结果要用到的相关技术;第6节对全文进行总结。
1 图书馆中的大数据
1.1 图书馆中的大数据来源
图书馆中的大数据主要有以下几个来源:
(1)自建数据库:每年图书馆都会新购大量的图书,这些图书数据以及随书的音频、视频数据会被存入数据库。
(2)外购数据库:图书馆会外购其他的数字资源,如超星数字图书馆。学校图书馆还会根据各专业需求,外购相应的生产实训资源库,包括了大量的视频和动画等。这些数据每年都处于增长中。
(3)网络数据:用户访问图书馆自建数据库、外购数据库、网站系统以及其他电子资源的访问记录、评论等数据也是图书管大数据的来源之一。
(4)传感器数据[4]:在图书馆中,不同的环境、位置有相应的传感器。传感器不断的对环境和资源进行感知,持续生成数据。这些数据经过长时间的累积,也是非常巨大的[5]。
(5)RFID数据:在未来图书馆中,会在相关资源中嵌入RFID 射频卡,对资源进行跟踪分析。一旦RFID在图书馆得到推广,广泛应用,将会是大数据的主要来源之一[5]。
(6)移动互联网数据:近几年来,智能手机、平板电脑等移动设备的运用越来越广泛,用户可以通过移动终端随时、方便的访问图书管资源,这也是图书馆大数据的重要来源。
图书馆的大数据从其内在结构上可以分为结构化数据和非结构化数据[6]两大类。结构化数据主要是外购数据库、各应用系统产生的数据,这些数据主要存储在关系数据库中,如SQL Server和Oracle中。没有存放在关系数据库中的数据如动画、视频和音频等称为非结构化数据。据统计,在图书馆中,非结构化的数据所占的比重高达80%以上,传统的关系数据库处理非结构化数据非常困难。
1.2 图书馆中大数据的特点
图书馆中的大数据满足4V定义[7]:即规模大(volume)、变化多样(variety)、价值密度低(value)[8]。
(1)数据规模:以国家图书馆为例[9],在 2007年底,其馆藏数字资源为200TB,而这一数字在2011年则达到了561.3TB,五年之内增长了将近3倍[10]。增长速度非常惊人的。
(2)数据多样:图书馆中的数据种类繁多。有自建数据库和外购数据以及各应用系统的结构化数据。还有许多视频文件和音频文件等非结构化数据。
(3)数据价值密度:数据量大,但是单一数据却没有多大价值,需要将大量数据一起分析,才能从中发现有价值的数据。例如,用户的访问记录等单一数据难以发现有用的信息,如果将大量用户的访问记录进行分析,则能挖掘出有用的数据。例如美国科学家通过Facebook成功预测了大米的价格趋势。
2 研究图书馆大数据的意义
大数据在电子商务行业已经成功运用,并取得了良好的效果。在国外,eBay购物平台每天产生的数据量达到了100PB,eBay使用大数据处理技术对每一条数据进行跟踪分析,以便准确掌握用户的购物行为[11]。沃尔玛是最早利用大数据的企业之一,其在大数据方面的投资,正在逐渐产生回报。在国内淘宝其对历史数据的分析,特别是用户的消费习惯、搜索习惯以及浏览习惯等数据所进行的综合分析[12]。在最近几年的“双十一”购物节中取得了巨大的成交额,2013年达到了350.19亿元人民币的成交金额[12]。
对于图书馆而言,对大数据进行分析,能够在以下几方面带来好处:
(1)能够帮助图书馆更好的控制各种风险。例如帮助更好控制数字图书馆信息安全、知识产权、图书馆投资与收益等。
(2)能帮助图书馆更好的分析用户行为与使用习惯,对不同用户进行分析,开发出更符合用户需求的产品,吸纳更多的、不同层次的用户,阻止用户流失。例如在高校中,教职工用户流失异常严重[5],因此可以对高校图书馆大数据今进行分析,对用户需求进行更为准确的预测,从而提供更好的服务。
(3)能够建立更好、更快的知识服务引擎。如何帮助用户从大量的信息中获取自己想要的数据,是图书馆的技术核心。通过对大数据进行深入分析和挖掘能够,能够帮助图书馆更为准确、智能的预测用户需求。
3 大数据处理技术
3.1 并行数据库
并行数据库出现在于20世纪80年代[13],是一种关系型数据库,主要存储结构化数据结构化数据,都支持标准的SQL,通过SQL语言,并行数据库与外界可以很好的交互。从80年代到现在的30多年时间里,并行数据库取得了很好的发展,直到现在其功能也在不断扩充和增强。然而,随着图书馆资源越来越多,其累积的数据已经大大超出了并行数据库的处理能力,同时,并行数据库对非结构化数据(图片、视频)支持较差。并行数据库在大数据面前已经显得力不从心,最为主要的原因是并行数据库的扩展性较差。并行数据库性能扩展主要通过纵向扩展(scale up)和横向扩展(scale out)来实现。纵向扩展(scale up)是指提升单个节点的硬件性能,如增加或更换性能更好的CPU,扩大内存和硬盘,这种方式并不能无限制的提升单个节点的处理能力。横向扩展(scale up)是指增加计算机节点数量,形成集群,将数据库部署到集群上以提升并行数据库的处理能力。这种方式对单个节点硬件的要求较为苛刻,如果某一节点的性能较其他节点低,则会影响这个集群的处理能力,极端情况下会出现,集群处理能力还不如单个节点的情况。如果想要达到规模较大的集群,代价比较高昂。
3.2 云计算
云计算的核心是海量数据的存储以及数据的并行处理,是一种可行的处理大数据的技术。是在分布式计算(Distributed Computing)、并行计算(Parallel Computing)和网格计算(Grid Computing)的基础上发展起来的[14]。数据存储技术主要有两种:(1)Google公司的分布式文件系统 GFS(Google File System)[15],使用廉价的服务器搭建的集群,具有良好的性能、高可用性以及高扩展性,但并不开源;(2)Hadoop的HDFS(Hadoop Distributed File System)[16],具有和DFS相似的功能,是开源系统。很多互联网公司,包括雅虎、淘宝等都使用HDFS技术存储数据[17]。
为了能更好的处理大数据,需要使用特定编程模型。MapReduce[18]是Google在2004年提出的用于处理大数据的编程模型。MapReduce简化了分布式编程的复杂性,程序员只需要关心程序的逻辑实现,而复杂的并行处理以及任务调度交由系统完成。用户在编程时只需要实现 Map函数和Reduce函数,Map函数指定需要处理的数据块,Reduce函数则对分块数据进行处理,MapReduce框架自动对数据分块、调度并执行,其执行流程如图1所示:

图1 MapReduce并行执行流程
Google通过GFS和MapReduce每天能处理的数据高达20PB[19]。
3.3 大数据在图书馆中的应用
大数据处理技术在图书馆中的应用还处于起步阶段。文献[20]分析了大数据时代的到来给许多行业包括图书馆行业带来的各种问题,讨论了在现阶段图书馆针对大数据所做的一些工作。文献[21]分析了在大数据时代,数据将成为图书管的核心资产,图书馆需要利用大数据提升自己的服务质量,图书馆可以利用工具对大数据加以分析增强图书馆服务和图书馆的智能化水平。文献[9]结合了图书馆的实际需求,采用了科学的分析方法,提出了大数据时代存储图书馆数据分方法。以上文献对大数据的分析应用都还基本处于理论阶段,并未真正投入应用。
4 处理图书馆的大数据
4.1 大数据的存储
虽然可以利用Hadoop的HDFS系统来存储图书馆中的大数据,但是难以满足其对实时性的要求。因此需要对图书馆中产生的大数据进行分类,采用不同的方式进行存储。实时性要求较高的数据存储到实时数据库中,实时系统处理后的数据以及其他对实时性要求不高的数据或各业务系统产生的数据采用并行数据仓库存储,大量的历史数据和非结构化数据存储到HDFS系统中。图书馆大数据存储架构如图2所示:
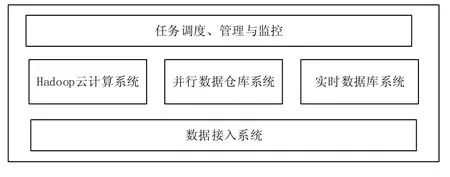
图2 图书馆大数据存储架构
4.2 大数据的展现
图书馆中的大数据经过分析后,将会有许多信息呈现给用户,这是数据处理的最后一个环节。如何将信息直观、有效的进行呈现是一项非常有挑战性的工作[20]。没有好的人机交互界面就不会有好的用户体验,系统的实用性将大打折扣。因此科学的设计人界交互界面是图书馆大数据处理重要的技术。
5 小结
图书馆已经产生了大量的数据,如何科学存储和分析这些大数据是必须要解决的问题。本文提出了云平台、并行数据仓库以及实时数据库共同来存储图书馆产生的数据,成本低、扩展性高、数据处理速度快,满足了数据处理的实时性又能存储海量的数据。但大数据在图书馆中的运用还处于初级阶段,还有许多问题需要大家去探索、解决。
[1]王元卓 靳小龙 程学旗.网络大数据:挑战、现状与展望[J].计算机学报.2013(06),1125-1138
[2]百度百科.数字图书馆[EB/OL].[2013-01-13].http://w ww.moc.gov.cn/2006/06tongjisj/06jiaotonggh/guojiagh/g uojiajt/200608/t20060815_46064.html(Baidu Encyclope dia.Digital library [EB/OL].[2013-01-13].http://ww w.moc.gov.cn/2006/06tongjisj/06jiaotonggh/guojiagh/gu ojiajt/200608/t20060815_46064.html)
[3]王世伟.再论智慧图书馆[J].图书馆杂志.2012(11),2-7
[4]覃雄派 王会举 杜小勇等.大数据分析——RDBMS与MapReduce的竞争与共生[J].软件学报.2011(9),32-45
[5]樊伟红 李晨晖 张兴旺.图书馆需要怎样的“大数据”[J].图书馆杂志.2012 (11),63-68
[6]宋亚奇 周国亮 朱永利.智能电网大数据处理技术现状与挑战[J].电网技术.2013(4),927-935
[7]Grobelnik M.Big-data computing:Creating revolutiona ry breakthroughs in commerce science and society[R/OL].[2012-10-02].http://videolectures.net/eswc2012_gr obelnik_big_data/
[8]孟小峰 慈祥.大数据管理:概念、技术与挑战[J].计算机研究与发展.2013(1),146-169
[9]李白杨 张心源.数字图书馆建设中大数据问题初探[J].情报科学.2013 (11),26-29
[10]国家图书馆.数字资源建设[EB/OL].[2012-12-22].http://www.ndlib.cn/szzyjs2012/201201/t20120113_57990.ht m
[11]Dealing with data.[J]Science,2011,311(6018):639-80 6
[12]新华网.“双十一”电商丰收 阿里单日销售额超 350.19亿元[R/OL].[2013-11-12].http://news.xinhuanet.com/f ortune/2013-11/12/c_118096396.htm
[13]王珊 王会举 覃雄派等.架构大数据:挑战、现状与展望[J].计算机学报.2011(10),1741-1752
[14]中国云计算网.什么是云计算? [EB/OL].[2008-05 -1 4].[2009-02-27].http: //www.cloudcomputing-china.c n/Article/ShowArticle.asp?ArticleID=1
[15]GHEMAWAT S,GOBIOFFH,LEUNG P T.TheGoo gle file system[C].Proceedings of the 19th ACM Sy mposium on Operating Systems Principles.New York:ACM Press,2003: 29-43
[16]ApacheHadoop.Hadoop [EB/OL].[2009-03-06].http://hadoop.apache.org/
[17]陈全 邓倩妮.云计算及其关键技术[J].计算机应用.200 9(09),2562-2567
[18]Dean J,Ghemawat S.MapReduce: Simplified data pr ocessing on large clusters//Proceedings of the 6th Sy mposium on Operating System Design and Implemen tation (OSDI.04).[J]San Francisco,California,USA,2 004: 137-150
[19]Dean J,Ghemawat S.MapReduce: Simplified data pr ocessing on large clusters.In: Brewer E,Chen P,ed s.Proc.of the OSDI.California: [J]USENIX Associati on,2004.137-150.[doi: 10.1145/1327452.1327492]
[20]张文彦 武瑞原 于洁.大数据时代的图书馆初探[J].图书与情报.2012(06),15-20
[21]韩翠峰.大数据时代图书馆的服务创新与发展[J].图书馆.2013(01),121-122
[22]Wong P C,Shen H W,Chen C,et al.Top ten int eraction challenges in extreme-scale visual nalytics[J].Computer Graphics andApplications,2012,32(4):63-67.
猜你喜欢
心理学报(2022年4期)2022-04-12
水泵技术(2021年3期)2021-08-14
河北理科教学研究(2021年4期)2021-04-19
军民两用技术与产品(2021年2期)2021-04-13
计算机教育(2020年5期)2020-07-24
福建基础教育研究(2020年3期)2020-05-28
财经(2017年2期)2017-03-10
财经(2016年15期)2016-06-03
财经(2016年3期)2016-03-07
财经(2016年6期)2016-02-24
