
延迟容忍网络中一种多信息融合的改进概率路由算法
2014-02-01 08:49:39何荣希
电讯技术 2014年11期
王 旭,何荣希
(大连海事大学 信息科学技术学院,辽宁 大连 116026)
1 引 言
与传统网络不同,延迟容忍网络(Delay Tolerant
Network,DTN)中源节点和目的节点之间很难形成稳定的端到端路径[1]。因此,使用存储-携带-转发方式将分组传输到物理上或社会性上更接近目的节点的节点,直至最终传输到目的节点[2]。也就是说,当一个节点收到分组后,将携带分组移动直到遇到(在其通信范围内)合适的中间节点或目的节点时,才转发该分组。
DTN在星际网络、战术通信网、车载自组网等许多受限网络环境都具有潜在的应用。由于它面临的应用环境极为特殊,传统路由协议无法适用于DTN[3],研究者针对DTN的不同应用场景提出了多种路由协议。文献[1,3]分析比较了目前一些主要的DTN路由算法,并指出未来路由研究的重点。概率路由是DTN中一类有效的路由机制,它通过计算节点传输概率来选择合适的转发节点[4-7]。文献[4-5]分别提出基于选择复制的动态数据传输策略(Selective Replication-based Adaptive Data Delivery Scheme,SRAD)和基于相对距离感知的动态数据传输策略(Relative Distance-Aware DataDelivery Scheme,RDAD),它们都是根据节点与目的节点的相对距离来计算传输概率。文献[6]引入节点速度矢量信息,对文献[4-5]提出的算法进行改进,提出一种节点状态感知的路由策略(Situation-Aware Routing Method,SARM)。文献[7]提出PRoPHET(Probabilistic Routing Protocol using History of Encounters and Transitivity)算法,利用节点历史相遇信息来计算节点的转发概率,有利于选择合适的转发节点。
尽管利用节点当前位置信息和速度矢量信息可以预测节点下一时刻的运动规律,有利于选择合适的转发节点,但是,由于节点移动的随机性,单纯基于位置和速度矢量等物理状态信息进行预测会降低预测的准确性,从而影响DTN的路由性能。与之相对应,仅使用历史相遇等社会关系信息(而不考虑物理状态信息)来选择转发节点,尽管可以增加分组最终转发到目的节点的机会,但是,往往会导致传输延迟增加。在某些情况下,会使一些分组在到达目的节点之前由于超出生存周期而被丢弃,从而阻碍了分组投递率的进一步提高。因此,为了改善DTN概率路由算法的性能,应该将节点的物理状态信息与社会关系信息有机融合,来选择更合适的分组转发节点。为此,本文提出一种综合考虑节点位置、速度矢量和历史相遇等信息的多信息融合概率路由算法(Probabilistic Routing based on Multi-information Fusion,PRMF)。该算法依据节点距离目的节点的远近程度,选择合适的信息来动态计算传输概率,并依据传输概率的大小选择转发节点。对于距离目的节点较近的节点,主要依据位置和速度矢量信息来预测相遇情况,而对于距离目的节点较远的节点则主要利用历史相遇信息来预测相遇关系。通过合理分配传输概率计算中利用两类信息进行预测的权重,有利于改善算法的投递率和平均延迟性能。
另外,为了进一步提高PRMF的投递率和减小传输延迟,还引入二分喷射等待算法(Binary Spray and Wait,BSW)[8]中限制分组最大副本数量和将分组尽可能快地散播到网络中的思想,同时利用预测信息改进了节点的缓存管理策略。最后,通过ONE(Opportunistic Networking Environment)仿真平台[9]对所提算法进行了仿真分析,仿真结果验证了算法的有效性。
2 算法描述
本文提出的多信息融合概率路由算法(PRMF)包含转发节点选择模块和分组转发模块。转发节点选择模块利用节点的物理状态信息和社会关系信息来计算节点的转发概率,从而决定如何选择转发节点,而分组转发模块完成分组副本控制、缓存管理和转发分组。
2.1 转发节点选择
转发节点选择是否恰当,将直接影响分组投递率和传输时延等性能指标的好坏。在选择转发节点时,将综合考虑节点的位置和速度矢量信息以及历史相遇信息,通过合理加权来联合计算节点i的转发概率pi。pi值越大,表明节点i越适合作为转发节点。pi可表示为
pi=αpli+(1-α)phi
(1)
其中,phi是按节点i与目的节点的历史相遇信息(从节点社会关系层面考虑)计算的相遇概率,可体现出两者在较长时间内的相遇关系;而pli是利用节点i的位置和速度矢量信息(从节点物理状态层面考虑)计算的与目的节点的相遇概率。考虑到节点移动的随机性,pli更能体现在较短时间范围内节点间的相遇情况。随着与目的节点间距离的增加,pli预测的准确性会降低。因此,应该依据节点间的距离来动态调整phi和pli的加权因子α(0≤α≤1)。
当节点i与目的节点距离较近时,经过较短时间就可能与目的节点相遇。由于相遇前经历的时间较短,其速度矢量发生变化的概率较小。因此,在计算转发概率时,pli的权重相应大一些。相反,如果节点i距离目的节点较远,需要经过较长时间才可能相遇。经过的时间越长,节点i在移动过程中速度矢量发生变化的概率就越大,依据物理状态信息预测的相遇概率的准确性就越低。因此,计算传输概率pi时基于历史信息的phi的权重就应该越大。综上,加权因子α可表示为
(2)
其中,d为节点i与目的节点间的距离矢量;‖d‖表示距离标量;r表示当前携带分组的节点i通信覆盖范围的半径;ds为一个距离常数,表示相对最远距离。可根据网络场景大小设定,网络场景越大,ds值越大。当目的节点位于节点i的通信范围内时,可将分组直接转发到目的节点,因此,α=1,pi=pli=1。如果目的节点位于节点i的通信范围之外,则需要根据相对距离来决定权值。节点i与目的节点距离越远,phi所占权重越大,距离越近,pli的权重越大。由于节点i与目的节点距离越远,利用位置和速度矢量信息预测的节点间相遇概率越不准确,因此,当节点间距离大于ds时(说明它们距离足够远),预测的pli值准确性极低,在计算转发概率pi时可以忽略pli的影响,因此,α=0,pi=phi。
pli的计算可借鉴文献[6]的方法,结合上述分析,需要进行一些修改。pli的表达式为
(3)
其中,pdi和pvi分别为节点i到目的节点的相对距离概率和相对速度概率[6];λ代表加权因子,决定pdi和pvi在预测pli中所占的比重。pdi与pvi可通过节点i与目的节点的速度矢量和距离矢量信息来计算。
图1为节点i的速度示意图,其中,i为预测节点;D为目的节点;v1为目的节点的速度矢量;v2表示节点i的速度矢量;v=v1-v2表示两个节点的相对速度矢量;d代表节点i与目的节点的距离矢量;θ为速度矢量v与距离矢量d的夹角,θ的范围在0°~180°之间,即θ∈[0°,180°]。θ表示将来两节点相遇的偏差,θ越大两节点相遇的概率越小。用‖v‖表示速度的标量,即速率,用‖d‖表示距离标量。
文献[6]利用位置和速度矢量信息计算pvi值的范围是[-1,1],为了便于与基于历史相遇信息预测的phi合并,需要进行如下修改,使pvi的范围在0到1之间,即
(4)
其中,θ可以根据两向量夹角的余弦公式计算[6],即
(5)
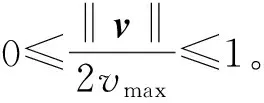
在式(3)中,λ和pdi都是随节点i与目的节点之间的距离动态变化的,因此,也可利用式(2)相同的方法进行计算,即
(6)
phi的计算可借鉴文献[7]的思想,当两节点相遇时,可按式(7)对phi值进行更新:
(7)
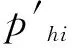
2.2 分组转发
PRMF算法引入了文献[8]的散播分组和控制副本策略,分组转发过程分为喷射和等待两个阶段。在喷射阶段,源节点产生n个分组副本,转发一半的分组给相遇节点。在网络中只要携带分组副本数量大于1的节点与无分组副本的节点相遇,就会转发一半分组,并保留另一半。当携带的分组副本只剩下1个时,节点进入等待阶段。这n个节点携带分组移动,直到遇见目的节点将分组转发出去或到达分组生存周期而删除分组。
与已有概率路由算法[4-7]不同,PRMF在决定是否转发分组时,并不是单纯依靠节点转发概率pi的大小,而是把分组的剩余副本数量也考虑在内。考虑到DTN中很难保持端到端路径,分组依据转发概率选择合适的转发节点。分组在网络中扩散越充分,遇到的节点就越多,就越有可能到达目的节点。因此,应该鼓励优先转发副本数量多和转发概率大的分组。当两节点相遇要转发分组时,节点i先将缓存中的分组按照式(8)计算的si1大小排序,然后按从大到小的顺序依次转发。
si1=ηnri/n×(1-η)pi
(8)
其中,nri表示节点i剩余分组副本数量;n为源节点产生分组副本数量;η是一个权值常数,表示分组副本数量和传输概率所占的权重。
在缓存的管理方式上,PRMF也考虑了节点转发概率的影响。当新来分组时,如果节点i缓存已满,则与队列中已有分组一起按式(9)的计算结果si2大小进行排序,然后丢弃排序最后的分组。
si2=0.5sttl/Tl+0.5pi
(9)
其中,sttl表示分组的剩余生存期时间,Tl为分组的生存期时间,pi为节点i的转发概率。
综上所述,PRMF算法的主要流程可归纳为:根据式(3)~(6)基于节点位置和速度矢量信息计算pli,每次两节点相遇按式(7)更新基于历史相遇信息的传输概率phi,再根据式(1)和(2)计算出总的转发概率pi。最后,根据式(8)将分组在队列中排序,依次转发分组。若缓存已满,按式(9)排序并丢弃最后的分组。
3 算法仿真及性能分析
本节将利用ONE仿真器[9]对提出的PRMF算法进行评测,并与SARM[6]、PRoPHET[7]和BSW[8]进行比较,以验证算法的有效性。ONE是专为DTN设计的、基于离散事件的开源仿真工具,已被广泛用于DTN路由算法的评测。仿真场景是模拟赫尔辛基市区的一个真实场景,包括一个4 500 m×3 400 m的区域和不同类型的节点。该模拟场景主要包括街道、商店、公园和公交车站等,所有节点分成6组,每组节点具有相同的移动速度、暂停时间分布、数据传输率、缓存大小和通信范围。其中,组1和组3代表行人,组2是汽车,而组4~6表示有轨电车。除了组4的节点使用IEEE 802.11b的WLAN技术外,其余组的节点都使用蓝牙进行通信。在仿真实验中,组1~3的节点数分别从10增加60(每次增加10),而组4的节点数固定为1,组5~6的节点数固定为2。每个组的详细参数设置如表1所示。仿真中所用到参数分别设置为:pi=0.75,ds=3 500,Tl=300,η=0.6,n=10。另外,PRoPHET[7]中老化和传递性参数γ和β分别设置为0.98和0.25。在仿真开始阶段,路由的初始化时间设置为1 000 s,用来初始化传输概率。
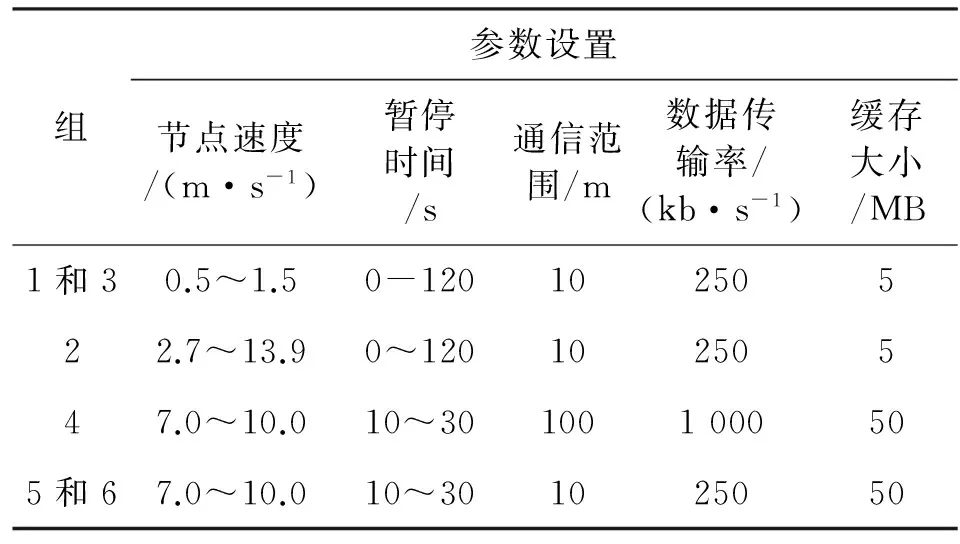
表1 不同节点组的参数配置Table 1 Parameter setting of different groups
仿真时采用投递率、平均开销和平均延迟3个参数来比较不同算法的性能。投递率定义为目的节点成功接收分组数和源节点发出总分组数的比值。平均开销定义为目的节点成功接收一个分组所需的平均分组副本数,即
(10)
式中,u表示平均开销,nc表示全网总分组副本数,nd表示目的节点成功接收分组数。平均延迟表示所有成功接收的分组从创建到正确接收所经历时间的平均值。
图2比较了不同节点数下4种算法的投递率。从图中可以看出:PRMF的投递率最高,其次是BSW、SARM和PRoPHET。另外,除了PRoPHET的投递率随节点增加变化不大外(节点数小于95时,投递率随节点数增加稍有增加,随后,随节点数增加投递率略有下降),其他3种算法的投递率都随节点数的增加而显著增加。主要原因在于:节点数增加会导致分组转发次数增加,一方面有利于增加分组转发到目的节点的概率,另一方面也会加重路由开销。由于PRoPHET没有副本限制策略,当网络节点增加到一定程度时,大量复制的副本会导致节点出现缓存溢出,从而丢弃大量分组,此时投递率将不再随节点增加而增大,甚至会略有降低。SARM算法利用节点位置与速度矢量信息选择转发节点,节点数增加,潜在地使网络中向目的节点移动的节点也会增加,因此,有利于选择更合适的转发节点,从而增加投递率。SARM算法在选择转发节点时根据节点的速度矢量,选择的转发节点很分散,分组将分散到网络中的各个节点,从而可减小缓存溢出发生概率。但是,PRoPHET选择那些与目的节点相遇次数多的节点,而这些节点往往集中在某些中心性较高的节点中[10],网络中所有节点基本都选择这些节点作为转发节点,所以PRoPHET比SARM更容易导致缓存溢出。因此,SARM的投递率高于PRoPHET。虽然BSW没有选路策略,但是,当节点数量增加时,BSW算法将分组在网络中散播的速度也在增加,所以分组传递到目的节点的概率也会增大,投递率也随节点增加而增大。由于PRMF算法结合了BSW和SARM各自的优点,而且进一步进行了优化,因此比其他算法具有更高的投递率。
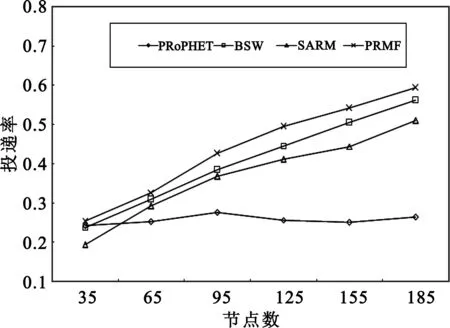
图2 节点数量对投递率的影响Fig.2 Delivery rate in different number of nodes
图3比较了不同节点数量下4种算法的平均开销。从图中可以看出:BSW和PRMF的路由开销明显低于PRoPHET和SARM,两者非常接近(PRMF略高于BSW)。这是因为BSW和PRMF都采用副本数量限制机制,所以不管节点数如何变化都能保持较低的路由开销。相反,PRoPHET和SARM没有采用副本限制机制,随着节点数增多,网络中总的分组转发次数增多,平均路由开销增大。另外,由于BSW仅根据分组进入队列先后顺序选择被转发分组,而PRMF依据分组转发次数对分组排序,有利于使分组在网络中更充分扩散,虽然其平均开销略高于BSW,但是却可以进一步提高投递率。
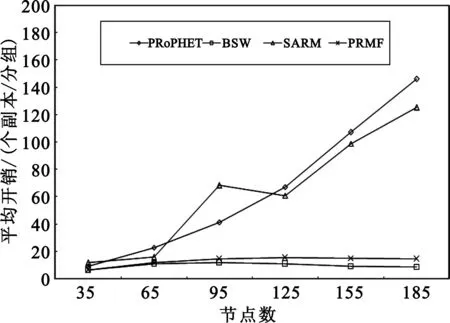
图3 节点数量对平均开销的影响Fig.3 Average overhead in different number of nodes
图4比较了不同节点数下4种算法的平均延迟性能。从图中可以看出:随着节点数增加,4种算法的平均延迟呈下降趋势,而PRMF具有更好的延迟性能。BSW和PRMF的平均延迟曲线在节点数少于95时几乎重合,但节点数超过95后,PRMF算法的平均延迟继续随节点数增加而下降,而BSW几乎不变。主要原因在于:BSW算法的关键是将分组散播出去,节点数增加到一定程度时已经使分组散播达到最大化,继续增加节点对分组传输延迟的影响不大,而PRoPHET、SARM和PRMF算法的关键是选择节点的转发策略,节点数越多,选择到合适节点的概率增加,因而有利于降低平均延迟。

图4 节点数量对平均延迟的影响Fig.4 Average delay in different number of nodes
另外,本文还比较了节点缓存大小对算法性能的影响,仿真结果如图5~7所示。
图5比较了4种算法在不同缓存大小下的投递率。可以看出:节点缓存越大,投递率越大;但是,无论节点缓存大小如何变化,PRMF的投递率都高于其他算法,其次为BSW和SARM,最后是PRoPHET。
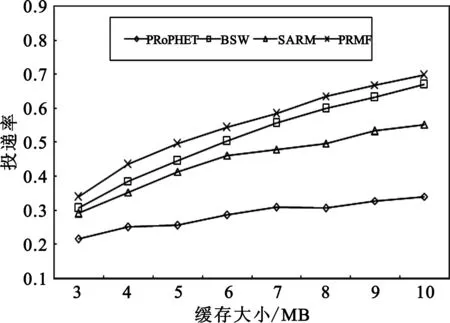
图5 缓存大小对投递率的影响Fig.5 Delivery rate in different buffer size
图6比较了缓存大小对算法平均开销的影响。从图中可看出:PRMF和BSW的平均开销比较接近,都大大低于PRoPHET和SARM。另外,随着节点缓存增加,路由算法的平均开销呈缓慢下降趋势,但改变不大。这是因为节点缓存增加,每个节点可以携带分组数增加,会增加网络中总的分组转发次数。但是,由于缓存增大,全网的投递率也会增加,因此,根据式(10)计算的平均开销变化不太明显。
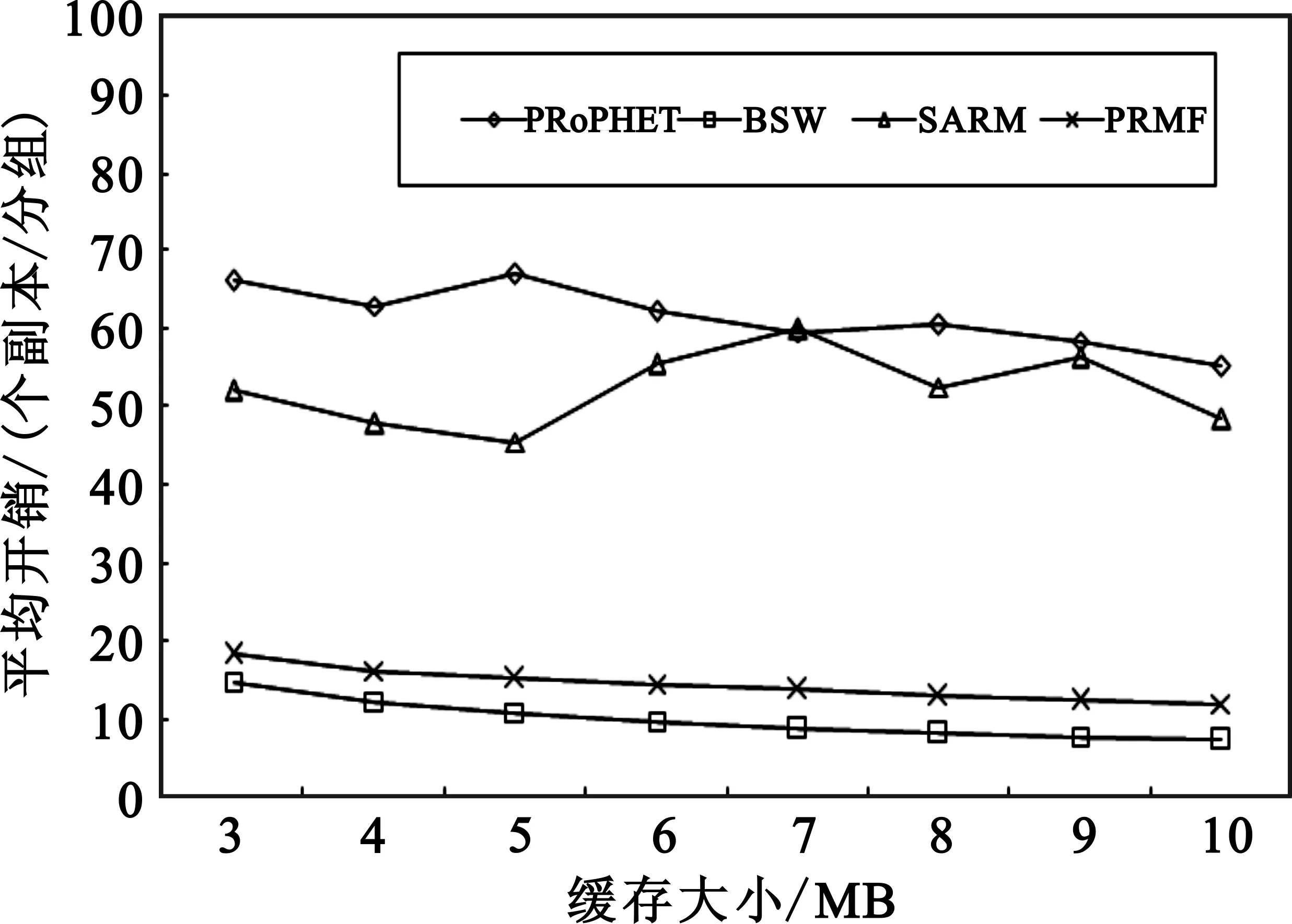
图6 缓存大小对平均开销的影响Fig.6 Average overhead in different buffer size
图7比较了节点缓存大小对算法平均延迟的影响。从图中可以看出:PRMF具有最低的平均延迟,其次是BSW和SARM,PRoPHET具有最大的平均延迟。另外,随着节点缓存的增加,4种算法的平均延迟都有所增大。这是因为:节点缓存变大,存储能力增强,可以存储更多分组,因缓存限制丢弃的分组减少,所以在小缓存时因缓存限制被丢弃而未能到达目的节点的分组,此时可以被节点继续携带,可以增加遇到合适的转发节点或者目的节点而被转发的概率,有利于增加投递率,同时也会增加平均延迟。
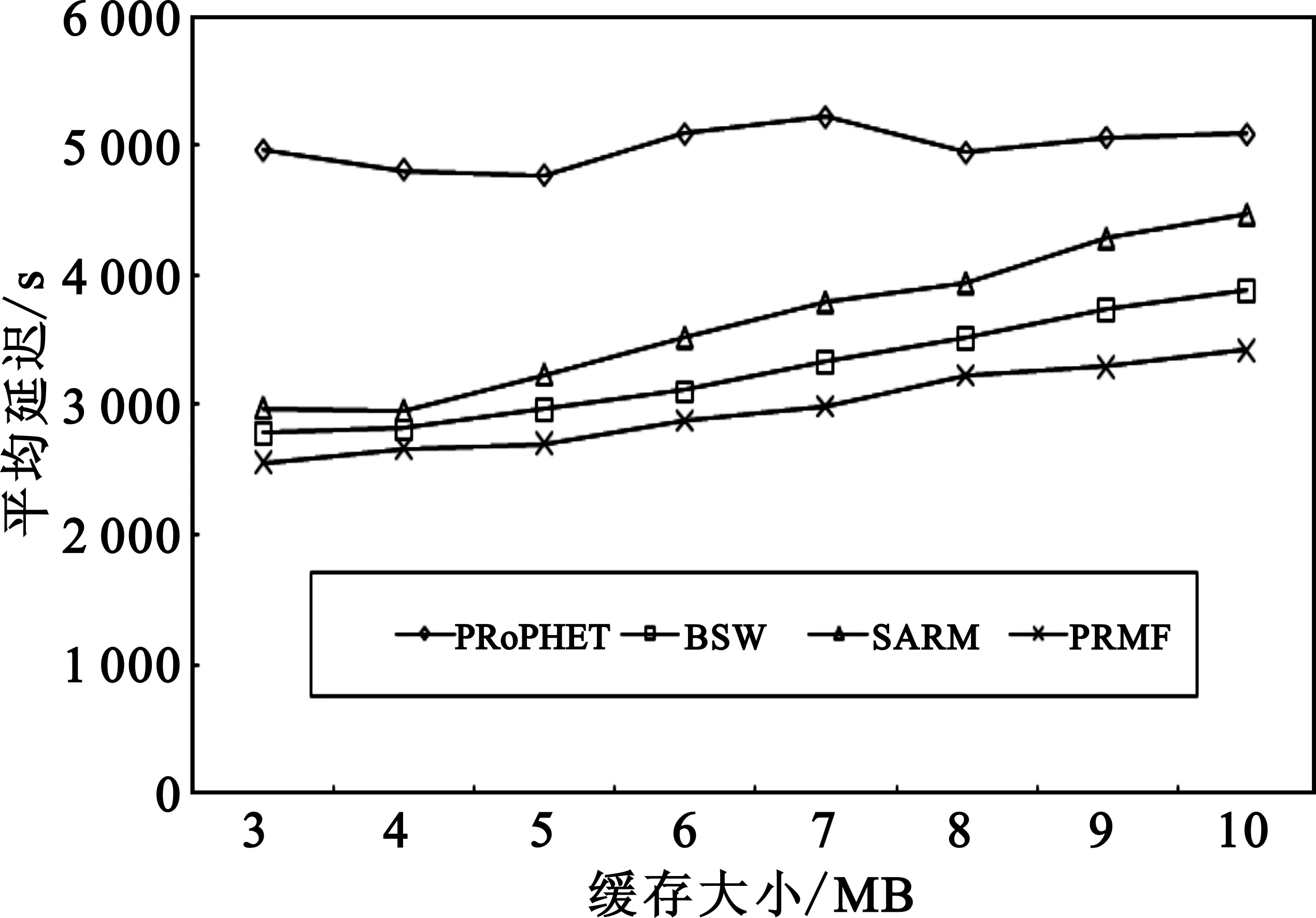
图7 缓存大小对平均延迟的影响Fig.7 Average delay in different buffer size
4 结 论
选择合适的转发节点是提高DTN概率路由算法性能的关键,本文将节点位置与速度矢量信息和历史相遇信息有机结合,提出了一种多信息融合的概率路由算法(PRMF)。在进行传输概率预测时,PRMF按节点距离的远近动态调整利用节点物理状态信息和社会关系信息的权重,并利用预测信息改进缓存管理策略,同时引入限制分组最大副本数量和将分组尽快散播的思想。仿真结果表明:与文献[6-8]中现有算法相比,PRMF保持了较低的平均开销,同时具有最高的投递率和最小的平均延迟。本文所提算法基于节点都愿意协作的假设,但是,由于某些节点可能存在自私行为,不愿意转发与自己无关的分组,因此,下一步可研究考虑节点自私行为时如何合理选择转发节点,设计有效的激励和惩罚机制,来进一步提高算法的性能。
[1] Zhu Y,Xu B,Shi X,et al.A survey of social-based routing in delay tolerant networks:positive and negative social effects [J].IEEE Communications Surveys & Tutorials,2013,15(1):387-401.
[2] Yamamura S,Nagata A,Tsuru M,et al.Virtual segment:Store-carry-forward relay-based support for wide-area non-real-time data exchange [J].Simulation Modelling Practice and Theory,2011,19(1):30-46.
[3] 苏金树,胡乔林,赵宝康,等.容延容断网络路由技术[J].软件学报,2010,21(1):119-132.
SU Jin-shu,HU Qiao-lin,ZHAO Bao-kang,et al.Routing techniques on delay/disruption tolerant networks [J].Journal of Software,2010,21(1):119-132.(in Chinese)
[4] 朱金奇,刘明,龚海刚,等.延迟容忍移动传感器网络中基于选择复制的数据传输[J].软件学报,2009,20(8):2227-2240.
ZHU Jin-qi,LIU Ming,GONG Hai-gang,et al.Selective replication-based data delivery for delay tolerant mobile sensor networks [J].Journal of Software,2009,20(8):2227-2240.(in Chinese)
[5] 许富龙,刘明,龚海刚,等.延迟容忍传感器网络基于相对距离的数据传输 [J].软件学报,2010,21(3):490-504.
XU Fu-long,LIU Ming,GONG Hai-gang,et al.Relative distance-aware data delivery scheme for delay tolerant mobile sensor networks[J].Journal of Software,2010,21(3):490-504.(in Chinese)
[6] 吴亚辉,邓苏,黄宏斌.延迟容忍网络状态感知的路由策略研究 [J].电子与信息学报,2011,33(3):575-579.
WU Ya-hui,DENG Su,HUANG Hong-bin.Research of situation-aware routing method in delay tolerant network [J].Journal of Electronics & Information Technology,2011,33(3):575-579.(in Chinese)
[7] Lindgren A,Doria A, Schelèn O.Probabilistic routing in intermittently connected networks [C]//Proceedings of Service Assurance with Partial and Intermittent Resources,Lecture Notes in Computer Science. Heidelberg,Berlin:Springer,2004:239-254.
[8] Spyropoulos T,Psounis K,Raghavendra C.Spray and wait:an efficient routing scheme for intermittently connected mobile networks [C]//Proceedings of the 2005 ACM SIGCOMM Workshop on Delay-tolerant Networking.New York,USA:IEEE,2005:252-259.
[9] Keranen A,Ott J,Karkkainen T.The ONE simulator for DTN protocol evaluation [C]//Proceedings of the 2nd International Conference on Simulation Tools and Techniques.Rome,Italy:IEEE,2009:1-10.
[10] Hui P,Crowcroft J,Yoneki E.Bubble rap:Social-based forwarding in delay-tolerant networks [J].IEEE Transactions on Mobile Computing,2011,10(11):1576-1589.
猜你喜欢
工业设计(2023年1期)2023-03-02 10:08:12
中外文摘(2022年13期)2022-08-02 13:46:16
计算机系统应用(2019年2期)2019-04-10 05:08:46
网络安全和信息化(2018年3期)2018-11-07 03:02:44
计算机与生活(2016年11期)2016-11-22 02:07:32
红领巾·萌芽(2015年5期)2015-06-16 02:35:40
计算机工程与科学(2015年3期)2015-03-27 07:46:15
电测与仪表(2014年16期)2014-04-22 05:20:30
计算机工程(2014年6期)2014-02-28 01:25:54
河南科技(2014年5期)2014-02-27 14:08:56
