
关系型本体转换为关联数据技术方案比较研究
2014-01-16 01:09濮德敏任瑞娟
图书馆理论与实践 2014年12期
●濮德敏,任瑞娟,米 佳,张 欣
(1.河北大学a.管理学院,b.图书馆,河北保定071002;2.天津空港经济区文化中心,天津300308)
关系型本体转换为关联数据技术方案比较研究
●濮德敏1,b,任瑞娟1,a,b,米 佳b,张 欣2
(1.河北大学a.管理学院,b.图书馆,河北保定071002;2.天津空港经济区文化中心,天津300308)
关系型本体;关联数据;转化;Ⅴirtuoso;Triplify;D2R
论述了关系型本体向关联数据转化的可行性,在此基础上分别论述了Ⅴirtuoso Universal Server、Triplify、D2R三种主流的转化技术方案并进行了比较分析,得出结论:D2R方式是当前规模化转化的优选方式,并将国内成功实现的研究机构——河北大学知识组织与知识管理实验室作为本研究的成功案例进行了介绍。
关系型数据库是结构化数据的存储方式,也是规模化本体存储的常用格式,在其中的数据属性间和表与表间主键连接中蕴含大量的关联关系,此关联关系是完全可以采取自动或半自动方式提取并加以定义为互联网语义化组织所广为应用的。因此,本论文的研究就是针对这种关系型数据,利用关联数据技术,实现自动或半自动提取数据的关联关系并加以定义、映射和发布,实现基于关联数据技术的语义化信息发布,并作为关键词查询的补充,提高语义查找效率,最终提高搜索结果的语义理解并扶持决策。[1]从本体出发,依据其语义关系,采用关联数据技术方案是知识检索的最佳方案,而解决问题的核心是将本体和关联数据相结合。[2]
1 关系型本体向关联数据转化可行性
1.1 关系型数据库
关系模型的实体以及实体之间的关系都可以用二维表来表示,其属性间的关系可以看成是一种单一的结构关系。依关系模型中实体间联系的复杂程度,分成三种:一对一联系,一对多联系和多对多联系。实体关系模型利用图形的方式呈现,即,实体-关系图(图1)来表示数据库的结构及概念设计。

图1 实体-关系图
在上述关系模型的实例中,通常将每一个实体设计为一个表,方框中的三个实体则分别存储著者、出版、作品三类不同实体,椭园内为实例,在关系模型中表现为表的属性。
1.2 关系型本体
本体能够体现出知识和知识之间的语义关系,本研究的本体是指由词表、术语等改造而成的轻量级本体。基于文件系统存储本体的方式简单,但检索效率低,且难适应数据大的情况。采用关系型数据库存取本体,这适合规模化语义应用系统,能支持大数据下的高效语义查询。关系型本体依其采用水平或垂直存储形式的程度,分为水平型存储、垂直型存储或混合存储,表及其属性根据对术语的含义以及术语之间的关系加以定义。[2]由此,可用关系表来表示某个特定领域的知识。图2是关系型本体库的关系图示。关系表Knowledge中的领域名称、描述信息、子领域概念、领域公理集和上述本体定义相对应。领域中概念都由概念名称、属性、属性值、实例组成,关系表Sub-WordKnowlege中的名称、描述信息、关系、属性集、实例集、子领域概念集和上述子本体组成元素对应。而本体库中的关系、属性、实例分别由关系表Relationship、Property、Ⅰnstance来表示。利用这种对应关系,采用关系型数据库存储本体。
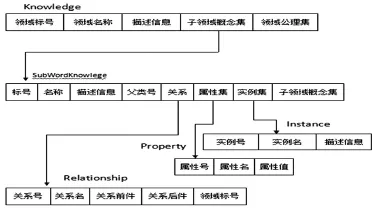
图2 关系数据库和本体库之间的对应关系
1.3 关联数据组织模式
关联数据的数据模型是RDF一阶谓词模型。RDF模型可以用三元组的方法来表示,即主语、谓语、客体构成,称为RDF陈述。例如:张老师教信息检索课。其中,张老师是主语,是需要描述的资源,教是谓语,它可以看成描述主语与其某个属性的关系,信息检索课是客体,它其实可以看成是属性的值或者关系的值。但不管是主语还是谓语最后都表示成HTTP URⅠ。而客体不仅可以是用HTTP URⅠ标识的资源,也可是文本。即:主语可被认为是类资源,谓语可被认为是类资源的属性,而客体或者是类资源或者是文字型资源。由客体的种类决定了三元组的分类,即分为文字型三元组以及非文字型三元组。
1.4 可行性分析
把主语和客体看作节点,属性看成是一条边,则一个RDF陈述可表示成一个RDF有向图。RDF实质是一种二元关系的表达,其中属性和属性值类似于关系模型,因此RDF数据模型可以被用来描述任何复杂的关系。实际上,属性和属性值都可以包含URⅠ,通过URⅠ可以访问任何可以被标识的事物,因此,RDF能联系万维网上各类事物,链接万维网上的各种资源。Linked Data强调通过丰富的RDF链接,构建资源的“语境”。[3,4]用户可通过RDF命名域和值来表达与资源有关的简单声明,自定义一些词汇,然后用这些词汇来描述资源。
由于关系型数据和关联数据的概念模型都是基于实体、属性及其关系而构建,两者具备建立映射和实现转换的可能性,这种可能性是基于二者之间的关系确立。关系模型和RDF三元组之间的转换关系从两个方面入手:一是概念转换,二是数据转换(如表1)。

表1 关系模型与三元组之间的映射关系
因此,在关系模型和RDF三元组的转换中,类名称、数据属性与实体名称、实体关系的映射较明了。从表1可以看出:首先是类与实体的转换表现为二维表与RDF三元组中类的转换,也就是二维表转换为RDF三元组中的主体或客体,而表的主键转换为主语或对象的URⅠ;其次是数据属性的转换,也就是二维表的列转换为三元组中的谓词,而二维表的行数据,转换成文本对象。对象属性的转换较复杂,在关系数据库中,实体内部及实体之间的关系有不同的表达和构建方式,且在设计转换过程中根据实际需求有独特的应用设计。而在关联数据中,资源描述框架链接表示对象之间的语义关系。因此,对象属性的映射,是关系数据库与关联数据语义组织模式映射的关键。[5]关系型数据转换关联数据的构建方式、模式转换、语义映射分析如下。
(1)不同表之间的关联关系。在关系型的某数据库中,会用很多不同的表来代表不同的实体,而表与表之间的关系可以看成是实体与实体之间的关系。在关联数据的资源描述框架中,通过关联链接来表达不同表间的关联关系。这些关系型数据,根据其不同表之间的关系种类可以划分为以下两种。①通过外键标引的表间关系。例如在书目数据表中,书目数据的keyword属性,引自主题词表的keywordsⅠD,主题数据的母体即keywords属性,引自本体库关系叙词表的subjectⅠD。对这些数据进行关联数据发布时,应表达这些在数据库中显性构建的关联关系。②通过属性来关联的表间关系。例如书目数据表和教师信息表都有name属性,表明两者存在一定的关系,使用SQL检索的语句如下:
select*from书目数据表,教师信息表where书目数据表.name=教师信息表.name
通过上面的SQL检索语句,可得到书目数据表和教师信息表中相同作者姓名的关联关系。如果再增加一定的限制条件,还能够动态获得某些关联关系。
(2)同一表内部的关联关系。①二维表中的列,看以看成一个实体及其属性之间存在的一对多的映射,表1中的实体属性和数据属性的映射转换。例如关系叙词表与其诸多列之间,存在一对多的内在联系。②两个行列相同二维表,是指可以通过将一个表逻辑上拆分为两个表,基于属性相等的条件,构建两个不同实体的逻辑关系。
(3)与外部数据的关系。关联数据即为从文档网络向数据网络转化的一种优化策略,在关联数据标准下,其可成为目前最好的发布和连接结构化数据的规则。[6,7]在关系型数据转换为关联数据过程中,数据关联化表示与外部更多的数据相关联时,需将这些数据与已知的URⅠ建立关联,关联数据就是通过URⅠ、HTTP、RDF等语义网技术将网络上相关的数据资源关联起来。RDF用URⅠ标识事物,用简单的属性(Property)及属性值来描述资源,这使得资源描述框架可以将关于资源的简单陈述中的一个或多个表示为一个由节点和弧组成的图。其中,节点和弧代表资源、属性或属性值。本质上,RDF数据模型所描述是包含主体、谓词和客体的三元组。RDF模式定义语言(Resource Description Framework Schema,简称RDFS)和网络本体语言(Ontology Web Language,简称OWL)来建立描述实体及其联系的词表的基础。任何人都可以建立网络数据词表,但这些数据须用RDF三元组表示,并可与其他词表相关联。
2 关系型数据的关联化转化主流技术方案
虽然关联数据在进行数据的语义查询时带来了便利,但目前很多现有的数据并不满足关联数据的准则。要想把现有的数据发布成关联数据,须借助自动化工具,Linked Data推动者促使相应工具的产生,常见的主流软件有D2R、Drupal、Ⅴirtuoso、Triple等,且这些软件都是开源的。
2.1 Ⅴirtuoso Universal Server方式
Ⅴirtuoso Universal Server系统属于应用程序服务,其架构为一种网络实时程序设计架构。Ⅴirtuoso是一种开放链接软件、支持跨平台应用操作系统,主要功能是提供网络查询与浏览服务。数据以被称为三元组的形式存储(subject-predicate-object)类型,支持导入/导出RDF文件来对数据进行操作。
Ⅴirtuoso具有通用操作系统的特点,提供硬件虚拟化,是一种嵌入式实时操作系统。ⅤirtuosoⅠDE中对于应用程序的编译、加载、运行可自动完成,并为程序调试提供所有目标的动态信息,程序运行的结果可调用实时库函数,通过主机实现输出操作。Ⅴirtuoso Universal Server由关联数据界面或一个SPARQL端点将数据转化为RDF数据,且直接存储在Ⅴirtuoso中。Ⅴirtuoso具备混合体系结构能够提供以下几个方面的功能模块:关系数据管理、RDF数据管理、XML数据管理、文字内容管理和全文索引、文件Web服务器、链接数据服务器、Web应用服务器、部署Web服务(SOAP或REST),支持SPARQL查询。[6]
2.2 Triplify方式
Triplify,是AKSW(The Agile Knowledge and Semantic Web,简称ASKW)研究组最近发布的产品,目的在“为万维网的‘语义化’提供建筑单元”。Triplify是发布从关系数据库到RDF并且链接web数据的一个简单方法,是基于关系数据库的映射并可以通过HTTP-URⅠ进行查询。Triplify为轻量级组件,易集成,易被Web应用程序广泛部署。不支持SPARQL,不支持发布更新日志。Triplify为小型Web插件,能将关系型数据库发布成RDF数据。
Triplify可将关系型数据转换成RDF语句,并在网络上公布,它提供不同的RDF序列化,特别是为关联数据。Triplify能够以RDF、JSON或者Linked Data格式提供数据库的内容,属小型Web应用插件,能揭示出关系数据库中存储的数据语义结构。通过Triplify插件和在查询中调整数据列,Triplify可以分析查询所返回的数据,并以前面提到的格式对外提供数据。基于重新映射HTP URⅠ请求,Triplify可以分析查询所返回的数据,能将HTML DOM数据以RDF格式序列化输出,从而揭示出关系数据库中所保存数据的语义结构。不需维护大规模语义定义,支持Web环境下拓展关联数据应用。
2.3 D2R方式
D2R(Database to RDF,简称D2R)软件是目前使用广泛的工具,能够支持多种主流关系型数据如Oracle、MySQL、PostgreSQL、Microsoft SQLServer、Microsoft、Access等。它的功能是把关系型数据库发布成Linked Data。
D2R发布关联数据时的映射机制主要分为两大部分,第一部分是构建关系型数据库与RDF三元组之间映射关系,即利用映射语言,将映射关系用RDF三元组的形式描述出来,形成映射文件;第二部分是构建关联数据服务,应用第一部分中形成的映射文件对关系型数据进行转化,并提供多种访问模式。D2R主要包括三个核心部分:D2R Server、D2RQ Engine和D2RQ Mapping语言。[5,8]图3是D2R总体框架及运行机制图。

图3 D2R总体框架及运行机制图
3 主流转化技术方案对比分析
3.1 相同点与不同点比较分析
通过对D2R、Ⅴirtuoso、Triple三种软件的介绍,总结它们的异同,便于将关系型数据转换成关联数据时选择最合适的方案,为本研究的实现搭建最优平台(如表2)。
(1)相同点。①均为web服务,属于B/S(Browser/Server,浏览器/服务器模式)模式,这种模式统一了客户端,将系统功能实现的核心部分集中到服务器上,简化了系统的开发、维护和使用。关联数据发布到Web服务器,用户只需有一台能上网的电脑通过Web浏览器就能访问客户端。因此,系统的扩展性非常容易,只要能上网,再由系统管理员分配一个用户名和密码,就可以使用了。甚至可以在线申请,通过服务器内部安全认证后,系统可自动分配给账号,不需要人工参与。②均为转化RDF的专用工具。③均有对域名的依赖。D2R、Ⅴirtuoso、Triple三种软件在发布关联数据后,都需要通过Http或者URⅠ协议进行浏览访问。
(2)不同点。①自动化程度不同。D2R自动化程度最高,Ⅴirtuoso属于半自动化软件,Triple是依靠人工操作多,自动化程度最低。②数据库语义驱动类型不同。D2R和Ⅴirtuoso属于可以手工定制数据库驱动,Triple是只局限于自己的领域。③访问的接口不同。D2R可以通过关联数据和SPARQL两种方式展示,Ⅴirtuoso则是依赖SPARQL,而Triple是直接用关联数据形式访问。
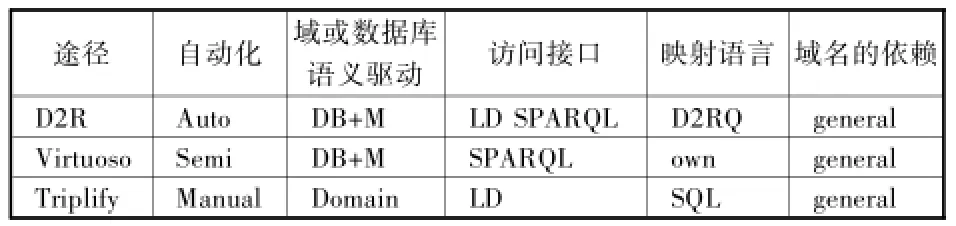
表2 三种方案的比较
(DB+M指,半自动方法即可以手动进行定制)
D2R是用来将关系数据库中的内容发布到语义网上的一个工具,在语义网中,使用RDF对数据进行建模和表示,D2R Server使用一个可定制的D2RQ映射文件来将关系数据库中的内容映射成RDF格式,并使这些数据可以被浏览和搜索到,这也是语义网中两种主要的访问模式。
3.2 D2R的优势
作为一种致力于关系型数据库的RDF映射框架,D2RQ由于其对环境(操作系统、数据库版本等)的适应性、操作简便性以及灵活的可配置性,仍不失为对现有数据内容完成关联数据化发布的最佳选择。D2R是其中一个非常流行的工具,它的作用是将关系型数据库的数据转换为虚拟的RDF数据进行访问。D2R主要包括D2R Server、D2RQ Engine以及D2RQ Mapping语言。选择D2R Server的原因如下。
(1)D2R Server没有将关系型数据库发布成真实的RDF数据,而是使用D2RQ Mapping文件将其映射成虚拟的RDF格式。它的好处是可以适时地使以大型关系数据库为后端的应用系统可以提供语义服务,而不用事先将大量关系型数据库存储在专用RDF数据库中。
(2)D2R Server是一个HTTP Server,是广泛应用的关系数据库内容发布成关联数据的一种工具。用D2R Server发布的关联数据集有:Berlin DBLP Bibliography Server;Hannover DBLPBibliography Server;欧盟国家和地区数据库;欧洲研究和发展信息服务;欧洲就业服务;欧洲研究领域人才数据库。D2RQ Engine并没有将关系型数据库发布成真实的RDF数据,而是使用D2RQMapping文件将其映射成虚拟的RDF格式。一般来讲,数据库的数据规模都比较大,且内容经常发生变化,转换为虚拟的RDF数据空间复杂度会更低,更新内容更加容易,因此,D2R的应用更加广泛。
4D2R方案案例:河北大学知识组织与知识管理实验室D2R项目
该项目组在国家社科基金与教育部人文社科基金支持下建立,通过在完成词表本体化组织基础上,通过D2R生成映射文件完成了关系型数据的二维组织模式转换为RDF的三元组模式;通过关联数据的统一语义描述方法(RDF)和统一存取机制(SPARQL),实现了对书目信息关联化发布及在关联发布与本体基础上的语义化组织与语义化聚合。
项目组在实验室通过D2R实验实现了下述内容(网址:http://sinto.hbu.edu.cn/D2R)。
(1)书目数据的关联化发布。初步实践基于本体构建语义关联,通过关联数据的一致化语义描述方法(RDF)和统一存取机制(SPARQL)进行语义化组织,实现书目数据关联化发布。
(2)映射的形成。将数据结构、约束条件转换为本体的概念语义和规则语义,通过执行D2R生成映射文件的执行脚本Generate Mapping实现[9]了关系型数据的二维组织模式转换为RDF的三元组模式。
(3)原有的语义关系的细化及书目数据的语义聚合。通过词表本体化组织及关联化发布,基于本体与实际语义逻辑修改MAPPⅠNG文件,实现书目原有语义关系的细化及细化关系后的书目数据的语义聚合。
[1]肖强,郑立新.关联数据研宄进展概述[J].图书情报工作,2011(13):72-75,134.
[2]任瑞娟,等.分布式本体编辑系统(ADORES)的设计与实现[J].现代图书情报技术,2011(3):9-16.
[3]白海燕,乔晓东.基于本体和关联数据的书目组织语义化研究[J].现代图书情报技术,2010(9):18-27.
[4]黄永文.关联数据驱动的Web应用研究[J].图书馆杂志,2010(7):55-59.
[5]白海燕,梁冰.利用D2R实现关系数据库与关联数据的语义映射模式[J].现代图书情报技术,2011(z1):1-7.
[6]孙鸿燕.图书馆关联数据的综合管理及其实现[J].图书馆学研究,2011(23):51-54,5.
[7]任瑞娟,等.基于概念云与本体的信息检索系统(ⅠRSCCO)的设计与实现[J].情报学报,2011,29(6):992-999.
[8]Miller,et al.Linked data and libraries[J].Serials Librarian,2011,60(1-4):17-22.
[9]王毅喆,张力.金融领域基于本体模式的关联数据转换解决方案[J].计算机工程,2007,33(12):93-95.
G250.74
A
1005-8214(2014)12-0030-05
濮德敏(1968-),女,副研究馆员,硕士,发表论文10余篇;任瑞娟(1970-),女,教授,博士在读,发表论文及出版著作30多篇(册);米佳(1976-),男,副研究馆员,本科,发表论文20余篇;张欣(1986-),女,硕士,发表论文2篇。
2014-02-26[责任编辑]菊秋芳
本文系教育部人文社会科学研究一般项目规划基金(项目编号:11YJA870019)和教育部“网络时代的科技论文快速共享”研究资助项目(项目编号:201113)研究成果之一。
猜你喜欢
山东冶金(2022年2期)2022-08-08
山西大学学报(自然科学版)(2021年1期)2021-04-21
哈哈画报(2021年10期)2021-02-28
科学技术创新(2020年22期)2020-01-09
五邑大学学报(自然科学版)(2019年3期)2019-09-06
计算机技术与发展(2018年12期)2018-12-20
制造业自动化(2017年2期)2017-03-20
青春岁月(2016年21期)2016-12-20
现代防御技术(2014年6期)2014-02-28
图书与情报(2013年1期)2013-11-16
