
基于形态学图像处理的网屏编码识别技术*
2013-12-07 06:18孙延鹏王尔申魏勇涛
电子技术应用 2013年2期
孙延鹏,许 军,王尔申,魏勇涛
(沈阳航空航天大学 电子信息工程学院,辽宁 沈阳 110136)
网屏编码具有信息隐藏量大、安全性高、成本低、鲁棒性好、抗攻击能力强等优点[1-2],在信息隐藏和纸类防伪方面发挥着越来越重要的作用。编码图像预处理是网屏编码应用的关键技术,随着对网屏编码技术的深入研究,许多学者针对网屏编码的特点,在图像预处理过程提出了各自的改进算法。参考文献[3]采用自适应动态阈值来实现二值化,即根据项目经验设定一个初始阈值,然后根据各个像素周围区域的灰度值确定中央像素的阈值。参考文献[4]将基于B样条的边缘检测技术应用到识别过程中,该技术具有较好的光滑性,同时与原图像曲面具有相似的凹凸性。参考文献[5]提出了使用三次样条插值方式提高定位点的定位准确性。参考文献[6]使用双线性内插值方法进行图像的缩放。
网屏编码具有信息位小、信息隐藏的特点,识别只需读取相应的信息即可,而信息位的形状、大小、样本背景及纹理都不会对信息位的判读产生影响。形态学处理能膨胀或腐蚀图像,但是可以不改变信息位所含的信息。根据这一特点,本文将形态学图像处理应用于网屏编码图像预处理。
1 系统框图及功能
扫描获得网屏编码图像后,首先进行图像二值化。通过构建合适的结构元素,进行形态学开运算和闭运算,去掉图像的瑕疵和污点,再将原图像与腐蚀后的图像相减,实现了图像的边界提取。倾斜矫正后经过坐标定位,采用网格法将其译码读出,基本流程如图1所示。
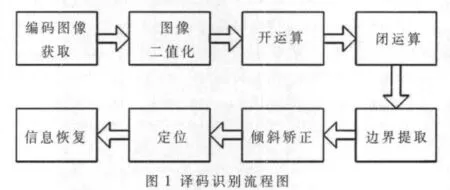
2 图像预处理算法研究及实现
2.1 图像二值化
图像二值化主要有两方面的作用[7]:(1)为使用形态学打下基础;(2)在图像二值化过程中,能够滤除背景中的噪音,并且在最后网格坐标定位时化繁为简,缩短识别时间。实现图像二值化有以下两个步骤:
(1)彩色图像转为灰度图像:根据三基色原理,实现过程为:
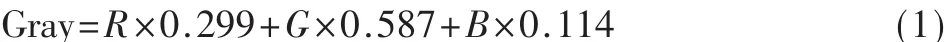
(2)灰度图像转为二值图像:扫描编码图像得到的直方图并没有出现明显的双峰形状,故不能采用双峰法或迭代法选取阈值作为二值化的归一化阈值。根据直方图特点,选用最大类间方差法。具体计算过程如下:
首先将图像按灰度级用阈值T分为C0和C1类,即:
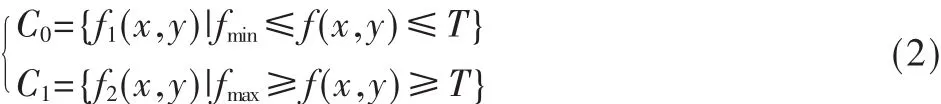
图像f(x,y)的均值为:

定义两类的类间方差σ2(T)为:

使类方差σ2(T)取得最大值时的阈值,即:

其中,fmin、fmax分别为图像 f(x,y)中灰度的最大值与最小值,P0、u0、P1、u1分别为 C0、C1出现的概率和均值。
2.2 开运算和闭运算
在图像扫描过程中会不可避免地引入噪音,常见的有孪生像噪音、圆孔噪声、行噪音和随机噪音等,这些噪音会降低译码率。开运算能平滑图像轮廓,削弱狭窄部分,去掉细长突出、边缘毛刺和孤立斑点,断开目标物之间粘连。闭运算可以填充目标内的细小空洞和裂缝,连接断开的临近目标[8]。
结构元素的选取会影响滤波效果。Top-Hat算子具有高通滤波的某些特性,开Top-Hat算子能检测出图像的峰,闭Top-Hat算子能检测出图像中的谷,但是点目标图像中出现强背景噪音干扰时,传统的Top-Hat形态学滤波算子对其抑制就显得不理想。为此,有必要采用修正的Top-Hat形态学滤波算子[9]。
设待滤波图像 F={(x,f(x))|x∈P,P⊆E2},修正 Top-Hat形态学滤波器结构元素由两部分嵌套而成:内部结构元素 Bi(n×n)和外部结构元素 Bo(m×m),即 Bi⊂Bo。 定义边缘结构元素:

在此基础上定义修正的Top-Hat算子:
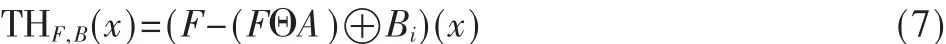
实验验证,修正Top-Hat形态学滤波器可以很好地抑制噪音的影响,如图2所示。

图2 原始图像与开运算后的图像比较
2.3 边界提取和倾斜矫正
扫描图像不能做到100%的水平,倾斜的编码图像使译码率急速下降,大大影响网屏编码的使用和发挥。倾斜矫正主要有3个过程:边界提取、Hough变换及水平矫正。
对于一个图像A,可以先用一个结构元素B对该集合进行腐蚀运算,然后再求腐蚀结果和集合A的差集,可以得到图像的边界,其定义为:

同样,像滤波一样,结构元素的选取会影响边界提取的效果。本文采用多结构元素、多尺度形态学边缘检测,具体步骤为;
(1)利用正方形结构元素B(w=5)进行边界提取,其中,B可以分解为8个不同的结构元素,如图3所示。即:
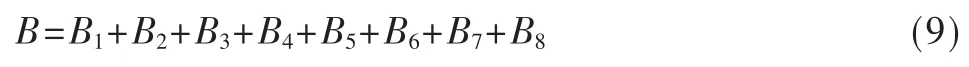

图3 正方形结构元素B及其8个不同方向的结构元素
(2)利用8个不通方向的结构元素分别提取图像的边缘,得到:

(3)将各个方向的边缘进行加权求和,最后得到图像的边缘:

式中,wi为权重值,各方向的边缘贡献应该一致,即取wi值为1/8。图4所示为倾斜矫正后的编码图像。
2.4 网格定位

图4 倾斜校正后的图像
采用网格法进行译码识别时,网格的坐标十分重要。固定网格法适用于数据量小、信息位整齐的编码图像。但是相对于二维码,网屏编码数据量较大,一张A4的纸大约能隐藏100 KB的数据[10],并且信息位较小,任何微小的纸张形变都可能对译码造成影响,因此有必要采用动态坐标定位法。图5的示为网格法动态行坐标定位流程图。

图5 动态行坐标定位流程图
与二维码网格法采用固定大小的网格不同,动态网格坐标法的网格大小随着纸张的形变而发生变化。由于已经将编码图像二值化,图像像素值只有“1”、“0”,所以计算量较小。坐标定位的主要思想是对每一行的像素值进行加法运算。每行的像素值与列像素数比较,若等于列像素值,则表示此行没有信息位;若不等于列像素值,则表示此行已经有信息位的一部分,将此行坐标值减1作为此网格上面的行坐标。继续对下一行像素值进行加法运算,直至像素和与列像素的个数相等,表明此行像素已经没有信息位,可将此行作为此网格下面的行坐标。列坐标的方法也类似,在此不再重复叙述。
3 性能分析
实验采取Intel(R)Core(TM)2 Duo T5470处理器、1.6 GHz主频、1.00 GB内存、Version7.8.0.347版本Matlab 2009a软件对样本进行信息读取。
3.1 识别率比较
表1所示为针对不同的样本进行不同的译码方法识别率的比较。通过多样本的验证可以看出,采用动态网格定位方法后,可以提高网屏编码的识别率。译码率的提高主要体现在采用动态网格定位法后,网格的定位更准确,消除了纸张微小形变对译码的影响。
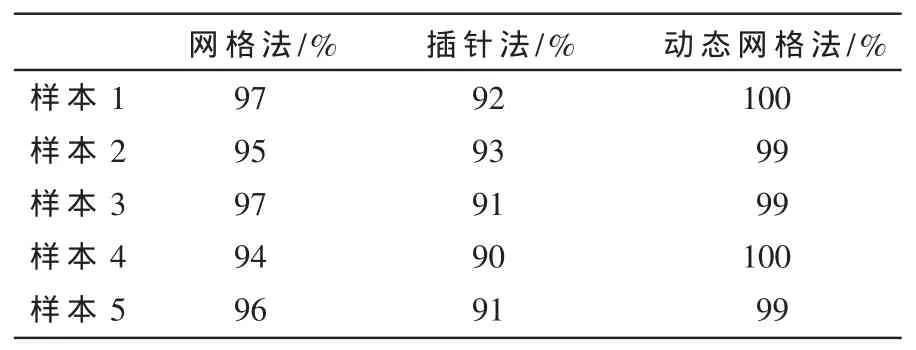
表1 不同方法的识别率
3.2 识别时间
识别时间比较,主要是通过对同一样本分别采用参考文献[4-5]图像处理方法和形态学图像处理方法,进行译码时间比较。表2所示为不同方法的时间统计表。
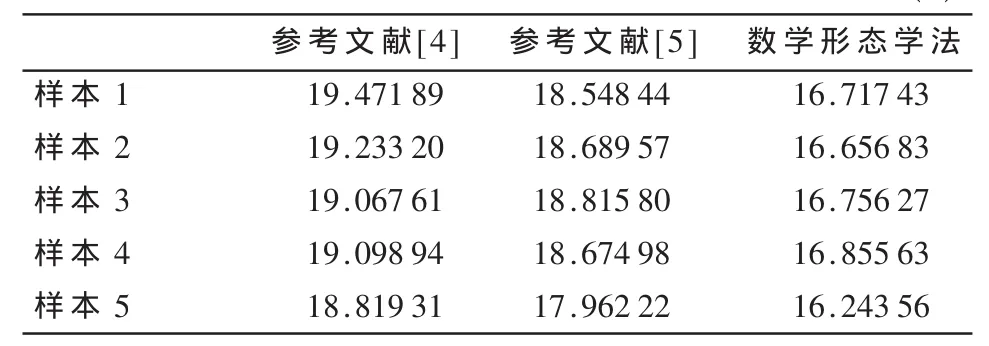
表2 不同方法的识别时间(s)
由表2可以看出,数学形态学法识别编码图像相对于参考文献[4-5]所用的时间减少了10%。其中主要体现在滤波和边界提取过程中运算量的减少。
本文根据网屏编码的特点,将形态学图像方法应用到译码中。通过选择合适的结构元素,实现了图像的滤波、边界提取和倾斜矫正。最后通过选取动态网格坐标,消除纸张形变对编码图像的影响。译码结果表明,在不增加识别时间的同时,识别率有了很大的提高,并且减少了一定的识别时间。对比结果显示了本方法的有效性,并可以应用于网屏编码的识别译码中。但是,网屏编码定位仍采用人工定位,如何实现自主定位图像、实现信息读取是下一步的研究目标。
[1]陈锡蓉,顾泽苍.论网屏编码技术及防伪应用[J].中国品牌与防伪,2008,11(1):64-67.
[2]郭淳学.网屏编码技术介绍 [J].电子技术应用,2010,36(1):17-23.
[3]王玲.基于网屏编码的多层印刷模型及自动读取系统[D].天津:南开大学,2009.
[4]胡小剑.网屏编码技术在信息隐藏和文档图像检索中的应用[D].天津:南开大学,2008.
[5]贾凤美.网屏编码信息安全技术的研究 [D].天津:南开大学,2007.
[6]孙铮.网屏编码技术在手机平台上的应用 [D].天津:天津大学,2009.
[7]张晓磊.基于网屏编码技术与混沌理论相结合的图像信息隐藏算法研究[D].天津:南开大学,2009.
[8]刘刚,赵立香,董延.Matlab数字图像处理 [M].北京:机械工业出版社,2010.
[9]车宏,孙隆和.圆形结构形态学滤波器优化设计及应用[J].南京航空航天大学学报,2011(4):486-490.
[10]赵立龙,顾泽苍,方志良,等.一种基于视觉特性及形态网屏编码的纸介质信息防伪方法[J].光电子·激光,2008,11(1):1524-1527.
猜你喜欢
小哥白尼(军事科学)(2022年2期)2022-05-25
现代电子技术(2021年7期)2021-04-08
现代计算机(2021年36期)2021-03-14
红领巾·萌芽(2019年8期)2019-08-27
中国与非洲(法文版)(2017年10期)2017-11-23
新闻传播(2016年3期)2016-07-12
CHIP新电脑(2016年3期)2016-03-10
中国继续医学教育(2015年2期)2016-01-06
遥测遥控(2015年2期)2015-04-23
振动、测试与诊断(2014年6期)2014-03-01
