
中文软件评论挖掘系统的设计与实现
2013-11-30 05:01:28文涛,杨达,李娟
计算机工程与设计 2013年1期
文 涛,杨 达,李 娟
(中国科学院软件研究所 互联网软件技术实验室,北京100190)
0 引 言
网络化软件以服务大众为目标,强调以用户的期望为着手点,通过多种途径使得自己提供的产品或服务达到或超越用户期望,获得用户满意。传统的用户满意度研究是通过确定用户满意度模型以及问卷调查的方式得到。然而这种方式由于数据收集过程繁琐、冗长,并且调查受众有限,很显然已经不能满足网络化时代的要求,特别是针对近几年来兴起的各类移动应用,其软件版本更新速度非常之快,若不能及时掌握用户需求,则会被市场所淘汰。
网络上存在着大量的用户对软件的评论,这些评论大都为用户使用软件后对其功能和性能的评价,通过对这些评论进行分析,可以得到大众用户对软件各方面的总体倾向,从而使软件开发者了解到自身产品的不足和用户的实际需求,为下一版本的改进依据。但是网络上的评论信息数据量巨大、来源众多,例如,仅Android Market上应用软件的总数量目前就已达40万[1],并且还在不断增长,一些热门软件的用户评论也是高达上万条,如果采用人工阅读的方式将会耗费大量的时间和精力,而目前并没有相关的对中文软件评论进行分析的工具,因此一个有效的中文软件评论挖掘系统将会给开发者带来具大的帮助。
目前,评论挖掘是一个非常热门的研究领域,具有很大的研究价值和应用价值,正受到国内外越来越多的研究机构和组织的重视。评论挖掘在英文领域的起步比中文领域早,技术也相对成熟,已有了一些原型系统和产品,并且有些还在商业中得到了应用。比较有代表性地如Liu[2]等人所开发的系统Opinion Observer,该系统从网上获取关于产品的评论,分析该评论中用户所针对的产品特征及所持的情感倾向,然后采用可视化方式对多种产品的特征的综合评价进行比较。微软公司的 Gamon[3]等人开发的“Pulse”系统可以自动获取网络上有关汽车的评论,并挖掘这些评论中所包含的褒贬信息及强弱程度。
中文方面,由于中英文之间的诸多差异,一些针对英文评论挖掘方面的研究成果无法在中文评论挖掘中直接应用,再加之中文评论挖掘研究起步较晚,目前已有的中文评论挖掘系统相对较少,最具代表性的是姚天昉[4]等人研究开发的一个用于汉语汽车评论的意见挖掘系统。该系统从各门户网站和汽车论坛上获取有关汽车的评论,然后挖掘用户在评论中对汽车各性能指标所持的观点,判断这些观点的极性以及强弱并给出可视化的结果。但是系统需要以人工的方式建立汽车本体,移植性较差,并且当产品属性发生变化时其本体还需要重建。因此,该系统对其它领域很难适用,特别是软件这一领域,软件功能的增加或变化是相当频繁的。
为此,本文构建了一个中文软件评论挖掘的系统。系统通过抓取网络上的软件评论数据,然后采用自然语言处理、机器学习、意见挖掘等技术,识别出评论中的关键信息(软件、特征、评价),通过对这些信息的细粒度情感倾向性分析,最终得到大众用户对软件各方面的满意度并将结果以可视化的方式进行展示。
1 系统设计
系统主要包含数据收集、意见挖掘和结果展示3个部分。详细的结构如图1所示。
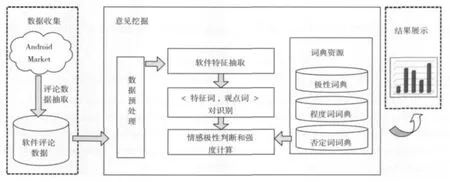
图1 系统总体架构
各个部分的主要功能如下:
(1)数据收集。它是整个系统的基础部分,主要负责从 Android Market(http://market.android.com)上抓取软件的相关信息和评论数据。Android是近年来兴起的智能手机操作系统,其平台上拥有大量的应用程序和用户。Android Market正是提供基于Android平台软件下载的一个大的站点,用户数量巨大,为本文的研究提供了大量的数据来源。同时Android Market开放了一些对外的API,这也方便了本系统数据的获取。
(2)意见挖掘。它由数据预处理、软件特征抽取、<特征词、观点词>对识别、情感极性判断及强度计算4个模块组成,是整个系统的核心部分。主要功能是利用自然语言处理、机器学习的一些技术从软件评论文本中抽取出软件特征、评价词等关键信息,然后通过对这些信息进行细粒度的情感分析,得到大众用户对软件各方面的满意程度。
(3)结果展示。它的主要功能是将软件评论进行意见挖掘分析之后的结果,以可视化的方式进行展示,方便开发者查看。
系统采用B/S结构进行开发,整个系统的流程大致可描述如下:首先用户通过交互界面输入软件名称(如图2所示),然后数据收集模块在Android Market中查找相关软件的信息并将检索结果反馈给用户,用户在结果页面选取某一款具体的软件后,数据收集模块再次启动抓取其评论数据,存储到数据库中。接着意见挖掘模块对评论数据进行挖掘分析,将结果传送给展示模块。最终结果展示模块以可视化的方式将结果进行显示。结果展示的界面如图3所示,以软件特征为粒度,显示其正负评论数,点击数字可以查看具体的评论信息。
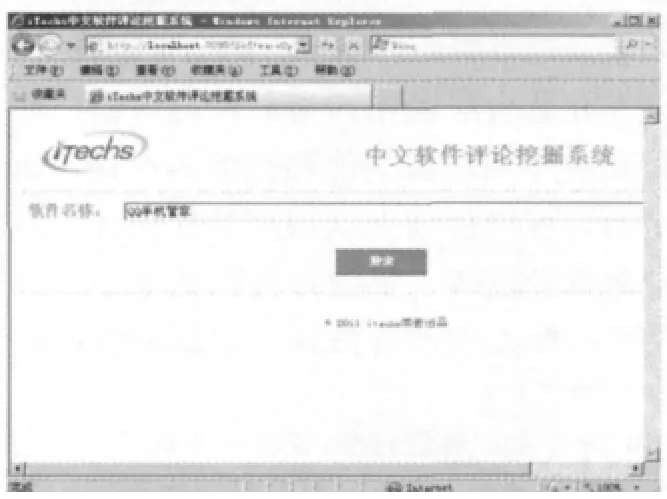
图2 系统交互界面
系统的实现和运行表明,各模块间只通过数据进行联系,降低了模块之间的耦合度,提高了实现的效率并方便了后续对各模块的改进。
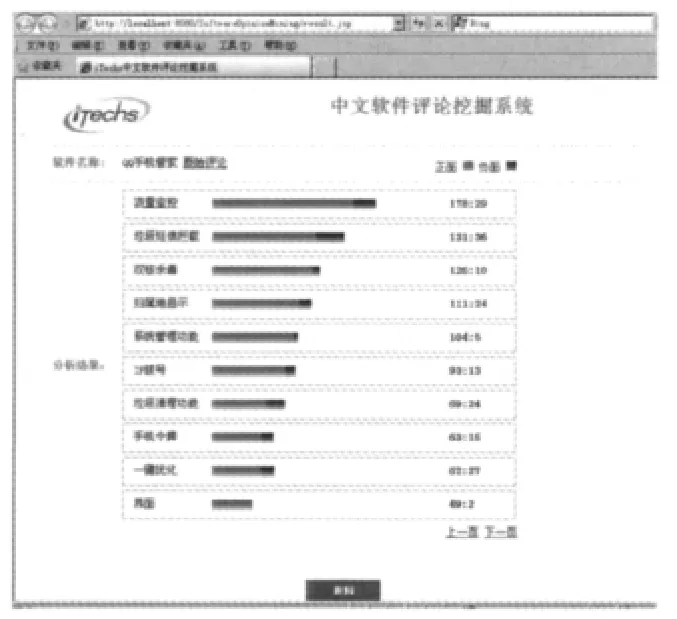
图3 结果展示界面
2 关键技术及实现
软件评论挖掘系统的有效与否主要在于其结果是否真实、准确。因此系统意见挖掘部分所涉及到的软件特征抽取、<特征词、观点词>对识别、情感极性判断及强度计算等技术是其关键的技术。
2.1 软件特征抽取
软件特征为用户对软件进行评论时的关注点,一般为描述软件功能或性能的词或短语。Hu和Liu[5]最早使用关联规则算法Apriori来进行产品特征的抽取。但是该方法并没有充分考虑评价对象的结构特征以及评价对象的领域相关性,直接用会产生很大噪声。国内的李实[6-7]等人对中文评论中产品特征的抽取进行了研究,他们在Apriori算法的基础上,设计了一些剪枝算法来提高特征挖掘的正确率和召回率。这与本文的方法比较相似,但是在剪枝策略的设计上有明显的不同。同是我们还注意到,对于软件这一领域,在利用频繁k项集(K>=2)生成特征时,还需要考虑词的顺序问题。如有频繁二项集 {省电,功能},描述的特征应为 “省电功能”而不是 “功能省电”,而有时还存在前后顺序都合理的情况,如 “垃圾清理功能”和 “清理垃圾功能”。基于此,本文的特征提取方法在剪枝后还加入了顺序还原的过程。方法基本步骤如下:
(1)对评论语料进行预处理,主要是将每一条评论语句进行分词和词性标注。本研究中利用了中国科学院计算所开发的分词软件ICTCLAS进行。
(2)在词性标注的语料中,提取出句子中的所有名词、动词以及字符,同时过滤停用词、情感词,最终形成的结果作为关联规则的事务文件。
(3)使用关联规则挖掘的Apriori算法寻找所有的频繁项集并将其作为候选特征集。
(4)距离剪枝。在中文评论中,假设fk是频繁规则k项集,表示为 {Q1,Q2,…Qk},评论语句S包含fk,S分完词也可以表示成词语序列的形式 {W1,W2,…Wn}。这样,S包括fk的最短摘要定义为包含fk中所有词的最短词语序列,比如从 Wi到Wj(0<i<j≤n)。定义fk的距离为表达式(1)所示
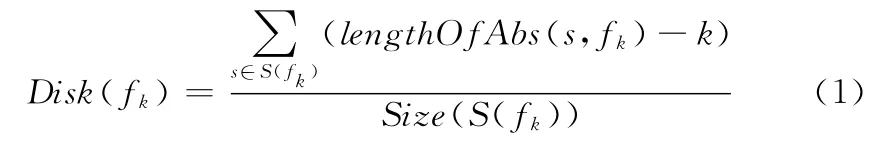
式中:S(fk)——fk包含的所有评论语句的集合,length-OfAbs(s,fk)——s中包含fk的最短摘要的长度,Size(S(fk))——集合的大小。
遍历所有的频繁k项集(K>=2)fk,将Dist(fk)>α的项从候选项集中移除,这里α为设定的一个阈值,本系统中设置为4。此技术主要为了找出频繁出现的短语候选特征。
(5)冗余过滤。如果某一频繁项集的所有项被更高的频繁项集所包含,则将该频繁项集从候选特征集中删除。这一步骤主要是为了防止生成冗余的特征。
(6)还原顺序。对于K>=2的频繁K项集,在生成特征时,还需要考虑其顺序。如对于频繁二项集 {省电、功能},需要确定最终的特征是 “省电功能”还是 “功能省电”。本文的方法是对该频繁项集在其评论语句中的出现顺序进行频次统计,若某种顺序出现的频次大于阈值β,则认为是合理的顺序,本系统中设置为3,之所以不直接取频次最高的是因为可能存在多种顺序都是合理的情况。例如:“病毒扫描功能”和 “扫描病毒功能”都是合理的且为同为同一特征,但不同的用户的表达不同而已。对于多种顺序都合理的情况,选取出现频次最多的为该特征的标准表示,其余合理的形式为其同义表示加入特征列表中。
2.2 <特征词,观点词>对识别
在构建出软件的特征库后,针对每一条评论语句需要进一步识别出其中包含的<特征词,观点词>对。我们通过对真实软件评论中出现的特征词和观点词进行了观察分析,发现特征词和观点词在句子内部存在一定的语法关系。如 “好看的界面,强大的功能,我喜欢”这一评论中,特征词 “界面”、“功能”分别与观点词 “好看”,“强大”形成修饰关系。因此在句子特征词已知的情况下,可利用语法关系识别出对应的观点词。本文正是通过引入依存句法分析技术完成<特征词,观点词>对的识别。依存句法主要是通过分析句子内部各个语言单位成分的依存关系来表示句子的句法结构。通过对软件评论句子的依存关系仔细研究,我们得到特征词和观点词的依存关系主要有如下3种:
(1)定语结构(amod)。若特征词出现在句子的定语结构中,则结构中的形容词即为该特征对应的观点词。如对于评论语句 “真/d是/vshi一/m 款/n好/a软件/n”,其中包括了结构 “amod(软件-6,好-5)”,则可以识别出<特征词,观点词>对<软件,好>。
(2)主谓结构(nsubj)。评论中有一类语句是特征词为主语的情况,这时观点词一般为谓语或补语。首先遍历句子中所有出现特征词的主谓结构,若谓语为形容词,则该形容词即为修饰该特征词的观点词;若谓语为动词,还需要继续寻找包含该动词的补语结构,将修饰动词的补语作为该特征对应的观点词。如表1的两个例子就对应了这两种情况(ccomp表示补语结构)。
(3)动宾结构(dobj)。除了形容词能作为观点词外,动词通常也可以用来表达用户的情感,如 “喜欢”、“讨厌”等。动宾结构就是为了处理特征词和观点词的这一类对应关系。如在评论语句 “比较/d喜欢/vi隐私保护功能/n,/wd不怕/v别人/rr愉看/v手机/n”中,就存在结构 “dobj(喜欢-2,隐私保护功能-3)”,因此识别出<隐私保护功能,手机>。

表1 评论中的主谓结构
我们使用了Stanford Parser[8]的中文自然语言处理工具来得到一个句子的依存关系,然后基于上述3种结构,在已知特征词的前提下,定位句子中相对应的观点词,生成<特征词,观点词>对
2.3 情感极性判断及强度计算
为了获得<特征词,观点词>的极性,需要借助极性词典。本文所提到的极性词典主要由三部分构成:①基础极性词典。直接使用了知网[9]公布出的情感词汇资源,包含负面评价词语(3116个),负面情感词语(1254个),正面评论词语(3730个),正面情感词语(836个)。②网络极性词典。由于网络上的用户评论中口语化比较普遍,仅仅利用书面的一些观点词并不能满足需求。因此本文构建了网络极性词典,它主要由两部分构成,一是从现有的《中国网络用语词典》中挑选了83个观点词语。二是从真实评论语料中,人工随机浏览500条评论,从中抽取出具有观点倾向的网络词语。③领域极性词典。某些词语只有结合其使用的领域才能判断出其表达的情感极性。如 “大”这个词,在 “屏幕很大”与 “内存占用很大”中就表现出完全相反的极性。本文通过人工的方式,构建了一个软件领域常用的极性词词典。
对于在极性词典中检索不到的词,本文采用了基于知网的极性计算方法[10]。对于某个观点词word,其静态极性计算如下:
(1)选取22对褒贬基准词。这里基准词指褒贬态度非常明显,具有代表性的词语。基本思想就是:与褒义基准词联系越紧密,则词语的褒义倾向性越强烈;与贬义基准词联系越紧密,则词语的贬义倾向性越强。
(2)利用选取的基准词通过表达式(2)计算出word的正面接近程度Positive(word)。
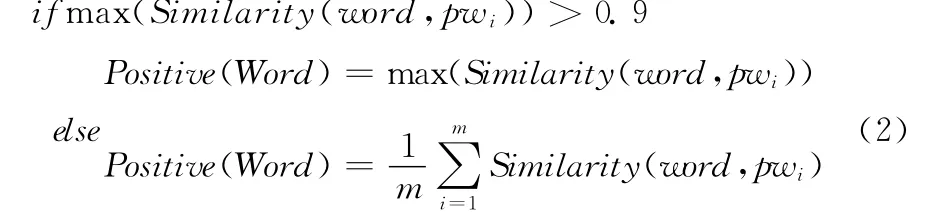
式中:pwi——某个褒义基准词,m——褒义基准词的个数,Similarity(word,pwi)——利用HowNet计算两个单个词之间的相似度结果。具体而言,就是利用知网计算两个词汇义原之间的相似度,并取两个词汇义原之间相似度的最大值作为Similarity(word,pwi)的结果。同理,也可以计算出word负面接近的程序。
(3)最终word的极性得分为
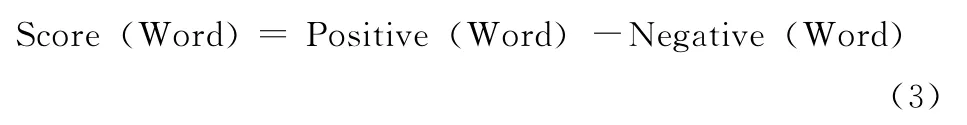
在考虑<特征词,观点词>对的极性强度时,还不能够忽视程度词和否定词的影响。例如对于评论语句 “界面比较好看”,“界面非常好看”,“界面不好看”,抽取出的都为<界面,好看>这一二元关系对,但前两句的情感强度是递增的,最后一句情感极性会反转。显然,为了更准确表达用户的情感倾向,必须要考虑修饰情感词的程度副词和否定副词。本文总结了一些常用的程度词,根据它们的程度分为了4个级别,赋值从0到1,分别为 {0.2,0.5,0.8,1.0}。否定词会对句子的情感倾向产生反转的影响,同样,本文总结了部分常用的否定词,建立的常用的否定词词典。最终,情感强度的计算为表达式(4)所示
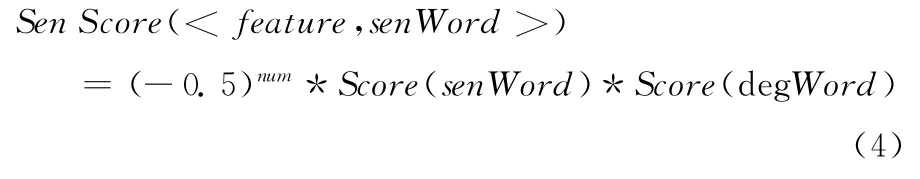
式中:Score(senWord)——情感词senWord的分值,它可以通过查表或式(3)计算。Score(degWord)——程度词的分值,num表示句子中否定词的个数,我们知道双重否定表示肯定,通过句子中否定词的个数是奇数还是偶数能决定是否发生反转。但是一般情况下并不能直接取反,例如,“不好看”并不代表 “难看”,“不是不好看”也不并能等价于 “好看”,因此本文设置否定词的反转参数为-0.5。
3 实验结果与分析
为了验证系统的有效性,本文对系统中使用的关键技术的效果进行了实验评估。我们选取了Android Market上4款使用较多的软件的用户评论评论作为实验数据,分别为 “QQ手机管家”、“搜狗手机输入法”、“UC浏览器”和“360手机卫士”。
由于网络评论中存在大量的噪音,有很多句子并不是用户对软件的评论语句。本文将包含软件特征的句子设定为评论句,这样就滤掉了一部分无用的句子。同时,对于一些结构比较复杂的句子,进行了人工断句处理。最后通过在这些数据集上的实验,和人工标注的结果作对比,得到了方法在特征抽取和极性判断两个方面的效果,结果见表2和表3。
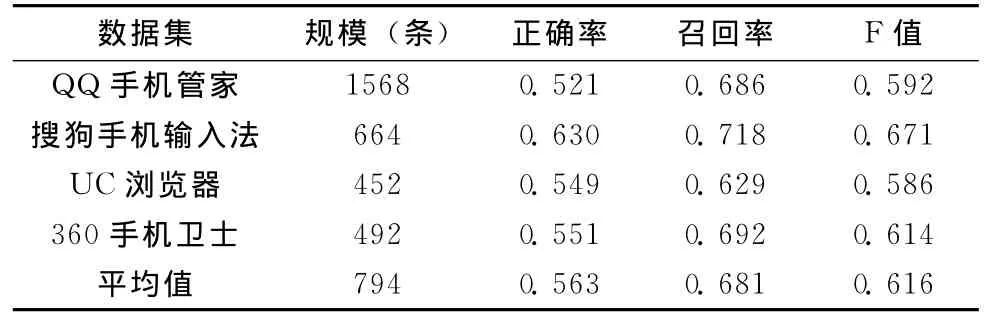
表2 软件特征抽取结果
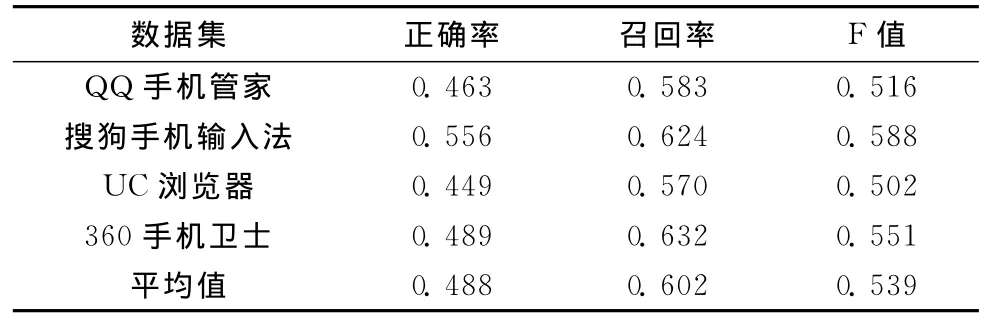
表3 特征情感倾向判断结果
从表2可以看到,对于软件特征抽取结果,4个数据集上的F值都在0.6左右,结果比较稳定。通过进一步分析特征抽取错误的结果发现其主要原因包括以下三点:①一些软件特征为比较复杂的短语结构;②特征之间存在层次关系,例如 “软件速度很快”,“双核杀毒速度很快”,前者的“速度”表示软件整体运行速度,后者的 “速度”为 “双核杀毒”的速度,而本文并没有考虑。③一些分词和词性标注的结果不准确。因此,如何挖掘出复杂短语结构的软件特征、分析软件特征之间的层次关系以及减少分词错误对特征抽取结果的影响都将是今后进一步工作的改进方向。
情感倾向判断的结果如表3所示,由于情感倾向判断是以软件特征抽取为前提的,因此会存在错误的叠加,但通过结果对比可以看出,情感倾向判断的F值(0.539)相比于软件特征抽取的F值(0.616)并没有低很多,由此可以得到在抽取出的正确的特征上,情感倾向的判断结果大都是正确的,这也充分说明了系统的有效性。
4 结束语
如何快速获取用户对软件的满意度,从而发现用户期望,为软件的改进提供依据,一直是软件开发者关注的问题。特别是随着移动互联网的兴起,大量移动应用的涌现,加之移动应用软件版本快速更新的特点使得这一需求更加迫切。为此,本文构建了一个中文软件评论挖掘的系统。系统利用网络上用户的海量评论数据,通过自然语言处理、机器学习等技术,识别出评论中的软件特征和用户对这些特征所表达的情感倾向,最终通过可视化技术将结果进行展现,方便了开发者及时了解用户反馈,从而发现用户期望,为软件的改进提供了依据。同时,通过在Android Market上的测试,验证了系统的有效性。
当然,这个系统还存一些不足的地方,如软件特征抽取时只考虑了显示出现的软件特征;观点词识别的效果依赖于句法分析的精度,而目前中文句法分析的技术还不是很成熟等。这些也将是本系统下一步改进的方向。
[1]Distimo.Google android market[EB/OL] .[2011-11-30].Http://www.distimo.com/appstores/stores/view/19-Google _Android_Market.
[2]Liu B,Hu M,Cheng J.Opinion observer:Analyzingand comparing opinions on the Web[C]//New York:Proceedings of the 14th International Conference of World Wide Web,2005:342-351.
[3]Gamon M,Aue A,Corston-oliver S,et al.Pulse:Mining customer opinions from free text[C]//Madrid:The 6th International Symposium on Intelligent Data Analysis,2005:121-132.
[4]YAO Tianfang.An opinion mining system for chinese automobile reviews[C]//Beijing:Proceedings of the 25th Chinese Information Processing Society,2006:260-281(in Chinese).[姚天昉.一个用于汉语汽车评论的意见挖掘系统[C]//北京:中国中文信息学会二十五周年学术会议,2006:260-281.]
[5]Hu Minqing,Liu Bing.Opinion extraction and summarization on the web[C]//Boston:Proceedings of the National Conference on Artificial Intelligence,2006:1621-1624.
[6]LI Shi,LI Qiushi.Research on pruning algorithm of product feature mining in Chinese review[J].Computer Engineering,2011,37(23):43-45(in Chinese).[李实,李秋实.中文评论中产品特征挖掘的剪枝算法研究[J].计算机工程,2011,37(23):43-45.]
[7]LI Shi,LI Qiushi.Improving the performance of features extraction from Chinese customer reviews[C]//Hong Kong:The 2th International Conference on Communication Systems,Networks and Applications,2010:26-29.
[8]Stanford Parser web page[EB/OL].[2012-01-10].http://nlp.stanford.edu.software/lex-parser.shtml.
[9]DONG Zhendong,Dong Qiang.HowNet[EB/OL].[2012-02-01].Http://www.keenage.com(in Chinese).[董振东,董强.知网[OL].[2012-02-01].Http://www.keenage.com.]
[10]ZHU Yanlan.Semantic orientation computing based on HowNet[J].Journal of Chinese Information Processing,2006,20(1):14-20(in Chinese).[朱嫣岚.基于HowNet的词汇语义倾向计算[J].中文信息学报,2006,20(1):14-20.]
猜你喜欢
时代英语·高一(2019年5期)2019-09-03 02:09:34
计算机技术与发展(2018年8期)2018-08-21 02:08:14
军营文化天地(2018年1期)2018-08-15 00:44:08
中国机械工程(2017年22期)2017-12-02 01:52:34
电测与仪表(2016年11期)2016-04-11 12:20:42
电源技术(2015年5期)2015-08-22 11:18:28
中文信息学报(2015年4期)2015-04-21 08:29:12
营销界(2015年22期)2015-02-28 22:05:04
清风(2014年10期)2014-09-08 13:11:04
武陵学刊(2011年5期)2011-03-20 20:59:04
