
基于交货期的多目标一维优化下料模型研究*
2013-11-24 02:17:52邱红喜
网络安全与数据管理 2013年1期
邱红喜 ,刘 林 ,2,裴 军
(1.合肥工业大学 管理学院,安徽 合肥 230009;2.过程优化与智能决策教育部重点实验室,安徽 合肥 230009)
当今,企业之间的竞争已发展成为供应链与供应链之间的竞争。给供应链环境下企业的下料问题带来了新的特点,供应链下的下料问题普遍呈现多目标的特性,更注重供应链中相关环节的利益平衡。
近年来许多学者对下料排产[1]各种问题做了大量的研究。如参考文献[2]采用离散变量优化方法对优化目标为废料最短的下料模型优化求解,并改进了优化下料的线性模型。参考文献[3]建立了复杂约束状态下,以综合资源消耗最小为目标函数的优化下料问题的数学模型;提出并实现了非定长优化和定长优化相结合的两阶段一维优化下料方法。参考文献[4]研究了余料最小和满足顾客需求的多目标下料问题模型,把上述模型转化成单目标整数规划模型用分支定界法求解。参考文献[5]研究了由交货时间限制较大规模的单一原材料下料问题模型,针对该型提出DP贪婪算法发现下料问题主要局限于单一的下料生产环节,建立的目标和约束也没有充分考虑复杂的生产环节。本文构造一个基于余料和交货期惩罚的多目标模型。利用改进的非支配排序遗传算法来求解该模型的Pareto最优解集。并通过实验仿真来验证算法的有效性,从而为改进企业生产模式、提高企业整体竞争力提供了一种新的途径。
1 多目标优化的数学模型
1.1 模型假设
在充分了解并分析了实际情况后,对一维下料问题提出如下假设:
(1)每种坯料都有各自的交货期,若某种坯料无交货期,则记该坯料交货期为无穷大。
(2)每天下料的数量受到企业生产能力的限制,每天下料的数量等于最大下料能力。
(3)切割时由锯缝、改换模具以及废料处理问题等一些因数产生的损耗在此不作考虑。
1.2 基于交货期的一维下料模型
设某企业现有若干根长为L的原材料,需要截成m种不同长度规格的坯料。每种坯料都有各自的交货期tj,如何截取,从而使第一目标是“余料最小”;其次,因企业一些特殊原因造成坯料不能按期交付,因此“不同交货期的惩罚最小”成为第二目标。
上述下料问题的多目标下料数学模型如下:
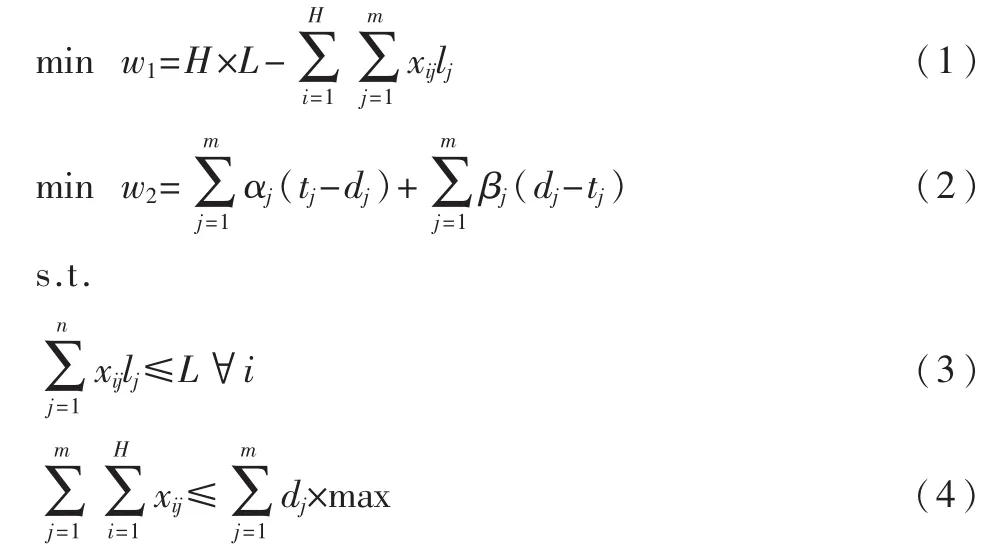
xij≥0 且 为整数 ∀i,j
其中:式(1)为余料最小的目标函数;式(2)为交货期满意度最好的目标函数;式(3)为原料长度的约束条件;式(4)为下料的数量不能超过企业的生产能力的约束条件;i表示原材料的编号;j表示坯料种类编号;H表示原材料的使用数量;lj表示第 j种坯料的长度;xij表示从 i号原料上截得第j种坯料的数量;dj表示第j种坯料的实际完工时间;T1~T2表示合理的交货期区间;tmin表示最早的交货期;tmax表示最迟的交货期;max表示企业每天最大的生产能力。
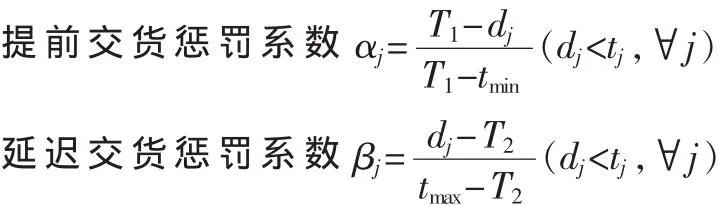
2 模型求解
随着问题规模的增大,组合优化问题的搜索空间急剧扩大,并且多为非线性规划问题,所以也是一个NPHard问题。大多数对于这样问题,一般无法得到最优结果或无法及时得到最优结果。人们已意识到应该把主要精力放在寻求其非劣解上。本文采用改进的非支配排序遗传算法[6],求解该模型的优化下料问题不仅可以避免早熟收敛,还提高了收敛速度。
2.1 编码
编码方式也称为基因表达方式,种群中的每个个体,即每个染色体是由基因构成的。根据一维下料问题的特点,选择用坯料的一个全排列作为一个下料方案,构成一个染色体,其中每个坯料作为基因。初始群体由需求的坯料随机排列产生。例如:有待切的坯料5种,依次给每种坯料编号(1~5),这样每个染色体的长度都是固定的。原料要切出1个1号坯料,3个2号坯料,2个3号坯料,1个4号坯料,1个 5号坯料,随机产生序列(5,2,1,4,3,3,2,2)就是群体中的一个个体。
2.2 拥挤距离
把非劣解集中的解(即每个个体)按某一维目标函数降序排列,处于边缘的个体分配给它以无穷大的距离,而剩下每个个体的拥挤距离可以通过计算同级别与其相连的两个个体在每个目标上的距离差之和来求取。拥挤距离大的个体参与繁殖和进化的机会较多,从而维持种群的多样性。拥挤距离的计算是为确保算法能收敛到一个均匀分布的Pareto曲面。
2.3 非支配排序
非支配排序的具体过程:首先找出当前种群中非支配最优解并分配等级1;然后将这些个体从种群中移出,在剩余个体中找出新的非支配解,再分配等级2;重复上述过程,直至种群中所有个体都被设定相应的等级。
2.4 遗传算子
(1)选择算子
本文采用联赛选择的方法,即在群体中,随机抽取(取值为2)个体,两两比较,非支配排序等级和拥挤距离皆优者保留,直到满足群体规模。如果两个个体的非支配排序等级不同时,则优先考虑等级低的个体;如果两个个体等级相同,则优先考虑较不拥挤的个体。
(2)交叉算子
交叉算子如果采用经典的单点交叉算子,产生的新个体有可能出现重复或缺失某些基因,导致该个体不合法。因此交叉算子的设计采用顺序交叉的方案,方法是由一染色体随机选出一个子串,复制到一个空染色体中,形成原始后代,然后另一染色体去掉和子串重复的基因,按顺序从左到右补齐原始后代染色体的空缺位置,这样就得到了一个新的后代染色体。采用该方法可以防止后代染色体出现重复的基因或缺失基因,从根本上保证了该个体的合法性。
(3)变异算子
变异算子的设计采用K-交换变异的方案,即在每个染色体中以概率P随机选取染色体上的两点,进行2-交换。文中采用的变异算子皆为2-交换变异。
2.5 算法流程
非支配排序遗传算法步骤:
(1)随机产生规模为 n初始化种群 P0,初始代数为g=0;
(2)非支配排序后,通过遗传算法的选择、交叉、变异三个基本操作得到第一代子代种群Q0;
(3)从第二代开始,将父代种群P0与子代种群Q0合并,此时种群规模变为2n,进行快速非支配排序,同时对每个非支配层中的个体进行拥挤距离计算;
(4)根据非支配关系以及个体的拥挤距离选择合适的个体组成新的父代种群;
(5)采用顺序交叉算子执行交叉操作;
(6)采用2-交换变异方案执行变异操作;
(7)判断是否达到终止条件,达到则算法结束,否则返回步骤(3)。
3 算例
下面给出一个例子说明上述算法的有效性。
例:下料所使用的原料长度L=2 000 mm,按企业的实际生产规模,需要32种配切的坯料,各坯料的交货期都为一周时间,最早交货期期为3天,最迟交货期为10天,产品合理的交货期为5~6天。各坯料的长度和需求量如表1所示。本算例中算法的种群规模为30~50,最大进化代数为 100,交叉概率为 0.25,变异概率为0.001。

表1 坯料重量与需求量
使用Delphi7语言编程,经单机运行得出Pareto最优解集如表2试验结果所示。
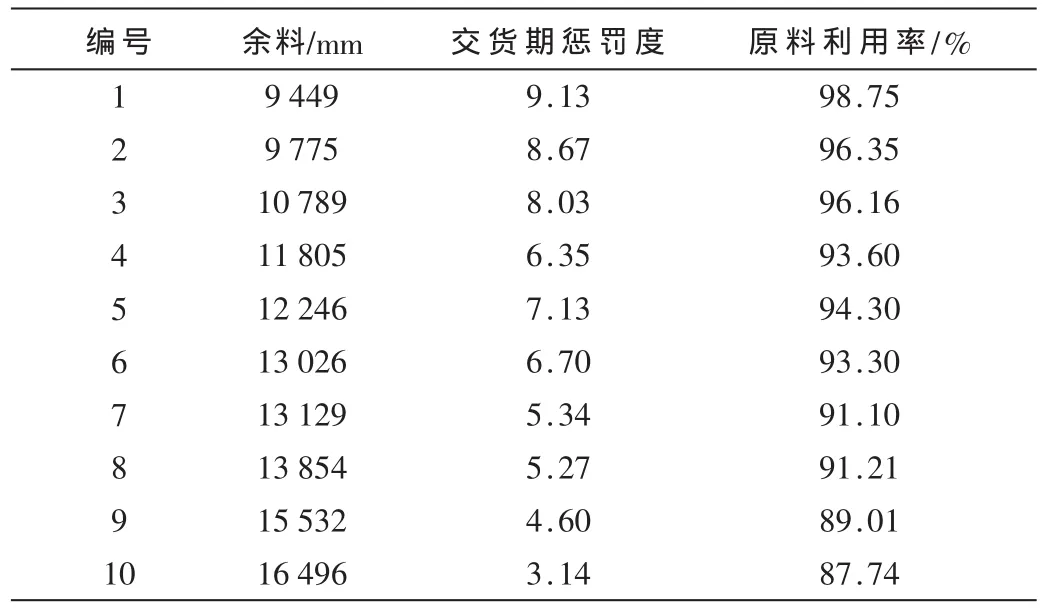
表2 试验结果
表3给出了改进的非支配排序遗传算法与非支配排序遗传算法比较结果。各算法的种群规模均取30~50,进化代数为均为100。利用参考文献[7]中的公式来比较最大散布范围、分布均匀性。最大散布范围的值越大,则表示散布范围越广;分布均匀性的值越小,则表示散布越均匀。

表3 两种算法比较
结果表明,改进的非支配排序遗传算法所获得Pareto解集较为稳定,解分布均匀,没有出现过陷于局部最优的情况。
改进的非支配排序遗传算法在解决多目标优化问题中表现出较好的性能,但仍然存在理论体系不够完善、实现方法不太成熟等问题。本文的研究工作,今后可以从以下几个方面进一步深入研究:(1)对于非支配排序遗传算法的继续深入研究和改进。(2)问题优化得到是一组Pareto解集,还需从这组Pareto解集中选出最满意的解,帮助决策者选出最满意的方案。
[1]HAESSLER R W,SWEENEY P E.Cutting stock problems and solution procedures[J].European Journal of Operation Research,1991,54:141-150.
[2]米洁.CAPP系统中优化下料问题的研究[J].机械,2001,28:30-32.
[3]阎春平,宋天峰,刘飞.面向可加工性的复杂约束状态下一维优化下料 [J].计算机集成制造系统,2010,16:195-201.
[4]林晓颖,王远.多目标优化下料问题的研究[J].哈尔滨师范大学自然科学学报,2003(5):14-16.
[5]王辉,朱珠,张志敏.有交货时间限制的大规模实用下料问题[J].数学的实践与认识,2005,35:64-69.
[6]VARELA R, MUÑOZ C, SIERRA M, et al.Improving cutting-stock plans with Multi-objective genetic algorithm[J].Communications in Computerand Information Science,2009, 22: 332-344.
[7]DEB K.Multi-objective optimization using evolutionary algorithms[M].New York: Jonh Wiley&sons Press, 2001:201-302.
猜你喜欢
轴承(2022年5期)2022-06-08 05:05:42
河南工学院学报(2021年3期)2021-09-27 12:08:44
文化交流(2019年3期)2019-03-18 02:00:12
沈阳师范大学学报(自然科学版)(2018年5期)2018-12-26 04:48:36
沈阳师范大学学报(自然科学版)(2018年5期)2018-12-26 04:48:36
中国科技博览(2017年14期)2017-06-05 14:58:09
科技视界(2016年27期)2017-03-14 15:33:44
科学与财富(2016年32期)2017-03-04 02:14:55
系统工程学报(2016年1期)2016-09-23 06:15:14
金属加工(热加工)(2015年21期)2015-11-30 03:27:15
