
高校信息化部分基础设施建设的实证分析
2013-11-22 11:44:16陈巍巍陈世平刘秋皊
上海理工大学学报 2013年2期
陈巍巍, 张 雷, 陈世平, 刘秋皊
(1.上海理工大学 管理学院,上海 200093;2.上海理工大学 信息化办公室,上海 200093)
信息化建设是一个新兴的课题,高校信息化也是如此.其建设内容包括基础设施建设、资源建设、应用系统建设、标准规范建设等.聚类分析作为一种基于相似性的子群划分方法,可先将调研地区进行分类,再根据分类情况对各类地区的信息化基础设施建设情况提出建议和指导,可有效地避免建设的不均衡和盲目性.按分类对象的不同,聚类分析可分为R 型和Q 型两大类,R 型聚类分析用于指标的分类处理,Q型聚类分析则用于样品的分类处理[1].在聚类的过程中,一方面,为度量样本间的相似性会采用如Euclidean距离、Man-hattan距离、Minkowski距离等.如果将距离的计算过程看成黑盒,那么这一过程就是从多维空间到一维空间的过程;另一方面,距离阈值d0该如何确定也是一件困难的事,且在很大程度上决定了簇类的数量和大小.从以上两方面来考虑,笔者试图先降维作特征提取,然后再进行比较,得到各个簇类.比较常用的特征提取方法主要有主成分分析(PCA)[2]和线性鉴别分析(linear discriminant analysis,LDA)[3].PCA基于这样一种思想:方差最大的方向包含最多的类间信息,而LDA则是在最大化类间信息的同时最小化类内信息,并最大化两者之比.然而,降维必定会导致信息丢失,而且这些具有较高复杂度的方法在动态、多变的环境中并无优势[4].因此,本文根据调研数据情况直接应用Q型聚类的方法,同时根据主成分降维聚类的结果对前面的聚类结果加以修正.以我国部分基础设施建设的数据为研究对象,通过对部分数据的分析和研究,以小见大,试图探索和总结高校整体信息化建设情况的分析方法与手段,并为如何更好地发挥信息化的作用提供理论参考.
1 数据来源与构建
2008年2月22日,教育部教育改革和发展战略与政策研究重大课题“教育信息化建设与应用研究”启动工作在教育部展开.第一工作组是“教育信息建设与应用状况调研组”,负责调研教育信息化建设与应用现状.本次调研区域包含:北京市、上海市、广东省、湖南省、湖北省、陕西省、甘肃省、内蒙古自治区、云南省、吉林省10个省、市、自治区.调研范围为这些区域的高校,包括高等职业技术学院[5].
信息化基础设施是信息化建设的基础条件,也是信息化的“命脉”.从一个社会组织的内部机构到一个组织的所有机构,从一个地区到一个国家,只有有了一条条畅通无阻的“信息高速公路”,形成了一个信息通信的网络,才有可能实现各种信息化应用.我国高校信息化基础设施的建设内容主要包含信息化基本设备配置、校园网建设、网络与信息安全建设、高性能计算环境建设四方面内容.本文由于可用的样本数据有限,主要从信息化基本设备配置数据着手进行研究和分析.
信息化设备包含服务器、个人计算机、交换机、路由器、扫描仪、录像机、投影机等.调研数据主要从服务器、个人计算机、多媒体教室的拥有现状三方面考察.服务器主要从价值方面来考察,统计计入固定资产的服务器总价值及10万元以上的服务器的台数.个人计算机主要从计入固定资产的个人计算机台数(包含笔记本电脑)及学生拥有个人计算机比例两方面考察.多媒体教室主要是考察配备多媒体设备(如投影仪)的教室占教室总数的比例及多媒体教室的利用率.综上,得信息化基本设备配置的6个指标X1,X2,……,X6,分别表示服务器的总价值/万元、10万以上服务器的数量/台、个人计算机数量/台、拥有个人计算机数量的比例、多媒体教室配备比例和多媒体教室的利用率.具体数据是以省和直辖市为单位,求出其所辖学校总体数据的平均值.
2 模型方法概述
2.1 主成分分析
用于数据分析的样品往往包含有多个(间隔)变量,较多的变量会带来分析问题的复杂性.然而,这些变量彼此之间常常存在着一定程度的、有时甚至是相当高的相关性,这就使含在观测数据中的信息在一定程度上有所重叠.正是这种变量间信息的重叠,使得变量的降维成为可能,从而使问题的分析得以简化[6].
主成分分析是设法将原来众多具有一定相关性(比如P个指标),重新组合成一组新的互相无关的综合指标来代替原来的指标.通常数学上的处理就是将原来P个指标作线性组合,作为新的综合指标.最经典的做法就是用F1(选取的第一个线性组合,即第一个综合指标)的方差来表达,即var(F1)越大,表示F1包含的信息越多.因此在所有的线性组合中选取的F1应该是方差最大的,故称F1为第一主成分.如果F1不足以代表原来P个指标的信息,再考虑选取F2,即选第二个线性组合.为了有效地反映原来信息,F1已有的信息就不需要再出现在F2中,用数学语言表达就是要求cov(F1,F2)=0,则称F2为第二主成分,依此类推可以构造出第三、第四,……,第P个主成分.
2.2 系统聚类
聚类分析至今,有许多种不同的聚类方法.其中应用得最多最成熟的方法为系统聚类法,也是本文将采用的方法.其思路为首先将每个数据对象各视为一类,根据类与类之间的距离或相似程度将最相似的类加以合并,再计算新类与其它类之间的相似程度,并选择最相似的类加以合并,这样每合并一次就减少一类,不断继续这一过程,直到所有数据对象合并为一类为止[7].
定义类与类之间的距离的方法有很多,应用欧几里得距离(Euclidean distance),即
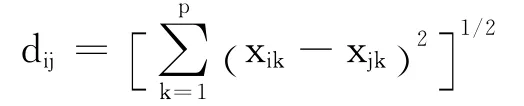
由于纳入分析的各变量方差相差太大时,变异度的差异会影响结果的正确性,所以一定要进行变量的标准化.类的个数可以综合系统聚类的结果和前面主成分分析的图形聚类分析共同确定.
3 实证分析
3.1 分析结果
根据主成分分析的思想,应用SPSS 16.0软件作为统计分析工具,首先将原始数据做标准正态变换(Z-Scores),消除数量级和量纲差异的影响[8],其次建立相关系数矩阵如表1所示.
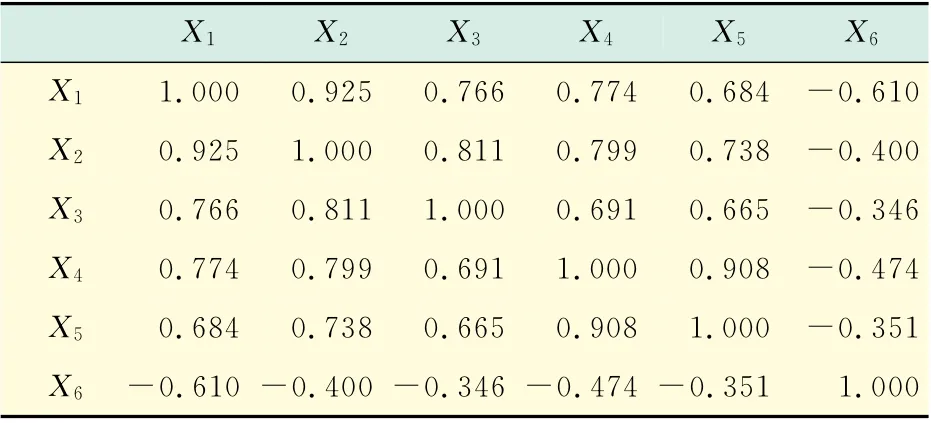
表1 相关矩阵Tab.1 Correlation matrix
通过数据处理得相关系数矩阵,从矩阵可看出指标间存在较强的相关性.进而对原始数据进行因子分析的可行性检验(KMO 值和巴特利特球形检验).KMO 的值为0.760>0.6;而巴特利特球形检验的显著性水平小于0.05,因此拒绝巴特利特球形检验的零假设.以上种种分析结果都表明样本适合主成分分析.进而求得主成分分析的方差累计贡献率如表2所示.
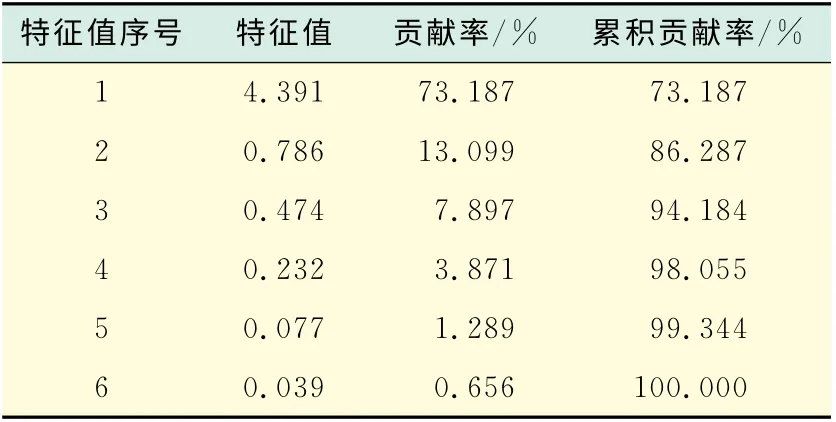
表2 特征值与贡献率[9]Tab.2 Eigenvalue and contribution
可见得到的前两个因子提取了原始数据的86.287%的数据信息,因此可以提取前两个因子作为主成分.同时也要注意,第一个主成分提取了73.187%的数据信息,相对于第二个主成分,它占有绝大多数的比例.而且从第二个主成分的主要数据源X6(根据表3)的原始数据分析,各省市的多媒体教室利用率的数值差异并不大(最小为86.58%,最大为94.64%).通过以上分析本文认为,从反映原始数据的角度来说第一主成分是更加重要和需要首要考虑的.
两个主成分与原始变量指标之间的关联程度由因子载荷值来体现,如表3所示.从表中可以看出第一主成分在前5个指标上具有较大的载荷值,第二主成分在第6个指标上具有较大的载荷值.联系实际指标意义可知,第一个主成分主要反映的是信息化设施配置水平,第二个主成分主要反映的是信息化设施的利用情况(这里主要是考察多媒体教室).显然这两个主成分是互为消涨的.
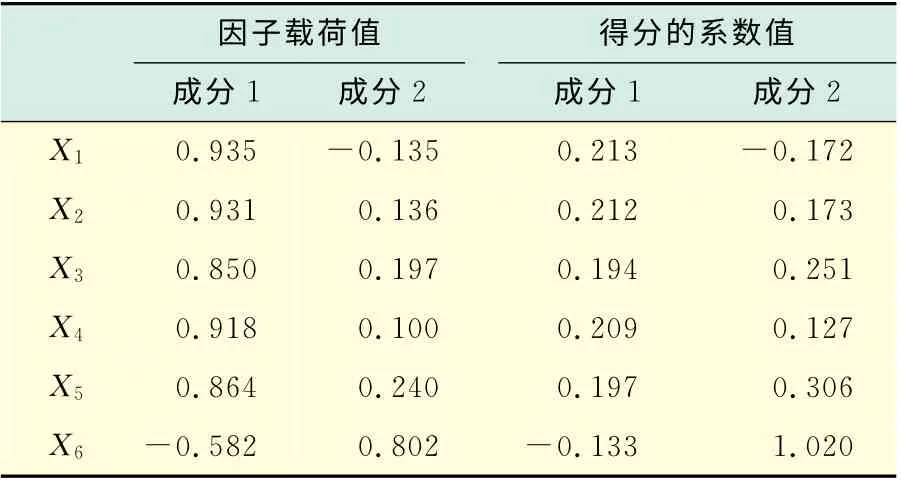
表3 成分的因子载荷和得分系数表Tab.3 Component’s factor loading and factor score
为了更直观的查看考察对象的两个主成分得分情况,采用线性回归的方法得到了成分得分的系数矩阵如表3 所示.由此可得到主成分得分的表达式为
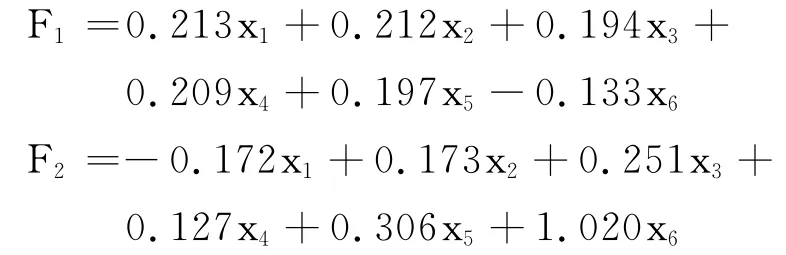
将各省、直辖市的标准化后的数据带入上式可计算出它们两个主成分的得分,进而可以画出如图1(见下页)所示的散点图,由于第一主成分比较重要,故意将横轴(第一主成分)的单位长度适当加大,以方便观察.
从图1看到北京的数据在基本设备配置水平方面远远高于其它省份,上海和广东省分居其后.吉林省和上海市在信息化设施的利用率方面相对较低,说明在现有的教学模式下,信息化设施基本满足使用要求.
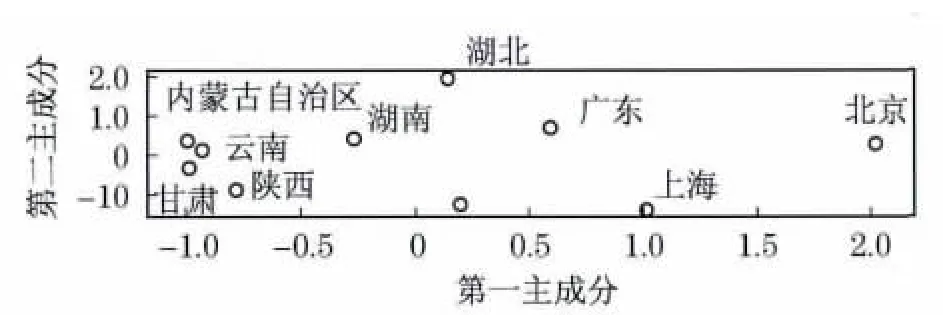
图1 主成分散点图Fig.1 Main components scatter chart
3.2 聚类分析结果
应用SPSS软件的系统聚类方法,得到图2 的聚类结果.

图2 系统聚类图Fig.2 System cluster chart
结合图1 的情况考察对象划分为4 类比较合理.第一类为第一主成分较低的省市,分别为内蒙古自治区、云南省、甘肃省、陕西省和湖南省,这些省份应该首要考虑提高辖内高校的信息化基本设备的配置水平,其次要考虑转变教学模式,灵活运用多媒体等信息化手段来改善教学效果.第二类为第二主成分比较高的湖北省,由于信息化基础设施的利用率相对较高,说明该省内高校信息化设备的利用处于饱和状态,所以进一步提高信息化设施的配置是当务之急.第三类为第一主成分相对较高,第二主成分相对较低的吉林省、广东省和上海市,它们所辖的高校现有信息化基本设备配置基本满足要求.但是从图1中注意到吉林省和上海市的信息化基础设施的利用率偏低,应进一步关注其高校的教学方式,及利用信息化先进技术的情况.最后一类为北京市,其所属高校无论在信息化基本设备配置的水平上,还是在信息化基础设施的利用上都表现较好.
4 结论和对策
通过上述分析,得出我国高校的信息化基本设备配置方面存在着不平衡表现的结论.东部沿海地区在信息化基础设施建设方面要远远优于中西部地区,这不利于我国高等教育的均衡发展.国家应当考虑从多方面扶持内陆贫困地区的高等教育信息化基本设备配置建设.从调研的10个省市来看,北京市的信息化基础设施建设最好,内蒙古自治区、云南省、甘肃省、陕西省和湖南省的基础设施建设还有待改善.从信息化基础设施的利用率来看,吉林省和上海市的利用率较低,可以进一步考察其在教学方式方法上是否有待改善.
[1]杨小平.统计分析方法与SPSS应用教程[M].北京:清华大学出版社,2008:227-228.
[2]Jolliffe I T.Pricipal component analysis[M].New York:Springer-Verlag,1986.
[3]Wang X C,Paliwal K K.Feature extraction and dimensionality reduction algorithms and their applications in vowel recognition[J].Pattern Recognition,2003,36(10):2429-2439.
[4]陈清华,李林锦,翁正秋.基于新聚类算法的推荐系统的研究 与 实 现[J].电 脑 知 识 与 技 术,2010,6(6):1523-1525.
[5]“教育信息化建设与应用研究”课题组.我国教育信息化建设与应用专题研究报告[M].北京:高等教育出版社,2010.
[6]王学民.统计分析方法及应用[M].上海:上海财经大学出版社,2010.
[7]唐敏,陈道平.基于因子分析和聚类分析的重庆市经济发展状况研究[J].现代商贸工业,2008(9):130-131.
[8]张文彤.SPSS11统计分析教程[M].北京:北京希望电子出版社,2002.
[9]柯兵,钱省三.聚类分析和因子分析在股票研究中的应用[J].上海理工大学学报,2002,24(4):371-373.
猜你喜欢
中国化肥信息(2022年5期)2022-08-30 01:58:04
清华金融评论(2022年4期)2022-04-13 21:33:11
名师在线·上旬刊(2021年3期)2021-09-10 04:20:48
消费导刊(2018年10期)2018-08-20 02:56:28
电子测试(2017年15期)2017-12-18 07:19:27
中国公路(2017年14期)2017-09-26 11:51:43
河南电力(2016年5期)2016-02-06 02:11:40
智能系统学报(2015年4期)2015-12-27 09:38:39
语文知识(2015年9期)2015-02-28 22:01:42
电子设计工程(2015年6期)2015-02-27 12:04:53
