
特征提取方法对朴素贝叶斯文本分类器的影响分析
2013-11-06 09:13迟庆云刘梦琳姜振凤枣庄学院信息科学与工程学院山东枣庄277160
长江大学学报(自科版) 2013年25期
迟庆云,刘梦琳,姜振凤,胡 华 (枣庄学院信息科学与工程学院,山东 枣庄 277160)
特征提取方法对朴素贝叶斯文本分类器的影响分析
迟庆云,刘梦琳,姜振凤,胡 华 (枣庄学院信息科学与工程学院,山东 枣庄 277160)
特征提取方法在文本分类过程中起着重要作用,文本分类的效果受特征提取方法选择的直接影响。采取信息增益和文档频率2种特征提取方法,对朴素贝叶斯分类模型的查全率和准确率进行验证比较。研究表明,朴素贝叶斯分类器的分类效果随着维数的增加先增加后减少;在维数一定时,信息增益(IG)的分类效果明显好于文档频率(DF)的分类效果。
文本分类;朴素贝叶斯文本分类;特征提取
文本分类能够改善文本信息杂乱的状况,其广泛应用于文本索引、文本信息过滤、自动元数据的产生、词意辨析、Web资源分类和应用程序中的文本管理等方面,其中朴素贝叶斯文本分类算法在垃圾邮件过滤、入侵检测等领域表现出较好的性能。此外,特征空间的高维性一直是文本分类的难题。在高维特征空间中,特征之间由于可能存在不相关性或者是冗余性,必然会出现过学习现象,导致时间与空间开销大。为了降低计算复杂度和提高分类准确率,必须降低特征空间维数,而特征提取是降低特征空间维数的较好的解决方法。下面,笔者分析了特征项提取方法对朴素贝叶斯文本分类器的影响。
1 贝叶斯分类算法
研究表明,贝叶斯分类算法能从各个方面进行考虑,其测试结果出错率较小[1]。计算机通过观察训练数据的特点,来猜测一个可能的分类规则,完成训练阶段的最终产品——分类器。训练过程一般花费时间比较长,系统将所有文本训练一次后,将假设训练语料包含N个文本D={D1,D2,…,Dn},上述文本分属于M个文本类别C={C1,C2,…,Cm},训练语料集共有L个文本特征词W={W1,W2,…,WL}。
当文本Di属于类别Cj时,则有P(Cj|Di)=1,否则P(Cj|Di)=0。如果给定文本类别变量,则文本类别Cj的先验概率估计为:

(1)
若用F(Wk,Di)表示特征词Wk在文本Di中出现的次数,则特征词Wk在类别Cj中的概率估计为:
任何文本都可视为一系列有序排列的特征词的集合,在贝叶斯分类器通过概率方法对数据如何生成制定了一个强有力的独立性假设,并得出类别Cj中产生文本Di的概率为:
(3)
根据测试文本特征数据计算测试文本属于每个类别的概率,然后按照最大概率对测试文本进行分类。测试文本Di属于类别Cj的概率:

(4)
文本向量通常采用向量空间模型进行描述。在向量空间模型中,如果不经过特征提取,不将非结构化的原始数据转化为可处理的结构化的形式,而是直接用分词算法和词频统计方法得到的特征项来表示文本向量中的各个维,那么所得到的向量维度将非常大。这种高维的文本向量必然使文本分类过程效率非常低下,不但给后续工作带来巨大计算开销,而且会降低分类算法的精确性[2]。因此,需要通过特征提取方法来降低特征空间维数,即使用某种算法从原始文本中抽取出的特征词进行量化来表示文本信息,用来描述和代替原文本,从而达到降低文本向量空间的目的。采取上述方法不但能选出能够很好反映文本内容的词,提高文本分类的效率,而且能降低系统的开销。
2 特征提取方法
在文本分类中,用于特征提取的方法主要包括文档频率、信息增益等。选择正确的特征提取方法对于对提高文本分类正确率有着十分重要的影响。
2.1文档频率
文档频率(DF)是指在整个数据集中有多少个文本包含某个单词。对于文档频率,通常会设定一个阈值。针对训练文本集中每个特征的文档频率,若该项的DF值小于阈值,表示该特征是稀有词,信息含量太少,没有代表性,应作为噪音加以删除;若其DF值大于某个阈值也应将其去除,因为其代表了“没有区分度”的极端情况。总之,在文本分类中使用文档频率进行特征提取具有操作简便、计算迅速的特点[3]。
2.2信息增益
信息增益(IG)是一种基于熵的评估方法,其计算公式如下:
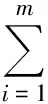
(5)

文档集中某个特征项对类的贡献越大,必然对类也越重要,那么它的信息增益值越大。在类分布和特征值分布高度不平衡的情况下,使用该方法的效果会大大降低,因为此时的函数值由不出现的特征决定,绝大多数类都是负类,绝大多数特征都不会出现。
3 朴素贝叶斯文本分类
3.1试验数据
试验语料库分为训练语料库和测试语料库2部分,从复旦大学中文语料库中下载,训练集由一组已经完成分类的文本组成,用来归纳各个类别的特性以构造分类器,分别为教育、医药、计算机、经济和环境。测试集用于测试分类器分类效果的文档的集合。
3.2文本预处理
针对训练语料库分词预处理部分,采用中科院计算所汉语词法分析系统(ICTCLAS)进行分词预处理、数据清洗和去除停用词[4]。ICTCLAS把训练语料库中的句子转换成词,对标点、助词、连词、介词、量词等进行清洗,并去掉文本中存在的助词、副词、连词、代词、介词、叹词、量词、数词等。
3.3特征项选择
特征选择模块包括词频统计和文本特征选择。词频统计是文本特征项权值计算的基础,其通过统计一定长度的语言材料计算每个词出现的次数并分析统计结果。文本特征选择模块采用信息增益(IG)和文档频率(DF)方法,从原始特征项中抽取一定数量的特征项,从而达到降维目的并形成特征项词典。在文档预处理后,将DF和IG特征选择后的前20个词取出进行分析。

表1 采用DF和IG特征提取方法提取的特征词
3.4试验结果分析
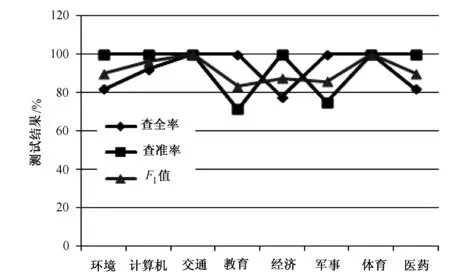
图1 特征提取的维数为3000维时朴素贝叶斯分类算法

从图1可以看出,“交通”和“体育”2个类别的查全率、查准率和F1值都为100%;“经济”的查全率为77.8%,相对较低;“教育”的查准率只有71.4%,是所有类别中最低的,这是由于这上述类别的训练文本和测试文本的相似度相对较低的缘故[6]。
测试文档提取1000维、2000维、3000维、4000维的试验结果如图2所示。

图2 测试文档提取1000维、2000维、3000维、 图3 不同方法提取特征时性能比较图
由图2可知,朴素分类器的分类效果随着维数的改变而改变,当文档特征值提取维数在3000维时,分类器的分类效果比较明显。在特征提取时采用信息增益(IG)和文档频率(DF)提取3000维的试验结果如图3所示。由图3可知,信息增益(IG)的分类效果明显好于文档频率(DF)的分类效果,这是因为DF所确定的值,即训练集合中单词发生的文本数在总体上是很小的,但在部分文本中出现的频率可能会很大[7]。
4 结 语
使用信息增益(IG)和文档频率(DF)2种特征提取方法,在去除停用词上,不单纯依据停用词表,而是利用词性标注进行数据清洗与停用词表相结合,进而达到降维的目的。研究结果表明,文档频率对文本的去停用词效果要求较高,因而采用该方法的分类效果较差,由于信息增益(IG)考虑了特征项未发现的情况,因而采用该方法可以取得较好的特征选择效果。
[1]Sebastian F.Machine learning in automated text categorization [J].ACM Computing Surveys, 2002, 34(1):1-47.
[2]夏克俭,张涛.基于贝叶斯算法的垃圾邮件过滤的研究[J].微计算机信息,2008,24(3):179-180.
[3]钟慰,周铁军.朴素贝叶斯分类在入侵检测中的应用[J].计算机与信息技术,2007(12):24-27.
[4]余芳.一个基于朴素贝叶斯方法的web文本分类系统:web CAT[D].广州:暨南大学,2004.
[5]王俊英.基于科技文献的中文文本分类算法研究[D].秦皇岛:燕山大学,2005.
[6]杨霞,黄陈英.文本挖掘综述[J].科技信息,2009,10(3):5-14.
[7]复旦大学语料库.中文自然语言处理开放平台[DB/OL].http://ishare.iask. sina.com.cn.ht,2008-09-12 .
[编辑] 李启栋
TP393.08
A
1673-1409(2013)25-0091-03
2013-06-12
迟庆云(1975-),女,硕士,讲师,现主要从事数据仓库、数据挖掘方面的教学与研究工作。
猜你喜欢
电子制作(2019年15期)2019-08-27
电子制作(2018年19期)2018-11-14
计算机应用(2017年4期)2017-06-27
自动化学报(2017年11期)2017-04-04
光学精密工程(2016年4期)2016-11-07
光学精密工程(2016年3期)2016-11-07
铁道通信信号(2016年6期)2016-06-01
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
电子器件(2015年5期)2015-12-29
噪声与振动控制(2015年4期)2015-01-01
