
基于难度系数的加权关联规则在试卷评估中的应用
2013-10-26 01:51陈世保吴国凤
井冈山大学学报(自然科学版) 2013年1期
陈世保,徐 峰,吴国凤
基于难度系数的加权关联规则在试卷评估中的应用
*陈世保1,徐 峰1,吴国凤2
(1.安徽财贸职业学院,安徽,合肥 230601;2.合肥工业大学,安徽,合肥 230009)
针对传统的关联规则在试卷评估中应用出现的问题:由于试题的难易程度不同,被答对的概率也不一样,即数据集中数据项发生的概率不一样,数据项具有倾斜支持度分布的特征,选择合适的支持度阈值挖掘这样的数据集相当棘手。文章提出了基于试题难度系数加权的关联规则挖掘算法,从而解决因试题难度不同而导致数据项出现的概率不均的问题,发现更多有趣的关联规则,并且理论上证明了基于难度系数的加权关联规则算法保持频繁项集向下封闭的重要特性。
Apriori算法;试卷评估;加权关联规则;数据挖掘;难度系数
1 问题提出的背景
数据挖掘是指从大量的数据中发现人们事先不知道的、有用的知识(模式)的处理过程,它是继数据库、人工智能等领域之后发展起来的一门重要学科[1],是目前国际上数据库和信息决策领域比较前沿的研究方向。关联规则挖掘是数据挖掘重要的研究分支,Agrawal等人[2]于1993年首次提出关联规则挖掘后,引起了国际上广泛的关注,文献[3]首次提出了经典的Apriori算法,并成功应用到商业中。

在试卷评估中更是如此,由于试题的难易程度不同,因此试题被答对的概率也不一样,即试卷的事务数据库中数据项出现的频率不一样:难度大的试题在数据库中出现的概率低,即具有较低的支持度;难度小的试题在数据库中出现的概率高,即具有较高的支持度。根据试卷评估中数据项出现的概率和试题的难易程度有关,故提出基于难度系数的加权关联规则挖掘算法,以解决此问题。
2 试卷评估中的关联规则形式化描述
由于关联规则挖掘算法针对的是事务数据库,因此需对学生作答的试卷进行转换,转换成事务数据库。


表1 学生试卷事务数据库

在给定的数据库D中,关联规则挖掘就是产生支持度和置信度分别大于用户给定的最小支持度(minsup) 和最小置信度(minconf) 的关联规则。例如,在某门课程试卷得分情况的数据库中,1000个学生中有600个学生答对第10题、第20题,而这600个学生中又有360个学生答对了第1题,则规则对答对第10题、第20题的学生同时又答对第1题的的支持度supp=360/1000=0.36(答对第10题、第20题和第1题360人占总人数的比例),置信度conf=360/600=0.6(答对第10题、第20题和第1题360人占答对第10题、第20题600人的比例)。
3 基于难度系数的加权关联规则
Apriori算法[5]是最经典的关联规则算法,Apriori算法是一种宽度优先算法,采用逐层搜索的迭代方法[5],其基本思想是重复扫描数据库。首先,产生频繁1-项集L1,然后是频繁2-项集L2,直到有某个日r值使得Lr为空,算法停止。这里在第k次循环中,先产生侯选k-项集的集合Ck,Ck中的每一个项集是对两个只有一个项不同的属于L(k-1)的频繁集做一个(k-2)连接来产生的。Ck中的项集是用来产生频繁集的候选集,最后的频繁集Lk必须是Ck的一个子集。如果Ck中某个候选集有一个(k-1)子集不属于L(k-1),则这个项集可以被修剪掉不予考虑,这是基于算法的频繁项集向下封闭的性质:一个项集是频繁的当且仅当它所有子集都是频繁的[6]。
目前很多学者都在研究加权关联规则算法[7],加权关联规则算法在关联规则的挖掘过程中考虑了人们对项目的兴趣(权值)。权值的赋予具有很大的主观随意性,很难把握;另一方面,由于权值的引入,破坏了频繁项集的封闭性,即频繁项集的任一子集不一定是频繁的,因此不能再利用该性质进行候选项集的剪枝。
本文引入基于难度系数的加权规则算法能有效解决由于试题难度不一而导致的数据项分布不均的问题,同时也不破坏关联规则算法的频繁项集的封闭性[8]。下面给出算法的相关定义:
定义1 难度系数也可以理解成“容易度系数”,是0~1之间的量值,难度系数越大,说明题目难度越小。难度系数一般分整卷难度系数和单题难度系数。文章中主要指单题难度系数,记作Pi。
Pi(第i题难度系数)=Ai(第i题平均得分)/Ti(第i题满分)
定义2 项目属性ij的权是与项目难度系数有关的权,记作:W(ij)。在本文中被定义为试卷的逻辑事务数据库D中该试题难度系数的倒数。
W(ij)=1/Pj
那么试题难度越大Pj越小,则W(ij)的值越大,也就是权重越大。
定义3 数据项集I的权是数据项集I中所有项目权值得均值。记作:W(I)
定义4 交易事务t的权重是指数据集D中某一条记录的权值,记作:W(tk),是所有属于tk的项目权值的均值。

该定理也说明了基于难度系数加权的关联规则算法保持了Apriori算法的向下封闭性,非频繁项集的超集也是非频繁的。
4 算法描述
基于难度系数加权的关联规则算法和Apriori算法很类似,都是首先根据指定的最小支持度(minsup)找出数据集D中所有的频繁项目集。然后根据第一步挖掘出的频繁项目集和指定的最小置信度(minconf)产生强关联规则。
算法的伪码如下:
1) W(ij)=scan(D) //扫描数据库D,根据定义1获得项目ij的权值。
2) L1= find_frequent_1_itemsets(D) //产生频繁1-项集
3) for (k = 2; L(k-1)≠ ∅; k++) {
4) Ck= aproiri_gen(L(k-1),min_sup)
5) for each transaction t∈D{
6) for each transaction t∈D{
7) Ct= subset(Ck,t)
8) for each candidate c∈Ct
9) c.wsp+=w(t) }
10) Lk={c∈Ck| c.wsp/w(D) ≥ min_sup}
11) return L = ∪Lk;
算法首先扫描数据库scan(D),根据定义1和定义2计算出各项的权值;然后算法步骤2再次扫描数据库产生频繁1-项集find_frequent_1_itemsets(D):根据定义3和定义4计算出事务的权值w(tk),整个数据库D的所有事务的权值W(D),项目的加权支持度,并根据用户给定的最小支持度(minsup)获得频繁1-项集L1; aproiri_gen函数对L(K-1)频繁项集进行联合、剪枝,得到K-候选项集Ck,aproiri_gen函数的实现与Apriori算法中的一样,在此不再赘述。
本算法比Apriori算法增加了一次扫描数据库的过程,目的是得到数据项的权值、事务的权值。
5 加权算法在试卷评估中的挖掘过程
根据试卷转化成事务数据库的规则,结合事务和项集的权值的概念,对试卷进行转化,如表2和表3。然后将基于难度系数的加权关联规则应用到该数据库中,充分理解该算法在试卷评估中的挖掘过程。

表2 数据库的事务记录

表3 数据库的项目的权
假定最小支持度minsup = 0.2,同时基于难度系数的加权最小支持度min-wsp = 0.2。由表2和表3看出使用难度系数加权的关联规则能够挖掘出包含低支持度项的模式,能够发现更多的有趣的关联规则。例如:表2中{I2,I3,I6}项集的支持度sup = 1/6<0.2,根据传统的关联规则,{I2,I3,I6}不是频繁项集;而根据难度系数加权的关联规则{I2,I3,I6}的加权支持度为min-wsp=3.5/12=0.291>0.2,{I2,I3,I6}是频繁项集。这说明试卷中的I6的试题难度很大,答对的人少,若是传统的关联规则将会丢失包含I6试题的有趣的规则,而使用基于难度系数加权的关联规则可以挖掘出来,克服了传统的关联规则在试卷评估应用的缺陷。
6 算法评估
为了证实基于难度系数的加权关联规则挖掘算法的改进效果,对基于难度系数的加权关联规则挖掘算法进行了测试。数据来源于我校2010年《会计基础》课程中的数据,将1000人的答题情况转换为布尔型事务数据库,然后分别用Apriori算法、一种改进的加权关联规则算法[9]和基于难度系数的加权关联规则挖掘算法进行挖掘做出对比。如图1和图2:

图1 算法挖掘效率比较
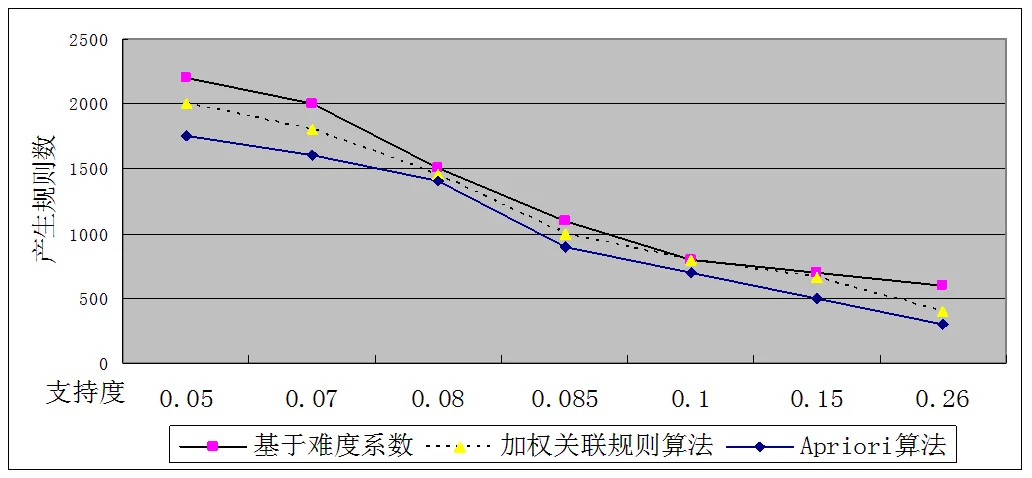
图2 算法产生的规则数比较
从图1和图2中可以看出:1)由于采用了难度系数的加权之后,提升了难度较大试题的支持度,同时降低了难度较低试题的支持度,使各个项目的加权支持度趋向于平均,因此可以挖掘出了更多的规则;2)在试卷评估中使用难度系数确定权值是比较合理和理想的;3)由于基于难度系数加权的关联规则算法仍然保持向下封闭性,因此本文中的算法和文献[10]加权关联规则算法基本保持一致,但是总体比Apriori算法性能优越。
7 结论
试卷评估是学校教学中的重要环节,要充分利用试卷中的信息,挖掘出有意义、有价值的信息,为教师有针对性地调整教学计划,调整教学策略以及改进教学方法提供科学依据,提高教学质量。根据试卷质量符合正态分布的特性,转换后的事务数据库具有倾斜支持度分布的特征,采用Apriori算法进行挖掘将会丢失很多有价值的信息。文章采用基于难度系数的加权关联规则能够很好的解决这个问题,挖掘出更多的有趣的关联规则,为教学提供更多的有意义的信息,为教师和相关部门决策提供理论依据。
[1] Han J, KamberM.数据挖掘:概念与技术[M].范明,孟小峰译.北京:机械工业出版社,2001.
[2] Agrawal R, Imielinski T, Swami A N. Mining association rules between sets of items in large databases[C]. ACM SIGMOD, 1993:207-216.
[3] Fayyad U M,Smyth P. Advances in Knowledge Discovery and Data Mining[M].NewYork:MIT Press,1996.
[4] 詹芹,张幼明.一种改进的动态遗传Apriori挖掘算法[J].计算机应用研究,2010,27(8) :2929-2930,2935.
[5] Tan Pangning,Steinbach M, Kumar V. Introduction to Data Mining[M]. 北京: 人民邮电出版社,2006.
[6] 李刚,董祥军.多支持度惯量规则的研究[J].广西轻工业,2007,10(5):60-62.
[7] 欧阳为民,郑诚,蔡庆生.数据库中加权规则的发现[J].软件学报,2001,12(1):612-619.
[8] 尹群,王丽珍,田启明.一种基于概率的加权关联规则挖掘算法[J].计算机应用,2005,2(4):805-807.
[9] 陈世保,吴国凤.一种改进的Apriori算法在试卷评估中的应用研究[J]. 井冈山大学学报:自然科学版,2012,4(2): 58-62.
[10] 李成军,杨天奇.一种改进的加权关联规则挖掘方法[J].计算机工程,2010,36(7):55-57.
WEIGHTED ASSOCIATION RULES BASED ON THE COEFFICIENT OF DIFFICULTY IN THE ASSESSMENT OF PAPERS
*CHEN Shi-bao1,XU Feng1,WU Guo-feng2
(1. Anhui Finance & Trade Vocational College, Hefei, Anhui 230601; 2. HeFei University of Technology, Hefei, Anhui 230009, China)
With the wide range of data mining applications, the association rule mining algorithm is applied to the paper assessment in the literature. Traditional association rule data mining problems in the papers assessment, such as the degree of difficulty of questions is different, the probability of being correct answers are not the same, that is to say, the data set is not the same as the probability of data entry, data entry with a sloping support the distribution of the characteristics of mining such data sets is very difficult to select the appropriate support threshold. We present the association rules mining algorithm based on item difficulty coefficient weighted to solve the problem of uneven frequency of data items appear different item difficulty and find more interesting association rules. Furthermore, we prove theoretically that the weighted association rules based on the coefficient of difficulty to maintain the important features of the frequent item sets is downward closed.
Apriori algorithm; evaluation; association rule; data mining; difficulty coefficient
TP274
A
10.3969/j.issn.1674-8085.2013.01.015
1674-8085(2013)01-0070-05
2012-06-12;
2012-07-28
安徽省高等学校重点教学研究项目(20101766)
*陈世保(1981-),男,安徽合肥人,工程师,硕士,主要从事数据库技术,数据库应用研究(E-mail: chenshibao@189.cn);
徐 峰(1967-),男,安徽合肥人,正高级工程师,硕士,主要从事软件工程、计算机网络研究(E-mail:xuf@163.com);
吴国凤(1954-),女,安徽合肥人,合肥工业大学副教授,硕士生导师,主要从事计算机网络技术、网络安全研究(E-mail:wgf@126.com ).
猜你喜欢
成都信息工程大学学报(2022年3期)2022-07-21
计算机与数字工程(2021年6期)2021-06-29
沈阳师范大学学报(教育科学版)(2021年2期)2021-02-01
计算机与生活(2019年11期)2019-11-12
科技与创新(2019年14期)2019-08-12
江苏通信(2018年4期)2018-12-04
计算机与数字工程(2018年10期)2018-10-23
天津科技大学学报(2018年4期)2018-08-22
自动化学报(2017年7期)2017-04-18
计算机工程与设计(2011年7期)2011-09-07
