
系统资源受限环境下的证书解析方法研究
2013-10-10 01:57:08邵奇峰龚雪容吴保中
单片机与嵌入式系统应用 2013年6期
邵奇峰,龚雪容,吴保中
(解放军信息工程大学,郑州450005)
引 言
随着信息技术的发展,基于数字证书的安全服务得到越来越广泛的应用。证书解析是数字证书应用的基础,用于获取证书中各字段的信息。目前已知的证书解析方法有 Microsoft 的 CryptoApi[1]和.net[2]、开 源 的 OpenSSL[3-4]等,均是在操作系统应用层实现的,且 CryptoApi和.net只能在 Windows平台中使用。内核层解析时,一般是将证书传递到应用层进行解析后再将结果送回,给证书验证和应用带来很大不便。尽管OpenSSL的证书解析方法具有较强的通用性,而且开源,但代码复杂,占用系统资源较多,不适用于操作系统内核层及嵌入式系统等资源受限环境。本文在证书格式研究的基础上,给出了一种适用于资源受限环境下证书解析的方法,并在 Windows和Linux内核层以及多款嵌入式设备中得到了应用。
1 数字证书格式
目前广泛应用的数字证书格式为X509v3[5],其基本内容包括基本证书域、签名算法域和签名值域三部分,如图1所示,其中基本证书域又包括版本号、序列号等子域。
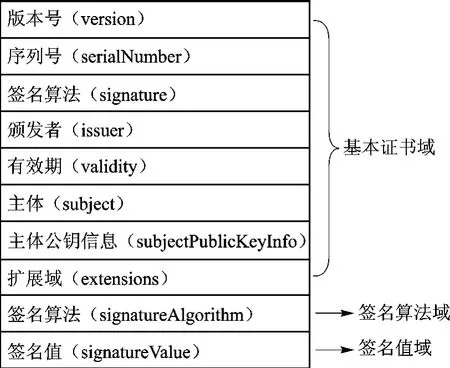
图1 X509v3格式数字证书基本内容
数字证书的格式用ASN.1语法进行描述:


2 数字证书解析方法
数字证书在颁发时采用了非典型编码规则(DER),该编码规则是基本编码规则(BER)的一个子集,ASN.1值与DER编码之间为一一对应关系[6]。DER编码由TLV组成,即Tag、Length和Value,其中Tag为数据类型标签,Length为数值的字节长度,Value是值。如果进行通用化解析,即在事先不知道内容格式的情况下解析出每个字段的类型、长度、值,则需要考虑ASN.1语法的各种情况,代码复杂,占用资源多且处理难度大。在Windows和Linux内核层以及嵌入式设备等资源环境有限的情况下实现难度大且不必要。
在数字证书内容格式已知的前提下,证书解析的关键就在于如何确定各字段的层次关系以及同层各域的次序,进而快速定位各字段位置。因此,在资源受限环境下Tag字段可忽略,重点在于确定Length和Value字段的位置和值。
证书字段可分为两类:次序固定字段和次序不固定字段。基本证书域中的扩展字段为次序不固定字段,其余字段均为次序固定字段,尽管基本证书域中的扩展字段为次序不固定字段,但扩展字段的集合在整个证书中的次序仍是固定的,即在AlgorithmIdentifier之前,在SubjectPublicKeylnfo之后。
在证书解析时,无论是次序固定字段还是次序不固定字段,都必须先定位字段位置。
首先,确定字段所处的包裹层次。X509v3数字证书的层次关系如图2所示,最外层是Certificate::=SEQUENCE{…},第 2层 是tbsCertificate、signatureAlgorithm和signature,第3层为version、serialNumber等。扩展字段所处层次较多,从第3层到第5层都有,但有用信息在第5层,故在解析时要跳过第3和第4两层。
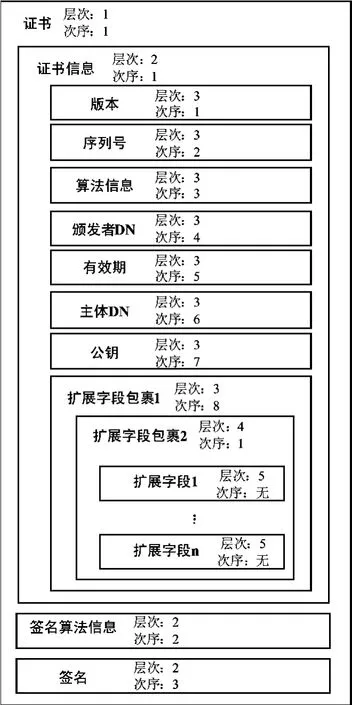
图2 证书层次关系图
其次,在相应层次确定该字段的位置。在X509v3格式数字证书中,同一层次的字段位置相对固定,因此在确定字段所处的层次位置后即可根据相对位置确定字段的最终位置。在字段位置确定后,次序固定字段在定位后可直接取该字段的值;次序不固定字段则需要获取字段的OID进行逐个比对,直至找到为止。
以DN字段为例:首先,确定其所在的层次是第3层;然后,在第3层中根据相对关系可知DN字段在版本字段之后;从而最终定位DN字段在整个证书中的位置,获取其值。
3 解析模块实现
前面描述了数字证书中各字段的包裹关系及数字证书的解析方法,为在资源受限环境下快速定位数字证书中各字段位置,高效地解析证书,在数字证书解析模块中定义了如下数据结构TLV。其中tag表示标签,暂时不用;length表示pValue指向的数据长度;selfLen表示TLV头的长度。

同时设计了ReadTLV、WalkCert、SearchExtField等函数。函数ReadTLV用于从二进制数据流中获取TLV信息。WalkCert函数根据层次和次序关系调用ReadTLV进行解析,跳过不必要的数据,定位所需字段的位置。对于扩展字段,还需要通过SearchExtField进行字段搜索,扩展字段搜索采用OID比对方式进行。在资源受限环境下数字证书解析的关键是证书中各字段的定位,下面给出WalkCert的定位方法:


定位到证书中各字段位置后,即可根据字段的定义类型进行相应的处理。在实现Windows和Linux内核层的证书解析时,还应考虑以下几个方面的问题[7]:
① 部分C库中的函数在内核中不能使用。如内存分配函数malloc需要根据平台使用不同的函数,Windows平台下使用ExAllocatePoolWithTag,Linux平台下使用kmalloc。
② 缺乏像用户空间一样的保护机制。内核可以发现应用层程序非法访问内存,但如果内核层程序发生内存错误,就会导致系统崩溃。
③ 内核层程序可使用的堆栈很小,不能在函数中使用大数组。
④内核层的程序执行效率要高,避免长时间占用CPU资源。
⑤要注意同步和竞争,避免发生死锁,函数要可重入。
上面所述的方法同样适用于证书撤销列表(CRL)的解析。图3给出了CRL的层次关系。
4 应用情况及测试
本文描述的方法已在Windows和Linux内核层、W78E58、TMS320C5416等环境中得到了应用。由于证书解析是纯软件的执行过程,与CPU的外围电路无关,并且采用C语言实现,移植简单,因此下文不再描述硬件电路和上文已描述过的实现过程,仅就不同环境中实现时的注意事项进行说明。
(1)Windows内核层
读取证书文件时要使用InitializeObjectAttributes、ZwCreateFile、ZwReadFile、ZwClose等函数。获取证书中的时间时需要考虑时区本地化处理,转换时要使用Rtl-TimeFieldsToTime、ExSystemTimeToLocalTime、RtlTimeToTimeFields等函数。C标准库中sprintf使用Rtl-StringCbPrintfA替换。动态内存分配使用ExAllocate-PoolWithTag,释放使用ExFreePool。另外,还要加入unicode和gb2312编码的转换数组。
在WDK.6001.18002环境下编译为内核动态链接库。方式是,在普通内核模块实现基础上增加DllInitial-ize、DllUnload两个函数,均直接返回成功即可,将需要导出的函数声明为extern。
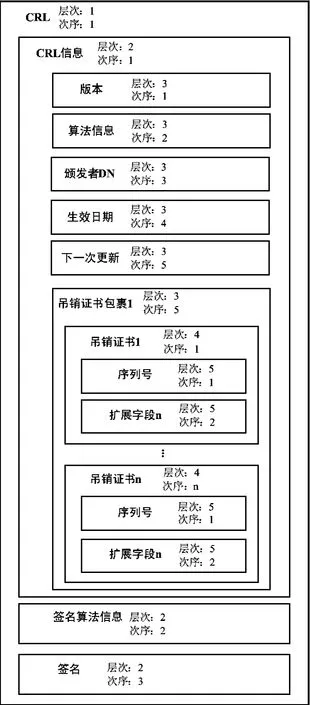
图3 CRL层次关系图
(2)Linux内核层
读取证书文件时使用filp_open打开文件,get_fs、set_fs(KERNEL_DS)、vfs_read读取文件,filp_close关闭文件。内核中没有相应的时间转换函数,需要参考应用层的代码自行实现。C标准库中的sprintf可直接使用。动态内存分配和释放分别使用kmalloc(xx,GFP_KERNEL)、kfree,另外还要加入unicode和gb2312编码的转换数组。
编译方式同普通内核模块,用insmod命令加载模块。
(3)W78E58和TMS320C5416
在W78E58和TMS320C5416环境下,不支持动态内存管理,证书从外部存储器读入内存中的全局数组中,运行时各函数使用指针参数传递证书数据,不复制缓冲区。临时数据可使用堆栈保存,本方法的堆栈使用量不超过512字节。时间转换参考Linux应用层代码自行实现,在没有硬件时钟的环境下该转换不需要。若设备上不需要显示证书名称,则unicode编码转换数组也可以省去,以节省空间。
分别在Keil和CCS环境下编译通过。由于是软件方法,可以直接在两种环境中进行模拟测试。
常见的应用层证书解析方法不适用于资源受限环境,无法和本文方法直接比较。此外,证书解析不是一种频繁的操作,性能不是重要的考核指标。基于上述考虑,表1仅给出了本方法在不同环境下的编译代码量和解析公钥时的平均运行时间(代码数约1500行)。
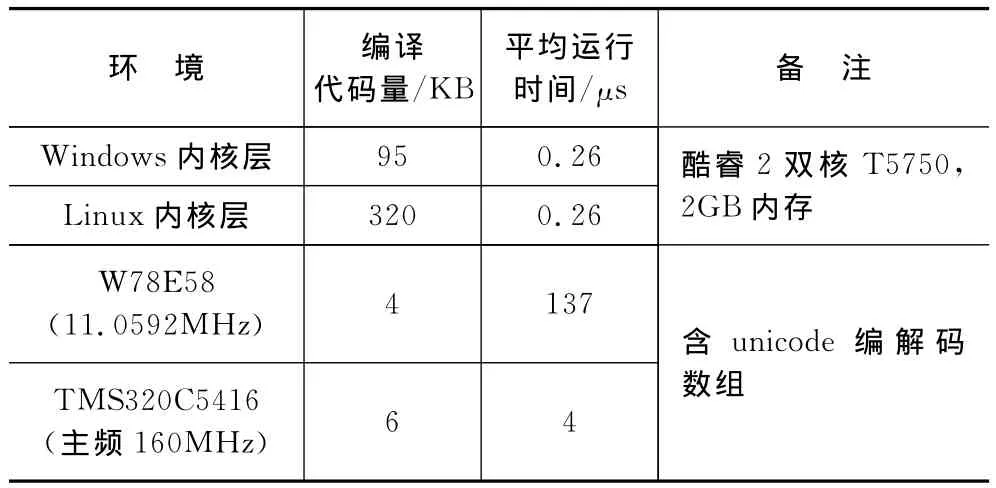
表1 编译代码量和平均运行时间
结 语
本文所描述的数字证书解析方法可方便地利用C语言实现,在Windows和Linux内核层以及嵌入式系统中具有广泛的适应性,已在Windows和Linux内核层、8051单片机、TMS320C5416等多个环境中应用,具备运行稳定、代码量小、解析速度快等特点,对开发人员有一定的参考价值。
[1]Cryptography Functions[CP/OL].[2013-01].http://msdn.microsoft.com.
[2]X509Certificate类 [CP/OL].[2013-01].http://msdn.microsof-t.com.
[3]OpenSS 源 码 [CP/OL].[2013-01].http://www.openssl.org.
[4]谭晓青.利用OpenSSL建立PKI数字证书系统[J].科学技术与工程,2005(20):1552-1554.
[5]IETF.RFC3280Internet X509Public Key Infrastructure Certificate and Certificate Revocation List(CRL)rofile[DB/OL].(2002-04)[2013-01].http://w-ww.ietf.org.
[6]GB/T 16263.1-2006信息技术 ASN.1编码规则第1部分:基本编码规则(BER)、正则编码规则(CER)和非典型编码规则(DER)规范[S].
[7]谭文,杨潇,邵坚磊.寒江独钓:Windows内核安全编程[M].北京:电子工业出版社,2009.
猜你喜欢
历史教学问题(2023年6期)2024-01-18 08:45:06
江苏科技信息(2022年16期)2022-07-17 09:07:36
小天使·六年级语数英综合(2017年8期)2017-08-04 00:44:51
网络安全和信息化(2016年8期)2016-11-26 06:42:52
网络空间安全(2016年3期)2016-06-15 20:27:08
电脑迷(2015年7期)2015-05-30 04:50:35
图书馆建设(2015年10期)2015-02-13 03:48:27
小天使·五年级语数英综合(2014年11期)2014-11-06 09:49:03
新世纪图书馆(2014年7期)2014-09-19 12:20:40
吉林金融研究(2014年2期)2014-04-17 00:04:38
