
多核系统的小波包并行算法及其在电力系统数据压缩中的应用
2013-10-10 07:22鲁晓帆刘志刚
电力自动化设备 2013年5期
鲁晓帆,刘志刚,吴 峰
(西南交通大学 电气工程学院,四川 成都 610031)
0 引言
基于小波变换的小波包变换,不仅在时频域都具有良好的局部化性质,而且对信号的高频部分提供了更精细的分解,从而得到大量高频信息[1-3]。小波包变换在电力系统多方面的应用都有明显的优势,例如在数据压缩领域,小波包变换可以针对电力系统故障录波信号中蕴含丰富暂态特征信号的特点,将故障信号分解成各个频带的信息,选择有重要信息的频带采用各种压缩算法进行压缩。近些年,在小波包算法基础之上,又提出了与嵌入式零数编码相结合[4]、与快速傅里叶变换相结合[5]、混合小波包[6]等各种提高压缩精度的压缩算法。这些算法虽然在一定程度上使压缩性能得到提升,但却增加了算法复杂度。随着电力系统数据记录装置的飞速发展、电力系统高采样的逐步演变、滤波装置的不断更新,电力系统电能质量数据逐渐呈现海量化趋势,传输、存储等环节对实时性的要求又进一步提高,因此,电力系统数据压缩效率问题得到越来越多的关注。以上各种压缩算法所基于的小波包变换,其核心部分的卷积运算过程复杂、运算量大、实时性差,严重阻碍了其在实际工程中的应用。为了提高小波包变换的计算速度,解决目前电力系统海量数据的压缩效率问题,本文提出将小波包变换并行化处理。
目前,针对这一问题,国内外学者提出利用各种并行技术来加快小波包变换的运算速度[7-13],大部分文献都是利用多机网络环境进行并行化处理,该方法不可避免地受到系统维护及网络传输环节所带来的不利影响。随着计算机的发展,单机多核处理器应用越来越广泛,因此基于多核技术的并行小波包研究具有十分重要的意义。
本文利用 Pthreads[14]和 OpenMP[15-17]2 种并行编程环境,针对提高小波运算速度问题,提出小波包Mallat分解重构算法不同的并行策略。在Pthreads环境下,提出小波包分解过程数据级并行、重构过程任务级并行;在OpenMP环境下,分别提出小波包分解重构特征嵌套和非嵌套并行策略。并利用C语言在单机双核处理器平台上进行了海量数据压缩实验研究,取得了明显的效果,为解决电力系统数据压缩效率问题提供一种新的方法。
1 小波包Mallat算法并行性分析
小波包是小波概念的推广。它是在小波变换(V0=V1⊕W1=V2⊕W2⊕W1=…)只将 V(尺度)空间进行分解的基础上,进一步对Wj(小波空间)进行分解,使正交小波变换中随j的增大而变宽的频谱窗口进一步变细,达到最适合于待分析信号的时频窗口或最优基[18]。其分解过程如图1所示,图中h0与h1分别表示小波包分解后的高频系数与低频系数,a表示尺度空间数据,d表示小波空间数据。
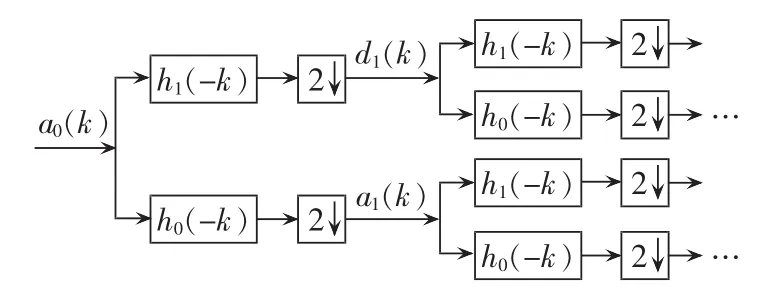
图1 小波包Mallat分解原理Fig.1 Principle of Mallat decomposition of wavelet packet
小波包分解重构过程的核心是滤波器与待处理数据的卷积过程。从卷积计算的公式可以了解到,卷积计算结果与待处理数据序列直接相关,不同位置的待处理数据与滤波器的卷积过程得到不同的卷积结果。因此不同位置的卷积结果之间并没有相关性,可以将待处理数据进行分配并行卷积。
小波包Mallat重构原理如图2所示,图中g表示由小波空间数据与尺度空间数据重构后得到的上一层的重构数据。可以看出,小波包变换中对尺度空间和小波空间的处理也不存在关联性,该部分同样可以作为并行任务执行。
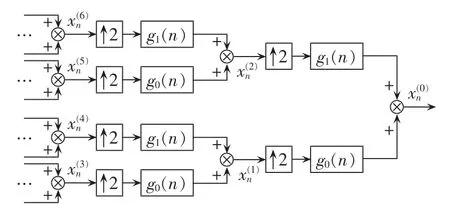
图2 小波包Mallat重构原理Fig.2 Principle of Mallat reconstruction of wavelet packet
2 基于Pthreads与OpenMP的并行小波包实现
2.1 Pthreads与OpenMP
Pthreads是Linux操作系统的多线程接口标准,在Windows操作系统上,可以利用Pthreads-win32开放源代码版本实现并行编程。与Pthreads库不同,OpenMP是通过采用指导语句、库函数调用和环境变量来给用户提供在共享存储计算机上创建和管理可移植并行程序的方法。它是一个在多处理机上用以编写可移植的多线程应用程序的API库,采用Fork-Join并行模式。
2.2 基于Pthreads的并行小波包实现
小波包对信号数据处理的流程,需要经过数据加载、延拓、分解、二抽取、二插值、重构这一过程。利用Pthreads实现分解过程数据级并行分解、重构过程任务级重构。其中,延拓、二抽取与二插值的过程与分解、重构过程融合为同一个流程。
a.数据延拓。为了执行数据延拓,将每组与后一组重复NFilter-1个数据,其中NFilter是滤波器系数个数,本文采取周期延拓,最后一组与第1组数据重复前NFilter-1个数据,假设有p个线程参与执行并行计算,则每组有N/p+NFilter-1个数,N为原始数据个数,卷积时滤波器第1位只对应每组前N/p个数进行计算。
b.数据级并行分解。由于小波包分解时各数据序列之间没有相关性,可以将各个数据分配给各个线程同时执行。为保证各个执行线程负载平衡,本文根据小波包分解层数将近似系数与细节系数的数据分别分为N/p组,每层N的大小为上一层的1/2,数据分组如图3所示。
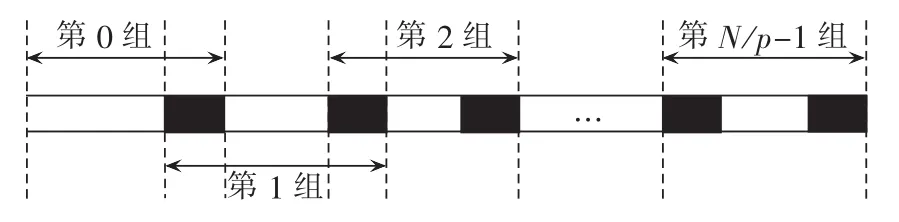
图3 数据分组Fig.3 Data grouping
将分解的前q组数据分给q个线程,每个线程同时执行分解过程,待线程挂起后,主线程继续向这些子线程派发新的q组数据。分解一层后,先对近似系数进行分组并行分解,再对细节系数分组执行。此时需要注意的是,由于延拓方式的影响,对应于每一层中近似与细节系数的延拓值将会不同,因此在分组完成后先要计算此次延拓后的余值项,再采用新的余值进行延拓与卷积计算。
c.二抽取。为了减少小波包变换计算时间,可以将分解中二抽取过程与分解过程相结合[20],即不再计算所有数据,而是选择奇数位数据计算,偶数位数据直接跳过。图4采用滤波器系数为4说明此过程。图中当数据延拓分组后,不同的线程针对本组数据进行卷积计算时,每个线程执行第1、3、5、…位为首的运算。
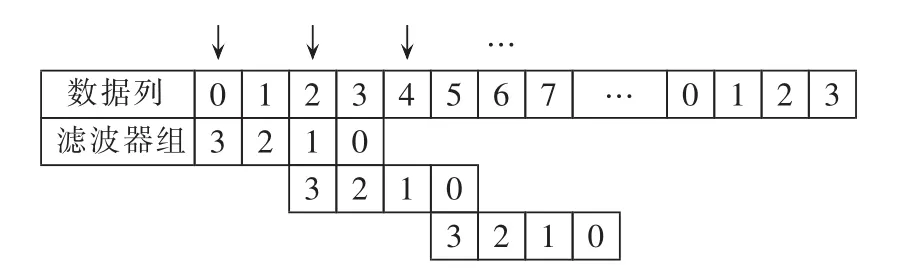
图4 数据二抽取分解原理Fig.4 Principle of second extraction decomposition
图5为小波包Pthreads并行分解流程,图中Ti为不同的线程,di为不同组的数据,主线程完成数据载入与延拓后,将数据分组,分出一组数据后创建一个线程执行该组的分解运算,完成近似系数的分解,接着继续分解第i层细节系数,直到所有系数分解完成。
由于数据回存需用到上一步线程的结果,并且是在同一堆栈中进行读写,为了保证数据回存的正确性,各线程完成卷积计算以后,需在分解数据回存之前与主线程合并,主线程完成分组后在此等待,创建的线程得到释放。
d.二插值与任务级重构。重构的过程中可以发现,每一层对应的近似系数和细节系数个数是相同的,并且不同的系数与不同的滤波器进行运算,不同类型系数之间没有相关性,读取数据实现卷积的过程就不会出现同步的问题,因此可以将近似系数和细节系数重构的过程看成是不同的任务,实现任务分解方式及任务大小相同,这也满足负载平衡要求。
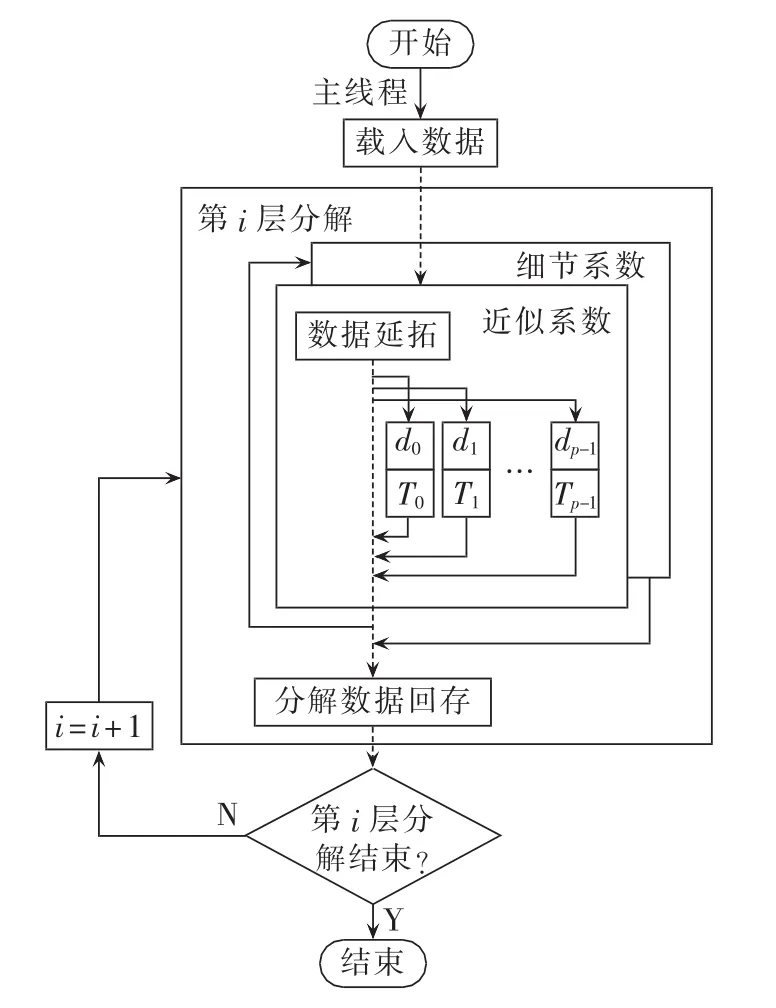
图5 小波包Pthreads并行分解Fig.5 Parallel wavelet packet decomposition on Pthreads
小波包重构并行过程,先根据每一层循环与分解层数的关系,计算数据延拓后的系数值,二插值时不进行补零操作,而是在非补零位置计算待处理数据与滤波器奇数位的系数卷积,补零位置计算待处理数据与滤波器偶数位的系数卷积。而整个过程中尺度空间与小波空间同时进行重构运算,其任务级并行重构流程如图6所示。
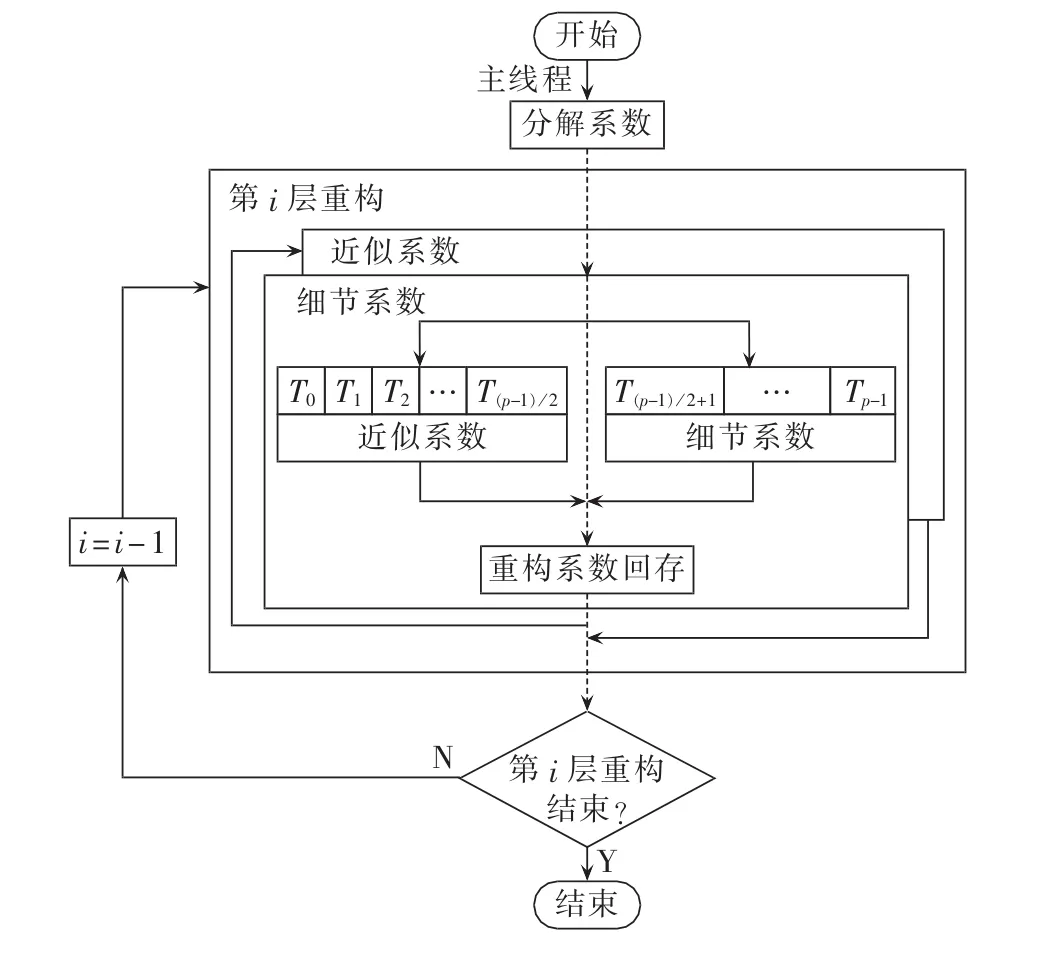
图6 小波包Pthreads并行重构Fig.6 Parallel wavelet packet reconstruction on Pthreads
2.3 基于OpenMP的并行小波包实现
OpenMP标准可以直接在串行程序的基础上调整程序的并行性,因此利用OpenMP实现小波包并行必须首先编写小波包分解的串行程序,本文在Visual studio 2008平台上利用C语言完成串行编程。OpenMP最显著的用处在于,可以将小波包for循环分配到不同处理器上同时执行,即根据处理器的个数p将循环次数分为p组,每组循环由一个线程执行,这样由p个线程同时完成不同次循环体中卷积、二抽取计算,如图7所示。
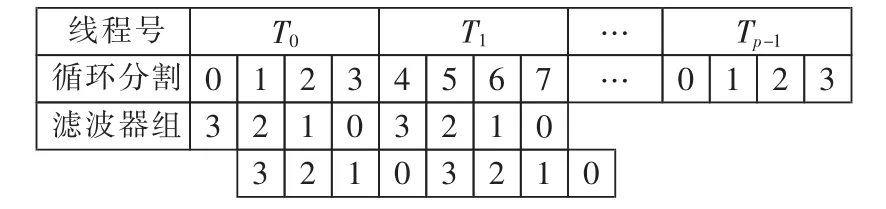
图7 OpenMP并行卷积过程Fig.7 Process of parallel convolution on OpenMP
小波包分解串行程序核心部分是一个嵌套循环过程。嵌套循环的含义是把小波包分解层次与计算低频、高频系数的次数相联系。为处理边界问题,对边界进行周期延拓,共享数据作为私有副本分配给各个线程。根据图2,假设分解n层(n≥1),外层循环需要进行2n-1次。假设外层分解至第j(j=0,1,2,…,2n-2)次,内层循环则从 jN/(2n-1)开始至(j+1)N/(2n-1)次结束。
a.嵌套方案。在OpenMP内,嵌套是一个默认不使能的布尔属性。当并行区域嵌套出现在线程已经运行在并行区域又遇到另一个并行区域时,若嵌套使能,那么程序就会按照之前动态线程的规则生产一个新的线程组。可以通过omp_set_nested(i)来设置嵌套使能状态,i=0表示嵌套未使能,i=1表示嵌套使能。
小波包分解过程利用嵌套使能并行执行嵌套循环。当主线程遇到外层循环时,派生出一组线程,这些线程同时继续向内层循环执行下一层并行,这时派生出的线程和原来的主线程成为针对内存循环的主线程,继续按照之前的方式派生新的线程从而并行执行内层循环,当内层循环执行结束时,这些线程逐级挂起,最终回到最初的主线程上。嵌套循环并行执行线程运行过程如图8所示,m为实际计算机核数。
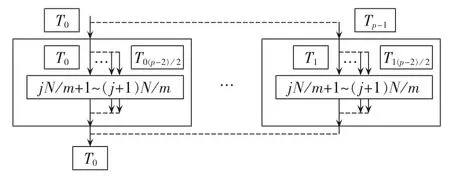
图8 嵌套循环并行线程运行图Fig.8 Threads of nested loop executing in parallel
b.非嵌套方案。另外一种方法即类似于小波分解并行执行过程。对于嵌套循环的程序,可以选择只对一层循环作并行处理,由于小波包分解中外层循环次数不多,而内层循环复杂度较高,本文选择只对内层循环过程作并行处理,即利用多核处理器同时对不同尺度的系数做卷积和二抽取过程。非嵌套循环并行执行线程运行状态如图9所示。
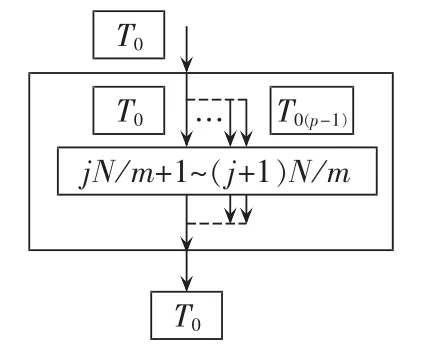
图9 非嵌套循环并行线程运行图Fig.9 Threads of non-nested loop executing in parallel
3 数据压缩分析实验
3.1 实验基本过程
为了检测并行小波包在数据压缩中的性能表现,本文对数据进行并行小波包压缩解压处理,由于小波包变换可以使信号经过小波包变换后能量集中在少数的系数上,并且这些系数的能量能够远大于其他多数小波包的系数,因此可采用阈值方法,现有的文献阈值选取包括全局阈值与局部阈值,考虑到全局阈值能降低计算的复杂度,而本文分析重点在于研究算法的并行性,因此选取全局阈值压缩。
数据压缩方法采用阈值压缩算法,阈值处理后需要记录非零小波系数的位置以及系数的取值,此过程采用文献[22]所提出的位图压缩法。
小波分解的最大级数J定义[23]如下:
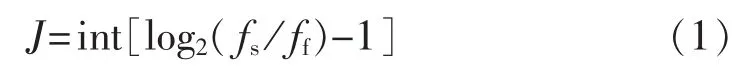
其中,ff是信号的基础频率,fs是信号的采样频率。
实验主要步骤如下。
a.载入信号后,对信号作并行小波包分解;分解层数根据式(1)得出,本实验分解层数为3层,分解过程采用第2节提出的小波包并行分解方案。
b.将分解后的小波系数,经过全局阈值处理,利用位图压缩算法将剩余后的小波系数依次排列,完成压缩过程。解压过程根据位图压缩法还原各系数原始位置,对其余位置进行补零操作。
c.采用第2节提出的并行小波包重构方案,对解压后系数作小波包重构,还原原始数据。
实验主要用于检验并行小波包的计算效率,在保证分解重构的结果与串行计算结果相一致的前提下进行。
实验时间记录从主线程执行并行小波包分解开始,直到小波包重构结束。由于实验针对小波包分解压缩重构的并行过程,因此不记录载入信号与写出信号的时间。
仿真信号源采用的是:
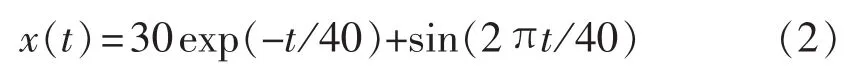
3.2 实验环境
本文采用的实验平台为:处理器为Intel(R)Core(TM)2 Duo CPU T5750,内存为 3 GB。 所有数据为5次计算时间平均值。
3.3 实验方案
为比较并行算法性能,采用本文所提出基于Pthreads及OpenMP 2种并行编程环境下的小波包并行算法与串行小波包算法分别进行数据压缩。实验在 210、215、216、220、221这 5 种数据量下,采用 db4 小波包,将信号分解为3层。实验结果见表1、2。
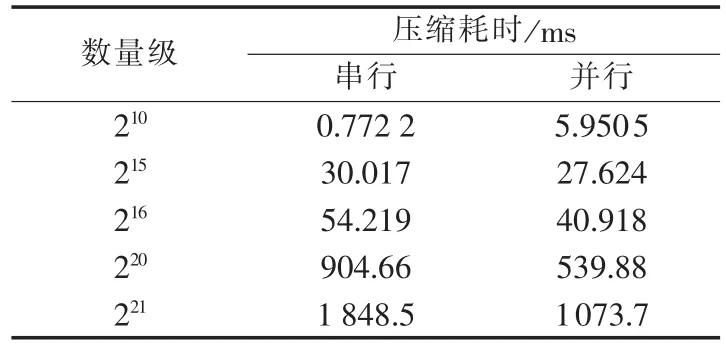
表1 小波包Pthreads数据压缩耗时Tab.1 Time consumption of data compression by wavelet packet on Pthreads
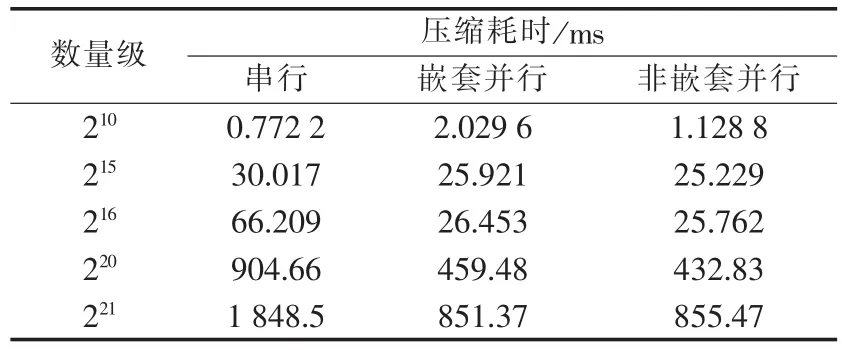
表2 小波包OpenMP数据压缩耗时Tab.2 Time consumption of data compression by wavelet packet on OpenMP
为了显示并行算法相对串行算法的性能改变,采用加速比描述:加速比=串行算法计算时间/并行算法计算时间。
表3中 S1、S2、S3分别表示 Pthreads环境下小波包并行压缩解压加速比、OpenMP环境下小波包嵌套并行压缩解压加速比、OpenMP环境下小波包非嵌套并行压缩解压加速比。
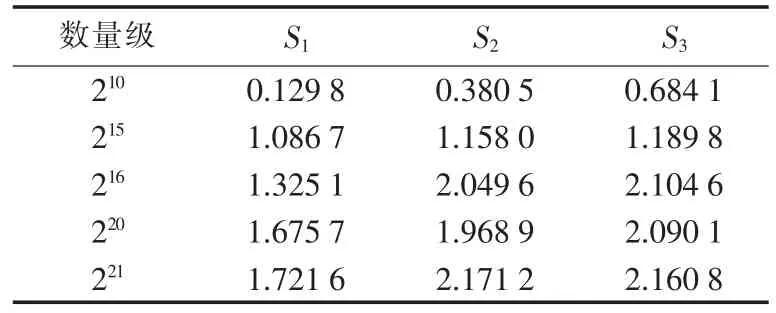
表3 加速比比较Tab.3 Comparison of speedup
3.4 实验结论
a.从实验可以看出基于Pthreads与OpenMP的并行小波包算法,在计算速度上有着较大的优势,这种性能的提升随着数据量的增大而增大。相对于串行算法有着接近2倍的速度提升,甚至在用OpenMP进行并行处理时出现超线性加速比的情况。
b.在数据量较少时,由于并行计算不可避免的开销要比并行效果带来的节约时间要大,并行计算的性能不如串行计算,在数据量为215时,各种方法的加速比表现较为一致,且都大于1,说明在此数据量附近,并行带来的节约只略大于并行开销,一旦计算机有其他程序的任务,就会严重影响此时加速比的表现。这一问题将随着海量数据处理的发展而逐渐被忽略。
c.随着数据量的增大,基于OpenMP的并行小波包加速比比基于Pthreads的并行小波包要好,这是由于Pthreads是直接控制线程调度,可以由程序员自主控制程序的底层运行,一旦代码优化效果好,就可以达到较高的加速比,反之,由于优化存在难度,在代码复杂度较高的情况下,可能达不到OpenMP的并行效果。
d.嵌套循环的并行性能比非嵌套循环较弱,这是由于嵌套使能开启后,内部循环仍旧按照之前的方式派生线程,由于外层循环根据处理器个数已经产生最大可并行执行的线程,因此,在内层循环中所派生出的新线程与其主线程并没有同时执行程序而是交替进行。此外创建和退出线程的过程又带来一定的时间消耗,使得性能下降。但是在处理器个数大于2时,通过动态分配线程,改变外层和内层线程分配方式,可以使嵌套并行循环的性能更优。
4 结语
随着单机多核处理器的广泛使用,利用多核技术实现并行小波包计算可以大幅提高处理数据的速度,进一步促进小波包变换在电力系统中的实际应用,使其可以满足由于高速电力发展带来的海量数据处理实时性的要求,保证大电力系统更安全、稳定、经济运行。
猜你喜欢
成都信息工程大学学报(2021年1期)2021-07-22
山西电子技术(2021年3期)2021-06-28
网络安全技术与应用(2020年1期)2020-01-07
测控技术(2018年8期)2018-11-25
金融经济(2017年7期)2017-07-15
环球市场(2017年36期)2017-03-09
电子测试(2016年19期)2016-11-10
电测与仪表(2016年18期)2016-04-11
城市轨道交通研究(2015年3期)2015-02-27
振动、测试与诊断(2014年4期)2014-03-01
