
基于XML的农作物病虫草害数据检索系统的研究
2013-09-28 04:57钟金琴辜丽川
合肥工业大学学报(自然科学版) 2013年8期
钟金琴, 辜丽川
(1.安徽大学 国际商学院,安徽 合肥 230031;2.安徽农业大学 信息与计算机学院,安徽 合肥 230036)
目前,农作物病虫草害数据存储在各种异构数据库中,由于不同数据库之间的不兼容,且信息标准大多不统一,造成病虫草害数据的检索和数据移植的极大困难,使得信息共享的效率大大降低。可扩展标记语言XML是近年来发展起来的基于Internet的元数据置标语言,它具有开放性、平台无关性、自描述性、灵活的可扩展性、高度层次化的数据组织形式等优点,它能轻易地整合各种数据源的数据,并且使数据具有良好的移植性。另外,农作物病虫草害数据本身结构化程度并不高,用描述半结构化数据格式标准的XML来描述无疑是个很好的解决方案。将农作物病虫草害数据用XML表示后,基于XML的农作物病虫草害数据的检索成为迫切需要。
不同于传统的文本文档,XML数据检索除了内容信息之外,还具有结构信息。当前,XML数据检索方式有2种[1]:① XML IR/query方式,使用XML数据的查询语言XQuery、XPath等对XML数据检索;②XML IR/keyword方式,直接将传统文本文档的关键字检索方法延伸至XML数据,同时可以利用XML具有的结构特征作为检索的辅助信息来限定关键词所在节点的范围。前者主要是针对以数据为中心的XML数据,后者则针对以文档为中心的XML数据。本文的XML病虫草数据主要是由大量文档数据组成,属于后者,采用XML IR/keyword检索方式。目前,XML文本数据的检索由于其用户友好性受到了越来越多的关注,成为国内外专家学者研究的热点问题[2-5]。
基于XML文本数据检索技术首先要解决的是建立一个比较高效的索引机制,包括内容索引和结构索引,索引是实现快速检索的重要保证。但是建立索引,特别是内容索引,需要很大的时间和空间上的开销,一般内容索引文档是原有XML文档的3~5倍的大小[6]。为此,本文结合XML表示的农作物病虫草害数据的特点,只建立结构索引,并未建立内容索引,由系统在缓存中建立一个堆区,自动构建存放XML文档数据的二维表数据集,此种方法可以快速定位检索信息,达到高效检索的目的。本文在此基础上提出了基于XML的农作物病虫草害数据检索模型,设计实现了一个基于XML的农作物病虫草害数据检索系统。
1 农作物病虫草害数据XML表示
(1)农作物病虫草害数据模型。以农作物中的水稻为例,通过查看一些关于水稻病虫草害的资料,经归纳分析得到水稻病害一般包括中文名、英文名、俗名、简介、症状、病原、防治方法、发病条件、传播途径、分布范围、抗病品种等部分,本文需要将这几个部分设计为XML的元素标记。一个XML文档的结构是一个典型的层状结构,可以模拟为树,称为结构树。结构树包含一个根节点和若干元素节点,元素节点既可表示元素又可表示属性[6]。图1所示为水稻病害的树状结构,同样可以得到水稻虫害、草害结构树图,并可通过合并得到水稻病虫草害总结构图。
(2)XML Schema的构建。XML Schema是用来描述XML文档结构的一种规范。它可以定义XML文档中存在哪些元素以及元素之间的关系,而且也可以定义元素和属性的数据类型。XML是一种标记性语言,水稻病虫草害XML文档中的标记是自定义的,为保证数据交流和共享的顺利进行,这些XML的数据结构、标记集必须通过XML Schema的验证。XMLSPY是XML的专业的编辑器软件,在XMLSPY中根据上述的结构图,对水稻病虫害结构图进行转化、定义后的XML Schema片断如图2所示。XML表示的农作物病虫草害数据都要符合XML Schema结构、数据类型、出现次数等限制。
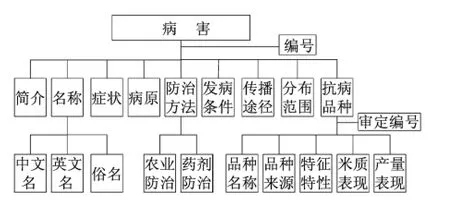
图1 水稻病害树状结构

图2 水稻病害XML Schema片段
本文的农作物病虫草害数据以水稻、花生、大豆、小麦中常见病害、虫害以及草害数据为例,具体的XML文档数据片段(水稻病害部分)如下。


2 检索系统框架的构建
(1)检索系统框架。基于XML的农作物病虫草害数据检索系统,考虑到用XML表示的农作物病虫草害数据大多具有统一的格式,并且XML元素标记之间嵌套不是很复杂的特点,采用在检索时系统自动构建虚拟二维表格的视图方式,避免了建立内容索引,解决了构建内容索引的时间和空间开销较大的难题。系统可以根据用户关心的农作物种类(水稻、小麦、花生、大豆等)和用户身份(专家学者、普通用户)逐渐缩小检索范围,有效提高了检索效率。在返回检索结果时,根据用户不同的身份返回不同的结果,具体是对专家学者返回某条病虫草害数据的所有相关标记信息,对普通用户,只返回对他们有用的标记信息。由于XML文档也属于文本文档,不方便用户查看和查找,本系统对返回结果的XML文档进行了显示优化,将其转换为表格视图的形式,方便用户的浏览。另外,加入了用户自定义词典,对经过用户鉴定的关键词可保存到词典中,以备下次检索时使用,这种智能化的方式将保证系统的使用时间越长,检索效果越好。系统总体框架如图3所示。

图3 检索系统总体框架
(2)检索系统框架构建过程。本检索系统是基于B/S结构的,利用DOM对XML表示的农作物病虫草害数据进行解析,并建立结构索引,在结构导航中显示XML的树状结构,使用户能够看到XML文档的结构信息;在缓存堆区中将解析过的XML文档数据构建成二维表数据集,XML标记名作为表中列名,使用户检索XML文档数据转换为检索二维表数据集;当用户输入检索关键词并在结构导航中选择相应标记节点时,系统首先通过用户信息库判断用户关心的农作物种类以及用户身份,缩小检索的数据集范围,再对用户输入的检索关键词进行分词处理,得到1个或多个关键词;对每个关键词分别在二维表数据集中进行查找匹配,返回包含关键词的相应二维表信息;利用XSL样式表将XML描述的检索结果文档转换为表格视图的形式,方便用户浏览。
3 关键技术分析及实现
3.1 中文分词
目前,中文分词技术已经比较成熟,概括起来可以归为基于匹配的分词、基于统计的分词和基于理解的分词3类,本文采用常用的基于词典匹配的方法。传统的匹配算法中词典大多使用文件系统txt文件存储,每一次词的匹配都要查找整个词典,平均查找次数大于n/2(n为词典长度),时间复杂度为O(n)。本系统将词典中的每个词加载到内存的一棵树上,形成词典树[7],这样分词匹配操作变成了在树上搜索词,大幅度提高了分词速度。
本系统中文分词的具体算法如下:
(1)顺序扫描词典文件,按顺序将每个词构造成一棵树。以“中国人”、“中华人民”、“甲板”为例,其树形结构如图4所示。由图可知,建树的主要目的是将词典中的词语用树与子树的关系关联起来。
(2)当用户输入关键词时,分词程序对关键词的第1个字在树中进行匹配查找,若找到,继续以该字作为根节点,顺序查找其孩子节点,如能找到关键词中第2个字,则将这2个字合为一个词,并以第2个字为根节点,顺序查找孩子节点,若找到,将这3个词合为一个词,以此类推,直到将关键词中每个字匹配完成。若没有找到,则将单个字作为一个关键词。为了描述更直观清楚,以“稻瘟病”为例,首先查找到“稻”所在的节点,然后以“稻”为根节点,在其众多孩子节点中顺序查找是否有“瘟”孩子节点,若存在,再以“瘟”为根节点,顺序查找是否有“病”孩子节点,最后返回词“稻瘟病”。

图4 词典构造树
3.2 检索实现
3.2.1 二维表数据集的构建
检索系统通过读取XML文档数据建立结构化索引时,在缓存中建立了一个堆区,自动构建存放XML文档数据的二维表数据集,该二维表使用源XML文档中标记作为表的列名,根据XML文档标记之间的嵌套关系,一个XML文档可以构建互相关联的多张二维表。这样用户对XML文档数据的检索就转化为对二维表数据集的检索。构建二维表数据集的优点如下:
(1)用户提交检索关键词后,系统不必每次都访问源XML文档数据集,不至于破坏源XML文档数据的内容,保证了XML文档数据的安全性。
(2)用户不必去检索文本形式的XML文档,只要直接访问结构化的二维表数据集,提高了检索效率。
(3)检索结束后,系统自动释放二维表数据集占用的堆区空间,减少了内存空间资源浪费。
3.2.2 检索过程
在进行检索时,首先通过中文分词将用户输入检索词分解为1个或多个关键词,然后对每个关键词分别检索。如果用户没有限定节点,那么就要访问所有二维表数据集;如果用户选择了相应的节点,那么检索范围缩小了,只要访问相应节点所在的二维表。在检索的同时,结合用户信息库,判断用户的身份、关心的农作物种类等,也进一步缩小要检索的二维数据集范围。
XML表示的病虫草数据的每一条病害、虫害或草害都是由中文名、英文名、俗名、简介、症状等固定的节点组成,所以检索返回的信息应该完整地包括这些节点,但系统在构建二维表数据集时将这些节点信息分开在不同的表中,有必要将完整的结果显示出来。返回检索结果的具体算法如下:

例如,用户输入检索关键词“稻瘟病”并选择了水稻名称下的中文名节点,首先检索出来的是二维表数据集下名称表中的一行数据,但希望显示的不仅仅是名称表的信息,还要显示稻瘟病相关的其他表信息,然后结合起来一起显示一个完整的病害信息。考虑到这些表是通过列“病害-Id”关联起来的,在知道名称表中的一行数据后,就要遍历所有的二维表数据集,从数据集中找出所有的数据表,再从数据表中找出所有行,再遍历所有行,看其中的Id列是否和查找出来的名称表中Id列信息一致,如果一致就需要显示出来。
3.3 检索结果显示优化
可扩展样式语言XSL是一种基于XML的语言,它被设计用来转换XML文档到另一种XML文档或HTML文档[8]。本系统返回的是源XML文档数据片段,不方便用户浏览。考虑到XML文档数据与显示格式是分离的,对于相同的结果XML文档,可以根据不同用户身份显示不同的格式。对于专家学者,显示病虫草害的所有XML标记数据,对于普通用户,其更关心的是农作物病虫草的防治方法,仅显示中文名和防治方法。本系统将检索结果XML文档显示如图5所示的表格视图。
对于专家学者,XML文档经转换其表格视图如图6所示。

图5 XML表格视图

图6 转换文档XSL
4 结束语
XML已经成为当前Internet上表示和交换数据的主要标准,如何对使用XML组织的数据进行快速有效的检索,是面临的一个主要问题。本文根据XML表示的农作物病虫草数据的特点,采用系统自动构建二维表数据集的方式,实现XML文本数据的高效检索。本检索系统避免了建立内容索引所需的时间和空间上的开销,对于可以标识一条病虫草害数据的几个元素标记,如中文名、英文名、俗名等,在检索时对其结构限制进行严格解释,其检索结果准确率可以达到100%。但检索系统采用最简单的字符串匹配方式,速度慢,尽管在目前微量的数据集情况下,该算法的缺点并没有体现出来,但是随着数据集的增大,该算法还有待进一步优化。另外,本检索系统并没有考虑到众多检索结果的排序显示问题,这也是下一步研究工作的重点。
[1]陈忆群,温子梅,曹瑾音.高适应性企业信息查询扩展系统设计与实现[J].计算机工程与应用,2011,47(2):227-232.
[2]刘 丹,孔少华,陆 伟.XML检索研究综述[J].现代图书情报技术,2010,10(4):24-34.
[3]Carmel D,Maarek Y,Soffer A.XML and information retrieval:a SIGIR 2000workshop [J].ACM SIGIR Forum,2000,34(1):31-36.
[4]Fuhr N,G¨overt N,Kazai G,et al.INEX:initiative for the evaluation of XML retrieval[M]//Liu L,Ozsu T M.Engyclopedia of Database System.New York:Springer,2009:1531-1537.
[5]廖述梅,万常选,徐升华.XML信息检索探究[J].情报学报,2007,26(2):229-234.
[6]连剑波,刘 任,刘 杰.XML数据库在蔬菜病虫害信息发布平台中的应用[J].安徽农业科学,2010,38(4):2178-2180.
[7]廖 敏,褚颖娜,宋继华.双数组Trie树索引的可操作性研究[J].计算机系统应用,2009(10):52-56.
[8]关 辉.利用XSLT实现XML文档格式的转换[J].福建电脑,2009(3):181,167.
猜你喜欢
客联(2022年3期)2022-05-31
中国新闻周刊(2021年26期)2021-07-27
校园英语·月末(2021年13期)2021-03-15
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
现代园艺(2018年1期)2018-03-15
今日农药(2017年6期)2017-07-20
信息安全研究(2016年4期)2016-12-01
浙江农业科学(2016年11期)2016-05-04
现代农业(2016年5期)2016-02-28
