
基于LabVIEW的说话人确认系统设计
2013-09-19 06:42:20崔艳秋张俊星
大连民族大学学报 2013年5期
崔艳秋,张俊星,李 敏,许 爽
(大连民族学院信息与通信工程学院,辽宁大连116605)
语音是人的自然属性之一,由于发音器官的生理性差异以及后天所形成的发音习惯的行为差异,不同说话人的语音具有鲜明的个人特征,这使得通过分析语音信号来识别说话人成为可能。说话人确认属于说话人识别中的一类,通过提取说话人语音中的个人特征来确定一个人的身份。说话人确认所使用的语音是人体所固有的生物特征,不容易被冒充或窃取,可以随时使用,并且可以利用电话网络实现远距离服务,相对于传统的密码、钥匙等身份识别方法更安全、更有效、更可靠,因此具有广泛的应用领域,越来越受到人们的重视。
LabVIEW是美国NI公司开发的一种编程语言和开发环境,是标准的数据采集和仪器控制软件[1],通过同计算机相结合可以组建自己的虚拟仪器。虚拟仪器利用计算机的软、硬件资源,可以高效的实现数据的分析、处理、表达、传递、储存,扩展了传统仪器的功能。虚拟仪器的核心是软件,用户可以根据自己的需要自行设计或扩展仪器的功能,增强了工程人员构建自己的科学或工程系统的能力,在各个领域得到广泛应用[2-4]。LabVIEW是一种图形化的编程语言,编程简单,而且提供了对声卡进行操作的函数。借助LabVIEW软件的这些优势,本文开发了一个说话人确认系统,该系统以计算机作为硬件平台实现数据的采集,以LabVIEW和MATLAB作为软件平台实现语音的分析和说话人的确认。该系统界面友好,操作方便,既可以作为一个系统用于出入境管理、金融服务、信息安全(个人隐私保护)等需要身份认证的领域,也可以作为一个实验平台用于各种说话人识别和语音识别算法的仿真分析。
1 工作原理
说话人识别是从说话人的语音信号中自动提取说话人的特征,并对说话人进行识别的研究。它同语音识别不同,目的不是识别说话人讲的内容,而是识别说话人是谁。按其最终完成的任务,说话人识别可以分为两类:说话人确认和说话人辨认。本质上,它们都是根据说话人所说的测试语句或关键词,从中提取与说话人本人特征有关的信息,再与存储的参考模型比较,做出正确的判断。不过,自动说话人确认是确认一个人的身份,只涉及一个特定的参考模型和待识别模式之间的比较,系统只做出“是”或“不是”的二元判断。
说话人识别属于语音信号的模式识别问题。典型的说话人识别系统的结构如图1,包括预处理、特征提取、建立参考模板、模式匹配和判决等几大部分[5]。建立一个说话人识别系统可以分为两个阶段:训练阶段和识别阶段。训练阶段的目的是提取说话人的特征参数,建立每个说话人的模板或者模型参数参考集;识别阶段的目的则是把待识别语音的特征参数和训练好的模板集进行比较,并根据一定的相似性准则进行判定,给出识别结果。对于说话人确认而言,则是将输入语音中的特征参数与声言为某人的参考量相比较,如果两者的距离小于规定的阈值,则予以确认,否则予以拒绝。

图1 说话人识别系统框图
2 系统构成
本文设计的说话人确认系统由软、硬件两部分组成。硬件部分的主要任务是通过麦克风和计算机上的声卡将语音信号转换为电信号,经过A/D转换,以数字信号的形式传入计算机;软件部分的主要任务是数字语音信号的分析和识别。
2.1 硬件部分
为了完成语音的采集和数字化,硬件一般包括三个部分:传感器及信号调理电路,A/D转换电路,PC机接口电路。但是由于声卡已经成为计算机的标准配置,而且LabVIEW提供了对声卡进行操作的函数,所以在本系统中直接采用话筒和声卡实现这部分功能。
2.2 软件部分
LabVIEW最显著的特性之一是对数据的图形化显示提供了丰富的支持。本系统借助LabVIEW的这一优势设计了功能强大、友好的系统用户界面。但是LabVIEW的数据处理功能不够强大,而本系统需要进行大量复杂的运算。为了弥补Lab-VIEW这方面的不足,本系统在LabVIEW中通过MATLAB Script节点调用MATLAB程序来完成语音的预处理和说话人的确认等复杂运算。本系统所用的LabVIEW版本为LabVIEW7.1。整个系统从功能上可以分为语音采集模块、训练模块、确认模块三部分,系统的前面板如图2。
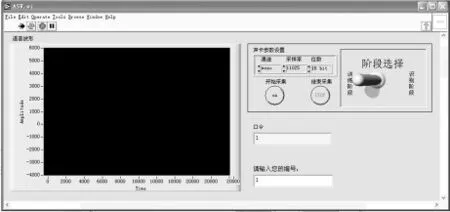
图2 程序前面板
(1)语音采集模块
该模块对应的程序框图如图3。
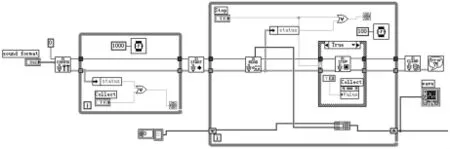
图3 语音采集模块程序框图
LabVIEW7.1中提供了一系列与声卡有关的函数,这些函数集中在Sound VI子模板下。这些函数都是利用Windows底层函数编写的,所以灵活、速度快,能够满足实时不间断采集的需要。语音采集模块主要利用这些函数来完成声卡参数的设置、语音信号的采集、语音波形的显示,以及最后声卡等一系列系统资源的释放。利用该模块,用户可以在前面板设置声卡的技术参数、启动语音信号的采集,并且可以同时看到采集的语音波形。
(2)训练模块
训练模块主要完成训练阶段语音信号的预处理、特征提取以及特征的存储等工作,对应的程序框图如图4。预处理工作包括数字语音信号的预加重、分帧、加窗以及端点检测,主要是通过调用MATLAB节点中的预处理函数MyPreprocessor来实现的。由唇端辐射引起的能量损耗,使得语音信号能量在高频处要明显地小于低频和中频处,这样就导致语音信号的频谱通常是频率越高谱值越小[6]。预加重的目的就是增强语音信号的高频部分,使信号的频谱变得平坦,以便于统一的分析和处理。本系统让语音信号通过一个传递函数为H(z)=1-0.937 5 z-1的滤波器来实现预加重的作用。分帧、加窗的目的是把语音信号分为一个个短时段,从而可以把语音信号近似为平稳信号来处理。本系统采用的是交叠分帧的方法,帧长为256个采样点,帧移为80个采样点,所用的窗函数为汉明窗。端点检测的目的是去除无声段保留浊音和清音段以备进行特征参数分析。本系统采用的是基于短时能量和平均过零率的双门限法[7]来进行端点检测。特征提取是通过调用MATLAB节点中的特征提取函数mfcc来实现的,提取的特征是Mel频率倒谱参数。训练时获得的特征参数最后利用LabVIEW函数Write To Spreadsheet File.vi存储在文件中。此外,为了防止训练中提取的有效语音段太短,在系统中设置了一个阈值。如果采用的帧数大于该阈值则训练成功,否则判定为训练失败。如图5为训练成功时对应的前面板。

图4 训练模块的程序框图
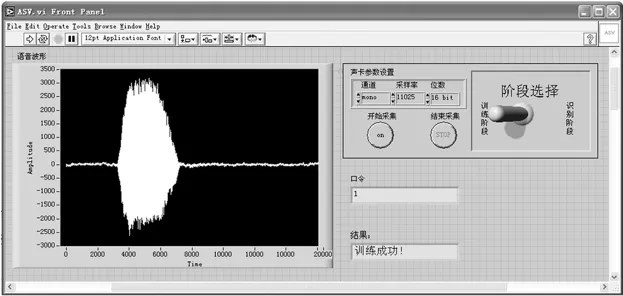
图5 训练成功时的前面板
(3)确认模块
确认模块主要完成识别阶段语音信号的预处理、特征提取以及模式匹配等工作,对应的程序框图如图6。预处理和特征提取过程的作用同训练模块中的预处理和特征提取过程类似,主要是完成识别阶段语音信号的预加重、分帧、加窗、端点检测以及Mel频率倒谱特征参数的提取。模式匹配过程主要在MATLAB节点中进行,函数dtw利用动态时间规整(DTW)算法把待确认者语音中提取出的特征参数同文件中读出的特征模板进行匹配。如果最后算得的距离小于给定的阈值则予以肯定,否则予以拒绝。最后的识别结果显示在前面板,如图7。
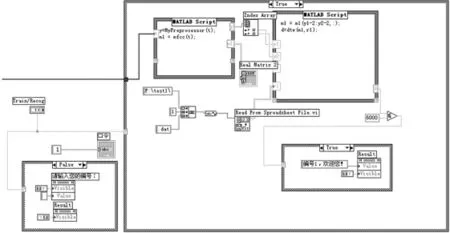
图6 确认模块的程序框图
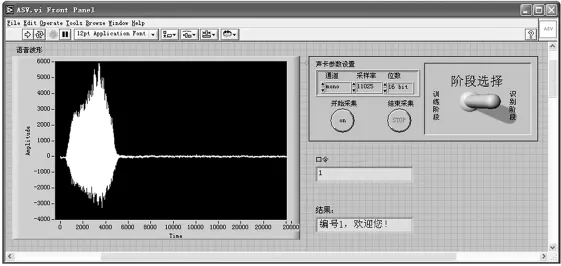
图7 确认成功时的前面板
3 实验结果与分析
本实验在实验室环境下进行。实验时,声卡参数通过前面板设置为单声道、采样频率为11025 Hz,数据格式为16位字长。本系统为与文本有关的说话人确认系统,训练和识别所用的音节显示在前面板的“口令”文本框中。训练时,每个说话人对指定的音节发音;识别时,每个说话人再对(同训练时)相同的音节发音。对于30个真的待确认者,每人进行10次实验,此系统的错误拒绝率为1%;对于20个假的待证实者,每人进行10次实验,错误接受率为0.5%。从实验结果可以看出,该系统较好的完成了对说话人身份的确认,识别准确率较高。该系统采用的识别特征是Mel频率倒谱参数,匹配方法采用的是动态时间规整方法,用户可以根据自己的需要灵活的升级算法,以获得更好的识别效果。
4 结语
本文设计了一个基于LabVIEW的说话人确认系统。该系统以计算机作为硬件平台、以麦克风作为输入设备,有强大的语音处理功能,能够实时、准确地对说话人的身份进行确认。同人脸识别、虹膜识别等其它生物特征识别系统相比,该系统输入设备成本低,且不涉及隐私问题,用户易于接受。系统界面友好,开发和维护费用低,易于同安全、监控、管理系统整合,可以广泛应用于出入境管理、金融服务、信息安全等需要身份认证的领域。同时,该系统也为构建说话人识别和语音识别系统提供了一个有效的框架。用户可以将它作为一个实验平台,根据需要灵活的升级算法,以实现对各种说话人识别和语音识别算法的仿真分析。
[1]侯国屏,王坤,叶齐鑫.LabVIEW7.1编程与虚拟仪器设计[M].北京:清华大学出版社,2005.
[2]王茜蒨,刘佳,彭中,等.基于LabView的激光束发散角测量系统[J].中国激光,2012,39(11):122-125.
[3]陈明星,朱灵,张龙,等.基于LabVIEW的光纤傅里叶变换光谱仪数据处理技术[J].仪器仪表学报,2010,31(3):488-492.
[4]LIU Yi.Analysis on virtual assembly technique of chemical engineering technological process based on labVIEW[J].Journal of Convergence Information Technology,2013,8(3):11-18.
[5]赵力.语音信号处理[M].2版.北京:机械工业出版社,2011.
[6]吴朝晖,杨莹春.说话人识别模型与方法[M].北京:清华大学出版社,2009.
[7]何强,何英.MATLAB扩展编程[M].北京:清华大学出版社,2002.
猜你喜欢
中国特种设备安全(2021年5期)2021-11-06 05:09:00
电脑报(2021年21期)2021-08-19 17:22:40
装备制造技术(2021年4期)2021-08-05 07:39:54
电脑报(2019年29期)2019-09-10 07:22:44
制造技术与机床(2017年11期)2017-12-18 06:46:39
电测与仪表(2015年7期)2015-04-09 11:40:04
无线互联科技(2014年7期)2014-09-24 00:07:42
计算机应用文摘(2010年20期)2010-04-29 00:44:03
微型计算机(2009年12期)2009-12-21 02:58:16
计算机应用文摘(2009年28期)2009-04-29 23:12:40
