
一种基于语义相关度的特征选择方法
2013-09-19 09:22刘洋
网络安全技术与应用 2013年4期
刘洋
桂林理工大学信息科学与工程学院 广西 541000
0 引言
随着网络技术的迅猛发展,网络上的信息量呈指数级增加,相关信息处理技术现已成为人们获取有用信息时至关重要的工具,文本分类(Text Categorization)作为处理和组织大量文本数据的关键技术应运而生。因此,研究文本分类成为自然语言处理和数据挖掘领域中一项具有重要应用和理论价值的课题。文本分类是在预定义的分类体系下,根据文本的特征,将给定文本与一个或者多个类别相关联的过程。文本自动分类问题的最大特点和困难之一是特征空间的高维性和文档表示向量的稀疏性。寻求一种有效的特征提取方法,降低特征空间的维数,提高分类的效率和精度,成为文本自动分类中需要首先面对的重要问题。
特征选择(Feature Selection,FC)作为文本分类关键一步,它的好坏将直接影响文本分类的准确率,特征空间的降维操作成为了提高文本分类准确率和效率的关键。好的降维不仅可以提高机器学习任务的效率,而且还能改善分类性能和节省大量的存储空间。在进行维数约简时,实际是将高维空间映射到一个小得多的低维空间,同时希望该低维空间一方面能尽可能多地保留原始信息中的重要信息,另一方面又能有效地把原始信息中的噪音、冗余数据过滤掉。本文提出一种基于《同义词词林》的词语相关度的特征选择方法,通过计算词语之间的语义相关度,进行特征取舍,降低特征空间的高维性,并有效减少噪声,得出最优特征空间,从而提高了分类精度。
1 特征选择方法
传统的特征选择相关研究主要集中在降维的模型算法与比较,特征集与分类效果的关系,以及降维的幅度3个方面。在文本分类中,常用的特征选择方法有基于阈值的统计方法,如文档频率方法(DF),信息增益方法(IG),互信息方法(MI),CHI方法,期望交叉熵,文本证据权,优势率,基于词频覆盖度的特征选择方法等,以及由原始的低级特征(比如词)经过某种变换构建正交空间中的新特征的方法,如主分量分析的方法等。基于阈值的统计方法具有计算复杂度低,速度快的优点,尤其适合做文本分类中的特征选择。关于文本分类中的特征选择问题, 比较有代表性的是Yang Yi ming和 Dunja Mladenic的工作(图1)。
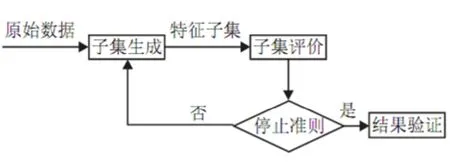
图1 特征选择示意图
(1) 文档频率
词条的文档频率(Document Frequency)是指在训练语料中出现该词条的文档数。采用DF作为特征抽取基于如下基本假设:DF 值低于某个阈值的词条是低频词,它们不含或含有较少的类别信息。将这样的词条从原始特征空间中移除,不但能够降低特征空间的维数,而且还有可能提高分类的精度。文档频率是最简单的特征抽取技术,由于其具有相对于训练语料规模的线性计算复杂度,它能够容易地被用于大规模语料统计。
(2) 信息增益
信息增益(Information Gain)在机器学习领域被广泛使用对于词条t和文档C类,IG考察C中出现和不出现t的文档频数来衡量t对于C的信息增益。我们采用如下的定义式:
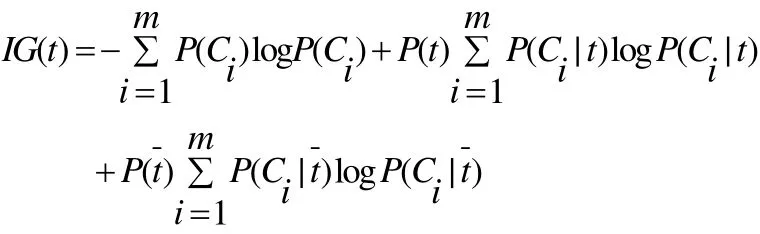
其中表示类文档在语料中出现的概率,P(t)表示语料中包含词条 t的文档的概率,P(Ci|t)表示文档包含词条t时属于Ci类的条件概率,P(t)表示语料中不包含词条 t的文档的概率,P(Ci|t)表示文档不包含词条t时属于Ci的条件概率,m表示类别数。
(3) 卡方(CHI)统计
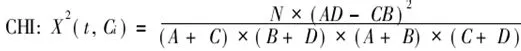
(4) 互信息
互信息(Mutual Information)在统计语言模型中被广泛采用。如果用A 表示包含词条t且属于类别C的文档频数,B为包含t 但是不属于C的文档频数,C表示属于C但是不包含t的文档频数,N表示语料中文档总数,t和C的互信息可由下式计算:
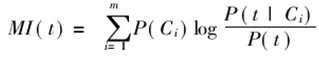
2 基于词汇相关度计算的特征选择
2.1 《同义词词林》介绍
《同义词词林》是梅家驹等人于1983年编纂而成,这本词典中不仅包括了一个词语的同义词,也包含了一定数量的同类词,即广义的相关词。由于《同义词词林》著作时间较为久远,且之后没有更新,所以哈尔滨工业大学信息检索实验室利用众多词语相关资源,完成了一部具有汉语大词表的《哈工大信息检索研究室同义词词林扩展版》。《同义词词林扩展版》收录词语近7万条,全部按意义进行编排,是一部同义类词典。
《同义词词林》按照树状的层次结构把所有收录的词条组织到一起,把词汇分成大、中、小 3类,《同义词词林》共提供了5层编码, 第1级用大写英文字母表示;第2级用小写英文字母表示;第3级用二位十进制整数表示;第4级用大写英文字母表示;第5级用二位十进制整数表示。例如:“Ae07C01=渔民 渔翁 渔家 渔夫 渔父 打鱼郎”,“Ae07C01=”是编码,“渔民 渔翁 渔家 渔夫 渔父 打鱼郎”是该类的词语。
2.2 词汇相关度计算
词汇相关性计算在很多领域中都有广泛应用,例如信息检索、信息抽取、文本分类等等。词汇相关性计算的两种基本方法是基于世界知识(Ontology)或某种分类体系(Taxonomy)的方法和基于语料库(Corpus-Based)上下文统计的方法。这两种方法各有优缺点。但从某种意义上来说,专家所划分的词汇知识概念体系应该具有权威性,依赖这样的概念体系进行词汇相关性计算也更加合理。本文采用基于《同义词词林》的词汇相关性计算是一种基于世界知识的方法。
2.3 改进的特征选择方法
本文根据文献5中算法指导,通过查找计算两两特征词之间的语义关系(上下义位关系、整体-部分关系、反义关系、包含关系),从而确定特征向量的选择。但是,针对具有同义关系的词,我们就要进行合并处理,因为过多同义词不但不能提高语义特性,反而会增加空间维数。根据《同义词词林》组织编排特点,基于《同义词词林》的语义相关度计算的主要思想是:基于《同义词词林》结构利用词语中义项的编号根据两个义项的语义距离,计算出义项相关度。
具体步骤如下:
(1) 经过分词、词干处理一系列文本预处理我们得到最初文本特征空间,对最初的在文本预处理得到的文本特征集的基础上,对于一篇文本而言,首先读取特征词,通过查询《同义词词林》,得到其各自对应分类结构树,对于分类结构树,逐一进行处理。
(2) 计算特征词语义相关度。首先判断在同义词林中作为叶子节点的两个义项在哪一层分支,即两个义项的编号在哪一层不同。相同则乘1,否则在分支层乘以相应的系数,然后乘以调节参数cos(n ×)其中n是分支层的节点总数。词语所在树的密度,分支的多少直接影响到义项的相似度,密度较大的义项相似度的值相比密度小的相似度的值精确。再乘以一个控制参数(n-k+1)/n,其中n是分支层的节点总数,k是两个分支间的距离。若两个义项的相似度用sim表示。公式(1)、(2)分别对应义项是不是在同一棵树上,a、b、c、d、e对应各自层数,分别取值为0.65,0.8,0.9,0.5,0.1。
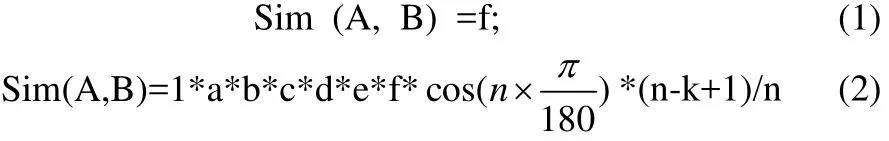
(3) 候选特征词依据修正后的权重排序,选取前N个特征词形成特征向量空间。
(4) 对词形特征向量空间模型的规范化处理,采用一范数规范化处理方式进行归一化处理,经过最后一步规范化处理后即得到了最终的向量空间模型。
3 实验结果
我们在Weka平台上,用谭松波等收集的中文语料集作为语料库进行实验。采用KNN分类器本文提出的基于《同义词词林》的文本特征选择方法的效果进行评估。试验中采用的评价参数如下:
分类准确率= 该分类的正确文本数/该分类的实际文本数。

表1 特征提取

表2 分类准确率提高
表1显示出使用本方法进行特征提取时,最终的特征向量个数大幅度减少;从表2能看出分类准确率有明显的提高。
4 结论
在《同义词词林》基础上,我们进行了基于语义相关度的文本特征选择的研究。与传统的特征选择方法进行了实验比较, 实验结果表明该方法有效的降低了特征空间的高维稀疏性和减少噪声,提高了分类精度,体现出更好的分类效果。
[1]宗成庆.统计自然语言处理[M].北京:清华大学.2008.
[2]代六玲,黄河燕,陈肇雄.中文文本分类中特征抽取方法的比较研究[J].中文信息学报.2003.
[3]SU Jin-Shu,ZHANG Bo-Feng,XU Xin..Advances in Machine Learning Based Text Categorization[J] Journal of Software, Vol.17, No.9, September 2006.
[4]周茜,赵名生.中文文本分类中的特征选择研究[J].中文信息学报.2003.
[5]田久乐,赵蔚.基于同义词词林的词语相似度计算方法[J].吉林大学学报.2010.
[6]刘群,李素建.基于《知网》的词汇语义相似度算[J]. Computational Linguistics and Chinese Language Processing.2002.
[7]http://sourceforge.net/projects/weak.
猜你喜欢
电子制作(2017年23期)2017-02-02
知识经济·中国直销(2016年5期)2016-11-07
西北工业大学学报(2015年4期)2016-01-19
智能系统学报(2015年4期)2015-12-27
知识窗(2015年1期)2015-05-14
信息安全研究(2015年3期)2015-02-28
振动工程学报(2014年4期)2014-03-01
Beijing Review(2012年37期)2012-10-16
